




介绍
神经网络(Artificial Neural Networks)是模仿人脑操作来解决普通算法无法解决的复杂问题的方法或算法。
神经网络中的感知器是一个单元或算法,它接受输入值、权重和偏差,并进行复杂的计算以检测输入数据中的特征并解决给定问题。它用于解决有监督的机器学习问题,例如分类和回归。它被设计为一种算法,但它的简单性和准确的结果被认为是神经网络的构建块。我们也可以称其为机器学习模型或数学函数。
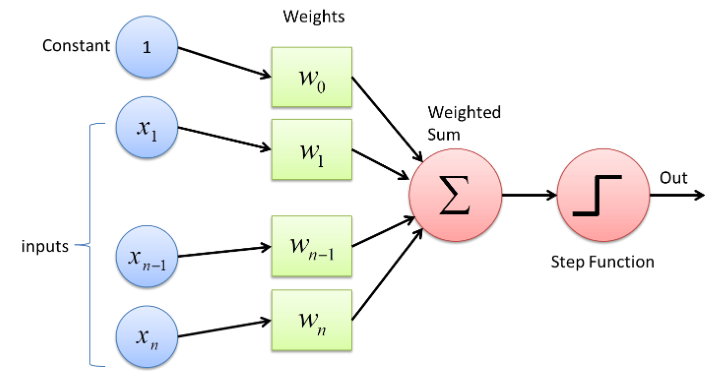
权重和偏差(表示为 w 和 b)是神经网络的可学习参数。权重是神经网络中将输入数据传递到包含信息权重的下一层的参数,权重越多意味着重要性越高。我们可以将偏差视为由恒定偏差值有效转置的线性线函数。
神经元是人工神经网络的基本单元,它接收并将权重和偏差从前一层传递到下一层。在一些复杂的神经网络问题中,我们考虑增加每个隐藏层的神经元数量以实现更高的精度值,因为每层的节点数量越多,从数据集中获得的信息就越多。尽管如此,在每层节点的一些值之后,模型的准确性仍然无法提高。然后我们应该尝试其他方法来获得更高的准确度值,例如增加隐藏层、增加 epoch 数、尝试不同的激活函数和优化器等。
以上是具有 Xn 个输入和一个常数的感知器的简单架构。每个输入都有其权重,常数将是其权重 (W0) 或偏差 (b)。这些权重和偏差将传递给 Summation (Sigma),然后传递给激活函数(在本例中为 Step Function),这将为我们提供数据的最终输出。
这里权重和偏差的总和作为输入进入激活函数。求和函数将如下所示:
Z = W 1 X 1 + W 2 X 2 + b
现在激活函数将 Z 作为输入并将其带入特定范围。不同的激活函数为此过程使用不同的函数。
多层感知器
单层感知器的唯一问题是它不能捕捉数据集的非线性,因此不能在非线性数据上给出好的结果。这个问题可以通过多层感知轻松解决,在非线性数据集上表现非常好。
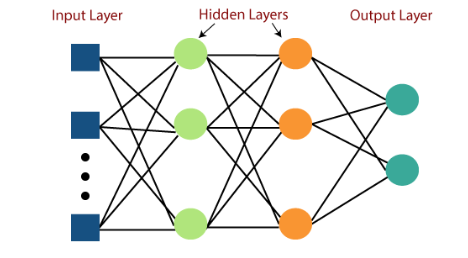
全连接神经网络 (FCNN) 是一种人工神经网络,其架构使得一层中的所有节点或神经元都连接到下一层中的所有神经元。
多层感知器是一组输入和输出层,可以有一个或多个隐藏层,每个隐藏层有几个神经元堆叠在一起。并且多层神经网络可以具有施加阈值的激活函数,例如 ReLU 或 sigmoid。多层感知器中的神经元可以使用任意激活函数。
在上图中,我们可以看到全连接的多层感知器具有一个输入层、两个隐藏层和最终输出层。隐藏层和层中节点数量的增加有助于捕获数据集的非线性行为并提供可靠的结果。
MLP 符号
使用神经网络时最难理解的事情是我们用来训练神经网络以递归更新权重和偏差并达到最高准确度的反向传播算法。
现在在训练神经网络时,神经网络中存在大量的权重和偏差,而反向传播也是更新权重和偏差的过程,因此所有不同的权重和偏差的符号成为理解的先决条件神经网络反向传播的核心直觉。
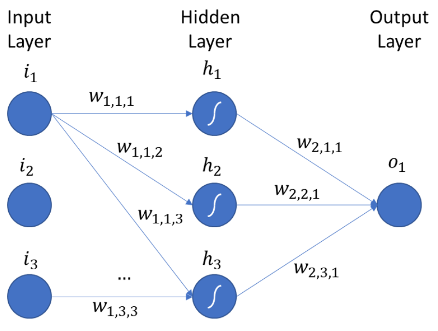
上图显示了具有输入层、隐藏层和输出层的多层神经网络。
1. 重量符号:
符号:W ij h
在那里,
i = 权重从哪个节点传递到下一层的节点。
j = 权重到达的节点。
h = 重量到达的层。
例子:
W 11 1 = 权重传递到前一层的第一个节点的第一个节点的第一个节点。
W 23 1 = 权重从前一层的第 2 个节点传入第 1 个隐藏层的第 3 个节点。
W 45 1 = 权重从前一层的第 4 个节点传递到第 2 个隐藏层的第 5 个节点。
2. 偏差符号:
符号:b ij
在那里,
i = 偏差所属的层。
j = 偏差所属的节点。
例子:
b 11 = 第一个隐藏层的第一个节点的偏差。
b 23 = 第二个隐藏层的第三个偏差。
b 41 = 第 4 个隐藏层的第一个节点的偏差。
3. 输出符号:
符号:O ij
在那里,
i = 偏差所属的层。
j = 偏差所属的节点。
例子:
O 11 = 第一个隐藏层的第一个节点的输出。
O 45 = 第 4 个隐藏层的第 5 个输出。
O 34 = 第三隐藏层第四节点的输出。
计算总可训练参数
人工神经网络 2 层之间给定的总可训练参数是它们之间存在的总权重和总偏差的总和。
神经网络中两层之间的总可训练参数 = [第一层中的节点数 * 第二层中的节点数](权重)+ [第二层中的节点数](偏差)
1.输入层和第一隐藏层之间的可训练参数:
权重 = 3 * 4 = 12
偏差 = 4(第一个隐藏层中的 4 个节点)
可训练参数 = 权重 + 偏差
= 12 + 4
= 16
2.第一隐藏层和第二隐藏层之间的可训练参数:
权重 = 4 * 2 = 8
偏差 = 2(第一个隐藏层中的 2 个节点)
可训练参数 = 权重 + 偏差
= 8 + 2
= 10
3. 第二隐藏层和输出层之间的可训练参数:
权重 = 2 * 2 = 4
偏差 = 2(第一个隐藏层中的 2 个节点)
可训练参数 = 权重 + 偏差
= 4 + 2
= 6
结论
在本文中,我们首先研究了神经网络、感知器、多层感知器的一些基本概念,以及计算神经网络总可训练参数的方法,包括多层感知器中权重、偏差和输出的表示法。关于这个关键概念的知识不仅有助于避免人们对神经网络的一些误解,而且有助于理解神经网络的一些核心概念(例如,反向传播)。
主要见解是:
1. 感知器是神经网络的基本组成部分,具有简单易懂的架构。
2. 当感知器由于数据集的非线性而失效时,可以使用多层感知器。
3. 每个使用神经网络的人都应该知道输入、输出和权重的符号,以避免在理解神经网络架构时产生误解。
4. 可以计算单个或多个隐藏层的总可训练参数,以清楚了解特定神经网络中包含的参数。
原文标题:Multi-Layer Perceptrons: Notations and Trainable Parameters
原文作者:Parth Shukla
原文地址:https://www.analyticsvidhya.com/blog/2022/10/multi-layer-perceptrons-notations-and-trainable-parameters/
