




概述
数据科学/机器学习/深度学习有 4 个数学先决条件(或者我们称之为“基本要素”),即:
- 概率与统计
- 线性代数
- 多元微积分
- 凸优化
介绍
在本文中,我们将讨论以下问题:
- 我为什么要关心 ML 中的优化?
- DS/ML/DL 中的优化在哪里使用?
- 什么是凸函数?
- 究竟什么是优化,它与其他数学问题有何不同?
- 有哪些不同类型的优化问题?
- 我们如何“解决”优化问题?
- 应该使用哪种方法来解决什么样的优化问题?
- 你能用机器学习算法展示“优化在行动”吗?
- 更多关于 ML/DL 域中使用优化的示例?
- 除了 ML/DL 域之外,优化还用在了哪里?
1. 我为什么要关心 ML 中的优化?
事实上,在每个机器学习(和深度学习)算法的背后,都涉及到一些优化。好吧,让我举个最简单的例子。考虑以下 3 个数据点:
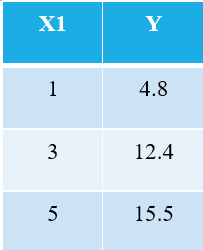
熟悉机器学习的人都会立刻意识到,我们将 X1 称为自变量(也称为“特征”或“属性”),而 Y 是因变量(也称为“目标”或“结果” )。因此,任何机器的总体任务都是找到 X1 和 Y 之间的关系。这种关系实际上是机器从DATA 中“学习”的,因此我们称之为机器学习。我们人类从我们的经验中学习,同样,同样的经验以数据的形式输入机器。
现在,假设我们要通过上述 3 个数据点找到最佳拟合线。下图以蓝色圆圈显示这 3 个数据点。还显示了红线(带正方形),我们称其为通过这 3 个数据点的“最佳拟合线”。此外,我还展示了一个“不合适的-
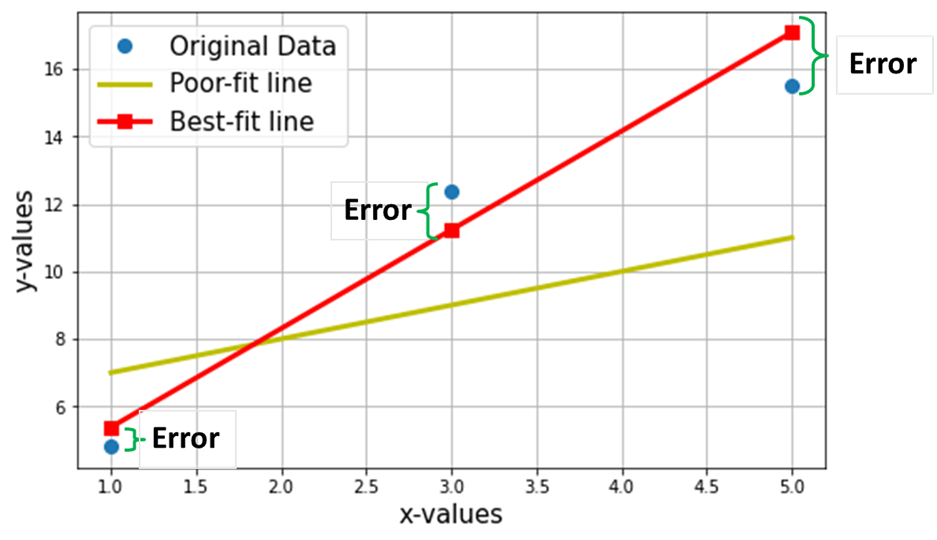
净目标是找到 最佳拟合直线的方程 (通过上表中提到的这 3 个数据点)。

是最佳拟合线的方程(上图中的红线)。
其中 w1 = 直线的斜率; w0 = 直线的截距
在机器学习中,这种最佳拟合也称为 线性 回归 (LR) 模型,而 w0 和 w1 也称为 模型权重或模型系数。
线性回归模型 (Y^) 的预测值在上图中用红色方块表示。当然,预测值与 Y 的实际值(蓝色圆圈)并不完全相同,垂直差异表示预测中的误差:

对于任何第 i 个数据点。
现在我声称这条最佳拟合线将具有最小的预测误差(在所有可能的无限随机“不良拟合”线中)。所有数据点的总误差表示为 均方误差 (MSE) 函数, 对于最佳拟合线而言,它将是 最小值。
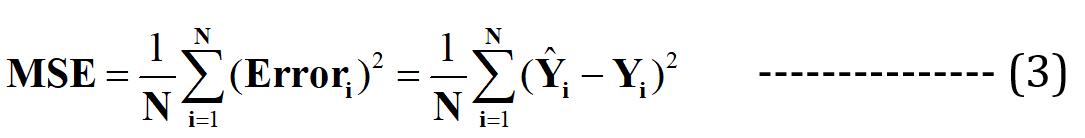
N = 总数 数据集中的数据点数(在当前情况下为 3)
最小化或最大化任何数量在数学上称为 优化问题,因此解决方案(存在最小值/最大值的点)被 称为最优 值变量。
2. DS/ML/DL 中的优化在哪里?
监督学习任务有两种类型:回归和分类。
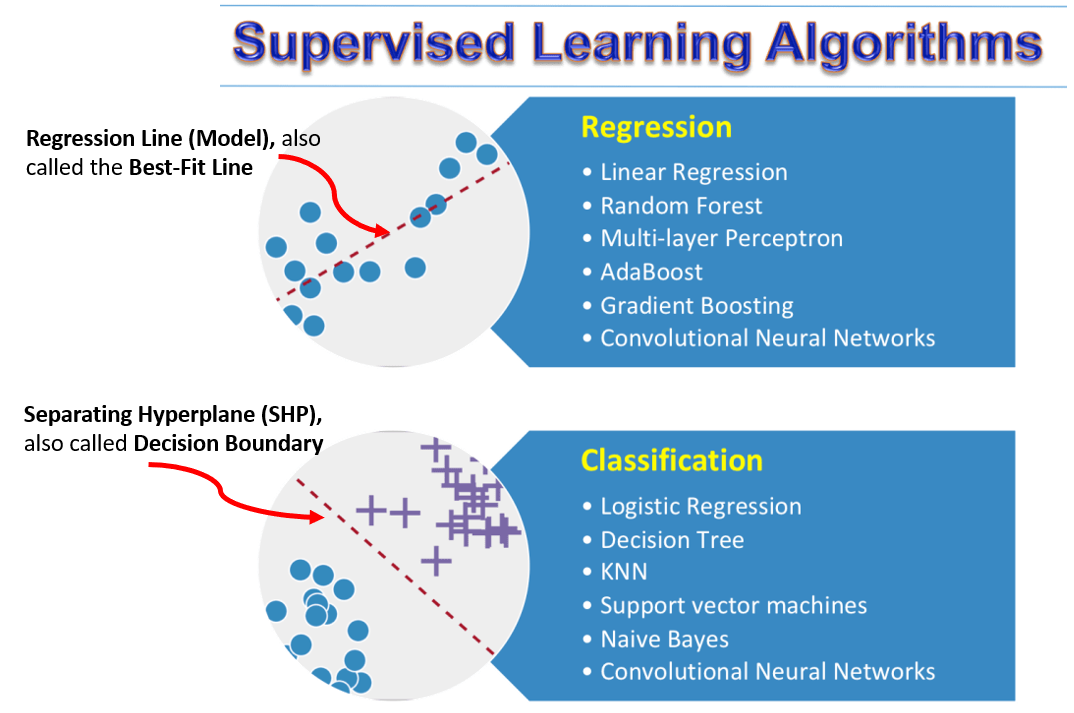
在回归问题中,目标是找到穿过大多数数据点的“最佳拟合”线(基本上,最佳拟合线将捕获 X 和 Y 之间的模式/关系),并且将具有最小值误差函数(也称为 成本函数或损失函数),通常是均方误差 (MSE)。为什么只有 MSE,为什么不简单的误差总和或绝对误差的平均值将在另一篇文章中讨论。因此,如上一节所述,净目标是找到具有该误差函数最小值的线。下表列出了在最常用的回归器算法中被最小化的误差函数。
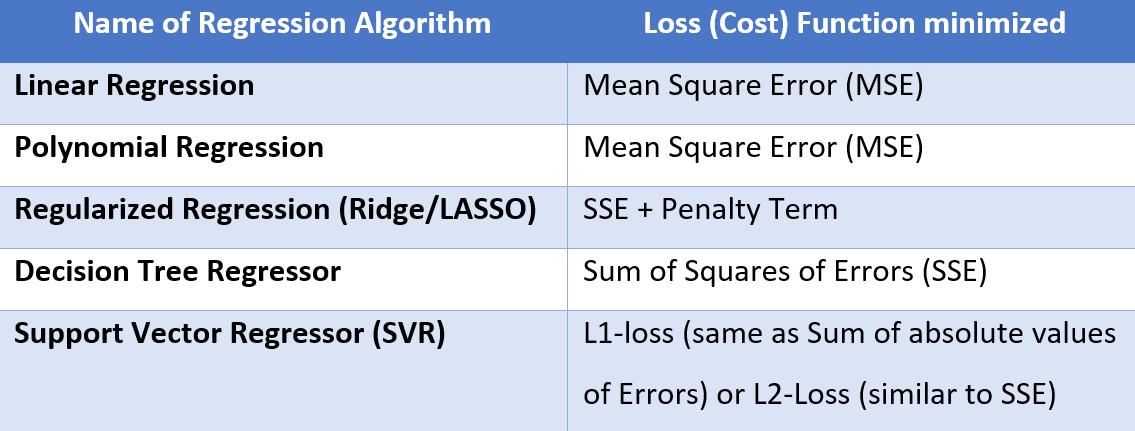
除了上面的列表,一些 ML 和 DL 算法也使用 Huber 损失。
在分类问题中,目标是找到 “最佳分离”超平面,本质上是一条在数据点“之间”通过的线(或曲线),以便能够将大部分数据点分成 2 个或更多类。在这种情况下,我们希望最小化分类错误(对于错误标记的数据点)。根据分类器 (ML) 算法的类型,该分类错误再次以多种形式表示,下表总结了相同的内容。
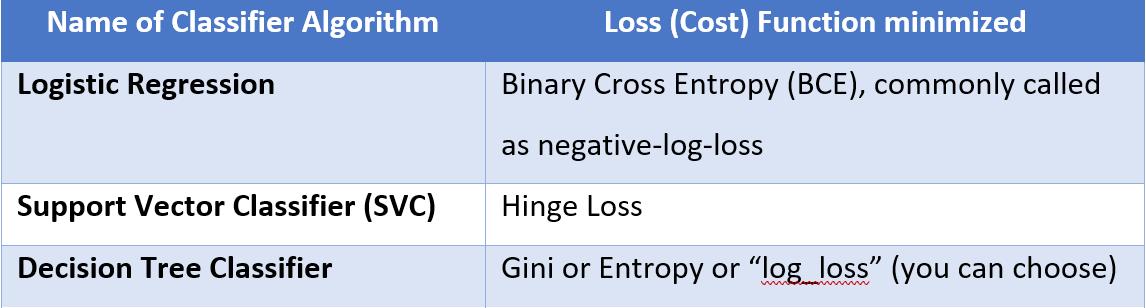
实际上,在深度学习架构中,您可以创建自定义的神经网络并根据问题选择您的损失函数(所有可用的损失函数都在此链接中列出: https ://keras.io/api/losses/ )
3. 什么是凸函数?
既然我们有一个合理的想法,即优化处理最大化或最小化一个数量,那么基本问题可以最大化或最小化任何数学函数吗?简单回答是不。数学函数是严格单调的,没有任何最大值/最小值。(例如,平方函数 y = x^2 或指数函数 y=e^x)。
凸函数具有最小值(在给定范围内),而严格凸函数将只有一个最小值(在整个范围内)。单个变量的凸函数的示例包括二次函数 (x^2) 和指数函数 (e^x)。在机器学习中,我们更喜欢损失函数不仅是凸的,而且是连续的和可微的。例如,LASSO 回归 (SSE + lambda*L1-Norm) 的损失函数是凸的,而 Ridge 回归 (MSE/SSE + lambda*square of L2-norm) 的损失函数是严格凸的,类似于使用的 MSE 损失函数在线性回归中。
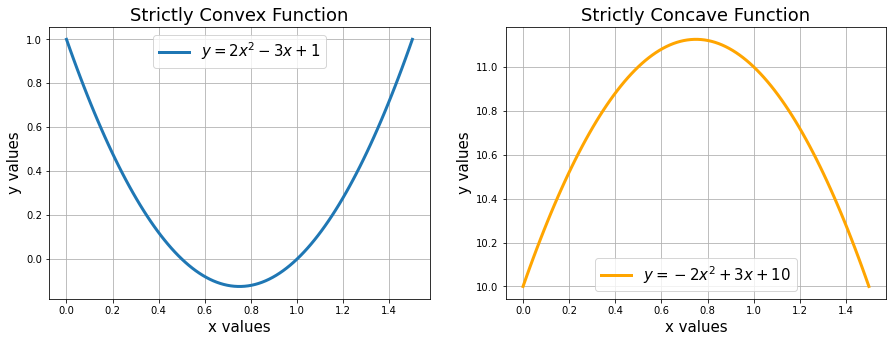
类似地,凹函数将具有最大值。您可以在此处阅读有关凸函数和凹函数 的更多信息。
4. 什么是优化,它与其他数学问题有何不同?
考虑求多项式 2x^2 – 3x + 1 的根的问题。多项式的根表示 x 的值,其中 f(x) = 0。从上图中可以看出,根是0.5 和 1.0。这种“确定性”问题不被视为优化问题。
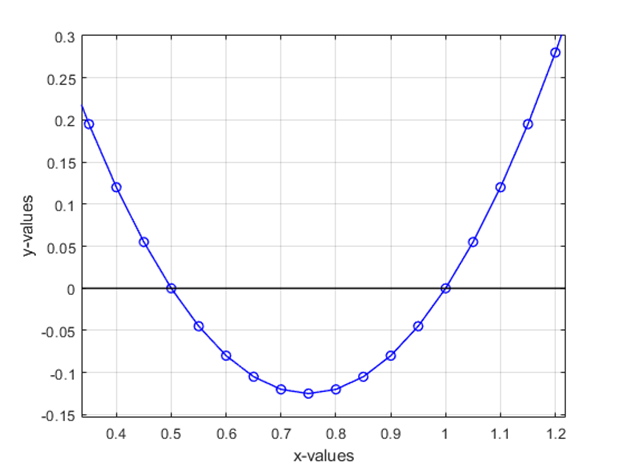
任何涉及最大化或最小化任何物理量(可以数学计算/以某些变量的形式表示)的问题都被定义为优化问题。
数学上,
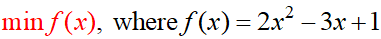
读作 “找到 f(x) 的最小值”, 是一个优化问题。这里 f(x) 被称为 目标函数 (在我们的机器学习中被称为损失函数或成本函数),这里的变量“x”被称为“决策变量”。
还有下面
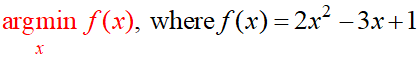
读作 “找到 f(x) 具有最小值的参数 x”, 也是一个优化问题。我们所有的机器学习优化都属于这种类型!
5. 有哪些不同类型的优化问题?
通常有两种类型的优化问题:约束和无约束。
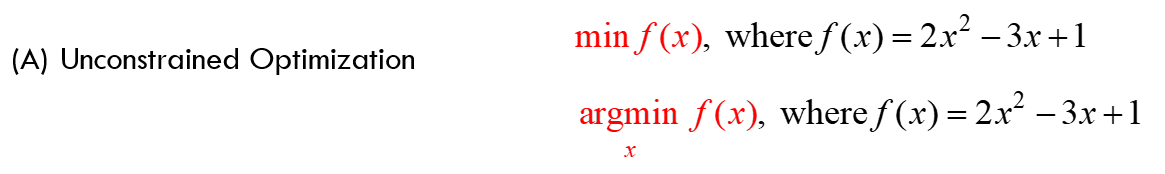
x 的值既没有任何“界限”(例如,x 必须是一个正数,或者它应该在 0 和 10 之间,等等),也没有任何类型的约束需要满足。
线性回归是无约束优化的一个例子,由下式给出:
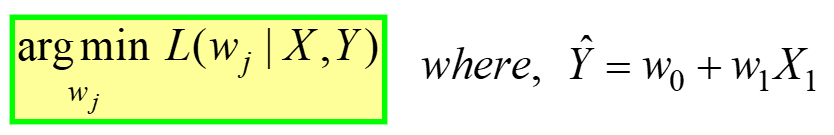
说,对于给定的 X,Y 数据,找到 MSE 损失函数(在上面的等式 3 中给出)具有最小值的最佳权重( wj ) (首先请参阅文章开头的表格)。L(wj) 代表 MSE 损失,模型权重的函数,而不是 X 或 Y。请记住,X 和 Y 是您的数据,应该是常数!下标“j”代表第j个模型系数/权重。
(B)约束优化: 例如
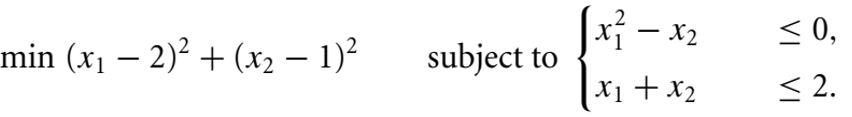
上面给出的“最小化 (x1-2)^2 + (x2-1)^2,受约束”。
满足所有约束的决策变量取值范围构成“可行区域”,最终的最优值将位于这些可行区域内。如果约束非常“硬”且相互矛盾,则给定的优化问题可能没有任何“可行的解决方案”。
https://en.wikipedia.org/wiki/Support-vector_machine#/media/File:SVM_margin.png
约束优化的一个例子是支持向量机 (SVM),它是一种通常用于分类的 ML 算法(尽管它也有一个回归变量)。默认情况下,支持向量分类器 (SVC) 尝试找到具有最大边距的分离超平面,并带有“硬约束”,即所有数据点都必须正确分类。但是,如果数据不是线性可分的,它可能不会导致任何解决方案。在这种情况下,我们使用“内核技巧”和/或使用 SVM 的软边距变体(由算法中的超参数 C 控制),损失函数为 Hinge Loss。有关 SVM 问题公式、损失函数和内核技巧的更多详细信息可以在本文中找到。https://www.analyticsvidhya.com/blog/2021/10/support-vector-machinessvm-a-complete-guide-for-beginners/
6. 我们如何“解决”优化问题?
通常有两种方法可以解决大多数最复杂的数值/科学问题:
- 分析方法:这是通常在学校/大学教学大纲中教给我们的“纸笔”理论方法。这些方法将为任何可解决的适定数学问题提供“精确”解决方案。例如,如果我们被要求找到函数 f(x) = 2x^2 – 3x + 1 值等于 0 的 x 值(通常称为多项式的“根”),我们知道已经被教导求解通用 2 次多项式 ax^2 + bx + c = 0 的根,由下式给出:
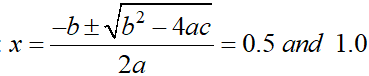
- 数值方法方法:通常,在这种方法中,我们从一个猜测值作为解开始,然后执行一些计算(在这种情况下,评估函数 f(x),然后在每次迭代中“改进”解,直到我们得到期望的结果(称为收敛)。例如,如果将容差设置为 0.0001,则当 f(x) <= 0.0001 的值时迭代将停止,并且整个优化过程被称为收敛到最优解。典型的“寻零”数值方法包括牛顿法、正割法、布伦特法和二分法。您还可以使用欧拉法和有限差分法迭代求解微分方程。我建议 Steven Chapra 写一本很棒的书《工程师的数值方法》详细研究这个话题。
同样,为了解决优化问题,我们也有两种方法:
- 分析方法:其中一个示例是普通最小二乘法 (OLS),由 scikit 的 LinearRegression ( https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html ) 类使用Python 中的 -learn 包和 numpy polyfit 函数。如前所述,OLS 技术给出了最佳拟合线的精确系数(斜率和截距项)。
- 迭代解决方案:解决机器学习中优化问题的最流行的迭代方法是梯度下降算法及其变体,随机梯度下降和 MiniBatch 梯度下降。深度学习中还使用了更高级的变体,例如 RMSprop、Adam、Adadelta、Adagrad、Adamax 和 Nadam(请参阅 Keras 的此网页(https://keras.io/api/optimizers/)。有几篇关于 Gradient 的文章在我们的 Analytics Vidhya 博客上下降。
除了基于 GD 的方法外,还有其他迭代方法可以解决受约束和不受约束的优化问题(请参阅 SciPy 文档页面:https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize。最小化.html )
迭代求解器还包括一类“启发式”求解器,如遗传算法、粒子群优化 (PSO)、蚁群优化 (ACO) 和其他非贪心算法,如模拟退火 (SA)。
7. 应该使用哪种方法来解决什么样的优化问题?
对于无约束最小化,您可以使用共轭梯度 (CG)、牛顿共轭梯度或 Broyden、Fletcher、Goldfarb 和 Shanno 算法 (BFGS) 的准牛顿方法、Dog-leg Trust-region 算法、牛顿共轭等方法梯度信任区域算法,或牛顿 GLTR 信任区域算法。
我需要知道这一切吗?好吧,其中一些技术用于 ML 算法!例如,scikit-learn 库的 LogisticRegression 类默认使用 BFGS 算法。
同样,对于有界和无界的约束优化问题,我们有 Nelder-Mead、有限内存 BFGS(称为 L-BFGS)、鲍威尔方法、截断牛顿共轭梯度算法、序列最小二乘规划 (SLSQP) 等算法。
8. 最后,让我们看看“优化在行动”
(A) OLS 方法:
回到我们在文章开头介绍的示例数据集,在等式中替换 Y^。3、最终的MSE损失函数如下:
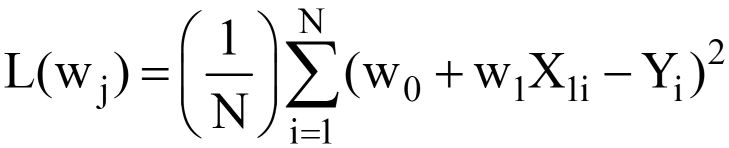
显然,L 是模型权重 (w0 & w1) 的函数,我们必须在最小化 L 时找到其最优值。最优值在下图中由 (*) 表示。
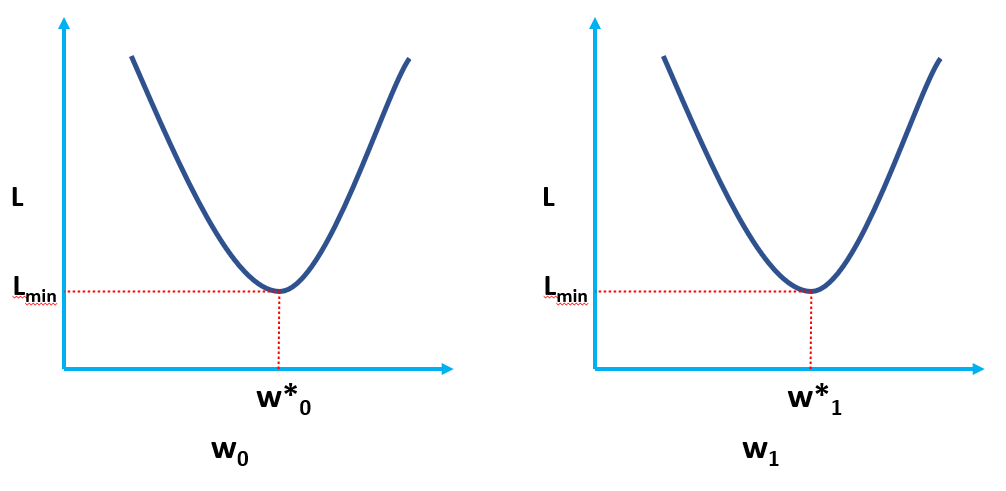
无需深入本文中的推导(计划在后续文章中),w0 和 w1 的最终最优值(其中 MSE 损失函数最小)由下式给出:
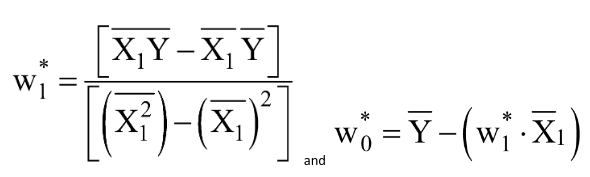
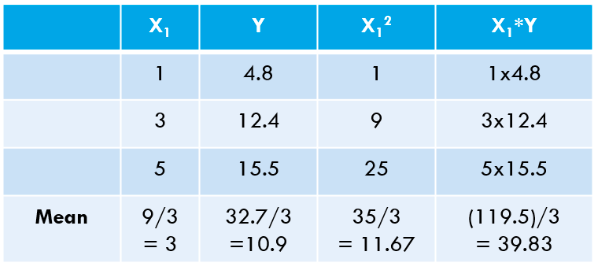
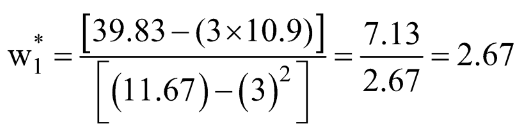
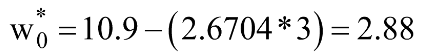
让我们使用 Python 代码进行计算:
import numpy as np
# define your X and Y as NumPy Arrays
X = np.array([1,3,5])
Y = np.array([4.8,12.4,15.5])
# np.polyfit function does a 1-dimensional Polynomial fitting
# and the np.poly1d function convers the polynomial coefficents
# into a polynomila object that can be evaluated
p = np.poly1d(np.polyfit(X,Y,1))
print(p)[OUTPUT]:
2.675 x + 2.875您可以看到我们的“手动计算”值与使用 NumPy 获得的斜率和截距值非常匹配(小的差异是由于我们手动计算中的舍入误差)。我们还可以验证相同的 OLS 是否在 scikit-learn 包中的 LinearRegression 类的“幕后运行”,如下面的代码所示。
# import the LinearRegression class from scikit-learn package
from sklearn.linear_model import LinearRegression
LR = LinearRegression() # create an instance of the LinearRegression class
# define your X and Y as NumPy Arrays (column vectors)
X = np.array([1,3,5]).reshape(-1,1)
Y = np.array([4.8,12.4,15.5]).reshape(-1,1)
LR.fit(X,Y) # calculate the model coefficientsLR.intercept_ # the bias/intercept term (w0*)
[Output]: array([2.875])LR.coef_ # the slope term (w1*)
[Output]: array([[2.675]])(B) 求解优化问题的迭代方法
让我使用第 4 节中的示例来演示这一点,我在其中定义了一个函数 fx=2*x^2 – 3*x +1 并绘制了它。如果您看到该图,似乎在 0.7 和 0.8 之间有一个最小值。
fx = λ x: 2*x**2 - 3*x + 1
从 scipy.optimize 导入最小化 x0 = 0 # 对最小值的粗略猜测(可以从最初的图中获得) 解决方案 = 最小化(fx,x0) 溶胶
输出:
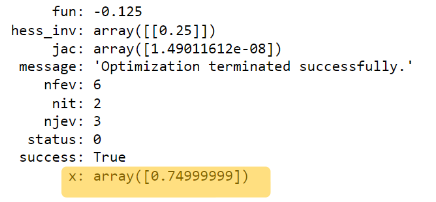
soln.x # 看到这是我们迭代求解器的“近似解”(最小值), # 反对 0.75 的理论解。 [输出]:数组([0.74999999])
您还可以看到函数在最小值处的值为 -0.125。下面使用 Nelder-Mead 方法的另一个示例代码:
soln = 最小化(fx,x0,方法='Nelder-Mead') 溶胶
输出:
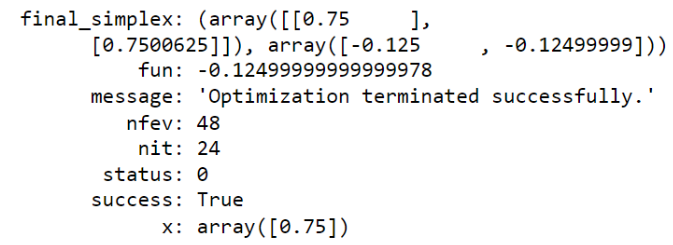
9. 机器学习和深度学习中还有哪些优化?
好的,我们现在对优化有了一个很好的想法。现在让我们看看所有这些在 ML 和 DL 中的用途。
- 线性回归使用 OLS 方法求解最优模型系数。
- 在逻辑回归中,模型系数的最优值是通过最小化 BinaryCrossEntropy Loss 函数来获得的。scikit-learn的逻辑回归类使用“solver”选项(默认值为 'lbfgs')和“max_iter”(默认值为 100)作为超参数之一。显然,sklearn 中的 LogisticRegression 类使用迭代求解器,其他支持的求解器是 'liblinear'、'sag'、'saga' 和 'newton-cg'。这些求解器的详细说明可以从:https ://stackoverflow.com/questions/38640109/logistic-regression-python-solvers-definitions
- 在支持向量机中,我们正在最小化铰链损失。scikit-learn API 中的 Python 实现使用“LIBSVM”库中的求解器(用 C 语言编码)。
- 在深度学习中,我们通常使用 MiniBatch 梯度下降算法的高级变体,例如 RMSprop、Adam、Adadelta、Adagrad、Adamax 和 Nadam(请参阅 Keras 的此网页)来训练我们的神经网络。
10. 优化的其他应用
除了数据科学领域之外,行业中的优化问题也很丰富。想象一家制造公司试图最小化制造产品的成本以最大化其利润。该总成本将是人力成本、原材料成本、库存、仓储、运输和其他物流成本的函数。此外,这些变量中的大多数都伴随着它们自己的一组约束。因此,您可以找到要制造的“最佳单元数”以具有最低的制造成本。
另一个相关的例子是在制造过程或装配单元中找到最佳的操作顺序,以使机器得到最佳使用(机器空闲时间最小化,一些没有过度使用,而其他部分则处于等待状态)。这是一个调度问题(有约束)。
调度问题的另一个例子是找到公司中员工在不同班次中执行特定任务的最佳时间表(占用和/或可用性表),以便最大限度地减少人力成本,并且可能不需要加班费。
另一个普遍存在的问题是具有容量限制的车辆路线。这更像是土木工程中的交通问题,我们必须找到最佳路线,以使交通拥堵最小化。此外,交通信号灯保持打开/关闭的时间必须是最佳的。另一个相关的例子是具有提货和交货约束的车辆路线问题,其中可能包括时间窗口约束。想想一个快递员,他的目标是每天在给定的地理位置收集和投递 20 个包裹。他/她想以最少的交通、最短的距离、最少的时间找到最佳路线,并且不想两次访问同一地点(另一个非常相似的例子是经典的旅行商问题。
化学工程师希望对用于化学反应的压力容器、锅炉和输送流体甚至储存的管道进行优化设计(形状、尺寸、直径、长度等)。
下面提到了来自不同工程学科的一些典型应用(转载自 Singiresu S. Rao 的《工程优化:理论与实践》一书的第 5 页):
1.飞机和航空航天结构的最小重量设计
2.寻找空间的最佳轨迹车辆
3.最低成本的框架、基础、桥梁、塔、烟囱、大坝等土木工程结构设计
4.抗震、抗风等随机荷载结构的最小重量设计
5.水资源设计最大效益的系统
6.结构的最佳塑料设计
7.连杆、凸轮、齿轮、机床和其他机械部件的优化设计
8.金属切削工艺中加工条件的选择以最小化生产成本
9.物料搬运设备的设计,例如输送机、卡车和起重机,以最小化成本
10.泵、涡轮机和传热设备的设计以实现最大效率
11.电机、发电机和变压器等电机的优化设计
12.电网的优化设计
13.销售人员走访各个城市时采取的最短路线
14.最佳生产计划、控制和调度
15分析统计数据并根据实验结果建立经验模型,以获得最准确的物理现象表示
16.化学加工设备和工厂的优化设计
17.流程工业的最佳管道网络设计
18.行业选址
19.计划维护和更换设备以降低运营成本
20.库存控制
21.在多个活动之间分配资源或服务以最大化收益
22.控制等待和空闲时间以及生产线的排队以降低成本
23.规划最佳策略以在存在竞争对手的情况下获得最大利润
24.控制系统的优化设计
结论
有几个 Python 包可以解决优化问题,如 CPLEX、DOCPLEX、PULP、PYOMO、ORTOOLS、PICOS、CVXPY、GUROBI、LOCALSOLVER 等。我希望这篇文章有足够的动力来深入研究优化的概念和应用。更多内容将在后续文章中讨论。
原文标题:Optimization Essentials for Machine Learning
原文作者:Prashant Sahu
原文地址:https://www.analyticsvidhya.com/blog/2022/10/optimization-essentials-for-machine-learning/

{kind=link}