





Oracle data guard概述
Oracle Rac、Data Gurad、Stream是Oracle 高可用性体系中的三种工具,每个工具即可以独立应用,也可以相互配合。 他们各自的侧重点不同,适用场景也不同。
Oracle RAC | Oracle Data Guard | Oracle stream |
RAC 的强项在于解决单点故障和负载均衡,因此RAC 方案常用于7*24 的核心系统,但RAC 方案中的数据只有一份,尽管可以通过RAID 等机制可以避免存储故障,但是数据本身是没有冗余的,容易形成单点故障。 | Data Gurad 通过冗余数据来提供数据保护,Data Gurad 通过日志同步机制保证冗余数据和主数据之前的同步,这种同步可以是实时,延时,同步,异步多种形式。Data Gurad 常用于异地容灾和小企业的高可用性方案,虽然可以在Standby 机器上执行只读查询,从而分散Primary 数据库的性能压力,但是Data Gurad 决不是性能解决方案。 | Stream 是以Oracle Advanced Queue为基础实现的数据同步,提供了多种级别的灵活配置,并且Oracle 提供了丰富的API等开发支持,Stream 更适用在应用层面的数据共享。 |
Oracle在版本7的时候,就支持Standby容灾备份数据库技术,并在Oracle8版本开始支持日志从生产数据库到备用数据库的自动传输。Oracle9i版本把standby技术正式命名为Data Guard。
Data Guard是Oracle的集成化灾难恢复解决方案,该技术可以维护生产数据库一个或多个同步备份,由一个生产数据库和若干备用数据库组成,并形成一个独立的、易于管理的数据保护方案。Data Guard备用数据库可以与生产系统位于相同的数据中心,也可以是在地理位置上分布较远的远程灾难备份中心。
Data Guard的基本原理是,当某次事务处理对生产数据库中的数据作出更改时,Oracle数据库将在一个联机重做日志文件中记录此次更改。在Data Guard中可以配置写日志的这个过程,除了把日志记录到本地的联机日志文件和归档日志文件中,还可以通过网络,把日志信息发送的远程的备用数据库服务器上。这个备用日志文件写入过程可以是实时、同步的,以实现零数据丢失(最大保护模式);也可以是异步的,以减少对网络带宽的压力(最大性能模式);或者是异步和同步可以自动切换的模式(最大可用模式)。当备份数据库接收到日志信息后,Data Guard可以自动利用日志信息实现数据的同步。当主数据库打开并处于活动状态时,备用数据库可以执行恢复操作,如果主数据库出现了故障,备用数据库即可以被激活并接管生产数据库的工作。
Oracle Data Guard 架构
Data Guard架构可以按照功能分成3个部分:
1) 日志发送(Redo Send)
Primary Database 运行过程中,会源源不断地产生Redo 日志,这些日志需要发送到Standy Database。 这个发送动作可以由Primary Database 的LGWR 或者ARCH进程完成, 不同的归档目的地可以使用不同的方法,但是对于一个目的地,只能选用一种方法。 选择哪个进程对数据保护能力和系统可用性有很大区别。
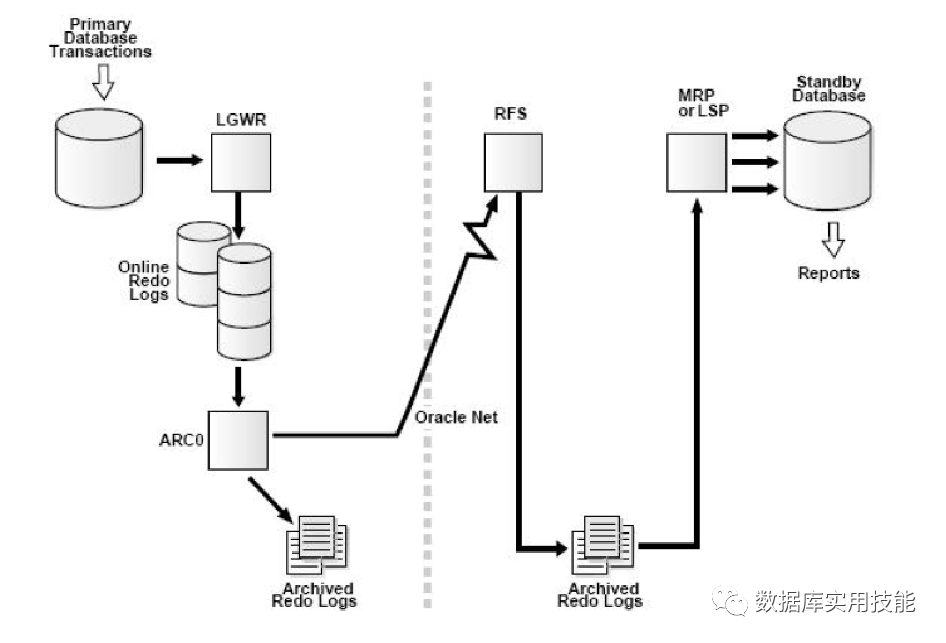
使用ARCH 进程
◆ Primary Database 不断产生Redo Log,这些日志被LGWR进程写到联机日志。
◆ 当一组联机日志被写满后,会发生日志切换(Log Switch),并且会触发本地归档.
◆ 完成本地归档后,联机日志就可以被覆盖重用。
◆ ARCH 进程通过Net 把归档日志发送给Standby Database的RFS(Remote File Server) 进程。
◆ Standby Database 端的RFS 进程把接收的日志写入到归档路径中。
◆ Standby Database 端的MRP(Managed Recovery Process)进程(Redo Apply)或者LSP 进程(SQL Apply)在Standby Database上应用这些日志,进而同步数据。
参见下图
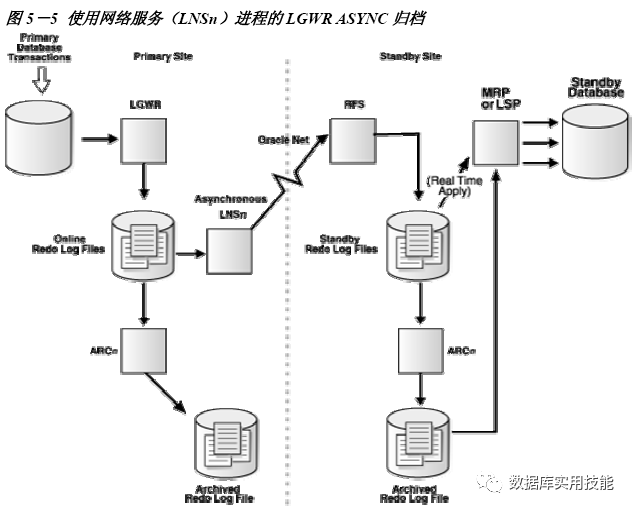
用ARCH模式传输不写Standby Redologs,直接保存成归档文件存放于Standby端。
说明:
逻辑Standby接收后将其转换成SQL语句,在Standby数据库上LSP进程执行SQL语句实现同步,这种方式叫SQL Apply。
物理Standby接收完Primary数据库生成的REDO数据后,MRP进程以介质恢复的方式实现同步,这种方式也叫Redo Apply。
注意:创建逻辑Standby数据库要先创建一个物理Standby数据库,然后再将其转换成逻辑Standby数据库。
使用ARCH进程传递最大问题在于: Primary Database 只有在发生归档时才会发送日志到Standby Database。 如果Primary Database 异常宕机,联机日志中的Redo内容就会丢失,因此使用ARCH 进程无法避免数据丢失的问题,要想避免数据丢失,就必须使用LGWR,而使用LGWR 又分SYNC(同步)和ASYNC(异步)两种方式。
在缺省方式下,Primary Database使用的是ARCH进程,参数设置如下:
alter system set log_archive_dest_2 = 'SERVICE=ST' scope=both;
使用LGWR 进程的SYNC 方式
◆ Primary Database 产生的Redo日志要同时写到日志文件和网络。也就是说LGWR进程把日志写到本地日志文件的同时还要发送给本地的LNSn进程(Network Server Process),再由LNSn(LGWR Network Server process)进程把日志通过网络发送给远程的目的地,每个远程目的地对应一个LNS进程,多个LNS进程能够并行工作。
◆ LGWR 必须等待写入本地日志文件操作和通过LNSn进程的网络传送都成功,Primary Database上的事务才能提交,这也是SYNC的含义所在。
◆ Standby Database的RFS进程把接收到的日志写入到Standby Redo Log日志中。
◆Primary Database的日志切换也会触发Standby Database 上的日志切换,即Standby Database 对Standby Redo Log的归档,然后触发Standby Database 的MRP或者LSP进程恢复归档日志。 因为Primary Database 的Redo 是实时传递的,于是Standby Database 端可以使 用两种恢复方法:
实时恢复(Real-Time Apply): 只要RFS把日志写入Standby Redo Log 就会立即进行恢复;
归档恢复: 在完成对Standby Redo Log 归档才触发恢复。
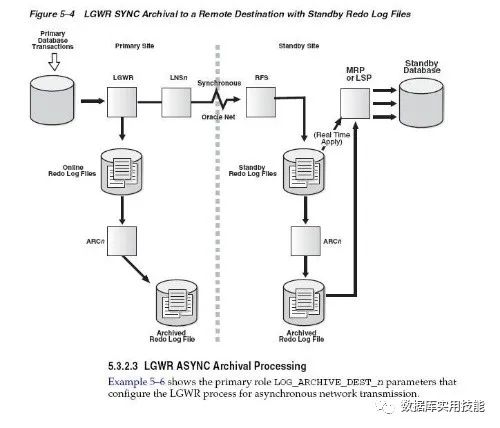
Primary Database默认使用ARCH进程,如果使用LGWR进程必须明确指定。使用LGWR SYNC方式时,可以同时使用NET_TIMEOUT参数,这个参数单位是秒,代表如果多长时间内网络发送没有响应,LGWR 进程会抛出错误。 示例如下:
alter system set log_archive_dest_2 = 'SERVICE=ST LGWR SYNC NET_TIMEOUT=30' scope=both;
使用LGWR进程的ASYNC 方式
使用 LGWR SYNC方法的可能问题在于,如果日志发送给Standby Database过程失败,LGWR进程就会报错。也就是说Primary Database的LGWR 进程依赖于网络状况,有时这种要求可能过于苛刻,这时就可以使用LGWR ASYNC方式。 它的工作机制如下:
◆ Primary Database 一段产生Redo日志后,LGWR 把日志同时提交给日志文件和本地LNS 进程,但是LGWR进程只需成功写入日志文件就可以,不必等待LNSn进程的网络传送成功。
◆ LNSn进程异步地把日志内容发送到Standby Database。多个LNSn进程可以并发发送。
◆ Primary Database的Online Redo Log 写满后发生Log Switch,触发归档操作,也触发Standby Database对Standby Database对Standby Redo Log 的归档;然后触发MRP或者LSP 进程恢复归档日志。
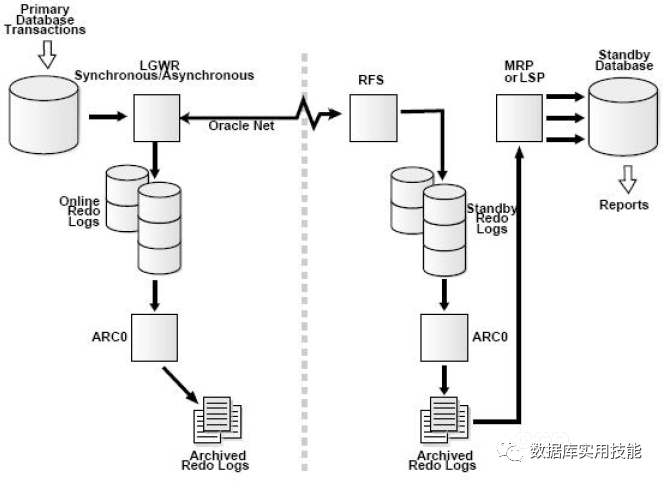
因为LGWR进程不会等待LNSn进程的响应结果,所以配置LGWR ASYNC方式时不需要NET_TIMEOUT参数。示例如下:
alter system set log_archive_dest_2 = 'SERVICE=ST LGWR ASYNC ' scope=both;
2) 日志接收(Redo Receive)
Standby Database 的RFS(Remote File Server)进程接收到日志后,就把日志写到Standby Redo Log或者Archived Log文件中,具体写入哪个文件,取决于Primary 的日志传送方式和Standby database的位置。如果写到Standby Redo Log文件中,则当Primary Database发生日志切换时,也会触发Standby Database上的Standby Redo Log 的日志切换,并把这个Standby Redo Log 归档。 如果是写到Archived Log,那么这个动作本身也可以看作是个归档操作。
在日志接收中,需要注意的是归档日志会被放在什么位置:
◆ 如果配置了STANDBY_ARCHIVE_DEST参数,则使用该参数指定的目录。
◆ 如果某个LOG_ARCHIVE_DEST_n 参数明确定义VALID_FOR=(STANDBY_LOGFILE,*)选项,则使用这个参数指定的目录。
◆ 如果数据库的COMPATIBLE参数大于等于10.0,则选取任意一个LOG_ARCHIVE_DEST_n的值。
◆ 如果STANDBY_ARCHIVE_DEST 和 LOG_ARCHIVE_DEST_n 参数都没有配置,使用缺省的STANDBY_ARCHIVE_DEST参数值,这个缺省值是$ORACLE_HOME/dbs/arc.
3) 日志应用(Redo Apply)
日志应用服务,就是在Standby Database上重演Primary Database日志,从而实现两个数据库的数据同步。 根据Standby Database重演日志方式的不同,可分为物理Standby(Physical Standby)和逻辑Standby (Logical Standby)。
Physical Standby 使用的是Media Recovery 技术,在数据块级别进行恢复,这种方式没有数据类型的限制,可以保证两个数据库完全一致。 Physical Standby数据库只能在Mount状态下进行恢复,也可以是打开,但只能已只读方式打开,并且打开时不能执行恢复操作,即在打开状态下不能应用日志。
Logical Standby使用的是Logminer 技术,通过把日志内容还原成SQL 语句,然后SQL引擎执行这些语句,Logminer Standby不支持所有数据类型,可以在视图DBA_LOGSTDBY_UNSUPPORTED 中查看不支持的数据类型,如果使用了这种数据类型,则不能保证数据库完全一致。 Logical Standby数据库可以在恢复的同时进行读写操作。
Standby数据库的相关进程读取接收到的REDO数据(可能来自于Standby端的归档文件,也可能来自于Standby Redologs),再将其写入Standby数据库。保存之后数据又是怎么生成的呢?两种方式:物理Standby通过REDO应用,逻辑Standby通过SQL应用根据Redo Apply发生的时间可以分成两种:
一种是实时应用(Real-Time Apply), 这种方式必须Standby Redo Log,每当日志被写入Standby Redo Log时,就会触发恢复,使用这种方式的好处在与可以减少数据库切换(Switchover 或者Failover)的时间,因为切换时间主要用在剩余日志的恢复上。
另一种是归档时应用,这种方式在Primary Database发生日志切换,触发Standby Database 归档操作,归档完成后触发恢复。 这也是默认的恢复方式。
如果是Physical Standby,可以使用下面命令启用Real-Time:
Alter database recover managed standby database using current logfile;
如果是Logical Standby,可以使用下面命令启用Real-Time:
Alter database start logical standby apply immediate;
查看是否使用Real-Time apply:
Select recovery_mode from v$archive_dest_status;
物理备用数据库和逻辑备用数据库
当备用数据库接收到从生产数据库传输过来的日志时,根据处理日志方法的不同,可以把Data Guard分为物理备用数据库和逻辑备用数据库两种。物理备用数据库,就是备用数据库处于Mount的状态下,直接利用数据恢复技术,把日志文件中记录的数据变更应用在备用数据库的数据文件上,从而实现与生产数据库的数据同步,在进行数据同步的时候,物理备用数据库是不能打开的、也无法提供数据查询等服务,物理备用数据库也可以通过只读的方式打开,但是,一旦物理备用数据库以只读方式打开后,就只能接收日志,而无法进行数据的同步;逻辑备用数据库,数据库是处于正常的打开状态的,当它接收到新的日志信息后,利用日志挖掘器的功能,把日志中记录的变更信息,转换成具体的SQL语句,并在逻辑备用数据库上执行这些SQL语句,从而实现与生产数据库的数据同步,逻辑备用数据库支持在数据同步的同时,进行数据的查询、报表等操作。Oracle从9i R2开始支持逻辑备用数据库。
物理备用数据库的数据保护级别
Oracle Data Guard 支持多种级别的数据保护模式:最大性能模式,最大可用性模式,最大保护模式。分别对应于“重要信息系统灾难恢复指南”中的5级,5级6级自适应,6级的数据保护级别。其中对应6级的最大保护模式可以实现实时数据实时同步和0数据丢失。另外,Oracle Data Guard 可以设置延时应用时间窗口,从而防范错误操作、黑客攻击等人为错误导致的数据损坏。
保护模式和重做传输
要确定适当的数据保护模式,企业需要根据用户对系统响应时间的要求来估量它们对数据保护的业务要求。下表从数据丢失风险的角度概述了各种模式的适用性。
采用归档日志传送还是联机日志传送,默认是归档进程是否采用ARCH进程还是LGWR进程,很多时候依赖于保护的方式,下表可以看到在不同的保护模式下,采用归档进程还是联机日志进程的情况。
保护模式 | 在出现灾难时 数据丢失的风险 | 重做传输机制 | 磁盘写操作 | 备用日志 | 备用库类型 |
最大保护 | 零数据丢失 | LGWR SYNC | AFFIRM | YES | 物理 |
最高可用性 | 零数据丢失 | LGWR SYNC | AFFIRM | 物理备用需要 | 物理和逻辑 |
最高性能 | 最小数据丢失通常为几秒 | LGWR ASYNC 或 ARCH | NOAFFIRM | LGWR和物理备用时需要 | 物理和逻辑 |
最大保护模式
最大保护(maximize protection):最高级别的保护模式。primay上的事务在commit前必须确认redo已经传递到至少一个standby上,如果所有standby不可用,则primary会挂起。该模式能保证零数据丢失。对于最大保护和最高可用性模式, Standby数据库必须配置standby redo log,并且oracle推荐所有数据库都使用LGWR ASYNC模式传输。强烈建议,这种模式应至少配置两个备用数据库。当最后参与的备用数据库不可用时,主数据库上的处理将停止。这就确保了当主数据库与其所有备用数据库失去联系时,不会丢失事务。
由于重做传输的同步特性,这种最大保护模式可能潜在地影响主数据库响应时间。可以通过配置一个低延迟网络,并为它分配足够应付高峰事务负载的带宽来将这种影响减到最小。需要这种最大保护模式的企业有股票交易所、货币交易所、金融机构等。
最大可用性模式
最大可用性模式拥有仅次于最高水平的主数据库数据可用性。最大可用(maximize availability):在正常情况下,最大可用模式和最大保护模式一样;在standby不可用时,最大可用模式会自动降低成最大性能模式,所以standby故障不会导致primay不可用。在问题纠正之后,Standby和主数据库进行再同步,至少有一个standby可用的情况下,即使primary down机,也能保证不丢失数据。(不过当问题修复,再同步之前有必要FAILOVER,那么有些数据可能会丢失)。最大可用性模式Standby必须配置Standby Redo log,Oracle推荐最大可用模式使用LGWR ASYNC(异步)模式传输。
采用最大可用的data guard模式,主库往备库传递在线日志(online redo log)信息,在线日志信息写入备用库的standby redo log,这些standby redo log归档后,备用库应用归档日志。
不过,在这种模式下(与最大保护模式不同),如果最后参与的备用数据库变为不可用 — 例如由于网络连接问题,处理将在主数据库上继续进行(类似于MySQL-5.5中的半同步复制)。备用数据库与主数据库相比,可能暂时落在后面,但当它再次变为可用时,备用数据库将使用主数据库上累积的归档日志自动同步,而不会丢失数据。
由于同步重做传输,这种保护模式可潜在地影响响应时间和吞吐量。可以通过配置一个低延迟网络,并为它分配足够应付高峰事务负载的带宽来将这种影响减到最小。
最大可用性模式适用于想要确保获得零数据丢失保护,但不想让生产数据库受网络/备用服务器故障影响的企业。如果又一个故障随后影响了生产数据库,然后最初的网络/备用服务器故障得到解决,那么这些企业将接受数据丢失的可能性。
最大性能模式
最大性能(maximize performance):这是data guard默认的保护模式。primay上的事务commit前不需要从standby上收到反馈信息(主数据库的提交操作不等待STANDBY),该模式在primary故障时可能丢失数据,但standby对primary的性能影响最小。 可以使用LGWR ASYNC或者ARCH两种传输模式。它与最高可用性模式相比,提供了稍微少一些的主数据库数据保护,但提供了更高的性能。在这种模式下,当主数据库处理事务时,重做数据由 LGWR 进程异步传输到备用数据库上。另外,也可以将主数据库上的归档器进程 (ARCH) 配置为在这种模式下传输重做数据。在任何情况下,均先完成主数据库上的写操作,主数据库的提交操作不等待备用数据库确认接收(类似于MySQL中的异步复制)。如果任意备用目标数据库变为不可用,则处理将在主数据库上继续进行,这对性能只有很小的影响或没有影响。
在主数据库出现故障的情况下,尚未被发送到备用数据库的重做数据会丢失。但是,如果网络有足够的吞吐量来跟上重做流量高峰,并且使用了 LGWR 进程来将重做流量传输到备用服务器,则丢失的事务将非常少或者为零。
当主数据库上的可用性和性能比丢失少量数据的风险更重要时,应该使用最高性能模式。这种模式还适合于 WAN 上的 Data Guard 部署,在 WAN 中,网络的内在延迟可能限制同步重做传输的适用性。
9i&10g Data Guard存在的不足
建设灾难备份数据库,需要投入基础设施(如机房、场地、人员)、硬件、软件等成本。因此,能否最大程度地充分发挥灾备系统的资源利用率,是很多企业的重要考虑因素。
物理备用数据库所需要的硬件资源不高、数据同步的速度也快,但是,在进行数据同步的同时,数据库是无法打开提供查询访问服务的,而如果用只读方式打开物理备用数据库,则数据同步就无法同时进行,因此,无法满足企业近实时数据查询的需要;而逻辑备用数据库,数据同步的同时、数据库是正常打开的,是可以在数据同步的同时提供对外查询服务的,但是,逻辑备用数据库在使用上存在一定的限制,例如:不支持long、long raw以及用户自定义的数据类型,一般需要为每个表创建关键字或唯一索引等。此外,由于逻辑备用数据库不仅要执行生产数据库上所发生的所有数据变更SQL语句,还需要额外的日志分析工作,因此,硬件资源的配置也相对较高。
有没有办法,把逻辑备用数据库和物理备用数据库的优势结合在一起,既能发挥物理备用数据库同步速度快、耗用资源低,又能够在数据同步的同时,可以进行数据查询,从而充分发挥备用系统的资源利用率呢?这就是Oracle11g Active Data Guard的功能。
Oracle11g Active Data Guard的功能增强
11g以前的Data Guard物理备用数据库,可以以只读的方式打开数据库,但是这时Media Recovery利用日志进行数据同步的过程就停止了,如果物理备用数据库处于恢复的过程中数据库就不能打开查询,也就是说日志应用和只读打开两个状态是互相排斥的,而Oracle11g Active Data Guard功能解决了这个矛盾,在利用日志恢复数据的同时可以用只读的方式打开数据库,用户可以在备用数据库上进行查询、报表等操作,这类似逻辑备用数据库的功能,但是,数据同步的效率更高、对硬件的资源要求更低。这样可以更大程度地发挥物理备用数据库的硬件资源的效能(比如对于实时要求比较高的报表服务)。
Oracle11g Active Data Guard除了可以运行在只读打开和日志同步应用的场景下,还可以切换到Snapshot Standby状态下运行。运行在Snapshot Standby状态下的物理备用数据库可以用读写的模式打开数据库,但是同时没有破坏它作为物理备用数据库的功能,这个特性可以用来在物理备用数据库上面执行某些测试,等测试完成,把数据库再切换到Physical standby状态下,又可以自动利用日志实现数据同步了。当然在Snapshot Standby以读写方式打开的时候它只能接收生产数据库传过来的日志,但是不能应用这些日志进行数据同步。
例如:把数据库从数据同步和只读打开状态切换到快照备用状态,只需要在备用数据库上执行Alter database convert to snapshot standby;而把数据库从快照备用切换会只读同步状态,只需要执行Alter database convert to physical standby就可以了。

