




这篇文章记录了我在 Postgres 中对 Timescale DB 扩展的初步探索。我感兴趣地观看了 Timescale 已经有一段时间了,但在此之前还没有真正尝试过它。我正在考虑将 Timescale 作为改进 OpenStreetMap 数据快照的长期存储的另一个可靠选择。自然,我使用的是启用了 PostGIS 且填充了 OpenStreetMap 数据的数据库。
我开始通过我的帖子Why Partition OpenStreetMap data?
https://blog.rustprooflabs.com/2021/02/postgres-postgis-why-partition-openstreetmap
重构我们的 OpenStreetMap 数据?那篇文章概述了我需要支持的历史用例。虽然我第一次尝试声明式分区(https://blog.rustprooflabs.com/2021/02/postgres-partition-openstreetmap-road-v1-review) 遇到了障碍,但我的第二次尝试(https://blog.rustprooflabs.com/2021/02/postgres-partition-openstreetmap-road-v2-review) 效果很好。这篇文章超越了我对该项目的初始要求,并确定了将 Timescale 添加到我们的数据库中的额外好处。
Timescale的好处
我将 Timescale 作为 Postgres 内置声明性分区的一个选项,主要有两个原因:
无需手动创建分区
压缩很诱人
必须手动创建具有 Postgres 声明式分区的新分区。语法不是很棘手,过程可以自动化,但它仍然存在,因此仍然需要管理。使用 Timescale 超大表时,新分区在幕后处理,无需我直接干预。Timescale 的另一个诱惑是它们对基于行的数据的列式压缩。在标准 Postgres 中,只有在行级别超过指定大小(默认为 2kb)时才开始压缩。请参阅我关于Postgres 中的大文本数据的帖子, 其中讨论了 Postgres 中的压缩。Timescale 一直在 写入 他们 的压缩 所以我想是时候试一试了。虽然压缩不是我概述的最初目标之一……但它会很好!
测试设置
我按照他们的说明在 Ubuntu 20.04 实例上安装了 Timescale 2.4.0 。我已经安装了 Postgres 13 和 PostGIS 3.1。安装 Timescale 后,需要更新postgresql.conf
文件以添加 timescaledb
到shared_preload_libraries
. 我一直启用pg_stat_statements
,所以我的设置行在postgresql.conf中如下所示:
shared_preload_libraries = 'pg_stat_statements,timescaledb'
现在 Timescale 扩展已准备好,我们数据库中创建和使用。
测试数据库有五 (5) 个模式,加载了科罗拉多州不同日期的 OpenStreetMap 数据。使用PgOSM Flex v0.2.1 和 osm2pgsql v1.5.0 将数据加载到 PostGIS。这些 OpenStreetMap 数据模式的总大小约为 8.6 GB,最新数据 ( osm_co20210816
) 占用 1,894 MB。
SELECT s_name, size_plus_indexesFROM dd.schemasWHERE s_name LIKE 'osm%'ORDER BY s_name;┌────────────────┬───────────────────┐│ s_name │ size_plus_indexes │╞════════════════╪═══════════════════╡│ osm_co20181210 │ 1390 MB ││ osm_co20200816 │ 1797 MB ││ osm_co20210316 │ 1834 MB ││ osm_co20210718 │ 1884 MB ││ osm_co20210816 │ 1894 MB │└────────────────┴───────────────────┘
这些来自科罗拉多州的快照是我收集多年来积累的 PBF 文件。通过 PgOSM Flex 加载的 Colorado 的当前大小接近 2GB。最终,我的计划是至少每季度对整个美国进行定期快照。当前加载到 PostGIS 的 OpenStreetMap US 区域需要 67 GB,未来一年可能会达到 70 GB。使用我以前的方案(无压缩)加载这些数据每年将占用近 300 GB 的磁盘空间。
OpenStreetMap tags
使用 PgOSM Flex 将 OpenStreetMap 加载到 PostGIS 会创建一个名为的表tags(https://github.com/rustprooflabs/pgosm-flex/blob/main/flex-config/style/tags.lua)
,该表 将每个要素的键/值数据存储在 JSONB 列中,也称为tags
. 数据是我熟悉 Timescale的tags
一个很好的起点,原因有两个:
osm.tags
是最大的表JSON 数据应该可以很好地压缩
我发现压缩的最佳候选也恰好是一个成比例的大表,这很方便。为了了解tags
表的起始大小,以下查询显示了osm_co20210816.tags
. 该表包含近 340 万行并占用 670 MB 磁盘空间,使该表占osm_co20210816
架构总大小的 35%!
SELECT t_name, rows, size_plus_indexes, descriptionFROM dd.tablesWHERE s_name = 'osm_co20210816'ORDER BY size_bytes DESCLIMIT 1;┌─[ RECORD 1 ]──────┬─────────────────────────────────────────────────────────┐│ t_name │ tags ││ rows │ 3,357,662│ size_plus_indexes │ 681 MB ││ description │ OpenStreetMap tag data for all objects in source file. …││ │… Key/value data stored in tags column in JSONB format. │└───────────────────┴─────────────────────────────────────────────────────────┘
tags
存储在表中的数据示例。
SELECT *FROM osm_co20210816.tagsWHERE osm_id = 709060219AND geom_type = 'W';┌─[ RECORD 1 ]────────────────────────────────────────────────────────────────────────────┐│ geom_type │ W ││ osm_id │ 709060219 ││ tags │ {"gauge": "1435", "usage": "main", "railway": "rail", "voltage": "25000", "…││ │…frequency": "60", "electrified": "contact_line", "railway:track_ref": "4"} ││ osm_url │ https://www.openstreetmap.org/way/709060219 │└───────────┴─────────────────────────────────────────────────────────────────────────────┘
tags
当主要特征表中 PgOSM Flex 定义的列不能满足您特定分析的需要时,这些数据很有帮助。
创建超大表
将tags
表格确定为我的起点,是时候进行测试了!我创建了一个以osmts
我的测试游乐场命名的模式。
CREATE SCHEMA osmts;COMMENT ON SCHEMA osmts IS 'Objects for OpenStreetMap data in Timescale hypertables, possibly with compression.';
osmts.tags
基于其中一个源表创建一个新tags
表。这使用 Postgres 的方便 LIKE source_table
语法,它允许我在源表中的列之前添加osm_date
和列。region
将非标准列添加到新表的开头可以使INSERT
语句在几个步骤中更易于编写和维护。的使用EXCLUDING INDEXES
允许为超表创建一个新的、更合适的主键。
CREATE TABLE osmts.tags(osm_date DATE NOT NULL,region TEXT NOT NULL,LIKE osm_co20210816.tags EXCLUDING INDEXES);COMMENT ON TABLE osmts.tags IS 'Hypertable for historic OpenStreetMap tag data for all objects in source file. Key/value data stored in tags column in JSONB format.';
使用该create_hypertable()
函数将osmts.tags
表转换为 Timescale 超大表。
SELECT create_hypertable('osmts.tags', 'osm_date');┌───────────────────┐│ create_hypertable │╞═══════════════════╡│ (1,osmts,tags,t) │└───────────────────┘
以下查询创建了一个新的PRIMARY KEY
,其中包含osm_date
和region
到方案中。我有意把它osm_date
放在最后,因为它已经有一个专门的索引。查询osmts.tags表时几乎总是使用osm_id
和geom_type
列,所以它们在前面。我没有找到其他更好用例。
ALTER TABLE osmts.tagsADD CONSTRAINT pk_osmts_tagsPRIMARY KEY (osm_id, geom_type, region, osm_date);
随着表的创建和准备,我开始加载数据,从最旧的第一个开始。Hypertables 的设计理念是较新的数据稍后出现,因此按此顺序进行测试是有意义的。
以下INSERT
查询将数据从tags
具有连接的最旧表移动到匹配pgosm_flex
表以检索osm_date
and region
。
INSERT INTO osmts.tagsSELECT p.osm_date, p.region, t.*FROM osm_co20181210.pgosm_flex pINNER JOIN osm_co20181210.tags t ON True;INSERT 0 2341324Time: 12404.793 ms (00:12.405)
在INSERT
之后,运行ANALYZE
以确保 Postgres 和 Timescale 已更新有关新填充数据的统计信息。
ANALYZE osmts.tags;
一个标准COUNT(*)
确认了前一个INSERT
的行数。
SELECT COUNT(*) FROM osmts.tags;┌─────────┐│ count │╞═════════╡│ 2341324 │└─────────┘(1 row)Time: 268.845 ms
如果不需要确切的数字,使用 Timescale 的 Hypertables 可以更快地获取行数。该approximate_row_count()
函数在大型表上运行得更快,结果接近实际行数。与先前结果和以下结果的差异只有 1,620 个不同,与总数的差异为 0.07%。
SELECT approximate_row_count('osmts.tags');┌───────────────────────┐│ approximate_row_count │╞═══════════════════════╡│ 2342944 │└───────────────────────┘(1 row)Time: 56.806 ms
在此示例中,使用approximate_row_count
比COUNT(*)
使用统计信息而不是全序列扫描快 79%。这也是我经常使用PgDD 扩展来计算常规 Postgres 表的行数的原因。
https://github.com/rustprooflabs/pgdd
另外值得注意的是,我必须运行ANALYZE
几次才能使approximate_row_count
实际行数与实际行数不同......😂
压缩超大表
默认情况下,时间尺度超表不会应用压缩,需要启用它。以下ALTER TABLE
语句定义了如何压缩表。Timescale docs on compression 建议segmentby
列应该与常见的WHERE
子句模式很好地保持一致。在您开始在生产中执行此操作之前,正确的组合segmentby
列和orderby
列非常重要。
ALTER TABLE osmts.tags SET (timescaledb.compress,timescaledb.compress_segmentby = 'region, geom_type',timescaledb.compress_orderby = 'osm_id');
注意:该osm_date
列不包含在压缩定义中。这个细节似乎是由 Timescale 在幕后处理的。
设置压缩策略以自动压缩超过某个阈值的数据。这是通过 add_compression_policy()
函数完成的。现在加载的数据来自 2018 年,远远超出了设定的 14 天阈值。
SELECT add_compression_policy('osmts.tags', INTERVAL '14 days');
添加策略后,等待一两分钟以进行压缩,然后使用chunk_compression_stats()
函数的结果检查大小。以下查询的结果报告数据未压缩时为 607 MB,压缩后为 45 MB。
尺寸缩小了 93%!
SELECT chunk_schema, chunk_name, compression_status,pg_size_pretty(before_compression_total_bytes) AS size_total_before,pg_size_pretty(after_compression_total_bytes) AS size_total_afterFROM chunk_compression_stats('osmts.tags');┌───────────────────────┬────────────────────┬────────────────────┬───────────────────┬──────────────────┐│ chunk_schema │ chunk_name │ compression_status │ size_total_before │ size_total_after │╞═══════════════════════╪════════════════════╪════════════════════╪═══════════════════╪══════════════════╡│ _timescaledb_internal │ _hyper_28_33_chunk │ Compressed │ 607 MB │ 45 MB │└───────────────────────┴────────────────────┴────────────────────┴───────────────────┴──────────────────┘
请记住,我的目标是在整个美国实施这一点,而不仅仅是科罗拉多州。美国数据的当前大小为 67 GB,其中 27 GB(40%!)在
tags
表中。将此表压缩 93% 应将每个美国快照减少约 25 GB。
现在我已经看到压缩工作如宣传的那样,是时候将其余tags
表中的其余数据加载到osmts.tags
.
INSERT INTO osmts.tagsSELECT p.osm_date, p.region, t.*FROM osm_co20200816.pgosm_flex pINNER JOIN osm_co20200816.tags t ON True;INSERT INTO osmts.tagsSELECT p.osm_date, p.region, t.*FROM osm_co20210316.pgosm_flex pINNER JOIN osm_co20210316.tags t ON True;INSERT INTO osmts.tagsSELECT p.osm_date, p.region, t.*FROM osm_co20210718.pgosm_flex pINNER JOIN osm_co20210718.tags t ON True;INSERT INTO osmts.tagsSELECT p.osm_date, p.region, t.*FROM osm_co20210816.pgosm_flex pINNER JOIN osm_co20210816.tags t ON True;
另一个ANALYZE
并检查估计的行数,现在报告 1530 万行。
ANALYZE osmts.tags;SELECT approximate_row_count('osmts.tags');┌───────────────────────┐│ approximate_row_count │╞═══════════════════════╡│ 15356225 │└───────────────────────┘
一段时间后,除了最新数据之外的所有数据都应该最终被压缩。如果你像我一样不耐烦,你可以手动压缩剩余的块。压缩统计数据不报告未压缩分区的大小,但我们可以看到四 (4) 个压缩分区现在仅占用 222 MB,低于源大小的 3,039 MB。
https://docs.timescale.com/timescaledb/latest/how-to-guides/compression/manually-compress-chunks/
SELECT chunk_schema, chunk_name, compression_status,pg_size_pretty(before_compression_total_bytes) AS size_total_before,pg_size_pretty(after_compression_total_bytes) AS size_total_afterFROM chunk_compression_stats('osmts.tags')ORDER BY chunk_name;┌───────────────────────┬────────────────────┬────────────────────┬───────────────────┬──────────────────┐│ chunk_schema │ chunk_name │ compression_status │ size_total_before │ size_total_after │╞═══════════════════════╪════════════════════╪════════════════════╪═══════════════════╪══════════════════╡│ _timescaledb_internal │ _hyper_28_33_chunk │ Compressed │ 607 MB │ 45 MB ││ _timescaledb_internal │ _hyper_28_35_chunk │ Compressed │ 790 MB │ 57 MB ││ _timescaledb_internal │ _hyper_28_36_chunk │ Compressed │ 810 MB │ 59 MB ││ _timescaledb_internal │ _hyper_28_37_chunk │ Compressed │ 832 MB │ 61 MB ││ _timescaledb_internal │ _hyper_28_38_chunk │ Uncompressed │ ¤ │ ¤ │└───────────────────────┴────────────────────┴────────────────────┴───────────────────┴──────────────────┘
我们可以使用该hypertable_size()
函数获得osmts.tags
表的总大小,1,057 MB,它允许使用计算未压缩块的大小为 835 MB (1057 - 222)。
SELECT pg_size_pretty(hypertable_size('osmts.tags'));┌────────────────┐│ pg_size_pretty │╞════════════════╡│ 1057 MB │└────────────────┘
查询性能
以下每个查询都运行了多次,EXPLAIN (ANALYZE)
并在此处选择了一个具有代表性的时间。没有显示完整的计划,只有时间安排。
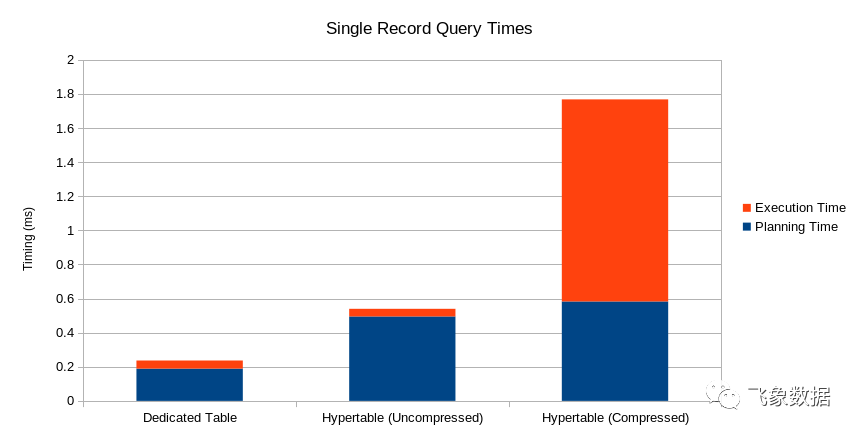
为了检查此设置如何影响查询性能,我首先从原始形式的最新数据中查询单个记录。这是基线。
EXPLAIN (ANALYZE)SELECT *FROM osm_co20210816.tagsWHERE osm_id = 709060219AND geom_type = 'W';Planning Time: 0.189 msExecution Time: 0.048 ms
现在查询同一日期的同一记录,只需使用该osmts.tags
表即可。更新后的查询需要对osm_date
添加一个以前不需要的额外过滤。计划现在需要将近 0.5 毫秒,但计划加上执行时间总共仍然不到 1 毫秒。该日期的数据是未压缩的部分。
EXPLAIN (ANALYZE)SELECT *FROM osmts.tagsWHERE osm_id = 709060219AND geom_type = 'W'AND osm_date = '2021-08-16';Planning Time: 0.495 msExecution Time: 0.045 ms
现在是一个查询,用于查看从历史压缩分区之一中提取相同记录时查询性能如何变化。执行时间现在略多于 1 毫秒。
EXPLAIN (ANALYZE)SELECT *FROM osmts.tagsWHERE osm_id = 709060219AND geom_type = 'W'AND osm_date = '2020-08-16';Planning Time: 0.583 msExecution Time: 1.185 ms
无论如何都不慢,但是这个时间点表明压缩的开销也不是免费的。
概括
tags
这篇文章已经开始通过加载五个非结构化 OpenStreetMap 键/值数据的快照来探索 Timescale 超表和压缩。创建超表并启用压缩很顺利。压缩率 (93%) 符合 Timescale 的广告预期,并且查询性能似乎对我的典型用例非常满意。
虽然我在这里的初步成功令人兴奋,但这只是旅程的一部分。tags
数据只是 PgOSM Flex 加载的一张 OpenStreetMap 表。随着时间的推移,我还计划保留道路、水路、地方和其他一些关键表。这些其他表都包含 PostGIS 数据,并且不会像标签那样压缩。初步测试显示,带有 PostGIS 数据的表格实现了 40-45% 的压缩,而不是此处实现的 > 90%。它还附带一个警告,但这篇文章已经足够长了。
