




本文作为数据科学博客马拉松的一部分发表。

介绍
2018 年,谷歌 AI 研究人员提出了BERT,它彻底改变了 NLP 领域。2019 年晚些时候,研究人员提出了 ALBERT(“A Lite BERT”)模型,用于语言表示的自我监督学习,该模型与 BERT 具有相同的架构主干。这一发展背后的关键目标是通过使用不同的技术来改进 BERT 架构的训练和结果,例如嵌入矩阵的分解、参数共享和句间连贯损失。
这篇文章将通过论文,解释模型的组件以及如何在项目中使用它。
现在,让我们开始吧!
强调
ALBERT 架构的主干与 BERT 相同。采用了一些设计选择,例如 i) 分解嵌入参数化、ii) 跨层参数共享和 iii) 句间一致性损失,以减少参数数量,从而减少内存消耗并提高训练速度伯特。
此外,还采用了一种自我监督的损失,专注于对句子间的连贯性进行建模,并证明它始终如一地促进具有紧随其后的多句子输入的任务。
仅 70% 左右的 BERT 参数,large 的 ALBERT-XXL 在几个具有代表性的下游任务的开发集得分方面优于 BERT-large,包括 SQuAD v1.1、SQuAD v2.0、MNLI、SST-2 和 RACE。
为什么我们需要一个类似 ALBERT 的模型?
考虑到当前最先进的模型通常具有数百甚至数十亿个参数,因此在我们扩展模型时可能会遇到内存限制。此外,分布式训练也会减慢训练速度,因为通信开销与模型中的参数数量成正比。
上述问题的现有解决方案包括模型并行化和智能内存管理。这些解决方案处理的是内存限制问题,而不是通信开销。提出了“A Lite BERT”(ALBERT)的架构来解决这个问题。
ALBERT 模型架构
ALBERT 架构的主干与 BERT 相同,后者使用具有 GELU 非线性的变压器编码器。
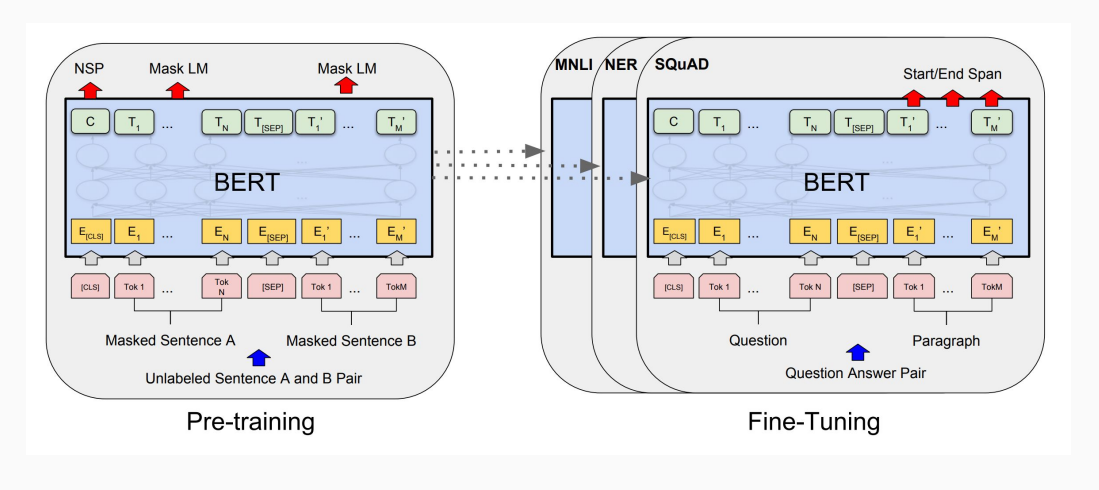
图 1:ALBERT 模型架构与 BERT 模型架构相同
以下是 ALBERT 对 BERT 的设计选择做出的三个主要贡献:
i) 分解嵌入参数化:在 BERT 以及后来的建模改进(如 XLNet 和 RoBERTa)中,WordPiece 嵌入大小 E 和隐藏层大小 H 捆绑在一起,即 E ≡ H。然而,无论是在建模方面还是在就应用而言,这种策略被证明是次优的。
通过将大词汇嵌入矩阵分解为两个小矩阵,隐藏层大小与词汇嵌入大小无关。这种分离有助于增加隐藏大小,而不会显着增加词汇嵌入的参数大小。当 H >>E 时,此参数减少是显着的。
ii) 跨层参数共享:跨层参数共享是另一种提高参数效率的技术。
参数可以通过不同的方式共享:
- 通过仅在各层之间共享前馈网络 (FFN) 参数,
- 只共享注意力参数,
- 通过跨层共享所有参数。
ALBERT 的默认方法是跨层共享所有参数。
后来在测试中发现权重共享会影响稳定网络参数。尽管与 BERT 相比 L2 距离和余弦相似度有所下降,但它们仍然没有收敛到 0,即使在 24 层之后也是如此。
iii) 句间连贯损失:与 BERT 类似,ALBERT 在训练中也使用了 Masked Language 模型。然而,ALBERT 没有使用 NSP(下一个句子预测)损失,而是使用了一种称为 SOP(句子顺序预测)的新损失。
NSP 是一种二元分类损失,用于检查连贯性和确定下一个句子的主题。然而,SOP 只寻找句子连贯性并避免主题预测。
与 BERT 一样,SOP 损失使用正例(来自同一文档的两个连续段)和负例(相同的两个连续段,但它们的顺序交换了)。这迫使模型发现有关话语级连贯性属性的细微差别。在测试中,结果表明NSP 根本无法解决 SOP 任务(即,它学习更容易的主题预测信号并在随机基线水平上完成 SOP 任务),而 SOP 可以将 NSP 任务解决到显着程度。因此,ALBERT 模型不断提高多句编码任务的下游任务性能。
注意:参数缩减方法还可以作为一种正则化,使训练保持稳定并有助于泛化。由于这些设计选择,人们可以扩展到相当大的 ALBERT 配置,这些配置仍然比 BERT-large 具有更少的参数,但实现了明显更好的性能。
ALBERT Vs. BERT
与 BERT 一样,ALBERT 在包含 16 GB 未压缩数据的英语维基百科和 Book CORPUS 数据集上进行了预训练。
由于 ALBERT 架构中使用了参数缩减技术,与相应的 BERT 模型相比,ALBERT 模型的参数大小更小。例如,BERT base 的参数是 ALBERT base 的 9 倍,BERT Large 的参数是 ALBERT Large 的 18 倍。
仅 70% 左右的 BERT 参数,large 的 ALBERT-XXL 在几个具有代表性的下游任务的开发集得分方面优于 BERT-large,包括 SQuAD v1.1、SQuAD v2.0、MNLI、SST-2 和 RACE。
与等效的 BERT 模型相比,ALBERT 模型由于更少的通信和计算开销而具有更高的数据吞吐量。例如,如果使用 BERT-large 作为基线,ALBERT-large 在迭代数据时要快约 1.7 倍,而 ALBERT-XXL 由于结构较大而慢约 3 倍。
限制和偏见
即使用于该模型的训练数据相当中性,该模型仍有可能做出有偏见的预测。
如何在项目中使用 ALBERT?
Huggingface 的 Transformers 库提供了不同版本和大小的各种 ALBERT 模型。出于演示目的,在这篇文章中,我们将重点介绍如何加载模型和预测掩码。
首先,我们必须首先安装和导入所有必要的包,并分别从 AlbertForMaskedLM 和 AutoTokenizer 加载模型及其标记器。然后,我们将整个输入(具有掩码)通过分词器以提取分词输出,然后将其用于预测掩码输入。
!pip install -q transformers#Importing the required packages
import torch
from transformers import AutoTokenizer, AlbertForMaskedLM
#Loading the model and the corresponding tokenizer
model_name = "albert-base-v2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AlbertForMaskedLM.from_pretrained(model_name)# Adding mask token
inputs = tokenizer("The capital of [MASK] is Delhi.", return_tensors="pt")
with torch.inference_mode():
logits = model(**inputs).logits# Retrieving the index of [MASK]
mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
tokenizer.decode(predicted_token_id)> 输出:印度
您可以在此处使用上述代码:https ://colab.research.google.com/drive/1bvrJFj-A6eV9MhHbnqbTO27G7VTjPdaW?usp=sharing 。
结论
总而言之,在本文中,我们学到了以下内容:
- ALBERT 架构的主干与 BERT 相同,后者使用具有 GELU 非线性的变压器编码器。此外,与 BERT 类似,ALBERT 在英文维基百科和 Book CORPUS 数据集上进行了预训练,包含 16 GB 的未压缩数据。
- 几种设计选择,如 i) 分解嵌入参数化、ii) 跨层参数共享和 iii) 句间连贯损失,用于模型参数减少。
- 仅 70% 左右的 BERT 参数,large 的 ALBERT-XXL 在几个具有代表性的下游任务的开发集得分方面优于 BERT-large,包括 SQuAD v1.1、SQuAD v2.0、MNLI、SST-2 和 RACE。
- 与等效的 BERT 模型相比,ALBERT 模型由于更少的通信和计算开销而具有更高的数据吞吐量。例如,如果使用 BERT-large 作为基线,ALBERT-large 在迭代数据时要快约 1.7 倍,而 ALBERT-XXL 由于结构较大而慢约 3 倍。
- 即使用于该模型的训练数据相当中性,该模型仍有可能做出有偏见的预测。
这篇文章到此结束。谢谢阅读。如果您有任何问题或疑虑,请在下面的评论部分发表。快乐学习!
原文标题:ALBERT Model for Self-Supervised Learning
原文作者:Drishti Sharma
原文地址:https://www.analyticsvidhya.com/blog/2022/10/albert-model-for-self-supervised-learning/
