




数据仓库、数据湖和数据流的概念和体系结构是对解决业务问题的补充。存储静态数据以进行报告和分析需要不同的功能和 SLA,而不是连续处理实时工作负载的动态数据。存在许多开源框架,商业产品和SaaS云服务。不幸的是,底层技术经常被误解和过度使用,用于单片和不灵活的架构,供应商推销错误的用例。让我们在博客系列中探讨这个困境。了解如何使用云原生技术构建现代数据堆栈。
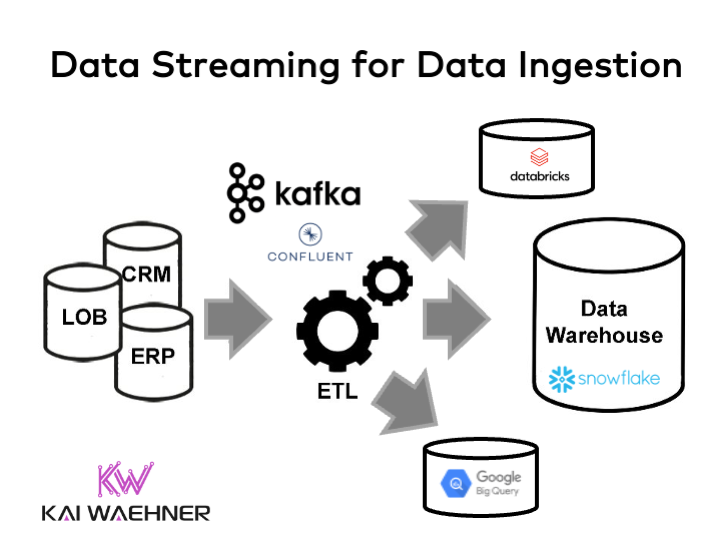
通过数据流实现可靠且可扩展的数据引入
可靠且可扩展的数据引入对于任何分析平台都至关重要,无论您是构建数据仓库、数据湖还是湖屋。
分析领域几乎非常主要的参与者重新设计了现有平台,以实现(近乎)实时的数据摄取,而不仅仅是批量集成。
数据引入 = 数据集成
仅仅从A到B获取数据通常是不够的。与提取、转换、加载 (ETL) 工作流的数据集成连接到各种源系统并处理传入事件,然后再将其引入一个或多个数据接收器。但是,大多数人在讨论数据引入时都会考虑消息队列。相反,良好的数据引入技术提供了其他功能:
- 连接性:连接器可实现与任何数据源和数据接收器的快速、可靠的集成。如果连接器可用,请不要构建自己的连接器!
- 数据处理:集成逻辑筛选、丰富或聚合来自一个或多个数据源的数据。
- 数据共享:跨区域、数据中心和多云复制数据。
- 经济高效的存储:真正将数据源与各种下游消费者(分析平台、业务应用程序、SaaS 等)分离
Kafka 不仅仅是数据引入或消息队列。卡夫卡是一个云原生中间件:
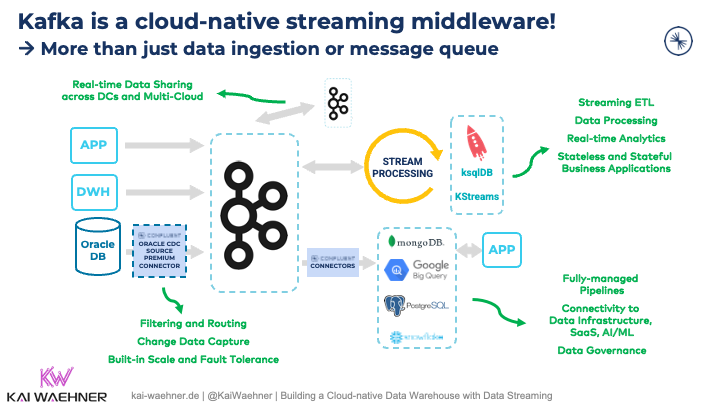
一个常见的选项是在数据仓库或数据湖中运行 ETL 工作负载。消息队列足以用于数据引入。即使在这种情况下,大多数项目也使用数据流平台Apache Kafka作为数据摄取层,即使许多伟大的Kafka功能都以这种方式被忽略。
相反,在数据引入管道中运行 ETL 工作负载具有以下几个优点:
- 处理层和存储层之间的真正分离可实现可扩展且经济高效的基础架构。
- ETL 工作负载是实时处理的,无论每个下游应用程序提供什么速度。
- 每个消费者(数据仓库、数据湖、NoSQL 数据库、消息队列)都可以自由选择技术/API/编程语言/通信范例来决定如何以及何时读取、处理和存储数据。
- 下游消费者在原始数据和精选的相关数据集之间进行选择。
静态还是动态数据集成?
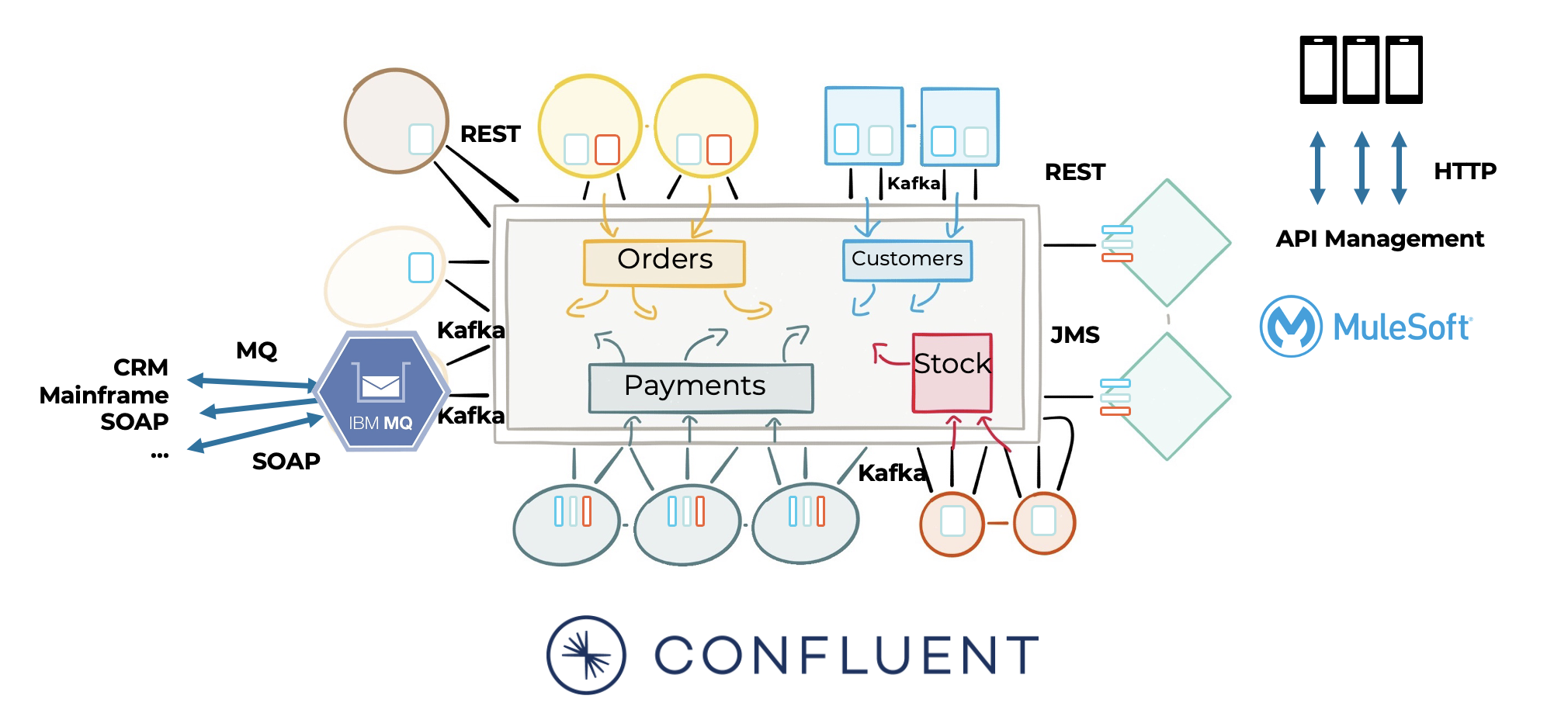
ETL 并不是什么新鲜事。来自信息网、TIBCO 和其他供应商的工具为构建数据管道提供了出色的可视化编码。云的演变为我们带来了云原生替代品,如SnapLogic或繁荣。像 MuleSoft 这样的 API 管理工具是基于 API 和点对点集成的集成层构建的另一个常用选项。
这些工具的巨大好处是可以更好地将构建和维护管道的上市时间缩短。但是,存在一些缺点:
- 独立的基础设施来运营和支付。
- 与本机流引入层(如 Kafka 或 Kinesis)相比,使用专用中间件的可伸缩性和/或延迟通常有限。
静态数据存储在单独的存储系统中。 - 与 Web 服务和点对点连接紧密耦合。
- 集成逻辑在于中间件平台、专业知识和专有工具,无法自由选择实施数据集成。
好消息是你有选择的自由。如果基础架构的核心是实时和可扩展的,那么您不仅可以添加可扩展的实时应用程序,还可以添加任何基于批处理或API的中间件:
通过 API 管理进行的点对点集成是对数据流的补充,而不是竞争。
用于多云数据引入的数据网格
数据网格是软件行业的最新流行语。它结合了域驱动的设计、数据集市、微服务、数据流和其他概念。像Lakehouse一样,数据网格是一个逻辑概念,而不是使用单一技术构建的物理基础设施! 我探讨了使用Apache Kafka进行数据流在数据网格架构中扮演的角色。
总之,Kafka的特性,如真正的解耦,背压处理,数据处理以及与实时和非实时系统的连接,使分布式全球数据架构的构建成为可能。
以下是跨云提供商和区域使用融合云和数据砖构建的数据网格的示例:
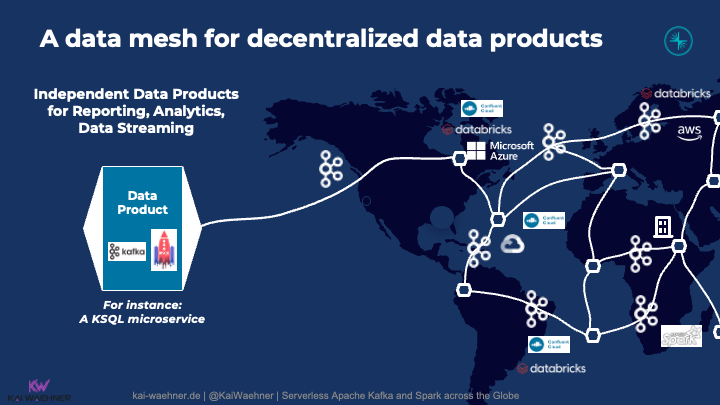
作为数据引入层的数据流在多云和/或多区域环境中扮演着许多角色:
- 云和/或区域之间的数据复制。
- 与各种源应用程序的数据集成(直接或通过第三方 ETL/iPaaS 中间件)。
- 在本地区域进行预处理,以降低数据传输成本并改善区域之间的延迟。
- 将数据引入到一个或多个数据仓库和/或数据湖中。
- 为慢速消费者或在互联网连接断开的情况下在区域之间进行背压处理。
在此示例中,数据流的强大功能变得更加明显:数据引入或消息队列本身对于大多数“数据引入项目”来说还不够好!
Apache Kafka - 数据引入湖屋的事实标准
Apache Kafka是数据流的事实标准,一个关键用例是数据摄取。Kafka 连接可在任何规模下实现可靠的实时集成。它会自动处理故障、网络问题、停机时间和其他操作问题。搜索您喜欢的分析平台,并查看 Kafka 连接连接器的可用性。您很有可能会找到一个。
与其他数据摄取引擎(如 AWS Kinesis)相比,Kafka的关键优势包括:
- 真正的分离:将数据引入数据仓库通常只是数据接收器之一。大多数企业将数据引入各种系统,并使用相同的 Kafka 基础结构和 API 构建新的实时应用程序。
- 跨多云和混合环境的开放式 API:Kafka 可以部署在任何地方,包括任何云提供商、数据中心或边缘基础设施。
- 成本效益:与 Kinesis 和类似工具相比,扩展的越多,Kafka 工作负载的成本效益就越高。
- 流平台中的长期存储:Kafka 内置了历史数据的可重放性和针对慢速使用者的背压处理(如果您利用分层存储,则具有成本效益)。
- 在单个基础架构中进行预处理和 ETL:传入的数据可以使用 Kafka Streams 或 ksqlDB 等工具进行动态处理,而不是将大量原始数据引入各种静态系统。每个消费者选择他们需要的策划或原始数据进行进一步分析 - 实时,近乎实时的批处理或请求 - 响应。
Kafka作为数据摄取和 ETL 中间件与卡夫卡连接和 KsqlDB
Kafka 提供了许多人在开始时经常低估的两个功能(因为他们认为 Kafka 只是一个消息队列):
数据集成:Kafka连接是一种工具,用于在Kafka和其他数据系统之间可扩展且可靠地流式传输数据。通过 Kafka 连接,可以轻松快速地定义将大型数据集移入和移出 Kafka 的连接器。
流处理:Kafka 流是用于构建无状态或有状态应用程序和微服务的客户端库,其中输入和输出数据存储在 Kafka 群集中。ksqlDB 建立在 Kafka 流之上,利用您对关系数据库和 SQL 的熟悉程度来构建数据流应用程序。
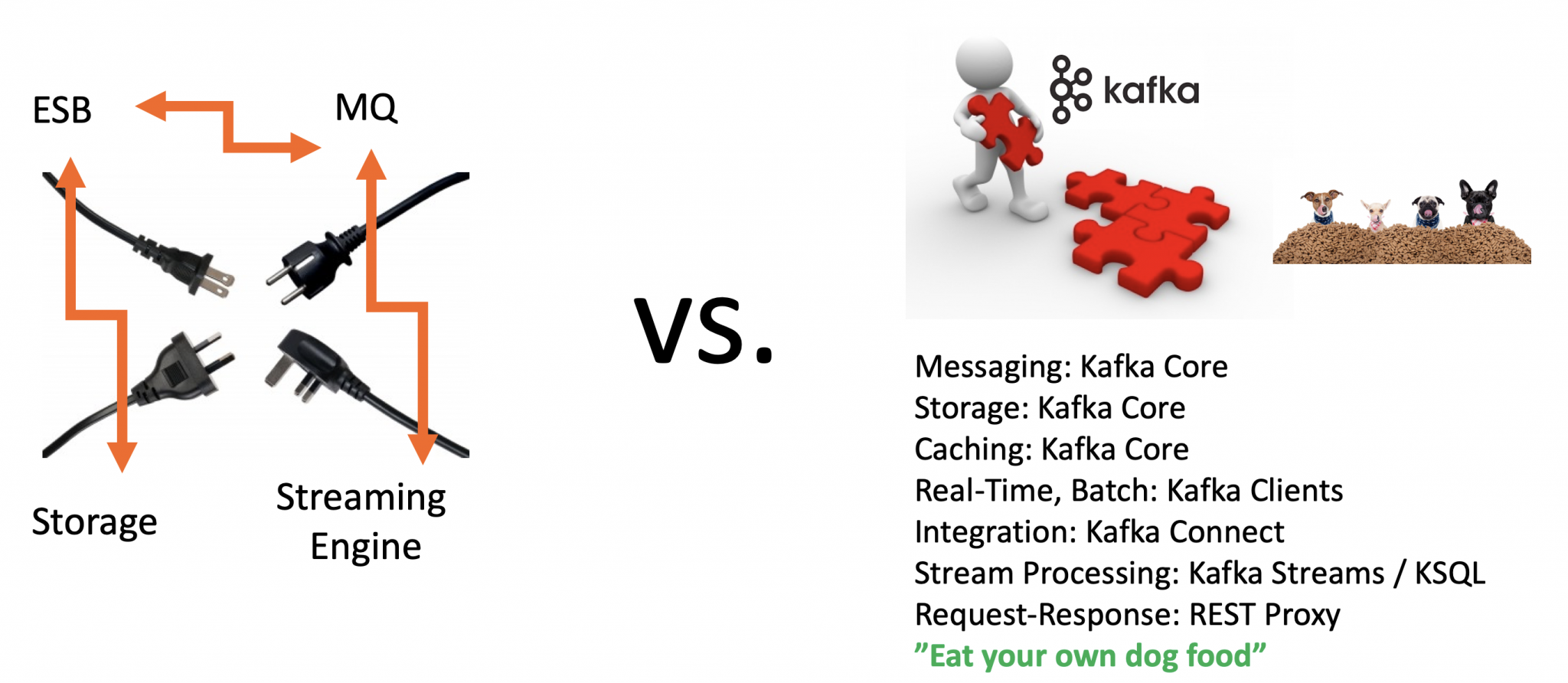
请注意,Kafka连接不仅仅是一组连接器。底层框架提供了许多其他中间件功能。查看单消息转换 (SMT)、死信队列、架构验证以及 Kafka 连接的其他功能。
Kafka作为云原生中间件
使用Kafka的数据流通常取代了 ETL 工具和 ESB。以下是主要原因:
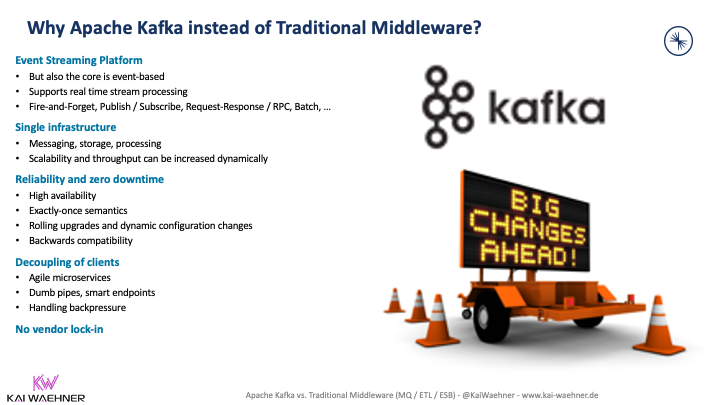
有些人认为数据流是一个集成平台即服务(iPaaS)。我不能完全同意这一点。这些论点与说卡夫卡是一个ETL工具非常相似。这些截然不同的技术与其他特征(和权衡)相得益彰。
使用Kafka进行数据摄取的参考体系结构
让我们探讨一下使用Apache Kafka和Kafka连接进行数据摄取的两个示例架构:弹性搜索数据流和数据砖三角洲湖。这两种产品都服务于非常不同的用例,并且需要不同的数据引入策略。
开发人员可以对不同的连接器使用相同的 Kafka 连接 API。在引擎盖下,实现看起来非常不同,以满足不同的需求和SLA。
两者都使用高级体系结构图上的专用 Kafka 连接连接器。在后台,必须根据项目要求和数据接收器功能配置引入速度、索引策略、交付保证和许多其他因素。
数据引入示例:使用 Kafka 和弹性搜索数据流进行实时索引
我最喜欢的例子之一是弹性搜索。当然,搜索引擎以批处理模式构建索引。因此,第一个 Kafka 连接连接器以批处理模式引入事件。但是,Elastic 创建了一种称为 Elasticsearch 数据流的新实时索引策略,以便为最终用户提供更快的查询和响应时间。
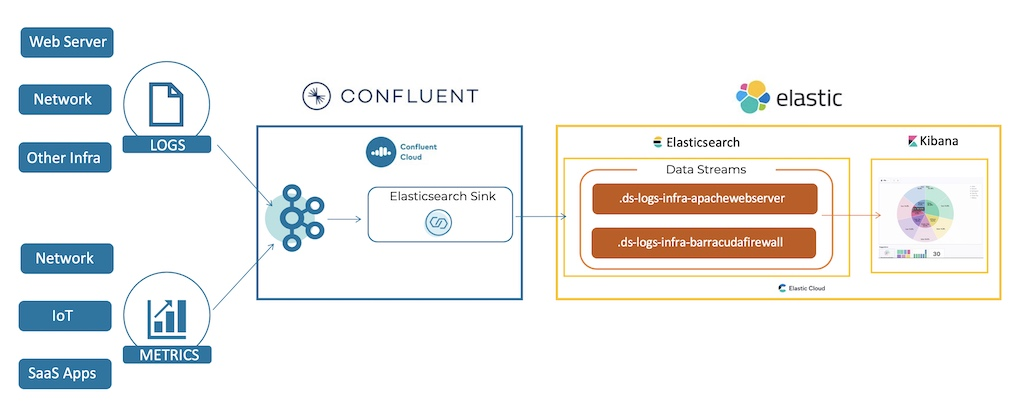
借助 Elastic 数据流,您可以跨多个索引存储仅追加时序数据,同时为您提供单个命名的请求资源。数据流非常适合日志、事件、指标和其他连续生成的数据。您可以将索引和搜索请求直接提交到数据流。流会自动将请求路由到存储流数据的后备索引。Kafka 数据流是弹性数据流的理想数据源。
数据引入示例:汇合和元数据砖
汇流与数据砖一起,是另一个很好的例子。许多人很难解释供应商的差异和独特的卖点。为什么?因为营销看起来非常相似:处理大数据,永久存储,实时分析,跨多云和多区域部署,等等。现实情况是,汇合和数据砖只重叠了约10%。两者相辅相成,效果很好。
汇流的重点是处理动态数据。数据砖的主要业务是存储静态数据以进行分析和报告。您可以在 Kafka 中存储长期数据(尤其是使用分层存储)。是的,您可以使用Spark流式处理数据砖(近乎)实时地处理数据。对于某些用例来说,这很好,但在大多数情况下,您(应该)选择并组合解决问题的最佳技术。
以下是使用融合和数据砖进行数据流和分析的参考架构:
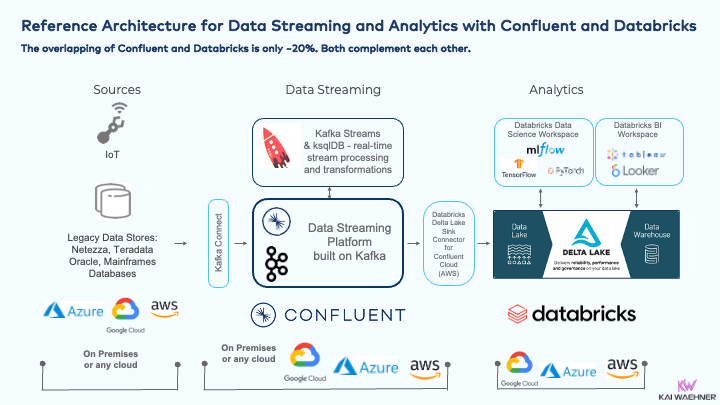
汇流和数据砖是现代机器学习架构的完美结合:
- 通过数据流进行数据引入。
- 数据湖中的模型训练。
- (流式传输或批处理)ETL 最适合用例的位置。
- 在靠近数据科学环境或数据流应用的数据湖中进行模型部署,以实现任务关键型 SLA 和低延迟。
- 通过数据流实时监控端到端管道(ETL、模型评分等)。
我希望很明显,像Confluent这样的数据流供应商与Databricks或Snowflake这样的数据仓库供应商具有非常不同的能力,优势和劣势。
数据流不仅仅是将数据引入湖屋
像Apache Kafka这样的数据流技术非常适合将数据引入一个或多个数据仓库和/或数据湖。但是,数据流远不止于此:与各种数据源集成、数据处理、跨区域或云的复制,以及最后将数据引入数据接收器。
与汇流、数据砖和弹性搜索等供应商合作的示例显示了数据流如何通过单一技术帮助解决许多数据集成挑战。
然而,没有银弹。现代化的湖畔别墅利用了同类最佳的技术。没有一种技术可以最好地处理各种数据集和通信范例(如实时、批处理和请求-响应)。
原文标题:Data Streaming for Data Ingestion Into the Data Warehouse and Data Lake
原文作者: Kai Wähner
原文地址:https://dzone.com/articles/data-streaming-for-data-ingestion-into-the-data-wa
