




本文测试用语句来自下面大佬文章《ORACLE CBO 的 SQL 自动转换(Cost Based Transformations)之五》
本文主要介绍由于11.2.0.4.190115中由于bug导致子查询不展开的情况。
https://blog.csdn.net/weixin_50513167/article/details/115694814
1. 基础知识之子查询展开
子查询展开(Subquery Unnesting)是优化器处理带子查询的目标SQL的一种优化手段,它是指优化器不再将目标SQL中的子查询当作一个独立的处理单元来单独执行,而是将该子查询转换为它自身和外部查询之间等价的表连接。
1.1 子查询展开两种情形
- 子查询拆开(即将该子查询中的表、视图从子查询中拿出来,然后和外部查询中的表、视图做表连接)
- 不拆开但是会把该子查询转换为一个内嵌视图(Inline View),然后再和外部查询中的表、视图做表连接,这种情况下,相当于优化器多了一条路径,CBO会考虑cost高低来决定是否将内嵌视图用来与外部查询表做关联,还是用外部表的数据来驱动内嵌视图走filter类型执行计划。
1.2 子查询是否展开判断
- 子查询如果展开,则会看到执行计划中会将子查询中基表拿出来与主查询中基表做关联或将子查询转换为内部视图与主查询中基表做关联。
- 子查询如果未展开,一般会在执行计划中最晚执行filter类型的子查询过滤。
1.3 _optimizer_unnest_corr_set_subq
该参数控制优化器在SQL语句包含子查询时,是否在满足子查询展开条件时,是否可以将子查询作为一个视图与主查询关联查询。
2. Oracle 11.2.0.4.190115 PSU下测试
Oracle版本:Oracle 11.2.0.4.190115 for Linux x86_64
Oracle参数: 优化器相关参数均为默认值,即相关_optimizer_unnest_corr_set_subq等参数默认均为true。
2.1 构建测试环境
测试用例均来自于https://blog.csdn.net/weixin_50513167/article/details/115694814
drop table t1 purge; drop table t2 purge; drop table drv purge; create table t1(key, pad) as select to_char(rownum*2-1), lpad(' ',50) from dual connect by level <= 100; create table t2(key, pad) as select to_char(rownum*2), lpad(' ',50) from dual connect by level <= 100; create table drv(key, pad) as select rownum, lpad(' ',500) from dual connect by level <= 5 union all select -rownum, lpad(' ',500) from dual connect by level <= 1000; exec dbms_stats.gather_table_stats(user, 'T1'); exec dbms_stats.gather_table_stats(user, 'T2'); exec dbms_stats.gather_table_stats(user, 'DRV');复制
2.2 执行测试SQL
# 下面参数默认即为true,此处设置为true是为了体现该参数确实为true SQL > alter session set "_optimizer_unnest_corr_set_subq" = TRUE; Session altered. SQL > set autot on SQL > select key from drv 2 where exists ( 3 select key 4 from t1 5 where drv.key = to_number(t1.key) 6 union all 7 select key 8 from t2 9 where drv.key = to_number(t2.key) 10 ); KEY ---------------------------------------- 1 2 3 4 5 Execution Plan ---------------------------------------------------------- Plan hash value: 1881039188 ---------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 5 | 3040 (1)| 00:00:37 | |* 1 | FILTER | | | | | | | 2 | TABLE ACCESS FULL | DRV | 1005 | 5025 | 23 (0)| 00:00:01 | | 3 | UNION-ALL | | | | | | |* 4 | TABLE ACCESS FULL| T1 | 1 | 4 | 3 (0)| 00:00:01 | |* 5 | TABLE ACCESS FULL| T2 | 1 | 4 | 3 (0)| 00:00:01 | ---------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter( EXISTS ( (SELECT "KEY" FROM "T1" "T1" WHERE TO_NUMBER("T1"."KEY")=:B1) UNION ALL (SELECT "KEY" FROM "T2" "T2" WHERE TO_NUMBER("T2"."KEY")=:B2))) 4 - filter(TO_NUMBER("T1"."KEY")=:B1) 5 - filter(TO_NUMBER("T2"."KEY")=:B1) Statistics ---------------------------------------------------------- 39 recursive calls 0 db block gets 4176 consistent gets 0 physical reads 0 redo size 599 bytes sent via SQL*Net to client 523 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 15 sorts (memory) 0 sorts (disk) 5 rows processed复制
可以看到上述SQL走了filter类型的执行计划,执行步骤为2-4-5-3-1,子查询在最后才进行过滤,即两种展开子查询方法均未使用。
2.3 SQL执行计划分析
- SQL子查询中有union all聚合运算,所以不满足直接拿基表出来与主查询中表drv做关联的子查询展开情形,也没有运算等,所以其实复合子查询展开的第二种情形即将子查询做内嵌视图,然后与基表drv做半连接查询。
- 根据上一条,那么该SQL就有两条执行计划:
- 全表扫描drv,得到结果集1,全表扫描T1、T2然后做union all得到结果集2,使用结果集1驱动结果集2走filter(filter其实是一种改良nested loop)类型执行计划使用子查询中条件筛选得到最终结果集,,即不做子查询展开的执行计划。
- 全表扫描drv,得到结果集1,全表扫描T1、T2然后做union all得到结果集2,使用两个结果集中较小结果集驱动较大结果集进行半连接(由于使用exists),可以发现只需要对drv、T1、T2表扫描一次即可,即做子查询展开第二种情形的执行计划。
- 目前执行计划是最优的吗?
- filter类型执行计划是一种改良nested loop,主查询中记录数决定了对子查询中表扫描次数,本例中drv表有1005条记录,则将会对T1、T2表全表扫描1005次(下面会证明这个结果),当然未必所有filter类型执行计划都会驱动子查询执行主查询结果集那么多次。
- 如果做子查询展开,则只会对drv、T1、T2全表扫描一次(由于三张表均无索引),将会大大提高执行效率,那么是什么导致优化器未选择cost明显更低的执行计划呢?
- 统计信息不准导致,很显然统计信息我们是收集了,并且执行计划中预估rows也是准确的。
- bug导致,后面会说明相关bug以及打补丁之后测试。
1. 使用gather_plan_statistics获取真正执行计划 SQL > SELECT /*+gather_plan_statistics*/ KEY FROM DRV WHERE EXISTS (SELECT NULL FROM T1 WHERE DRV.KEY = TO_NUMBER(T1.KEY) UNION ALL SELECT NULL FROM T2 WHERE DRV.KEY = TO_NUMBER(T2.KEY)) 2. 查询 SQL > select sql_id,sql_text,child_number,executions from v$sql where sql_text like 'select /*+gather_plan_statistics*/key from drv%'; SQL_ID ------------- 7cq2303g62nb7 3.获取真正执行计划 SQL > select * from table(dbms_xplan.display_cursor('7cq2303g62nb7',null,format=>'advanced allstats last')); PLAN_TABLE_OUTPUT ------------------------------------- SQL_ID 7cq2303g62nb7, child number 0 ------------------------------------- select /*+gather_plan_statistics*/key from drv where exists ( select null from t1 where drv.key = to_number(t1.key) union all select null from t2 where drv.key = to_number(t2.key) ) Plan hash value: 1881039188 ---------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | ---------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | | 3040 (100)| | 5 |00:00:00.01 | 8097 | |* 1 | FILTER | | 1 | | | | | 5 |00:00:00.01 | 8097 | | 2 | TABLE ACCESS FULL | DRV | 1 | 1005 | 5025 | 23 (0)| 00:00:01 | 1005 |00:00:00.01 | 75 | | 3 | UNION-ALL | | 1005 | | | | | 5 |00:00:00.05 | 8022 | |* 4 | TABLE ACCESS FULL| T1 | 1005 | 1 | 4 | 3 (0)| 00:00:01 | 3 |00:00:00.02 | 6018 | |* 5 | TABLE ACCESS FULL| T2 | 1002 | 1 | 4 | 3 (0)| 00:00:01 | 2 |00:00:00.02 | 2004 | ---------------------------------------------------------------------------------------------------------------------- ...省略部分 # 可以看到starts列,对T1、T2全表扫描了1005次,这显然是不合理的,也是我们不希望看到的。复制
3. bug说明
通过搜索Mos发现如下bug
Bug 19523291 - Subquery unnesting does not happen or ORA-1790 is signaled during subquery unnesting (Doc ID 19523291.8)
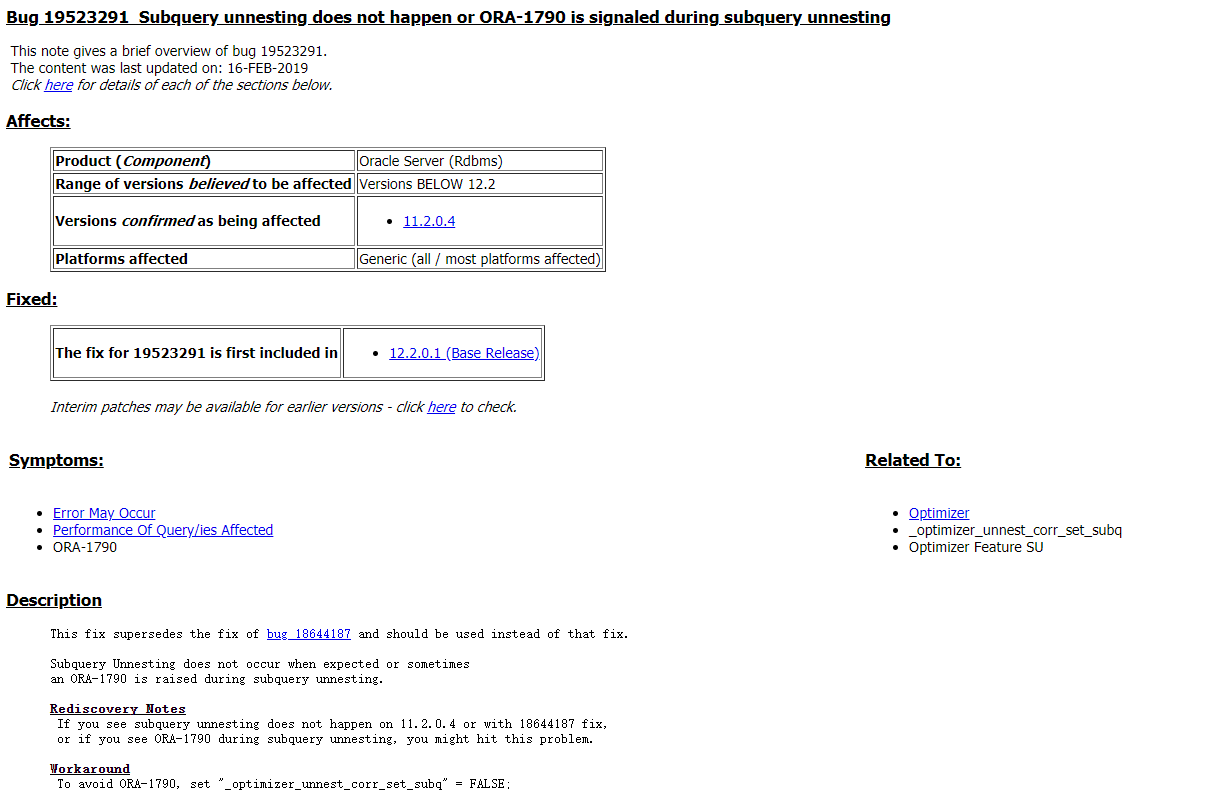
4. 打补丁之后测试是否生效
4.1 打补丁
Mos有提供上述bug的patch,下载下来打补丁之后测试效果
随后附件会附加mos文档与patch
$ unzip p25103607_112040_Linux-x86-64.zip $ /oracle/app/oracle/product/11.2/db_1/OPatch/opatch apply Oracle Interim Patch Installer version 11.2.0.3.25 Copyright (c) 2021, Oracle Corporation. All rights reserved. Oracle Home : /oracle/app/oracle/product/11.2/db_1 Central Inventory : /oracle/app/oraInventory from : /oracle/app/oracle/product/11.2/db_1/oraInst.loc OPatch version : 11.2.0.3.25 OUI version : 11.2.0.4.0 Log file location : /oracle/app/oracle/product/11.2/db_1/cfgtoollogs/opatch/opatch2021-04-12_21-48-11PM_1.log Verifying environment and performing prerequisite checks... OPatch continues with these patches: 25103607 Do you want to proceed? [y|n] y User Responded with: Y All checks passed. Please shutdown Oracle instances running out of this ORACLE_HOME on the local system. (Oracle Home = '/oracle/app/oracle/product/11.2/db_1') Is the local system ready for patching? [y|n] y User Responded with: Y Backing up files... Applying interim patch '25103607' to OH '/oracle/app/oracle/product/11.2/db_1' Patching component oracle.rdbms, 11.2.0.4.0... Patch 25103607 successfully applied. Log file location: /oracle/app/oracle/product/11.2/db_1/cfgtoollogs/opatch/opatch2021-04-12_21-48-11PM_1.log OPatch succeeded. SQL > startup; ORACLE instance started. Total System Global Area 471830528 bytes Fixed Size 2254344 bytes Variable Size 276826616 bytes Database Buffers 188743680 bytes Redo Buffers 4005888 bytes Database mounted. Database opened.复制
4.2 再次测试
SQL > alter session set "_optimizer_unnest_corr_set_subq" = TRUE; Session altered. SQL > set autot on SQL > select key from drv 2 where exists ( 3 select null 4 from t1 5 where drv.key = to_number(t1.key) 6 union all 7 select null 8 from t2 9 where drv.key = to_number(t2.key) 10 ); KEY ---------------------------------------- 1 2 3 4 5 Execution Plan ---------------------------------------------------------- Plan hash value: 1657361037 -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 18 | 29 (0)| 00:00:01 | |* 1 | HASH JOIN RIGHT SEMI| | 1 | 18 | 29 (0)| 00:00:01 | | 2 | VIEW | VW_SQ_1 | 200 | 2600 | 6 (0)| 00:00:01 | | 3 | UNION-ALL | | | | | | | 4 | TABLE ACCESS FULL| T1 | 100 | 400 | 3 (0)| 00:00:01 | | 5 | TABLE ACCESS FULL| T2 | 100 | 400 | 3 (0)| 00:00:01 | | 6 | TABLE ACCESS FULL | DRV | 1005 | 5025 | 23 (0)| 00:00:01 | -------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("DRV"."KEY"="VW_COL_1") Statistics ---------------------------------------------------------- 37 recursive calls 0 db block gets 166 consistent gets 79 physical reads 0 redo size 599 bytes sent via SQL*Net to client 523 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 15 sorts (memory) 0 sorts (disk) 5 rows processed复制
可以看到补丁已经解决了子查询不展开的bug,Oracle已经将该子查询作为一个内嵌视图与外部基表进行了连接,即子查询展开的第二种情形,cost已经大大降低。
5. 通过SQL改写,避免优化器相关特性
如果子查询可以展开,且我们可以清楚知道展开后cost会远低于不展开,那么其实我们可以直接写出改写后SQL,省去优化器自己判断,使执行计划更加稳定。
改写一定要基于等价原则。
# SQL原文 select key from drv where exists ( select null from t1 where drv.key = to_number(t1.key) union all select null from t2 where drv.key = to_number(t2.key) );复制
5.1 改写1
# SQL原文 select key from drv where exists ( select null from t1 where drv.key = to_number(t1.key) union all select null from t2 where drv.key = to_number(t2.key) ); # 由于子查询使用了exists,所以等价于预先distinct对t1、t2进行去重,然后与drv表做内连接 优点:CBO可以直接对内嵌视图与drv表做连接。 缺点:由于子查询会去重,所以可以看到结果集会排序,原SQL结果集没有排序,所以一旦t1/t2表较大时,排序将变的更加昂贵。 SELECT A.KEY FROM DRV A JOIN (select distinct key from (SELECT KEY FROM T1 UNION ALL SELECT KEY FROM T2) v_vso ) V_1 ON A.KEY = v_1.KEY; KEY ---------------------------------------- 1 2 3 4 5 Execution Plan ---------------------------------------------------------- Plan hash value: 3618528922 ------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 100 | 2700 | 31 (4)| 00:00:01 | |* 1 | HASH JOIN | | 100 | 2700 | 31 (4)| 00:00:01 | | 2 | VIEW | | 100 | 2200 | 8 (13)| 00:00:01 | | 3 | HASH UNIQUE | | 100 | 400 | 8 (13)| 00:00:01 | | 4 | VIEW | | 202 | 808 | 7 (0)| 00:00:01 | | 5 | UNION-ALL | | | | | | | 6 | TABLE ACCESS FULL| T1 | 102 | 408 | 4 (0)| 00:00:01 | | 7 | TABLE ACCESS FULL| T2 | 100 | 400 | 3 (0)| 00:00:01 | | 8 | TABLE ACCESS FULL | DRV | 1005 | 5025 | 23 (0)| 00:00:01 | ------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("A"."KEY"=TO_NUMBER("V_1"."KEY")) Statistics ---------------------------------------------------------- 52 recursive calls 0 db block gets 204 consistent gets 0 physical reads 0 redo size 599 bytes sent via SQL*Net to client 520 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 21 sorts (memory) 0 sorts (disk) 5 rows processed复制
5.2 改写2
# SQL原文 select key from drv where exists ( select null from t1 where drv.key = to_number(t1.key) union all select null from t2 where drv.key = to_number(t2.key) ); # 当t1 t2 key无重复值时,即当t1.key与t2.key有主键唯一等约束时,且需要不奥正t1.key与t2.key联合无重复值,则也等价于下面内连接形式 select a.key from drv a join (select key from t1 union all select key from t2) b on a.key = b.key; KEY ---------------------------------------- 1 2 3 4 5 Execution Plan ---------------------------------------------------------- Plan hash value: 1119802508 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 200 | 5400 | 29 (0)| 00:00:01 | |* 1 | HASH JOIN | | 200 | 5400 | 29 (0)| 00:00:01 | | 2 | VIEW | | 200 | 4400 | 6 (0)| 00:00:01 | | 3 | UNION-ALL | | | | | | | 4 | TABLE ACCESS FULL| T1 | 100 | 400 | 3 (0)| 00:00:01 | | 5 | TABLE ACCESS FULL| T2 | 100 | 400 | 3 (0)| 00:00:01 | | 6 | TABLE ACCESS FULL | DRV | 1005 | 5025 | 23 (0)| 00:00:01 | ----------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("A"."KEY"=TO_NUMBER("B"."KEY")) Statistics ---------------------------------------------------------- 97 recursive calls 0 db block gets 219 consistent gets 0 physical reads 0 redo size 599 bytes sent via SQL*Net to client 523 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 19 sorts (memory) 0 sorts (disk) 5 rows processed复制
最后再次感谢杨 昱明大佬文章https://blog.csdn.net/weixin_50513167/article/details/115694814,对优化器多了一些了解。
附件:
Mos文章:https://www.modb.pro/doc/26323
Patch: https://www.modb.pro/download/71385
评论

 0 点赞
0 点赞 0 点赞 1 1
0 点赞 1 1