




介绍
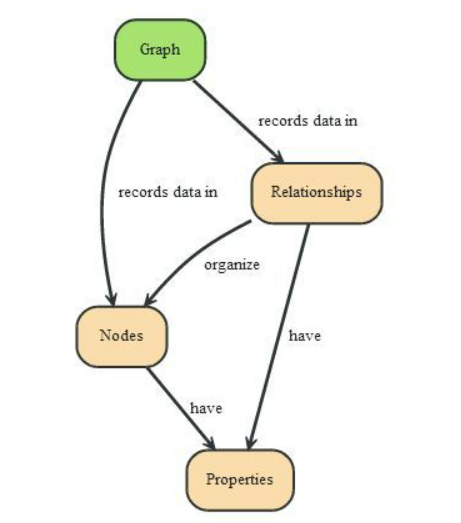
图形数据库是一个专门的、独一无二的平台,用于创建和操作图形。图具有节点、边和属性,这些属性以关系数据库无法实现的方式表示和存储数据。
另一个常用的术语是图形分析,它是指以数据点为节点,以关系为边,以图形格式分析数据。图形分析需要能够支持图形格式的数据库。它可以是专用图或支持多种数据模型(包括图)的融合数据库。
什么是图?
计算上下文中的图由两个元素组成:节点和关系。每个节点代表一个实体,例如人、地点、事物、类别或数据。这种通用结构使您能够对各种场景进行建模,从道路系统到建筑物网络。
从设备到人群的病史,关系决定了一切。例如,以 Twitter 为例,它拥有 3000 万用户并且仍在增长。该图像描绘了一个图表。
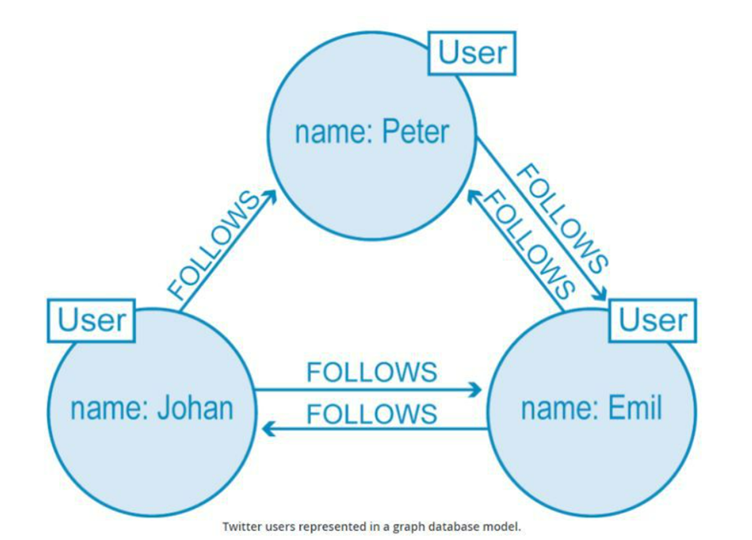
来源——codingnote.cc
尽管 Leonhard Euler 在著名的柯尼斯堡桥问题的解决方案中介绍了图的基本原理,但将问题抽象为边(关系)和数字(节点)激起了数学家对使用这种直观方法解决复杂问题的兴趣。
它现在是最复杂的数学分支之一。
什么是图数据库?
顾名思义,图数据存储是任何使用基本图原理以节点和关系的形式存储和处理数据的数据库。关系在图形数据存储中优先。因此,模式和实际数据紧密耦合。图形数据存储的灵活性使其能够轻松添加新的域对象、关系和属性,而不会影响现有设置。
图形数据库的数据模型比关系数据库或其他NoSQL 数据库更简单、更具表现力. 在图的领域,关系是一等公民,整个系统围绕着存储、维护和遍历关系的效率展开。在充满互连数据的现实世界中,图数据存储提供了一个框架和范式,可以直观地模仿语义关系。
来源——codingnote.cc
从技术上讲,原生图形数据库与其他数据库的不同之处在于以下方面:
图存储
图数据库的存储针对存储节点和关系进行了高度优化。例如,图形数据存储在 Neo4J 中的存储文件中,每个存储文件都包含图形特定部分的数据,例如节点、关系、标签和属性。这种划分存储的方法允许高性能的图遍历。本机图形存储从头开始设计用于处理高度互连的数据集,使其成为存储和检索互连数据的最有效方法。
图 2:原生图存储 (Neo4J) 的概念图。请注意,API 和事务管理直接构建在磁盘存储上,速度快如闪电。
图处理引擎
图形引擎使用高度优化的存储,连接的节点在物理上相互指向。这被称为“无索引邻接”。在无索引邻接世界中的数据加载期间,每个节点存储相邻节点的指针(RAM 位置)。因此,不需要额外的地址解析。
在上图中,我们可以直接从 A 到 B。但是,在 RDBMS 或 NoSQL 中,地址是在运行时使用第三方索引解析的,使其成为查询时间变量。因此,要从 C 到 D,我们必须首先使用索引分辨率确定 D 所在的位置,然后继续到 D。
为什么要使用图形数据库?
图形数据存储非常适合存储、分析和利用关系。当大规模使用时,这开辟了一系列使用传统“关系”技术无法实现的可能性。图数据库是专门为处理高度连接的数据而设计的,可以处理上面列出的所有问题。由于该图的以下特点,商家已经开始热身。
简单性:您的模型正是您想要的
该图提供了一种独立于实现的数据存储方法。您写下的内容就是您保存在数据库中的内容。它们提供基于关系的数据建模灵活性。从高度约束的关系数据库到没有规则的图,这是使业务用户能够解决实际问题的重要一步。图数据存储可以根据领域或业务的需要添加尽可能多的语义含义。这可以在不考虑通过非规范化进行规范化或数据重组等约束的情况下发生。
灵活性
图不仅允许模型的灵活性,而且还有助于数据库的发展。用户可以添加或删除新实体或关系,扩展模型以集成新业务,或直观地改进现有模型。
运营和分析:运营和分析支持
由于图形数据存储旨在不接触无关数据,因此对其进行了优化以支持事务操作。图结构有助于与开箱即用的算法以及标准 CRUD 操作集成。以数据关系为核心,图表在查询速度方面非常高效,即使对于深度和复杂的问题也是如此。图表可以快速找到所有关联的关系和相关信息,因为它们不必扫描整个表来查找关系。
例子
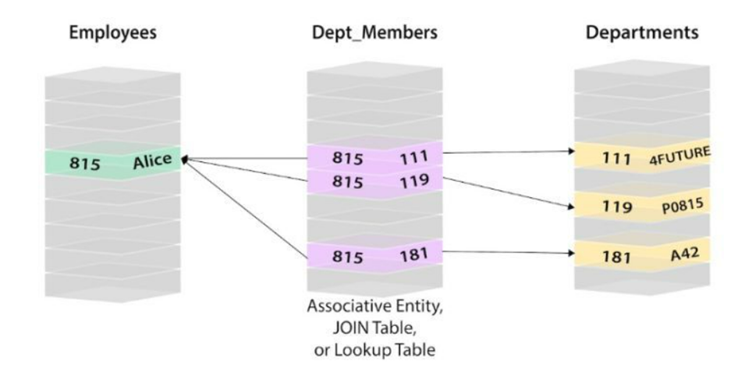
假设我们想知道某公司的员工 Alice 属于哪个部门。
来源——codingnote.cc
在关系型数据库中,一般需要建立员工信息表、员工与部门对应表(假设一个员工可以属于多个部门)、部门信息表。有3个步骤可以找到:
A、首先通过员工信息表找到Alice对应的工号;
B、然后用工号在关系表中找到其对应的部门ID;
C、最后使用部门ID在部门信息表中查找部门名称等信息。
A需要一个索引查找过程,B也需要一个索引查找,C可能需要3个索引查找。假设它是一家拥有数万甚至数十万员工的大公司。那样的话,员工和部门对应表的记录就会很丰富,B的搜索效率会比A和C低很多。
来源——codingnote.cc
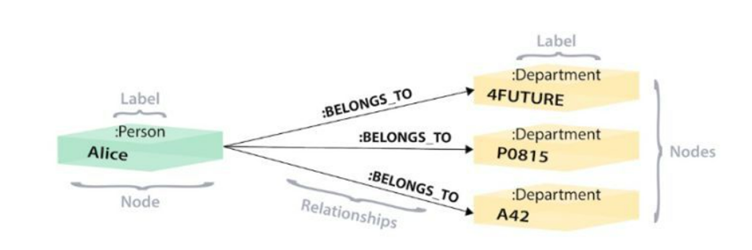
但是,图数据库中不需要如此复杂的查询。这是精确的,因为图形数据库的建模方式与关系数据库或数据的存储方式不同。在图表数据库中,员工和部门在同一个图表中,直接通过边建立关系。查找时也有3个步骤:
- 首先,通过在员工标签Person上建立全局索引(可以是稀疏的)找到Alice对应的节点Na;
- 通过标签BELONGS_TO保存的Na节点边找到对应的部门;
- 阅读部门信息。
虽然也可以分为3个步骤,但是效率差别很大。a的效率相当于A;b 无需进行索引查找;直接通过Na节点来获取,虽然Na节点可能有很多不同标签的边,跟员工和部门关系表中的记录数肯定不是一个数量级,而通过Na来查找edge 也可以到本地索引的 Na 节点,加快查找速度;对于 Neo4J 等支持无索引邻接的图数据库,Na 直接指向 3 个部门节点的物理地址,而对于其他非原生的图存储数据库,如 JanusGraph,则需要在部门标签部门。
结论
如果您拥有高度连接的数据并且您的业务问题利用了这种连接性,那么图表就是您要走的路。尽管图形已经存在了几个世纪,但图形数据库直到最近才开始受到关注。与传统数据存储(RDBMS 和 NoSQL)相比,该图具有多个优势,并且经过高度优化以利用关系。由于它的无索引邻接,它对于遍历问题的速度快如闪电,超级灵活,可以支持不断变化的业务需求,并带有一组预定义的机器学习算法。
一些要点:
1.一切都与关系有关
查询数据的方法有很多,但最有趣的方法之一是查看各种数据是如何连接的以及数据之间存在哪些关系。图数据库的优势之一就是在这个领域。
2. 快速的性能
性能是开发人员喜欢图形数据库的主要原因之一。对于某些大数据问题,尤其是那些涉及分析数百万或数十亿实体之间关系的问题,图形数据库的性能将优于几乎所有现有的现成数据库。
3.语义问题
语义是图形数据库工作的核心,尤其是那些遵循万维网联盟 (W3C) 的资源描述框架 (RDF) 规范的数据库。
原文标题:Graph Database Cheatsheet
原文作者:Kuldeep Pal
原文链接:https://www.analyticsvidhya.com/blog/2022/10/graph-database-cheatsheet/
