




这是专门讨论 MySQL 趋势的系列文章的第二篇。
正如我之前所写,了解您的工作量并观察其随时间的演变有助于在故障之前预测问题并制定解决方案。
本文介绍了MySQL 历史列表长度,也称为 HLL。
MySQL History List 与 InnoDB Undo Logs 相关。InnoDB是一个多版本存储引擎(MVCC)。它保留有关已更改行的旧版本的信息,以支持并发和回滚等事务功能。此信息存储在称为回滚段的数据结构中的撤消表空间中。
这意味着即使数据被其他事务更改,您也可以启动事务并继续看到一致的快照。此行为与隔离级别有关。默认情况下,在 MySQL 中,事务隔离是REPEATABLE-READ:
SQL> show global variables like '%isola%';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
为了提供这种隔离,InnoDB 需要保留被修改的旧版本的行,直到仍然有一个事务打开。
所有这些更改都保存在指向同一行的先前版本的链接列表中,该列表本身指向同一行的先前版本,等等……这意味着每次更新一行时,在新事务中,旧版本被复制到相应的回滚段,并带有指向它的指针。
然后每一行都有一个 7 字节的DB_ROLL_PTR字段,称为滚动指针。滚动指针指向写入回滚段的撤消日志记录。如果行已更新,则撤消日志记录包含在更新之前重建行内容所需的信息。
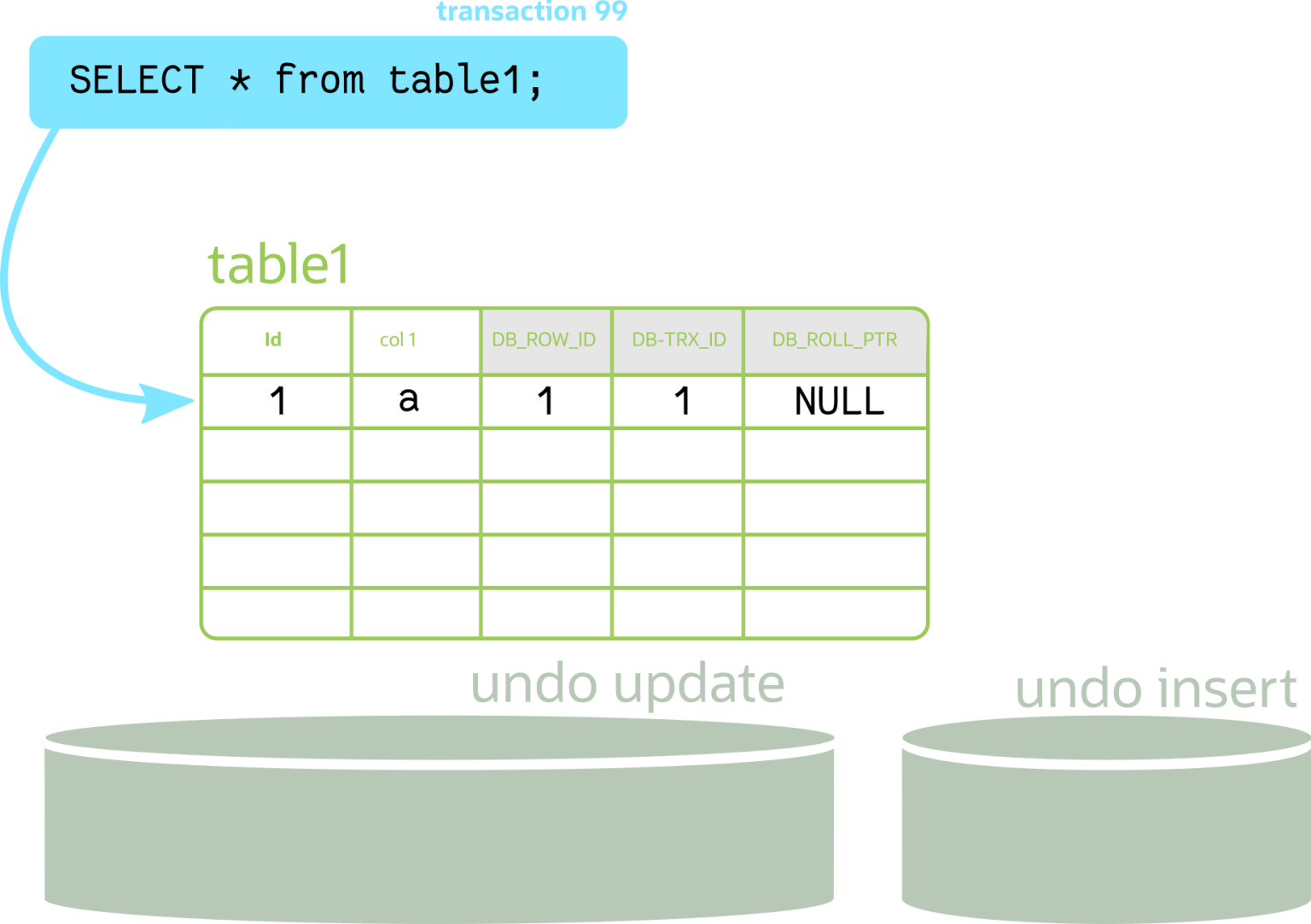
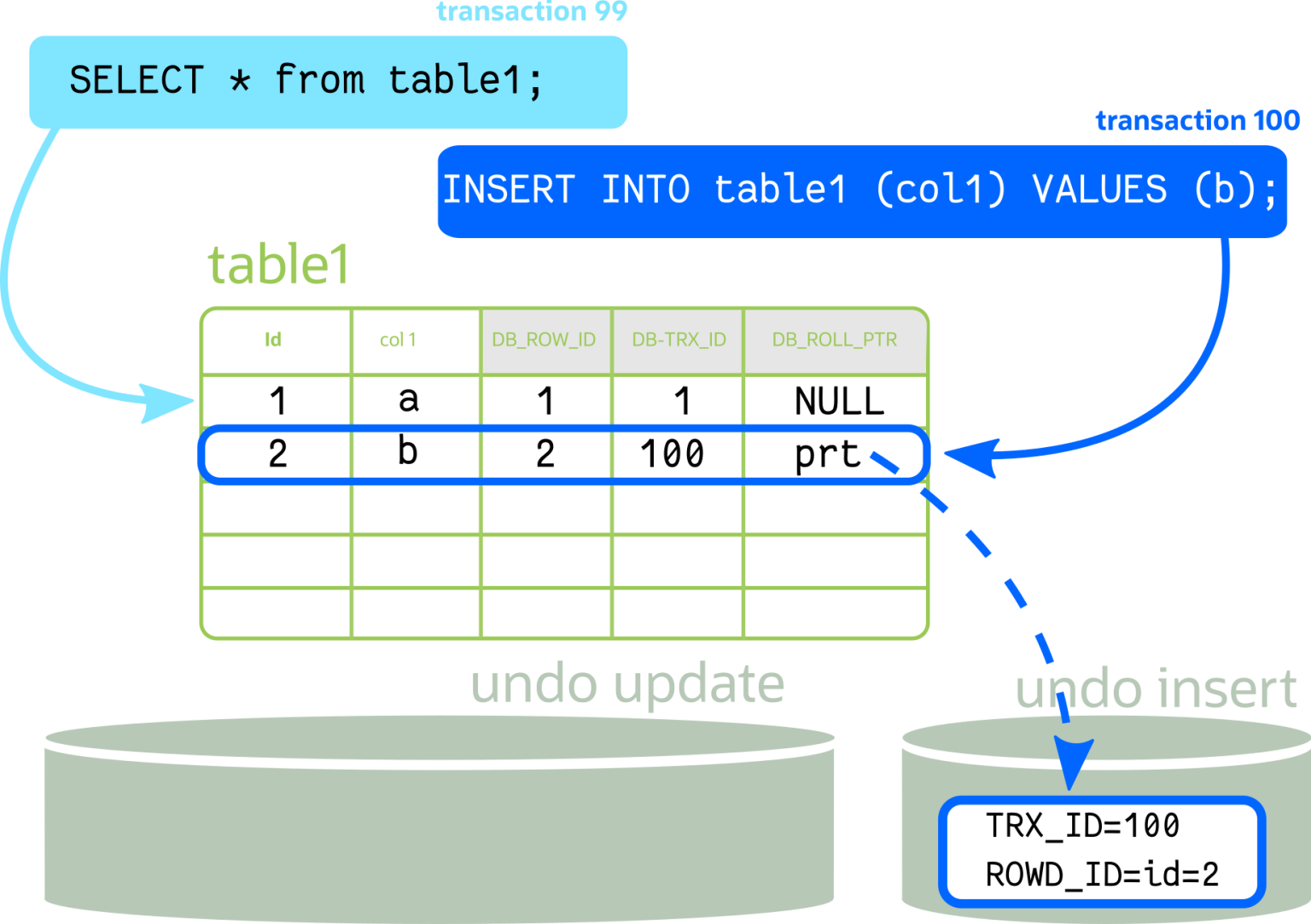
在上图中,第二笔交易 (tx 100) 插入了一条记录。默认情况下 ( REPEATABLE_READ),第二行在 trx 99 中不可见(该行的 TRX_ID 大于 99)。
现在,当数据更新时,更改也保留在撤消更新中:
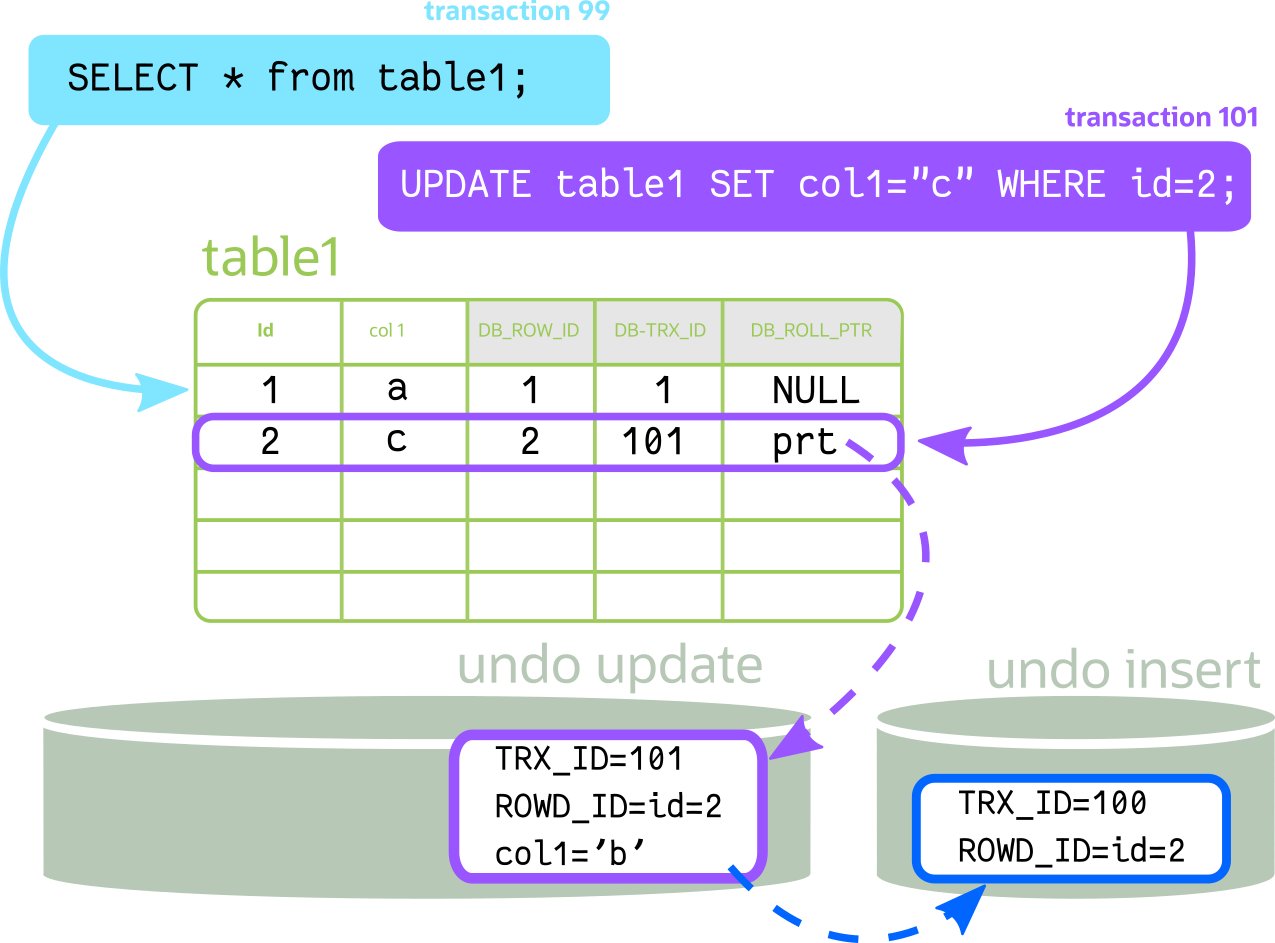
这会不断增加,直到撤消段未被清除
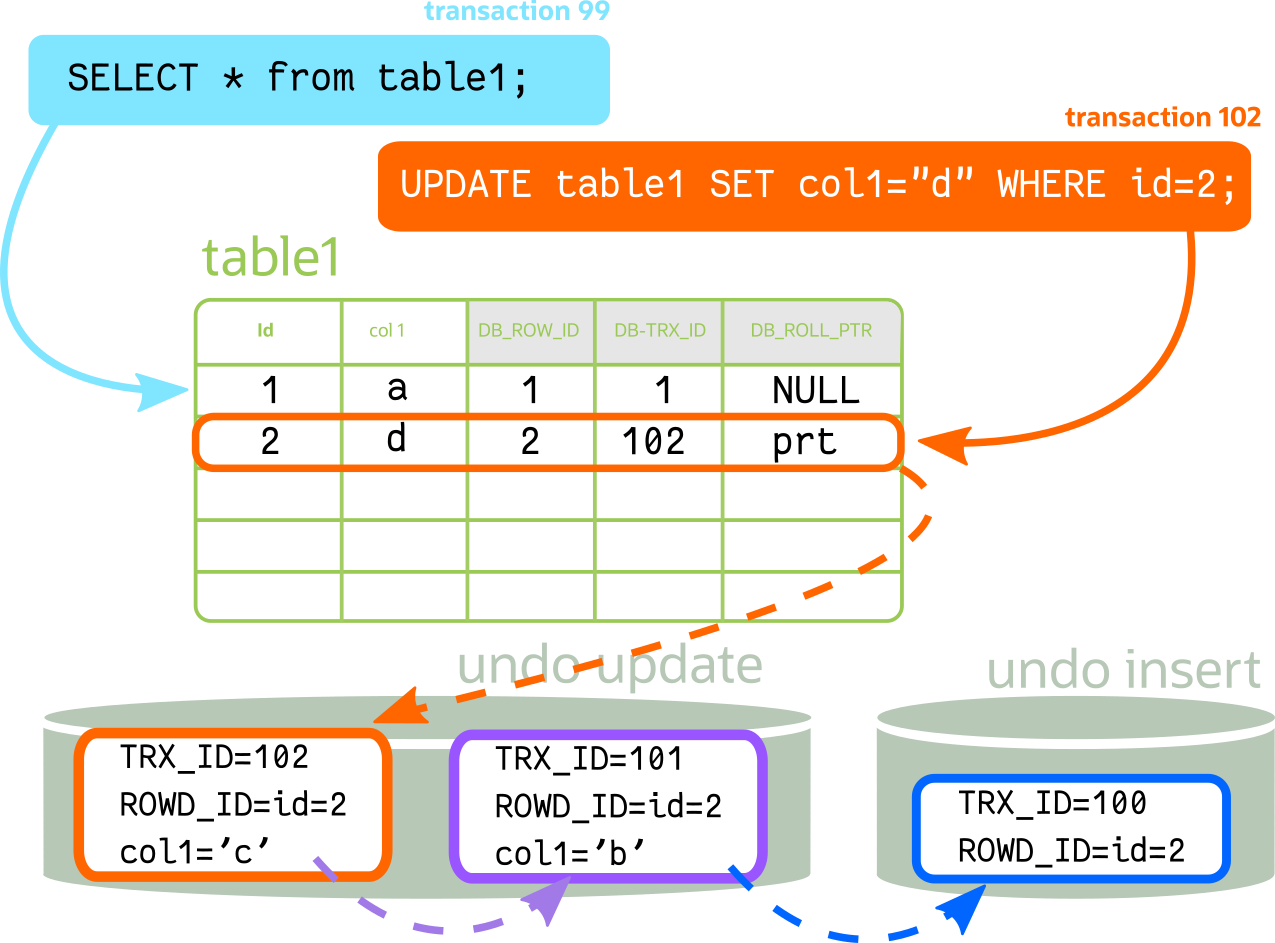
这是关于它在 InnoDB 中如何工作的高级说明。
历史列表长度量化了更改的数量(包含预览更改的记录数量)。
如果记录包含大量版本,则在最旧的事务中检索值可能需要更长的时间。
在 MySQL 手册中,我们可以看到:回滚段中的撤消日志分为插入和更新撤消日志。仅在事务回滚时才需要插入撤消日志,并且可以在事务提交后立即丢弃。更新撤消日志也用于一致读取,但只有在不存在已为其分配快照的事务存在后才能丢弃它们InnoDB,在一致读取中可能需要更新撤消日志中的信息来构建数据库的早期版本行。
阅读这些行,我们可以理解,如果我们有一个很长的事务(甚至是非活动的),它访问了一些未被任何其他事务使用的行,这不会影响历史列表……事实并非如此!
启用后,这些指标在INFORMATION_SCHEMA.INNODB_METRICS表中可用或在以下输出中可用SHOW ENGINE INNODB STATUS\G:
MySQL> select * from INFORMATION_SCHEMA.INNODB_METRICS
where name='trx_rseg_history_len'\G
*************************** 1. row ***************************
NAME: trx_rseg_history_len
SUBSYSTEM: transaction
COUNT: 8319
MAX_COUNT: 92153
MIN_COUNT: 7
AVG_COUNT: NULL
COUNT_RESET: 8319
MAX_COUNT_RESET: 92153
MIN_COUNT_RESET: 7
AVG_COUNT_RESET: NULL
TIME_ENABLED: 2022-05-25 10:23:17
TIME_DISABLED: NULL
TIME_ELAPSED: 135495
TIME_RESET: NULL
STATUS: enabled
TYPE: value
COMMENT: Length of the TRX_RSEG_HISTORY list
MySQL> show engine innodb status\G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2022-05-27 00:01:46 139760858244672 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 43 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 4146 srv_active, 0 srv_shutdown, 76427 srv_idle
srv_master_thread log flush and writes: 0
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 5954
OS WAIT ARRAY INFO: signal count 60629
RW-shared spins 0, rounds 0, OS waits 0
RW-excl spins 0, rounds 0, OS waits 0
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 0.00 RW-shared, 0.00 RW-excl, 0.00 RW-sx
------------
TRANSACTIONS
------------
Trx id counter 903438
Purge done for trx's n:o < 883049 undo n:o < 0 state: running but idle
History list length 9746
趋势图
让我们看一下这张图:
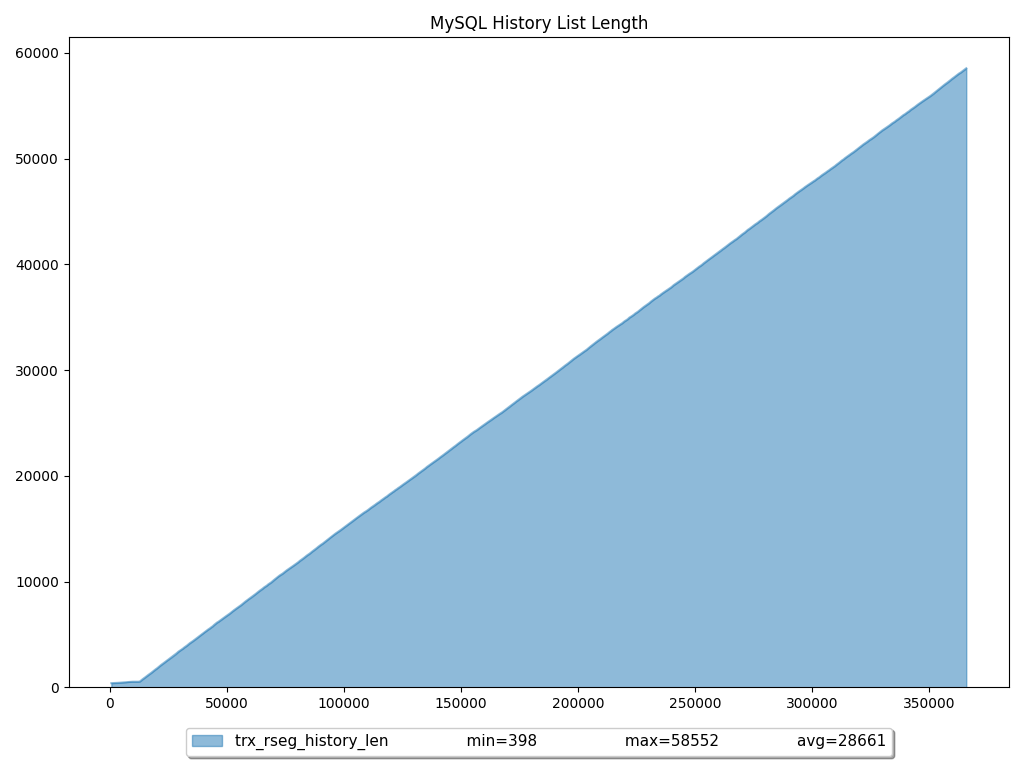
我们可以看到 History List Lengt ( trx_rseg_history_len) 是线性增加的……但工作量不是:
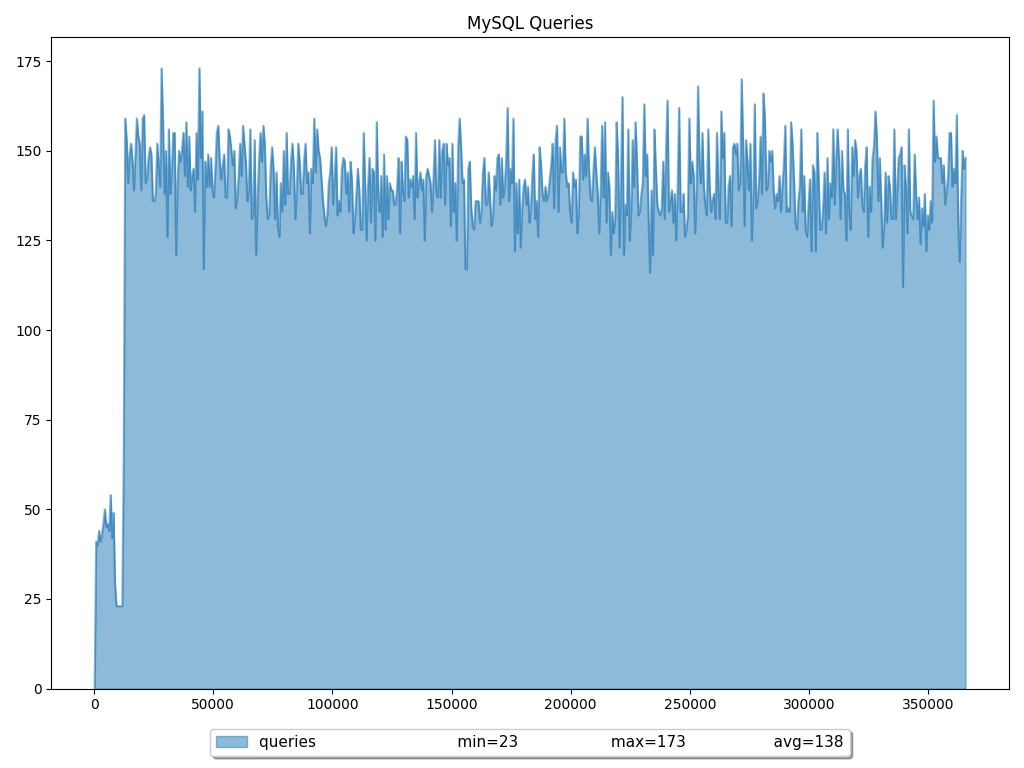
当 HLL 在一段时间内显着增加时,这意味着 InnoDB 保留了大量旧行版本而不是清除它们,因为一个或多个长时间运行的事务尚未提交或被放弃而没有回滚。
在 MySQL 中启动一个事务然后执行一个简单的SELECT启动所有这个 MVCC 机制。
Daniel Nichter 在他的书 Efficient MySQL Performance 中解释说,正常值innodb.trx_rseg_history_len小于 1,000。如果超过 100,000,则可能会出现问题,应发送警报。
让我们再看看接下来 10 分钟的历史列表长度:
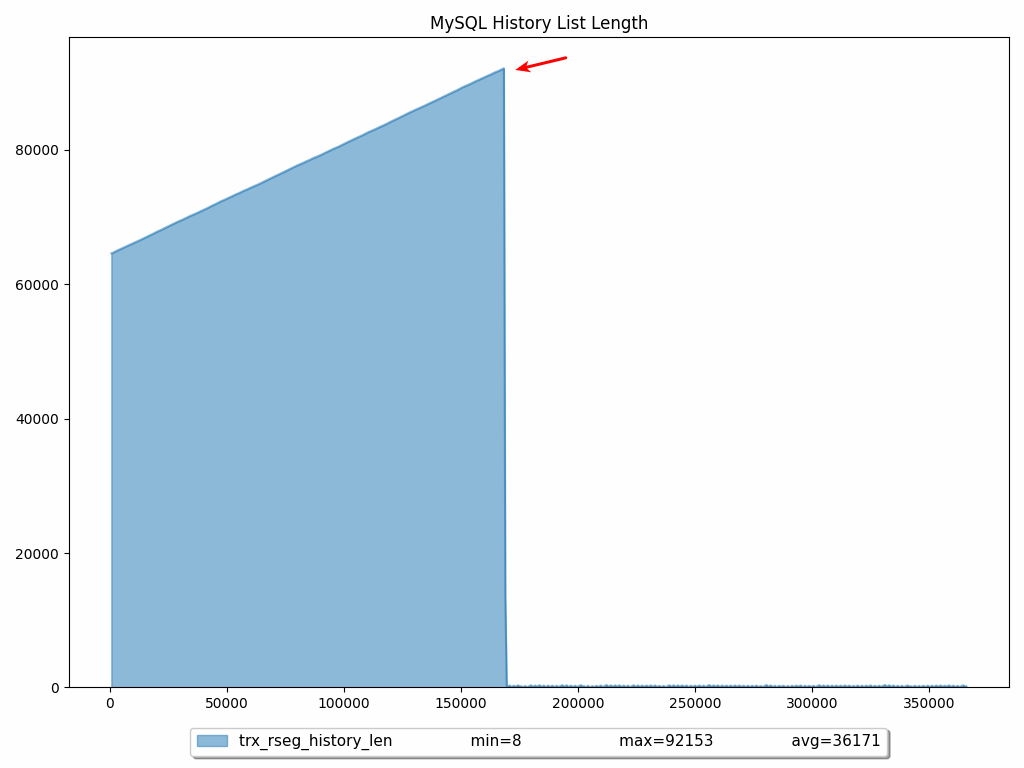
我们可以看到,一旦我们停止了一个保持打开(休眠)的事务,几乎立即就解决了!
工作负载是 sysbench OLTP 插入(不使用employees数据库),我们使用数据库创建了一个长事务employees。这份长长的交易声明是:
MySQL> start transaction;
MySQL> select * from employees.titles limit 10;
+--------+-----------------+------------+------------+
| emp_no | title | from_date | to_date |
+--------+-----------------+------------+------------+
| 10001 | Senior Engineer | 1986-06-26 | 9999-01-01 |
| 10002 | Staff | 1996-08-03 | 9999-01-01 |
| 10003 | Senior Engineer | 1995-12-03 | 9999-01-01 |
| 10004 | Engineer | 1986-12-01 | 1995-12-01 |
| 10004 | Senior Engineer | 1995-12-01 | 9999-01-01 |
| 10005 | Senior Staff | 1996-09-12 | 9999-01-01 |
| 10005 | Staff | 1989-09-12 | 1996-09-12 |
| 10006 | Senior Engineer | 1990-08-05 | 9999-01-01 |
| 10007 | Senior Staff | 1996-02-11 | 9999-01-01 |
| 10007 | Staff | 1989-02-10 | 1996-02-11 |
+--------+-----------------+------------+------------+
10 rows in set (0.0002 sec)
MySQL> We did nothing for 10 minutes
MySQL> rollback;
下图表示在 10 分钟 sysbench OLT 读/写中间 4 分钟的相同事务空闲:
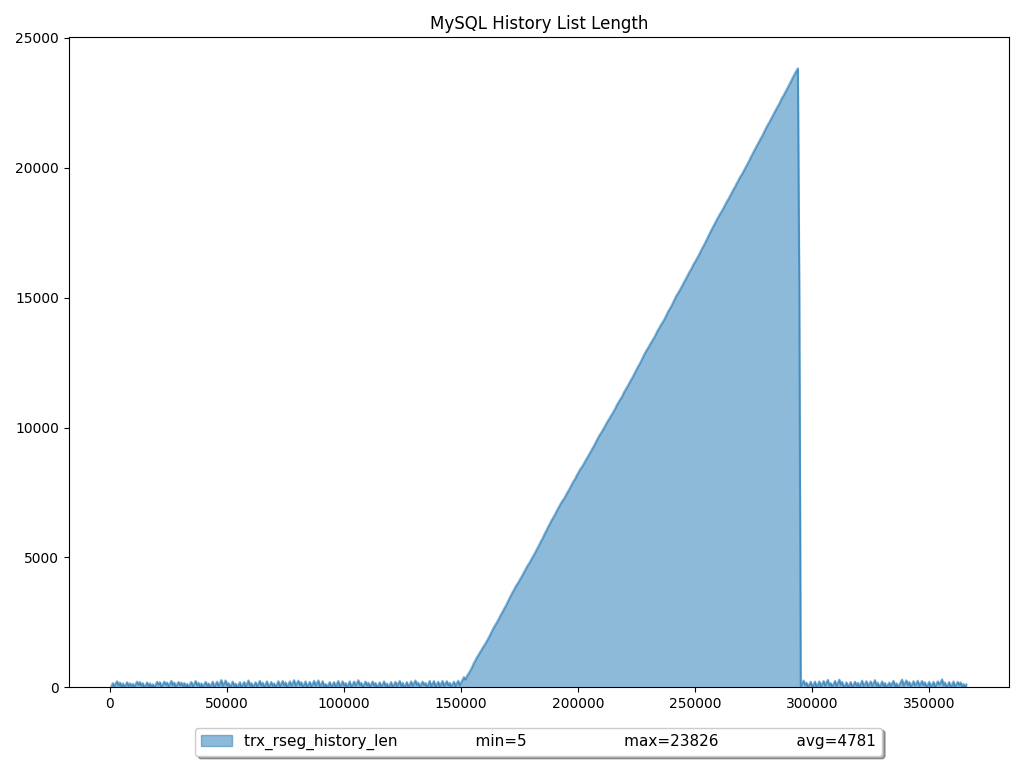
大型 HLL 的真正含义是什么?
历史列表长度增加的原因是InnoDB Purge 活动滞后!
清除线程负责清空和截断撤消表空间(参见手册)。
清除过程中出现这种滞后的原因是什么?
写入活动太高,清除无法尽快处理
长时间运行的事务正在阻止清除,并且在事务完成之前清除不会进行
我们稍后会看到如何处理这个问题,但首先,让我们看看性能。
性能表现
即使 HLL 不会直接影响性能,当需要遍历许多版本的行时,它也可能会出现问题。
让我们通过上面的示例来看看这种行为。如果我们在启动将要打开(放弃)的长事务时执行以下SELECT操作,请注意 HLL 的大小和执行时间:
MySQL> SELECT id, k, (
SELECT count FROM information_schema.innodb_metrics
WHERE name='trx_rseg_history_len') HLL
FROM sbtest.sbtest1 WHERE c LIKE '36%' LIMIT 10;
+-----+-------+-----+
| id | k | HLL |
+-----+-------+-----+
| 10 | 34610 | 98 |
| 288 | 561 | 98 |
| 333 | 54800 | 98 |
| 357 | 96142 | 98 |
| 396 | 82983 | 98 |
| 496 | 65614 | 98 |
| 653 | 38837 | 98 |
| 684 | 61922 | 98 |
| 759 | 8758 | 98 |
| 869 | 50641 | 98 |
+-----+-------+-----+
10 rows in set (0.0006 sec)
如果我们稍后在同一个事务中再次尝试(我们没有回滚或提交它),同样的查询我们会注意到一些不同的东西:
MySQL> SELECT id, k, (
SELECT count FROM information_schema.innodb_metrics
WHERE name='trx_rseg_history_len') HLL
FROM sbtest.sbtest1 WHERE c LIKE '36%' LIMIT 10;
+-----+-------+--------+
| id | k | HLL |
+-----+-------+--------+
| 10 | 34610 | 391836 |
| 288 | 561 | 391836 |
| 333 | 54800 | 391836 |
| 357 | 96142 | 391836 |
| 396 | 82983 | 391836 |
| 496 | 65614 | 391836 |
| 653 | 38837 | 391836 |
| 684 | 61922 | 391836 |
| 759 | 8758 | 391836 |
| 869 | 50641 | 391836 |
+-----+-------+--------+
10 rows in set (1.9848 sec)
当历史列表长度很大时,查询现在要慢得多。
正如Jeremy Cole 的这篇优秀文章中所解释的,在写入繁重的数据库中,具有较大的历史列表长度可能需要将大量行的版本恢复为非常旧的版本。这将减慢事务本身的速度,在最坏的情况下,可能意味着写入繁重的数据库中运行时间很长的查询永远无法真正完成;他们运行的时间越长,他们的读取成本就越高。
拥有较大的 HLL 意味着撤消日志也会增加。使用 MySQL 8.0,您可以更好地控制 Undo Log 表空间(参见手册),但您仍然需要监控您的磁盘空间!
解决方案
如果 HLL 正在增长,第一步是确定系统正在经历上述两个原因中的哪一个。
清除无法跟随大量写入
如果清除线程无法跟上写入工作负载,则有必要限制写入活动。
在 MySQL 8.0 中,可以为 InnoDB 配置最大清除延迟:innodb_max_purge_lag.
当清除滞后超过阈值时,会对和操作innodb_max_purge_lag施加延迟INSERT,以使清除操作有时间赶上。UPDATEDELETE
在一些非常罕见的情况下延迟变得太高,这就是为什么你也可以使用innodb_max_purge_lag_delay.
另一个与 InnoDB 的 Purge 相关的可调设置是innodb_purge_threads表示专用于 Purge 操作的后台线程的数量。
没有理想的数字可以推荐,像往常一样,这取决于😉
手册很好地解释了这一点:
如果innodb_max_purge_lag超出设置,清除工作会自动在可用的清除线程之间重新分配。在这种情况下,过多的活动清除线程可能会导致与用户线程的争用,因此请innodb_purge_threads相应地管理设置。
如果 DML 操作集中在少数表上,请将innodb_purge_threads设置保持在较低水平,以便线程不会相互争用对繁忙表的访问。如果 DML 操作分布在许多表中,请考虑更高的innodb_purge_threads设置。清洗线程的最大数量为 32。
该innodb_purge_threads设置是允许的最大清除线程数。清洗系统会自动调整使用的清洗线程数。
长时间运行查询
如前所述,长时间运行的事务,即使是休眠/停滞的事务,都会阻塞清除,无论写入工作量如何,即使它非常低,HLL 将在该事务的整个生命周期内继续增长。
解决此问题的唯一方法是停止那些长事务(提交、回滚、终止)。
要查找此类长时间运行的事务,Performance_Schema可以使用以下查询:
MySQL> SELECT ROUND(trx.timer_wait/1000000000000,3) AS trx_runtime_sec,
format_pico_time(trx.timer_wait) AS trx_runtime,
processlist_id, trx.thread_id AS thread_id,
trx.event_id AS trx_event_id, trx.isolation_level,
trx.autocommit, stm.current_schema AS db,
stm.sql_text AS query,
stm.rows_examined AS rows_examined,
stm.rows_affected AS rows_affected,
stm.rows_sent AS rows_sent,
IF(stm.end_event_id IS NULL, 'running', 'done') AS exec_state,
ROUND(stm.timer_wait/1000000000000,3) AS exec_time
FROM performance_schema.events_transactions_current trx
JOIN performance_schema.events_statements_current stm USING (thread_id)
JOIN threads USING (thread_id)
WHERE trx.state = 'ACTIVE' AND trx.timer_wait > 1000000000000 * 1\G
*************************** 1. row ***************************
trx_runtime_sec: 1040.443
trx_runtime: 17.34 min
processlist_id: 107
thread_id: 147
trx_event_id: 73
isolation_level: REPEATABLE READ
autocommit: NO
db: sbtest
query: select * from employees.titles limit 10
rows_examined: 10
rows_affected: 0
rows_sent: 10
exec_state: done
exec_time: 0.000
1 row in set (0.0004 sec)
如果状态和查询在多次运行之间没有变化,则可以将查询视为停止或放弃。DBA 应该采取行动并杀死它。
隔离级别也会影响这一点,我建议使用READ-COMMITTED而不是默认级别,REPEATABLE-READ因为它有助于减少 HLL。
实际上,使用READ-COMMITTED,为每个 SQL 语句生成一个新的读取视图,并且仅在其持续时间内保持活动状态,而不是REPEATABLE-READ读取视图的生命周期与整个事务相关联。这意味着,在REPEATABLE-READ前面的示例中,如果您启动事务并执行一次 SELECT 并去喝杯咖啡,您仍然会阻止撤消日志清除,但是READ-COMMITTED一旦查询完成,撤消日志清除不会更长的阻塞。
总是READ-COMMITTED更好?
DimitriK 指出,正如他在这篇文章READ-COMMITTED中解释的那样,还有一些警告。这是您需要探索的东西,并且可能仅针对那些长事务的会话更改隔离级别,如果您能负担得起脏读,最终会使用它。READ-UNCOMMITTED
回收 Undo Log 的磁盘空间
在 MySQL 8.0 中,我们有两种截断 undo 表空间以回收磁盘空间的方法,它们可以单独使用或组合使用来管理 undo 表空间大小。
第一种方法是通过启用自动启用innodb_undo_log_truncate的,现在默认启用。
第二种是手动的,使用 SQL 语句,DBA 可以将 undo log 表空间标记为innactive。允许在该特定表空间中使用回滚段的所有事务完成。事务完成后,清除系统释放 undo 表空间中的回滚段,然后将其截断为其初始大小,并且 undo 表空间状态从inactive变为empty。
始终需要两个撤消日志,因此当您将撤消日志表空间设置为非活动时,您必须至少有 3 个活动的(包括设置为非活动的)。
手动 SQL 语法是:
MySQL> ALTER UNDO TABLESPACE tablespace_name SET INACTIVE;
可以通过运行以下查询列出撤消日志表空间及其状态:
MySQL> SELECT NAME, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES
WHERE row_format='undo' ;
+-----------------+--------+
| NAME | STATE |
+-----------------+--------+
| innodb_undo_001 | active |
| innodb_undo_002 | active |
+-----------------+--------+
还有一些与 Undo Tablespaces 相关的状态变量:
MySQL> SELECT * FROM global_status WHERE variable_name
LIKE 'Innodb_undo_tablespaces%';
+----------------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+----------------------------------+----------------+
| Innodb_undo_tablespaces_total | 2 |
| Innodb_undo_tablespaces_implicit | 2 |
| Innodb_undo_tablespaces_explicit | 0 |
| Innodb_undo_tablespaces_active | 2 |
+----------------------------------+----------------+
以上输出是 MySQL 8.0 的默认输出。如果我们想设置 inactive innodb_undo_001,这是我们将得到的错误:
ERROR 3655 (HY000): 无法将 innodb_undo_001 设置为非活动状态,因为那里
将少于 2 个未激活的撤消表空间
所以我们需要先使用以下语法创建另一个:
MySQL> CREATE UNDO TABLESPACE my_undo_003 ADD DATAFILE 'my_undo_003.ibu';
Query OK, 0 rows affected (0.47 sec)
在文件系统上,我们可以看到新添加的表空间:
[root@imac ~]# ls /var/lib/mysql/*undo* -lh
-rw-r----- 1 mysql mysql 16M 5 月 31 日 20:13 /var/lib/mysql/my_undo_003.ibu
-rw-r----- 1 mysql mysql 32M 5 月 31 日 20:12 /var/lib/mysql/undo_001
-rw-r----- 1 mysql mysql 32M 5 月 31 日 20:13 /var/lib/mysql/undo_002
现在我们可以将其设置为非活动状态:
mysql> ALTER UNDO TABLESPACE innodb_undo_001 SET INACTIVE;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT NAME, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES
WHERE row_format='undo' ;
+-----------------+--------+
| NAME | STATE |
+-----------------+--------+
| innodb_undo_001 | empty |
| innodb_undo_002 | active |
| my_undo_003 | active |
+-----------------+--------+
3 rows in set (0.00 sec)
当为空时,我们可以将其设置回活动状态,如果需要,我们还可以像这样删除多余的:
MySQL> ALTER UNDO TABLESPACE my_undo_003 SET INACTIVE;
Query OK, 0 rows affected (0.00 sec)
MySQL> DROP UNDO TABLESPACE my_undo_003;
Query OK, 0 rows affected (0.01 sec)
MySQL> SELECT NAME, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES
WHERE row_format='undo' ;
+-----------------+--------+
| NAME | STATE |
+-----------------+--------+
| innodb_undo_001 | active |
| innodb_undo_002 | active |
+-----------------+--------+
2 rows in set (0.00 sec)
结论
您现在了解为什么监视 InnoDB 历史列表长度很重要,如果它增加太多,请确定清除是否无法处理写入工作负载,或者某些长事务是否完全阻塞了 InnoDB 清除。
另一种方法是手动的,使用 SQL 语句执行。
原文标题:A graph a day, keeps the doctor away ! – MySQL History List Length
原文作者:LEFRED
原文地址:https://lefred.be/content/a-graph-a-day-keeps-the-doctor-away-mysql-history-list-length/
