




点击上方蓝字关注我们
本文所说的 MySQL 事务都是指在 InnoDB 引擎下,MyISAM 引擎是不支持事务的。
事务(Transaction)是访问和更新数据库的程序执行单元;事务中可能包含一个或多个sql语句,这些语句要么都执行,要么都不执行。作为一个关系型数据库,MySQL支持事务,本文介绍基于MySQL5.7。
事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)四个特性,简称 ACID,缺一不可。
面试点:事务的特性有哪些?
▪ 隔离性:
前面一篇讲到锁的机制可以实现事务的隔离性,使得事务可以并发地工作。锁提高了并发性,但是带来了潜在的问题。下面看看哪些问题?
🔻 脏读:当前事务(A)中可以读到其他事务(B)未提交的数据(脏数据),这种现象是脏读。(灵魂画师):
🔽
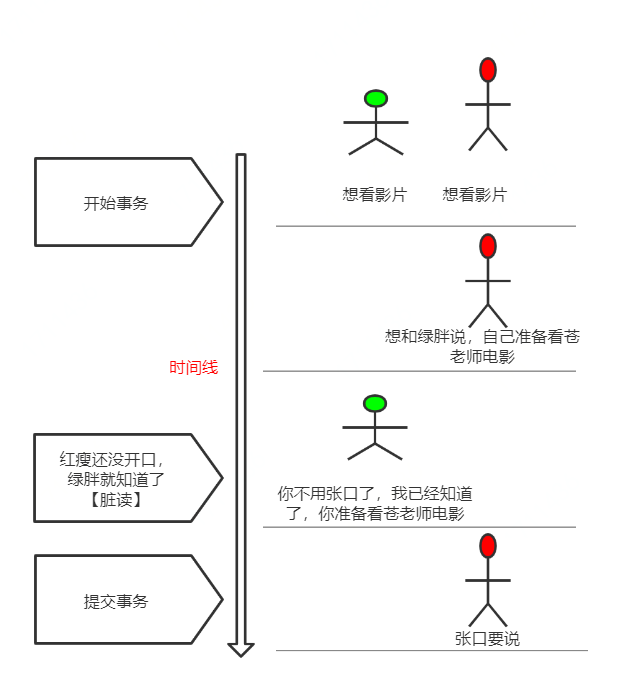
🔻 不可重复读:在事务A中先后两次读取同一个数据,两次读取的结果不一样,这种现象称为不可重复读。脏读与不可重复读的区别在于:前者读到的是其他事务未提交的数据,后者读到的是其他事务已提交的数据。举例如下:
🔽
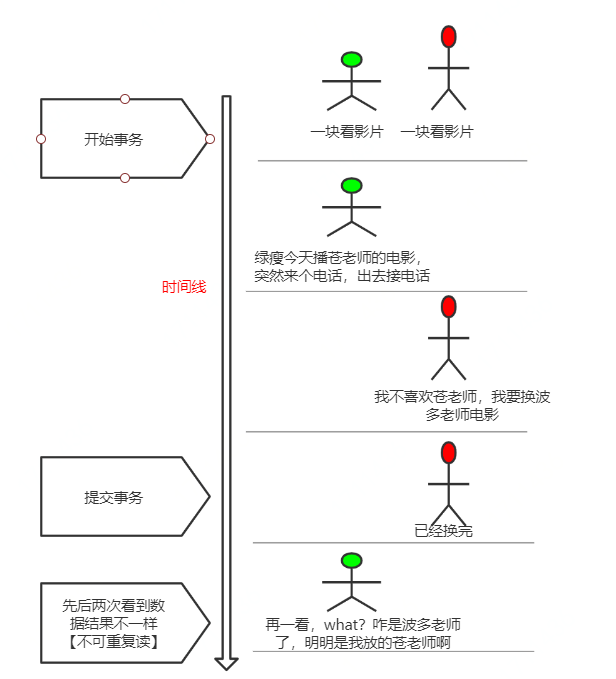
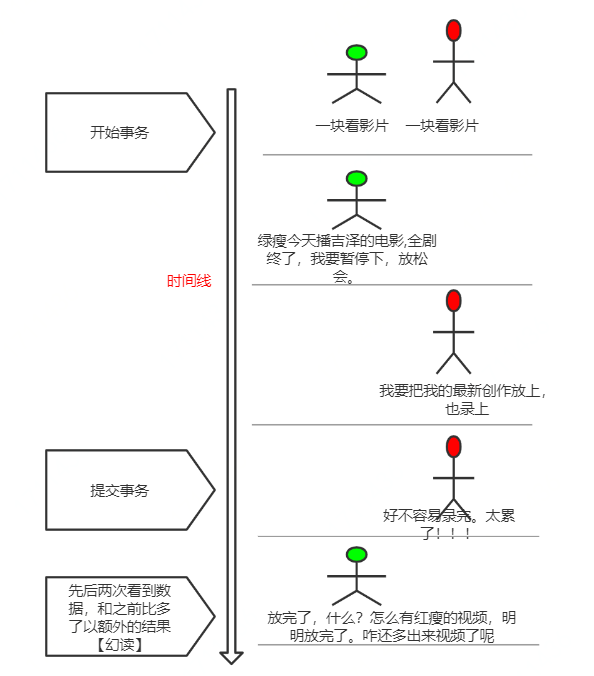
🔻 幻读:在事务A中按照某个条件先后两次查询数据库,两次查询结果的条数不同,这种现象称为幻读。不可重复读与幻读的区别可以通俗的理解为:前者是数据变了,后者是数据的行数变了。举例如下:
🔽
事务隔离级别
SQL 标准定义了四种隔离级别,MySQL 全都支持。这四种隔离级别分别是:
读未提交(READ UNCOMMITTED)读提交 (READ COMMITTED)可重复读 (REPEATABLE READ)串行化 (SERIALIZABLE)从上往下,隔离强度逐渐增强,性能逐渐变差。采用哪种隔离级别要根据系统需求权衡决定,其中,可重复读是 MySQL 的默认级别。
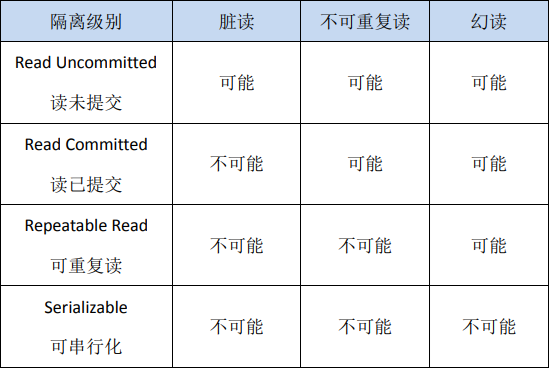
事务隔离其实就是为了解决上面提到的脏读、不可重复读、幻读这几个问题,下面展示了 4 种隔离级别对这三个问题的解决程度。
如何设置隔离级别
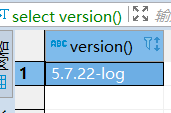
查看数据库隔离级别,我的数据库版本是5.7.22,默认的隔离级别是REPEATABLE-READ

1.读未提交
MySQL 事务隔离其实是依靠锁来实现的,加锁自然会带来性能的损失。而读未提交隔离级别是不加锁的,所以它的性能是最好的,没有加锁、解锁带来的性能开销。但有利就有弊,这基本上就相当于裸奔啊,所以它连脏读的问题都没办法解决。
任何事务对数据的修改都会第一时间暴露给其他事务,即使事务还没有提交。
✔动手篇(不要偷懒,让你记忆更深刻。)
CREATE TABLE `moving` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(128) COLLATE utf8_bin COMMENT '姓名',`action` varchar(128) COLLATE utf8_bin COMMENT '行为',PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='电影';INSERT INTO moving (name, `action`)VALUES('绿瘦', '喜欢苍老师');INSERT INTO moving (name, `action`)VALUES('红胖', '喜欢波多老师');复制
设置事务隔离级别读未提交
set global transaction isolation level read uncommitted;复制
设置完成后,只对之后新起的 session 才起作用,对已经启动 session 无效。如果用 shell 客户端那就要重新连接 MySQL,如果用 Navicat 那就要创建新的查询窗口。
启动两个事务,分别为事务A和事务B,在事务A中使用 update 语句,修改 action的值为'喜欢波多老师',初始是'喜欢苍老师' ,在执行完 update 语句之后,在事务B中查询 moving表,会看到 action的值已经是'喜欢波多老师'了,这时候事务A还没有提交。在事务B进行操作的过程中,很有可能事务A由于某些原因,进行了事务回滚操作,那其实事务B得到的就是脏数据了,拿着脏数据去进行其他的计算,那结果肯定也是有问题的。
图示如下:
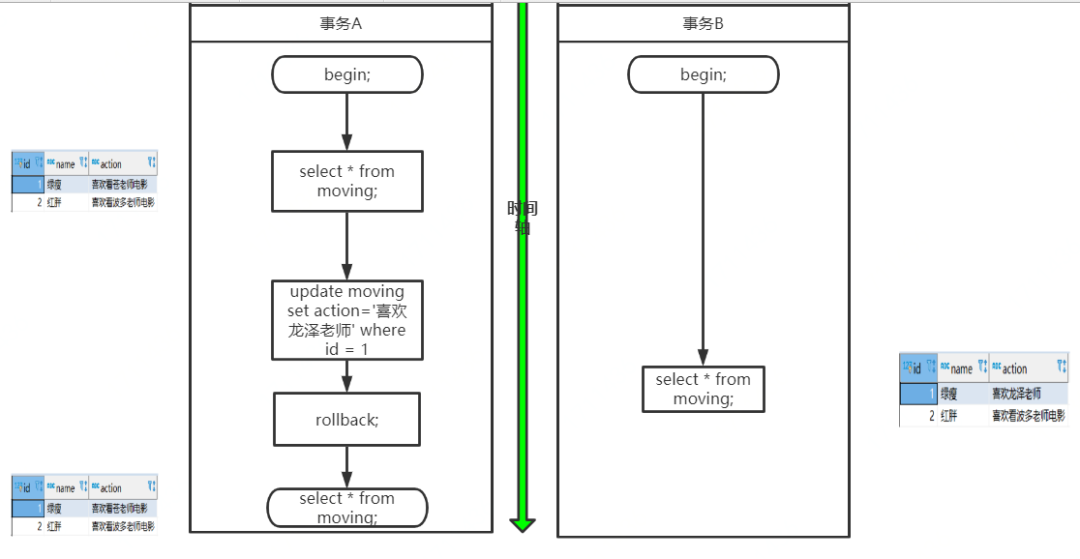
读未提交,其实就是可以读到其他事务未提交的数据,但没有办法保证你读到的数据最终一定是提交后的数据,如果中间发生回滚,那就会出现脏数据问题,读未提交没办法解决脏数据问题。
2.读提交
既然读未提交没办法解决脏数据问题,那么就有了读已提交。读已提交就是一个事务只能读到其他事务已经提交过的数据,也就是其他事务调用 commit 命令之后的数据。那脏数据问题迎刃而解了。
读提交事务隔离级别是大多数流行数据库的默认事务隔离界别,因为提交之后,其它事务看到也是理所应当的。
✔ 动手篇
设置事务隔离级别读已提交
set global transaction isolation level read committed;复制
同样开启事务A和事务B两个事务,在事务A中使用 update 语句将 id=1 的记录行 action的值为'喜欢龙泽老师',初始是'喜欢苍老师'。此时,在事务B中使用 select 语句进行查询,我们发现在事务A提交之前,事务B中查询到的记录 action一直是'喜欢苍老师',直到事务A提交,此时在事务B中 select 查询,发现 action的值已经是'喜欢龙泽老师' 了。
这就出现了一个问题,在同一事务中(本例中的事务B),事务的不同时刻同样的查询条件,查询出来的记录内容是不一样的,事务A的提交影响了事务B的查询结果,这就是不可重复读,也就是读提交隔离级别。
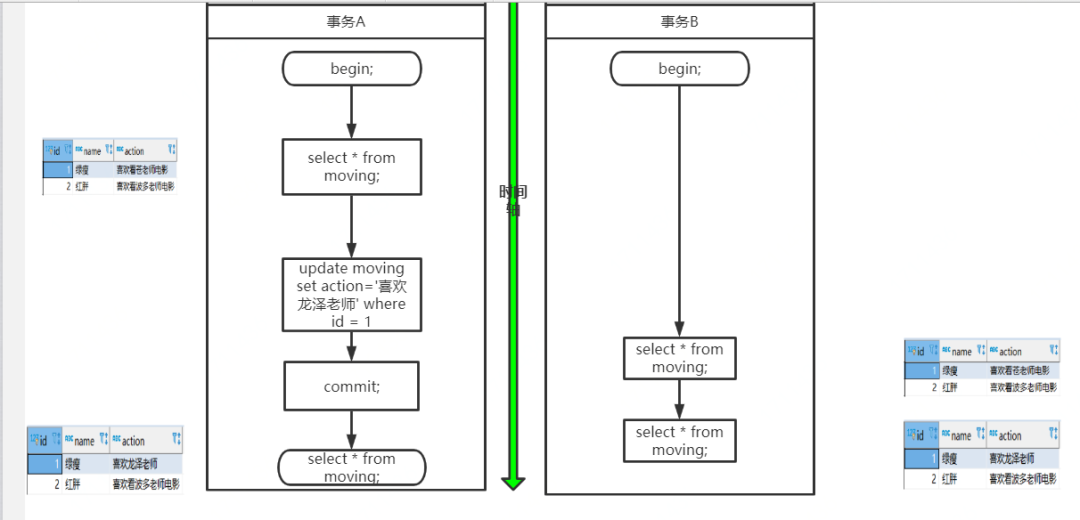
每个 select 语句都有自己的一份快照,而不是一个事务一份,所以在不同的时刻,查询出来的数据可能是不一致的。
读提交解决了脏读的问题,但是无法做到可重复读,也没办法解决幻读。
3.可重复读
可重复是对比不可重复而言的,上面说不可重复读是指同一事物不同时刻读到的数据值可能不一致。而可重复读是指,事务不会读到其他事务对已有数据的修改,及时其他事务已提交,也就是说,事务开始时读到的已有数据是什么,在事务提交前的任意时刻,这些数据的值都是一样的。但是,对于其他事务新插入的数据是可以读到的,这也就引发了幻读问题。
✔动手:
设置事务隔离级别可重复读
set global transaction isolation level repeatable read;复制
在这个隔离级别下,启动两个事务,两个事务同时开启。
首先看一下可重复读的效果,事务A启动后修改了数据,并且在事务B之前提交,事务B在事务开始和事务A提交之后两个时间节点都读取的数据相同,已经可以看出可重复读的效果。
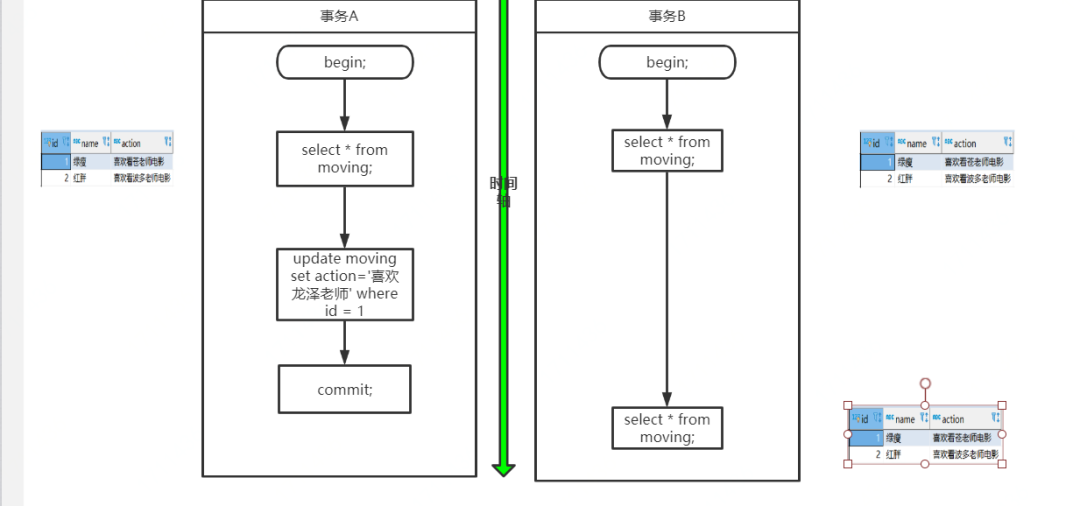
可重复读做到了,这只是针对已有行的更改操作有效,但是对于新插入的行记录,就没这么幸运了,幻读就这么产生了。我们看一下这个过程:
事务A开始后,执行 update 操作,将 id=1 的记录的 action改为'喜欢龙泽老师';
事务B开始后,在事务执行完 update 后,执行 insert 操作。插入一条新数据
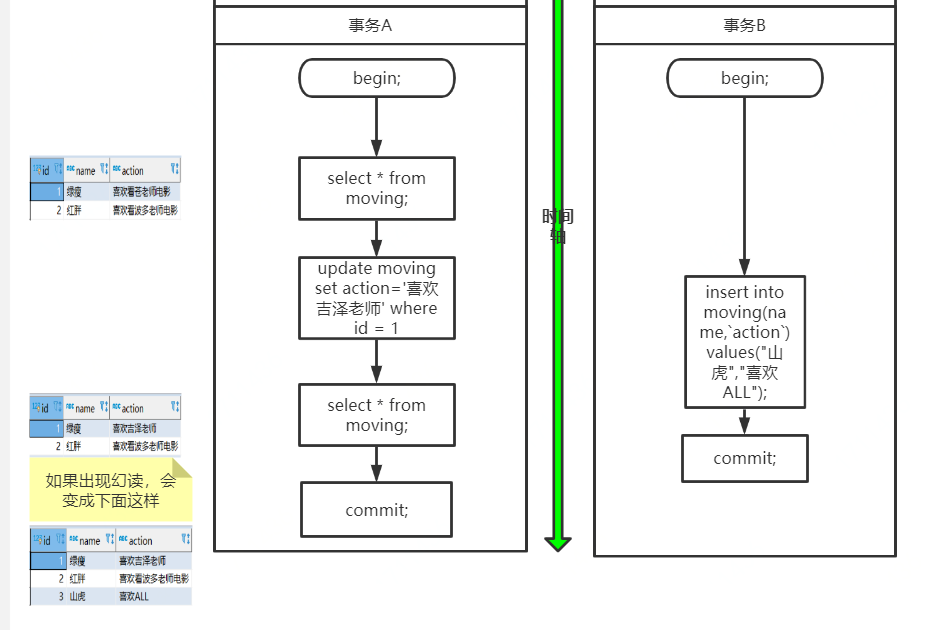
注意:
你在 MySQL 中测试幻读的时候,并不会出现上图的结果,幻读并没有发生,InnoDB利用锁机制解决了幻读问题,也可以设置串行化来解决幻读。这会在后面的内容说明
4.串行化
串行化是4种事务隔离级别中隔离效果最好的,解决了脏读、可重复读、幻读的问题,但是效果最差,它将事务的执行变为顺序执行,与其他三个隔离级别相比,它就相当于单线程,后一个事务的执行必须等待前一个事务结束。
🔻 MySQL 中是如何实现事务隔离的
读未提交,什么都不管,读写都不加锁。串行化。这个比较好理解,就是顺序执行。读提交和可重复读。这两种隔离级别是比较复杂的,既要允许一定的并发,又想要兼顾的解决问题。
🔹 实现可重复读
为了实现可重复读,InnoDB 采用了 MVVC (多版本并发控制) 的方式。
前面一篇文章讲到快照,学名叫做一致性视图,这也是可重复读和不可重复读的关键,可重复读是在事务开始的时候生成一个当前事务全局性的快照,而读提交则是每次执行语句的时候都重新生成一次快照。
对于一个快照来说,它能够读到那些版本数据,要遵循以下规则:
当前事务内的更新,可以读到;版本未提交,不能读到;版本已提交,但是却在快照创建后提交的,不能读到;版本已提交,且是在快照创建前提交的,可以读到;利用上面的规则,再返回去套用到读提交和可重复读的那两张图上就很清晰了。还是要强调,两者主要的区别就是在快照的创建上,可重复读仅在事务开始是创建一次,而读提交每次执行语句的时候都要重新创建一次。
🔹 解决幻读
上面介绍可重复读的时候,那张图里标示着出现幻读的地方实际上在 MySQL 中并不会出现,MySQL 已经在可重复读隔离级别下解决了幻读的问题。
InnoDB解决幻读用的是锁,叫做间隙锁,MySQL 把行锁和间隙锁合并在一起,解决了并发写和幻读的问题,这个锁叫做 Next-Key锁。
🔹 扩展
前面介绍的MVCC,是RR隔离级别下“非加锁读”实现隔离性的方式。下面是一些简单的扩展。
(1)读已提交(RC)隔离级别下的非加锁读
RC与RR一样,都使用了MVCC,其主要区别在于:
RR是在事务开始后第一次执行select前创建ReadView,直到事务提交都不会再创建。根据前面的介绍,RR可以避免脏读、不可重复读和幻读。
RC每次执行select前都会重新建立一个新的ReadView,因此如果事务A第一次select之后,事务B对数据进行了修改并提交,那么事务A第二次select时会重新建立新的ReadView,因此事务B的修改对事务A是可见的。因此RC隔离级别可以避免脏读,但是无法避免不可重复读和幻读。
(2)加锁读与next-key lock
按照是否加锁,MySQL的读可以分为两种:
一种是非加锁读,也称作快照读、一致性读,使用普通的select语句,这种情况下使用MVCC避免了脏读、不可重复读、幻读,保证了隔离性。
另一种是加锁读,查询语句有所不同,如下所示:

加锁读在查询时会对查询的数据加锁(共享锁或排它锁)。由于锁的特性,当某事务对数据进行加锁读后,其他事务无法对数据进行写操作,因此可以避免脏读和不可重复读。而避免幻读,则需要通过next-key lock。next-key lock是行锁的一种,实现相当于record lock(记录锁) + gap lock(间隙锁);其特点是不仅会锁住记录本身(record lock的功能),还会锁定一个范围(gap lock的功能)。因此,加锁读同样可以避免脏读、不可重复读和幻读,保证隔离性。
面试点:事务的原子性实现?
▪原子性
🔻 定义
原子性是指一个事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做;如果事务中一个sql语句执行失败,则已执行的语句也必须回滚,数据库退回到事务前的状态。
🔻 实现原理:undo log
在说明原子性原理之前,首先介绍一下MySQL的事务日志。MySQL的日志有很多种,如二进制日志、错误日志、查询日志、慢查询日志等,此外InnoDB存储引擎还提供了两种事务日志:redo log(重做日志)和undo log(回滚日志)。其中redo log用于保证事务持久性;undo log则是事务原子性和隔离性实现的基础。
下面说回undo log。实现原子性的关键,是当事务回滚时能够撤销所有已经成功执行的sql语句。InnoDB实现回滚,靠的是undo log:当事务对数据库进行修改时,InnoDB会生成对应的undo log;如果事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
undo log属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB会根据undo log的内容做与之前相反的工作:对于每个insert,回滚时会执行delete;对于每个delete,回滚时会执行insert;对于每个update,回滚时会执行一个相反的update,把数据改回去。
以update操作为例:当事务执行update时,其生成的undo log中会包含被修改行的主键(以便知道修改了哪些行)、修改了哪些列、这些列在修改前后的值等信息,回滚时便可以使用这些信息将数据还原到update之前的状态。
面试点:事务的持久性实现?
▪ 持久性
🔻 定义
持久性是指事务一旦提交,它对数据库的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
🔻 实现原理:redo log
redo log和undo log都属于InnoDB的事务日志。下面先聊一下redo log存在的背景。
InnoDB作为MySQL的存储引擎,数据是存放在磁盘中的,但如果每次读写数据都需要磁盘IO,效率会很低。为此,InnoDB提供了缓存(Buffer Pool),Buffer Pool中包含了磁盘中部分数据页的映射,作为访问数据库的缓冲:当从数据库读取数据时,会首先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool;当向数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中(这一过程称为刷脏)。
Buffer Pool的使用大大提高了读写数据的效率,但是也带了新的问题:如果MySQL宕机,而此时Buffer Pool中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。
于是,redo log被引入来解决这个问题:当数据修改时,除了修改Buffer Pool中的数据,还会在redo log记录这次操作;当事务提交时,会调用fsync接口对redo log进行刷盘。如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool,保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。
既然redo log也需要在事务提交时将日志写入磁盘,为什么它比直接将Buffer Pool中修改的数据写入磁盘(即刷脏)要快呢?主要有以下两方面的原因:
(1)刷脏是随机IO,因为每次修改的数据位置随机,但写redo log是追加操作,属于顺序IO。
(2)刷脏是以数据页(Page)为单位的,MySQL默认页大小是16KB,一个Page上一个小修改都要整页写入;而redo log中只包含真正需要写入的部分,无效IO大大减少。
面试点:redo log 和bin log 区别?
🔻 redo log与binlog
我们知道,在MySQL中还存在binlog(二进制日志)也可以记录写操作并用于数据的恢复,但二者是有着根本的不同的:
(1)作用不同:redo log是用于crash recovery的,保证MySQL宕机也不会影响持久性;binlog是用于point-in-time recovery的,保证服务器可以基于时间点恢复数据,此外binlog还用于主从复制。
(2)层次不同:redo log是InnoDB存储引擎实现的,而binlog是MySQL的服务器层(可以参考文章前面对MySQL逻辑架构的介绍)实现的,同时支持InnoDB和其他存储引擎。
(3)内容不同:redo log是物理日志,内容基于磁盘的Page;binlog的内容是二进制的,根据binlog_format参数的不同,可能基于sql语句、基于数据本身或者二者的混合。
(4)写入时机不同:binlog在事务提交时写入;redo log的写入时机相对多元:
· 前面曾提到:当事务提交时会调用fsync对redo log进行刷盘;这是默认情况下的策略,修改innodb_flush_log_at_trx_commit参数可以改变该策略,但事务的持久性将无法保证。
· 除了事务提交时,还有其他刷盘时机:如master thread每秒刷盘一次redo log等,这样的好处是不一定要等到commit时刷盘,commit速度大大加快。
▪ 一致性
🔻 基本概念
一致性是指事务执行结束后,数据库的完整性约束没有被破坏,事务执行的前后都是合法的数据状态。数据库的完整性约束包括但不限于:实体完整性(如行的主键存在且唯一)、列完整性(如字段的类型、大小、长度要符合要求)、外键约束、用户自定义完整性(如转账前后,两个账户余额的和应该不变)
🔻 实现
可以说,一致性是事务追求的最终目标:前面提到的原子性、持久性和隔离性,都是为了保证数据库状态的一致性。此外,除了数据库层面的保障,一致性的实现也需要应用层面进行保障。
实现一致性的措施包括:
· 保证原子性、持久性和隔离性,如果这些特性无法保证,事务的一致性也无法保证
· 数据库本身提供保障,例如不允许向整形列插入字符串值、字符串长度不能超过列的限制等
· 应用层面进行保障,例如如果转账操作只扣除转账者的余额,而没有增加接收者的余额,无论数据库实现的多么完美,也无法保证状态的一致
▪ 总结
下面总结一下ACID特性及其实现原理:
· 原子性:语句要么全执行,要么全不执行,是事务最核心的特性,事务本身就是以原子性来定义的;实现主要基于undo log
· 持久性:保证事务提交后不会因为宕机等原因导致数据丢失;实现主要基于redo log
· 隔离性:保证事务执行尽可能不受其他事务影响;InnoDB默认的隔离级别是RR,RR的实现主要基于锁机制(包含next-key lock)、MVCC(包括数据的隐藏列、基于undo log的版本链、ReadView)
· 一致性:事务追求的最终目标,一致性的实现既需要数据库层面的保障,也需要应用层面的保障
OS:如果您能读到这里,恭喜你大概率说明你是一个比较有耐心的人,如果你有任何问题都可以加我的微信我会尽我所能帮你分析一下,现在这个社会太浮躁。。。。。
大家好,我是山虎,喜欢数学,编码,算法,股票,AI。经历过一次失败的创业。东西不要死记硬背,要做到自己真正的理解。年轻人就要折腾,年轻人就要折腾,年轻人就要折腾。原创不易,帮忙转发。
JAVA八股文
随时欢迎与我讨论各种问题


点个在看你最好看
