




上一期文章介绍了全量备份和恢复的过程( [原理解析] XtraBackup全量备份还原 ), 先来回顾一下全量备份和恢复的要点:
全量备份开始时, 要监听并记录redo log的变化
全量备份拷贝InnoDB数据文件时, 数据库同时会写入数据, 导致数据文件的新旧程度不一致
拷贝InnoDB数据文件后, 对数据库施加全局读锁后, 才能拷贝 非事务类型的信息, 比如: binlog点位、非事务类引擎的数据文件等
全量恢复时, 对InnoDB数据文件的不一致, 通过将步骤1中记录的redo log的变化回放, 可消除步骤2中的数据文件的新旧程度不一致的问题
在讨论增量备份和恢复时, 我们需关注以下问题:
增量备份时, 如何识别InnoDB的哪些数据是增量的
类似于全量备份, 如何解决 增量备份的数据文件的新旧不一致问题
非事务类型的信息, 能否产生增量备份
下面来图解增量备份的步骤:
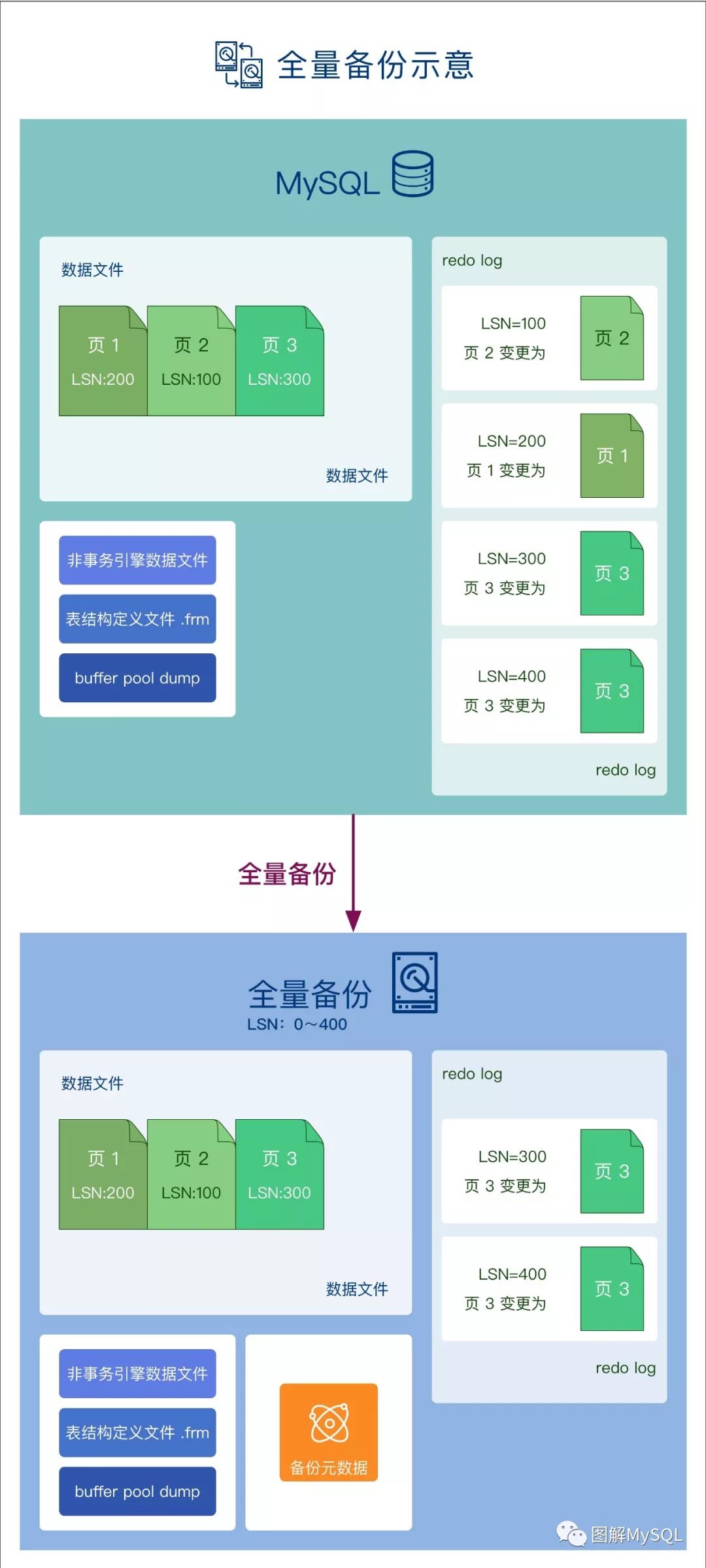
由于 增量备份 是在 全量备份 的基础上进行备份, 先来做一个全量备份:
讨论1: 现在我们开始做一个增量备份, 那么 如何识别InnoDB的哪些数据是增量的?
从全量备份的示意图里, 可以看到数据文件中的数据页都有LSN号 (在上一篇图解中我们介绍过LSN的概念, 不再赘述), LSN可以看做是数据页的变更时间戳.
那么通过这个时间戳, 就可以识别 数据页 在 全量备份后 是否修改过, 即通过LSN可以识别数据是否是增量的.
从下图中, 可以看到增量备份时, LSN>400的数据页才会进行备份
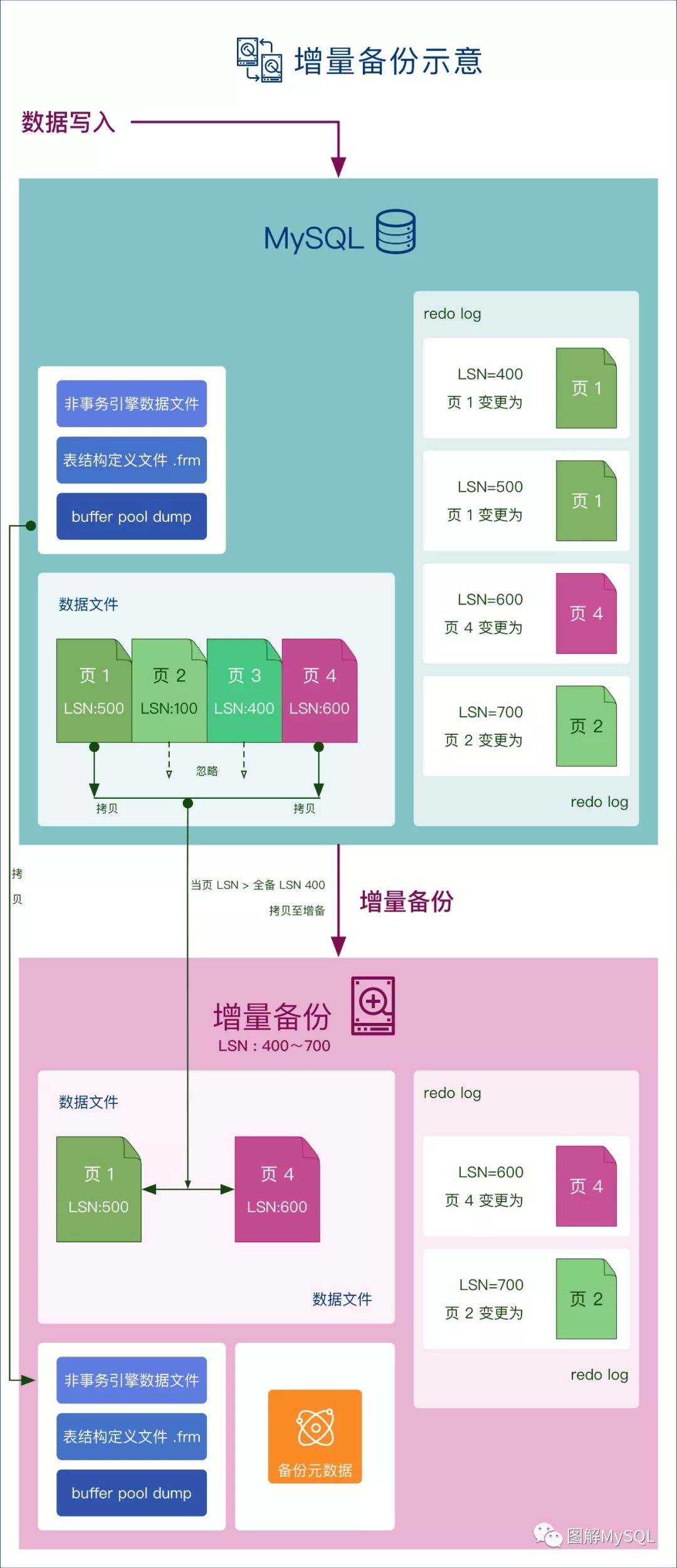
讨论2: 如果一个数据页原本不是增量范围内的, 在增量备份的过程中, 数据页更新了, 那么增量备份是否会涵盖这个数据页?
这个问题的本质, 与全量备份中的数据页新旧不一致的问题 相同, 解决方案也相同: 通过恢复时回放redo log, 解决数据新旧不一致的问题.
也就是说: 增量备份过程中, 如果数据页被更新了, 那数据文件中的这个数据页 有可能 被拷贝到备份中, 也可能 没有被拷贝到备份中, 但这个更新信息一定会被redo log记录, 并被记录在备份中. 在恢复过程中, redo log会被"安全地"回放成功, 达成数据的新旧一致.
下面我们来看看增量备份恢复的流程, 如下图:
先还原一个全量备份 到 临时目录 (详细步骤参看上一篇图解)
开始还原增量备份, 将增量备份中的增量的数据文件, 覆盖到临时目录中
将增量备份中的redo log, 回放到临时目录中
将其他文件覆盖到临时目录中
增备还原完成
重建redo log, 为启动数据库做准备
将临时目录中的文件, 拷贝到MySQL的数据目录中
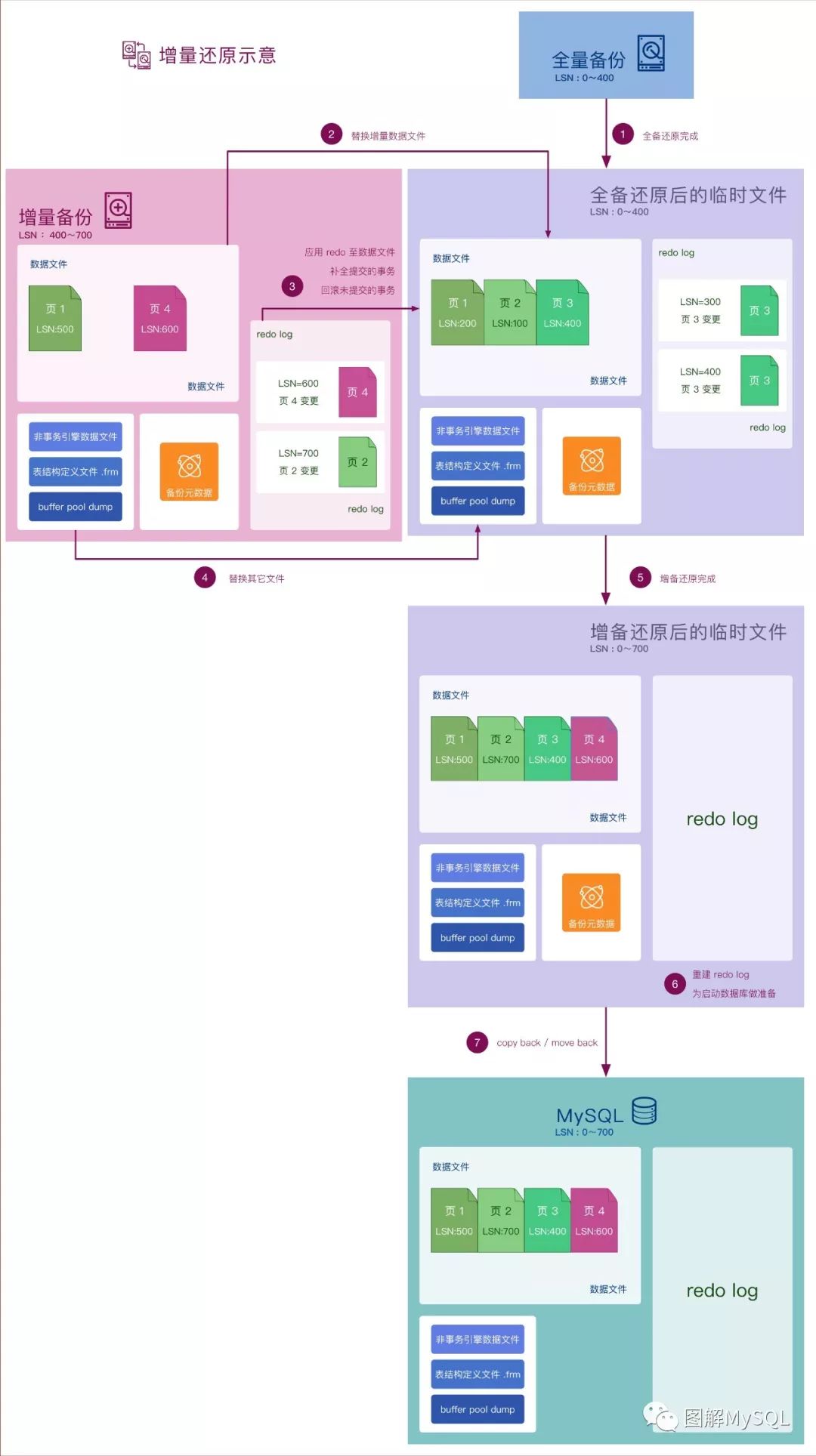
讨论3: 从图中可以看到, 非事务类的信息是从 增量备份 直接覆盖到 临时目录中的, 也就是说: 与事务类的信息不同, MySQL没有为 非事务类的信息 提供增量的机制, 均是全部拷贝和覆盖.
再往前一步: 增量备份是否需要全局读锁呢? 由讨论3的结论可知, 虽然示意图上没有标明, 但增量备份依然需要全局读锁去保证 非事务类的信息 的一致性.
回顾一下本次图解的重点:
增量备份时, 如何识别InnoDB的哪些数据是增量的:
数据页上的LSN充当了逻辑时间戳的角色, 用以识别增量类似于全量备份, 如何解决 增量备份的数据文件的新旧不一致问题:
解决方案与全量备份相同, 依靠redo log进行回放以保证一致性非事务类的信息, 能否产生增量备份:
非事务类的信息 没有提供识别增量的机制, 只能采用全局读锁+全部拷贝+全部回放的机制进行备份
