




介绍
自 1970 年代以来,关系数据库管理系统已经解决了存储和维护大量结构化数据的问题。随着大数据的出现,一些组织意识到大数据处理的好处,并开始选择像 Hadoop 这样的解决方案来解决大数据问题。Apache Hadoop 使用分布式文件系统以分布式方式存储大数据,并使用 MapReduce 框架对其进行处理。Hadoop 可以以结构化、半结构化或非结构化格式存储和处理大量数据。但是Apache Hadoop只能做批处理,我们只能顺序访问数据。
.png)
对于简单的工作,我们必须搜索整个数据集。当我们在 Hadoop 中处理一个巨大的数据集时,它会产生另一个巨大的数据集,我们必须按顺序处理这个数据集。正因为如此,Hadoop 不太适合记录检索、更新和增量添加小批量。因此需要一种新的解决方案,允许我们在单位时间内访问任何数据点。CouchDB、HBase、Cassandra、MongoDB 和 Dynamo 等应用程序应运而生。这些数据库可以存储大量数据并允许随机访问数据。现在让我们看一下HBase的介绍。
什么是 Apache HBase?
HBase 是一个用 Java 编写的开源、分布式、可扩展的 NoSQL 数据库。HBase 运行在 Hadoop 分布式文件系统之上,并提供随机读写访问。它是一种类似于谷歌大表的数据模型,旨在提供对大量结构化数据的快速随机访问。HBase 利用了 HDFS 提供的容错能力。它旨在实现存储大量稀疏数据集的容错方式。
HBase 是需要快速随机访问大量数据的应用程序的完美选择。HBase 通过对大数据提供更快的读写访问来实现低延迟和高吞吐量。
您可以直接或通过 HBase 将数据存储在 HDFS 中。使用 HBase,我们可以读取 HDFS 中的数据或随机访问它。
我们可以在哪里使用 HBase?
它并不适合所有问题。假设我们有数亿或数十亿行,想要快速读取数据;最好使用 HBase。主要用于实时对大数据进行随机读写访问。
当您想要存储大量数据并需要高可扩展性时,您可以使用 HBase。我们只有在没有传统数据库系统的所有其他特性(例如类型列、事务、高级查询语言、二级索引等)的情况下才能使用它。
如果我们有很多版本化的数据并且想要全部保存,这是一个不错的选择。如果你想要面向列的数据,你可以选择 HBase。现在让我们看看 HBase 中的存储机制。
HBase 数据模型
HBase 是一个面向列的数据库。面向列的数据库将数据存储在分组为列而不是行的单元格中。
让我们看一下 HBase 中数据组织的整个概念视图。
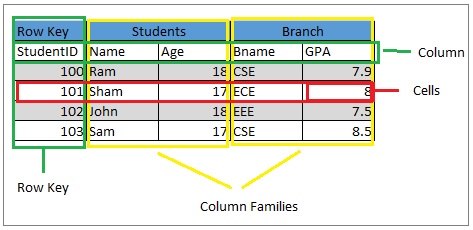
1. 表和 2. 行
Hbase 表中的几行是多行的。列具有分配给它们的值。HBase 按行键按字母顺序对行进行排序。
主要目标是存储数据,以便相关行更靠近。站点的域用作常见的行键模式。例如,如果我们的行键是域,我们应该将它们反向存储,即 org.apache.www 或 org.apache.mail 或 org。Apache.Jira。这样,所有 Apache 域在 HBase 表中都彼此靠近。
3.专栏
HBase 列由一个列族和一个由 :(冒号)字符分隔的列限定符组成。
A. 列族
列族物理上包含一组列及其值;那么,每个列族都有一组存储属性,比如它的数据是如何压缩的,它的值是否应该被缓存,它的行键是如何编码的等等。HBase 表中的每一行都具有相同的列族。
湾。栏目资质
将用于限定的列限定符添加到列族以提供该数据部分的索引。
示例:列族是内容,那么列限定符可以是内容:HTML 或内容:pdf。
列族在表创建期间是固定的,但列限定符是可变的并且在行之间变化很大。
4. 细胞
单元格本质上是行、列族和列限定符的组合。包含一个值和一个表示该值版本的时间戳。
5. 时间戳
时间戳是给定值版本的标识符,写在每个值旁边。时间戳默认表示写入数据时 RegionServer 上的时间。但是,我们可以在将数据插入单元格时指定不同的时间戳值。
Apache HBase 架构
HBase 由三个主要组件组成:HBase Region Server、HMaster Server and Regions 和 Zookeeper。让我们仔细看看这些组件中的每一个。
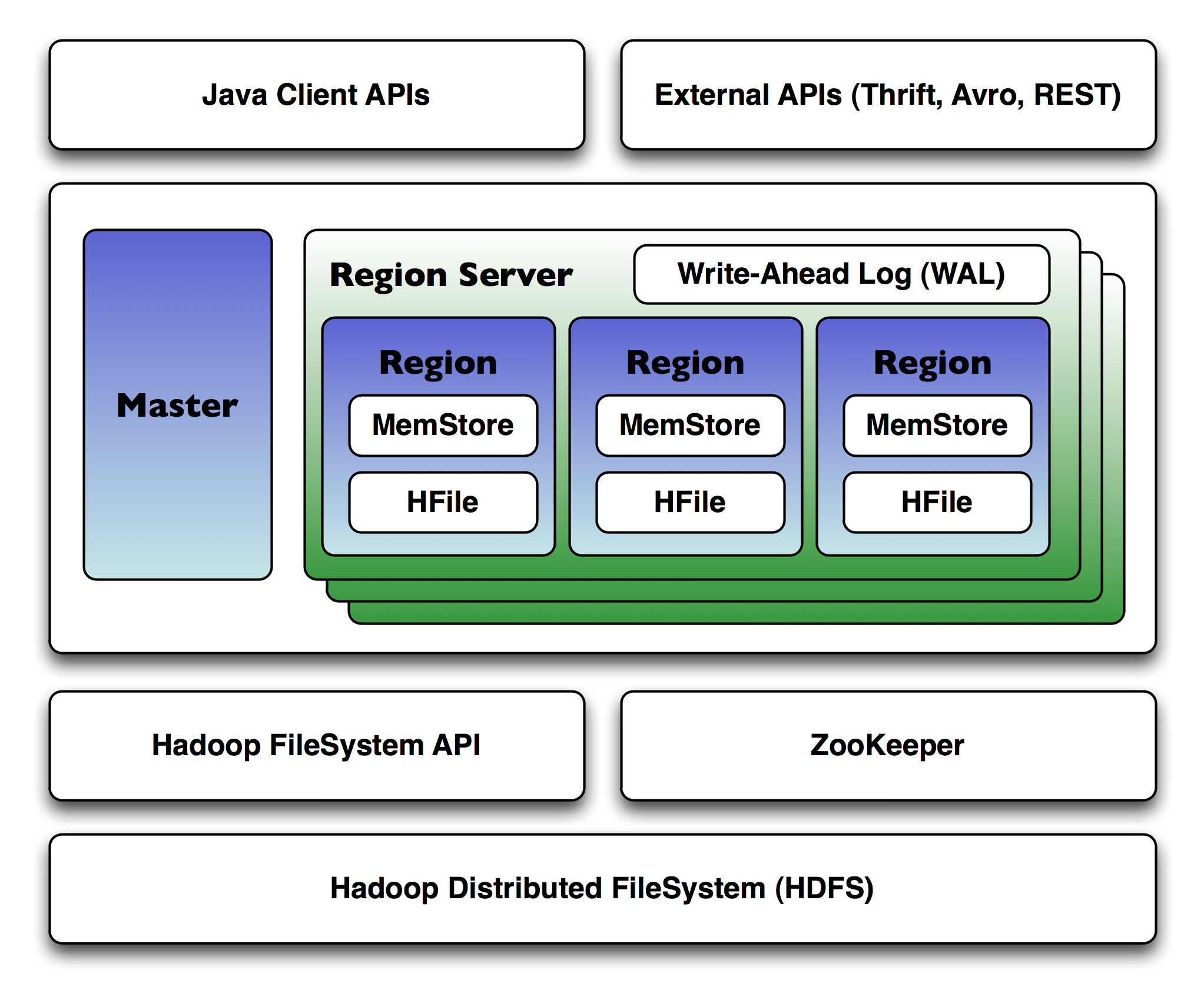
1.HBase区域
范围是在开始键和结束键之间存储数据的有序行范围。HBase 中的表分为几个区域。
默认区域大小为 256 MB,我们可以根据需要进行配置。Region Server 有一组供客户端使用的区域。Region Server 可以为客户端提供大约 1000 个区域。
2.HBase HMaster
HBase 中的 HMaster 处理驻留在 DataNode 中的 Region Server 集合。HBase HMaster 执行 DDL 操作并将区域分配给区域服务器。协调和管理区域服务器。
HMaster 在启动期间将区域分配给区域服务器,并在恢复和负载平衡期间将区域重新分配给区域服务器。它负责监控集群中的所有 Region Server 实例。它在 Zookeeper 的帮助下执行此操作,并在任何 Region Server 发生故障时执行恢复机制。HMaster 提供了创建、更新和删除表的接口。
3. HBase ZooKeeper – 协调器
Zookeeper 在分布式 HBase 环境中充当协调器。它通过会话通信来帮助维护集群内的服务器状态。
每个 Region Server 和 HMaster 服务器都会定期向 Zookeeper 发送连续的心跳。Zookeeper 检查哪个服务器处于活动状态且可用。Zookeeper 提供服务器故障通知,以便 HMaster 可以采取恢复措施。Zookeeper 还维护到 .META 服务器的路径。这有助于客户搜索任何区域。
4. HBase 元表
META 表是一个特殊的 HBase 目录表,它维护着 HBase 存储系统中所有区域服务器的列表。一个 。META 文件以键和值的形式管理表。该键将表示 HBase 区域的初始键及其 id。该值将包含区域服务器的路径。
Apache HBase 属性
Apache的基本属性可以定义如下。
- 原子读写:行级的原子读写。这意味着在一个读/写过程中,它会阻止所有其他进程执行任何读/写操作。
- 一致的读和写:由于上述特性,Apache HBase 提供了一致的读/写。
- 线性和模块化的可扩展性:因为 HBase 在 HDFS 之上运行,所以数据集分布在 HDFS 上。这使得 HBase 可以跨多个节点线性扩展。此外,它是模块化可扩展的。
- 易于使用的 Java API 用于客户端访问:HBase 提供了易于使用的 Java API 用于编程访问。
- Thrift 网关和 REST-ful Web 服务:HBase 还支持用于非 Java 前端的 Thrift 和 REST API。
- 块缓存和布隆过滤器:支持块缓存和布隆过滤器以优化大查询量。
- 自动故障转移支持:具有 Hadoop 分布式文件系统的 Apache HBase 提供跨集群的 WAL(预写日志),从而提供自动故障转移支持。
- 排序的行键:HBase 按字典顺序存储行键。使用排序的行键和时间戳,我们可以创建优化的请求。
- 数据复制:HBase 提供跨集群的数据复制。
- 分片:HBase 提供自动和手动将区域划分为更小的子区域,以减少 I/O 时间和开销。
Apache HBase 应用程序
我们可以在许多领域使用 HBase。HBase 在各个领域的一些应用是:
- 医学:医学部门使用 Apache HBase 存储基因组序列并运行 MapReduce。他们用它们来存储人们疾病和许多其他疾病的历史。
- 体育:我们可以使用 HBase 存储比赛历史,以进行更好的分析和预测。
- 石油和石油:它也用于石油和石油工业来存储勘探数据。这样做是为了分析和预测可能存在石油的位置。
- 电子商务:电子商务行业使用HBase来记录和存储客户搜索历史的日志。他们这样做是为了执行数据分析以瞄准感兴趣的受众以获取利润。
- 其他领域:我们可以在我们想要存储 PB 级数据并对其进行分析的其他领域使用 HBase,这对于 RDBMS 来说可能需要几个月的时间。
- Facebook、Yahoo、Twitter、Infolinks 和 Adobe 等公司在内部使用 Apache HBase。
Apache HBase 的限制
HBase 有很多好处,但也有一些限制。让我们一一来看。
- HBase 不提供对传统数据库系统的某些特性的支持。
- HBase 无法执行 SQL 之类的功能。它不支持 SQL 结构,因此没有查询优化器。
- HBase 是 CPU 和内存密集型的。
- HBase 与 Hive 和 Pig 工作负载的集成将导致一些集群计时问题。
- HBase 设置将需要更少的作业槽来在共享集群环境中分配 HBase CPU 请求。
- HBase 的成本和维护成本太高。
- Hbase 每个表仅支持一个默认排序规则。
- Hbase 表中的连接和规范化非常复杂。
结论
我们可以说 Apache HBase 是一个运行在 Hadoop 分布式文件系统之上的 NoSQL 数据库。提供 Hadoop 框架的 BigTable 功能。它由 HMaster Server、HBase Region Server、Regions 和 Zookeeper 组成。文章包括 HBase 和 RDBMS 的区别以及 HBase 和 HDFS 的区别。HBase 提供一致的读取和写入。它是开源和可扩展的。我们可以在很多行业使用 HBase,包括医药、体育、电商等。
- 范围是在开始键和结束键之间存储数据的有序行范围。HBase 中的表分为几个区域。默认区域大小为 256 MB,我们可以根据需要进行配置。Region Server 有一组供客户端使用的区域。Region Server 可以为客户端提供大约 1000 个区域。
- CouchDB、HBase、Cassandra、MongoDB和 Dynamo 等应用程序应运而生。这些数据库可以存储大量数据并允许随机访问数据。现在让我们看一下HBase的介绍。
- HMaster 在启动期间将区域分配给区域服务器,并在恢复和负载平衡期间将区域重新分配给区域服务器。它负责监控集群中的所有 Region Server 实例。
原文标题:A Brief Introduction to Apache HBase and it’s Architecture
原文作者:Trupti Dekate
原文链接:https://www.analyticsvidhya.com/blog/2022/10/a-brief-introduction-to-apache-hbase-and-its-architecture/
