




曾几何时,在数据技术这个领域,大家都在追求如何更好地解决大数据的问题。从Hadoop到Spark和Snowflake,然后又有clickhouse等等一众产品都在解决大规模数据的计算更快的问题。
然而,这些技术再怎么创新,都是需要大规模并行处理来解决大数据的计算问题。带来的结果就是为了完成这些计算,用户不得不付出昂贵的计算成本。
在如今激烈竞争的环境中,企业无论大小,都越来越重视数据对自己企业运营效率的提升,数据驱动的运营已经变成了很多企业的日常。也正是因为需求端的改变,也促进了现代数据技术栈的产生。
但是随着企业使用数据的场景的增多,很多企业也发现使用现代数据技术栈中的云端数据仓库面临这个成本显著增高而且不可控的情况。究其原因,实际上很多企业的日常运营所需要处理和分析的数据规模并不是大数据,但是现在的云端数据仓库平台都是针对大规模数据计算进行设计的。下图是我们最近在Google Survey上关于用户使用数据规模的一个调研的结果:
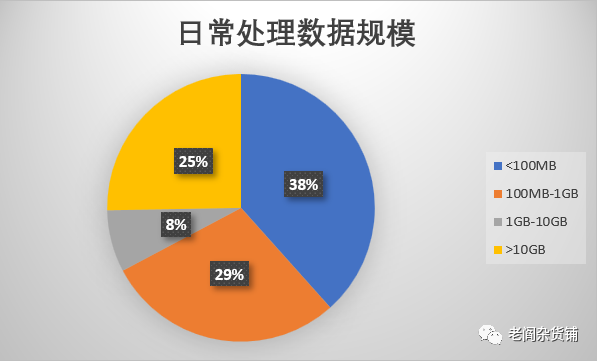
从这张图我们可以看到,日常处理数据大于10GB这个量级的占比仅仅1/4。也就是说,有3/4的数据相关日常运营型的数据规模都小于10GB。
而对于这个规模的数据,完全就不需要目前的大规模并行处理计算的技术。如果设计合理,单机内存就非常好的可以处理。并且因为是单机处理,又能避免大规模并行处理的网络序列化的各种开销,处理速度也更好,因此能够让使用者更快速地得到结果。
最近比较火热的嵌入式内存OLAP数据库DuckDB就是在这种规模的数据上实现OLAP的一个新型数据库。接下来我们就来了解这个数据库领域的小清新。
DuckDB简介

最初了解到DuckDB是去年决定自己开发QuickTable的内存引擎之前。因为从我们定义的场景看,我们需要一个在进程内能够高速地处理数据的引擎。为了这个需求,我们首先想到的是看看开源领域有没有可以被使用的产品。因此就搜索到了DuckDB,因为DuckDB本身就是设计为一个进程内的数据库。不过由于我们的产品侧重在进行数据的清洗、转换和处理,而DuckDB则侧重在多维分析,因此没有选择DuckDB。不过DuckDB的设计理念还是让我感觉到耳目一新。尤其是现在大量的数据库产品都在追求大,DuckDB则追求的是在一定规模的数据上,能够更快速的实现多维分析。在现在云原生成为主流的情况下,对于很多场景来讲无疑有其独特的价值。
我们先看看DuckDB的官网的描述:

这一句话清晰的把DuckDB自己的定位做了描述,是一款进程内的面向OLAP场景的SQL数据库管理系统。
在DuckDB之前,我们知道的最出名的进程内数据库系统是SQLite。不过SQLite是OLTP数据库,比较适合给一些业务类型的应用提供进程内数据的增删改查。实际上很多运行在移动端应用程序就是采用SQLite来作为自己的数据库进行业务数据的存储。
不过随着数据的分析型的需求越来越多,针对OLTP设计的SQLite显然很难适应这种分析型的需求。而DuckDB就是为了满足这种需求而设计产生的。
DuckDB由来自荷兰的Mark Rassveldt博士和Hannes Mühleisen博士主导进行开发。两个人目前都在荷兰阿姆斯特丹的荷兰国家数学与计算机科学研究中心(CWI)进行博士后研究。大名鼎鼎的python语言就是这个研究中心在90年代设计开发的。在这个研究中心,也孵化出来了非常多的高科技公司,如下图:

在计算机这个领域,我个人还是非常喜欢产学研结合能力非常强的研究机构的。CWI是一个,我们前面提到的伯克利也是一个。
DuckDB技术体系
DuckDB的核心代码是采用C++11进行开发的,其引擎没有任何其他的依赖。因此可以非常方便地作为进程内的数据库被嵌入到进程中去使用。
为了支持SQL,DuckDB的SQLParser继承于PostgreSQL。另外,为了方便SQLite的用户使用,DuckDB提供了SQLite的兼容层。这样使用SQLite的用户仅仅需要重新链接DuckDB的库就能使用DuckDB了。
因为DuckDB的目标是OLAP场景,因此与当前所有的主流的OLAP数据库系统一样,DuckDB采用了向量化计算的技术,这样就可以充分利用CPU的SIMD技术。
另外,DuckDB通过MVCC技术,从而能够支持ACID的一致性。从这个角度看,DuckDB自己本身就是OLTP和OLAP都能支持的HTAP系统。
DuckDB内部采用DataBlocks存储结构,一种兼顾OLTP和OLAP的压缩存储结构。但是DuckDB可以读取CSV,parquet等等文件结构。
DuckDB发展现状
DuckDB最近发展的非常的迅速,目前已经有6380个star,并且有603个fork.从代码贡献的节奏看,也是非常活跃:
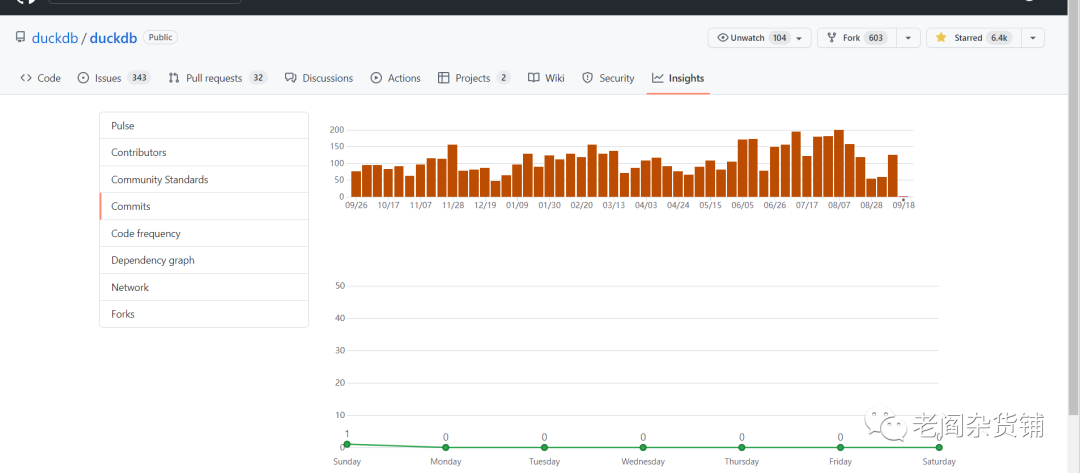
到今天为止DuckDB已经有148个贡献者,被253个项目使用。
目前DuckDB项目由DuckDB基金会进行支持,而在DuckDB的基金会中,我们可以看到Mode, Hex等公司的身影。

其中Mode是在云上做BI的公司,Hex同样是新型的云端协同BI的企业。对于BI场景来讲,DuckDB还是非常匹配的。Voltron Data则是Apache Arrow的主导公司。从这个角度看,DuckDB已经被大家越来越多地认可。而在twitter上,我也能看到不少人在讨论DuckDB。
总结
随着使用数据的场景越来越多,数据支撑运营的场景也越来越多。很多情况下,数据驱动运营需要的是近期的热数据,而不是长时间的数据。大数据在某些场景下有它独有的价值,但是很多情况下,快速的在一定规模的数据上去处理、分析才可能是常态。而云原生让单个容器中快速完成相关的工作成为可能,而DuckDB无疑就非常适合这个场景中去进行多维分析。我们在做的QuickTable也是在这个场景中去进行数据的清洗、转换和建模。考虑到DuckDB的发展状况,我在思考我们的内存引擎是否可以和DuckDB进行结合?这是我们后续可以技术上去探索的地方。
