




InnoDB事务锁是以page为单位组织锁结构的,每个锁对象是以结构体lock_t来描述的,记录锁是以lock_rec_t来描述的
/** Lock struct; protected by lock_sys latches */
struct lock_t
{
/** transaction owning the lock */
trx_t *trx;
/** list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/** Index for a record lock */
dict_index_t *index;
/** Hash chain node for a record lock. The link node in a singly
linked list, used by the hash table. */
lock_t *hash;
union
{
/** Table lock */
lock_table_t tab_lock;
/** Record lock */
lock_rec_t rec_lock;
};
复制/** Record lock for a page */
struct lock_rec_t
{
/** The id of the page on which records referenced by this lock's bitmap are
located. */
page_id_t page_id;
/** number of bits in the lock bitmap;
NOTE: the lock bitmap is placed immediately after the lock struct */
uint32_t n_bits;
/** Print the record lock into the given output stream
@param[in,out] out the output stream
@return the given output stream. */
std::ostream &print(std::ostream &out) const;
};
复制下图省去了次要信息大致展示了lock_t和lock_rec_t是如何组织的,InnoDB这样组织的目的主要是想实现以下两个目的:
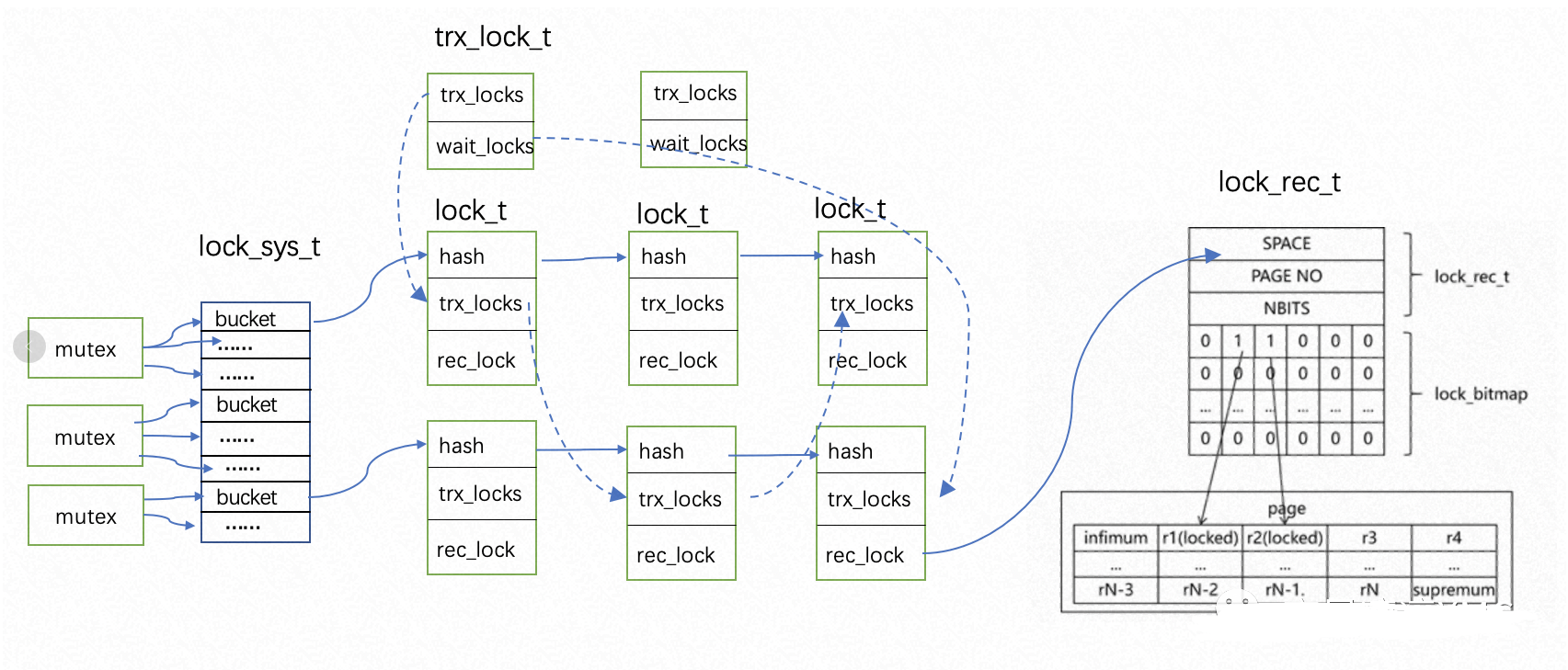
一个事务可以查到自己持有了哪些锁或者被哪个锁blocking。
每个事务会维护一个trx_lock_t的结构体,其中trx_locks指向lock_t的链表,通过lock_t的trx_locks双向链表从而将属于同一个事务持有的锁串联起来,因为一个事务有可能在多个page上面持有锁。另外如果一个事务被阻塞,wait_locks指向阻塞的lock_t。
可以查询一行有没有上锁以及上了什么锁。
通过维护一张lock_sys的hash table将所有的lock_t组织起来,根据(space,page_no)通过hash算法计算出一样的hash value 将会放在同一个bucket中,因为hash算法的局限性,不同的(space,page_no)有可能生成同样的hash value,我们知道解决hash冲突通常都是后面拉出一张链表,所以很自然的同一个bucket中的lock_t组成一个链表结构,那么怎么查询一行上了锁没有呢?具体是根据(space,page_no)做hash运算找到对应的bucket,然后扫描后面的lock_t的链表并比较是不是同一个page,如果是,再通过里面的lock_rec_t中的lock_bitmap继续判断某一行是不是上锁了,因为每个行记录头中保存了用于对page内每条记录生成唯一编号的heap_no,那么lock_bitmap中的每个bit位对应于page中的一条记录,bit位的位置就对应于记录的heap_no,该bit位为1就表示对应的记录上有锁,至于上什么类型的锁由type_mode决定。对于多线程并发访问hash table,需要有同步机制进行并发保护,为提高并发性和避免热点,拆分成了多个mutex,每个mutex保护一段bucket数组以及后面的hash table。
下面通过一个简单的例子看下InnoDB加锁的过程:
Table: awr
Create Table: CREATE TABLE `awr`
(
`id` int NOT NULL,
`c` int DEFAULT NULL,
`d` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
复制update awr set c=6 where id=4;
通过update语句生成的调用栈,忽略server层的操作,InnoDB加锁的核心函数是sel_set_rec_lock
* thread #39, name = 'connection', stop reason = breakpoint 1.1
* frame #0: 0x00000001072ae0ef mysqld`sel_set_rec_lock(pcur=0x00007fdb3938f930, rec="\x80", index=0x00007fdb22873f58, offsets=0x0000700007deaa30, sel_mode=SELECT_ORDINARY, mode=3, type=1024, thr=0x00007fdb39390100, mtr=0x0000700007dead58) at row0sel.cc:1141:11
frame #1: 0x00000001072a9e1b mysqld`row_search_mvcc(buf="\xff", mode=PAGE_CUR_GE, prebuilt=0x00007fdb3938f6b8, match_mode=1, direction=0) at row0sel.cc:5222:11
frame #2: 0x0000000106ea3382 mysqld`ha_innobase::index_read(this=0x00007fdb1c83d030, buf="\xff", key_ptr="\U00000004", key_len=4, find_flag=HA_READ_KEY_EXACT) at ha_innodb.cc:10111:13
frame #3: 0x000000010451c237 mysqld`handler::index_read_map(this=0x00007fdb1c83d030, buf="\xff", key="\U00000004", keypart_map=1, find_flag=HA_READ_KEY_EXACT) at handler.h:5130:12
frame #4: 0x00000001045084e7 mysqld`handler::ha_index_read_map(this=0x00007fdb1c83d030, buf="\xff", key="\U00000004", keypart_map=1, find_flag=HA_READ_KEY_EXACT) at handler.cc:3260:3
frame #5: 0x0000000104516fad mysqld`handler::read_range_first(this=0x00007fdb1c83d030, start_key=0x00007fdb1c83d110, end_key=0x00007fdb1c83d130, eq_range_arg=true, sorted=true) at handler.cc:7260:14
frame #6: 0x0000000106ea4e73 mysqld`ha_innobase::read_range_first(this=0x00007fdb1c83d030, start_key=0x00007fdb1c83d110, end_key=0x00007fdb1c83d130, eq_range_arg=true, sorted=true) at ha_innodb.cc:10599:19
frame #7: 0x0000000104513d82 mysqld`handler::multi_range_read_next(this=0x00007fdb1c83d030, range_info=0x0000700007deb840) at handler.cc:6422:16
frame #8: 0x00000001045157aa mysqld`DsMrr_impl::dsmrr_next(this=0x00007fdb1c83dc78, range_info=0x0000700007deb840) at handler.cc:6764:44
frame #9: 0x0000000106ec4c06 mysqld`ha_innobase::multi_range_read_next(this=0x00007fdb1c83d030, range_info=0x0000700007deb840) at ha_innodb.cc:23172:20
frame #10: 0x000000010451394b mysqld`handler::ha_multi_range_read_next(this=0x00007fdb1c83d030, range_info=0x0000700007deb840) at handler.cc:6360:12
frame #11: 0x0000000104a17c07 mysqld`IndexRangeScanIterator::Read(this=0x00007fdb2b97aed8) at index_range_scan.cc:365:22
frame #12: 0x0000000104e8354c mysqld`Sql_cmd_update::update_single_table(this=0x00007fdb2b97a2b8, thd=0x00007fdb33829600) at sql_update.cc:866:25
frame #13: 0x0000000104e88983 mysqld`Sql_cmd_update::execute_inner(this=0x00007fdb2b97a2b8, thd=0x00007fdb33829600) at sql_update.cc:1772:23
frame #14: 0x0000000104d7cc2b mysqld`Sql_cmd_dml::execute(this=0x00007fdb2b97a2b8, thd=0x00007fdb33829600) at sql_select.cc:581:7
frame #15: 0x0000000104cb8aef mysqld`mysql_execute_command(thd=0x00007fdb33829600, first_level=true) at sql_parse.cc:3553:29
frame #16: 0x0000000104cb3872 mysqld`dispatch_sql_command(thd=0x00007fdb33829600, parser_state=0x0000700007df0798) at sql_parse.cc:5174:19
frame #17: 0x0000000104caef2b mysqld`dispatch_command(thd=0x00007fdb33829600, com_data=0x0000700007df1e18, command=COM_QUERY) at sql_parse.cc:1938:7
frame #18: 0x0000000104cb1dab mysqld`do_command(thd=0x00007fdb33829600) at sql_parse.cc:1352:18
frame #19: 0x0000000104fa0de0 mysqld`handle_connection(arg=0x00007fdb1d870a50) at connection_handler_per_thread.cc:302:13
frame #20: 0x000000010756fac0 mysqld`pfs_spawn_thread(arg=0x00007fdb23425fd0) at pfs.cc:2947:3
frame #21: 0x00007fff204278fc libsystem_pthread.dylib`_pthread_start + 224
frame #22: 0x00007fff20423443 libsystem_pthread.dylib`thread_start + 15
复制首先会判断当前事务持有锁的数量如果超过了1w个同时满足buffe_pool free 空间<25%,则会退出。否则判断当前index是主键索引还是空间索引或者是二级索引,从而走不同的分支,因为我们是根据主键id更新显然是走lock_clust_rec_read_check_and_lock这个分支。
if (UT_LIST_GET_LEN(trx->lock.trx_locks) > 10000)
{
if (buf_LRU_buf_pool_running_out())
{
return (DB_LOCK_TABLE_FULL);
}
}
if (index->is_clustered())
{
err = lock_clust_rec_read_check_and_lock( lock_duration_t::REGULAR, block, rec, index, offsets, sel_mode,
static_cast<lock_mode>(mode), type, thr);
} else
{
if (dict_index_is_spatial(index))
{
if (type == LOCK_GAP || type == LOCK_ORDINARY)
{
ut_ad(0);
ib::error(ER_IB_MSG_1026) << "Incorrectly request GAP lock " "on RTree";
return (DB_SUCCESS);
}
err = sel_set_rtr_rec_lock(pcur, rec, index, offsets, sel_mode, mode, type, thr, mtr);
} else
{
err = lock_sec_rec_read_check_and_lock(
lock_duration_t::REGULAR, block, rec, index, offsets, sel_mode,
static_cast<lock_mode>(mode), type, thr);
}
}
复制lock_clust_rec_read_check_and_lock首先根据heap_no判断当前记录是不是supremum,如果不是,则会通过lock_rec_convert_impl_to_expl将当前记录的隐式锁转化为显式锁。所谓隐式锁,其实并不是一个真正的事务锁对象,可以理解为一个标记,由于事务锁涉及到全局资源,创建锁的开销高昂,InnoDB对于新插入的记录,在没有冲突的情况下是不创建记录锁的。
heap_no = page_rec_get_heap_no(rec);
if (heap_no != PAGE_HEAP_NO_SUPREMUM) {
lock_rec_convert_impl_to_expl(block, rec, index, offsets);
}
复制lock_rec_convert_impl_to_expl针对主键索引走到lock_clust_rec_some_has_impl这个分支,先查看记录的trx_id,判断此事务是不是活跃的,同时也没有显式锁加在这条记录上,则会通过lock_rec_convert_impl_to_expl_for_trx将这个事务的隐式锁转化为显式锁,我们要更新的这条记录上面目前没有隐式锁,这个分支我们先略过。另外对于二级索引记录中因为没有trx_id,所以判断逻辑在此处比聚集索引稍复杂一些,他是通过在page上记录最近一次更新的最大事务ID,通过回表的方式判断可见性,这个以后再介绍。
if (index->is_clustered()) {
trx_id_t trx_id;
trx_id = lock_clust_rec_some_has_impl(rec, index, offsets);
trx = trx_rw_is_active(trx_id, true);
} else {
ut_ad(!dict_index_is_online_ddl(index));
trx = lock_sec_rec_some_has_impl(rec, index, offsets);
if (trx) {
DEBUG_SYNC_C("lock_rec_convert_impl_to_expl_will_validate");
ut_ad(!lock_rec_other_trx_holds_expl(LOCK_S | LOCK_REC_NOT_GAP, trx, rec,
block));
}
}
if (trx != nullptr) {
ulint heap_no = page_rec_get_heap_no(rec);
ut_ad(trx_is_referenced(trx));
lock_rec_convert_impl_to_expl_for_trx(block, rec, index, offsets, trx,
heap_no);
}
复制接下来通过lock_rec_lock正式对记录加锁:
DEBUG_SYNC_C("after_lock_clust_rec_read_check_and_lock_impl_to_expl");
{
locksys::Shard_latch_guard guard{UT_LOCATION_HERE, block->get_page_id()};
if (duration == lock_duration_t::AT_LEAST_STATEMENT) {
lock_protect_locks_till_statement_end(thr);
}
ut_ad(mode != LOCK_X ||
lock_table_has(thr_get_trx(thr), index->table, LOCK_IX));
ut_ad(mode != LOCK_S ||
lock_table_has(thr_get_trx(thr), index->table, LOCK_IS));
err = lock_rec_lock(false, sel_mode, mode | gap_mode, block, heap_no, index,
thr);
MONITOR_INC(MONITOR_NUM_RECLOCK_REQ);
}
复制lock_rec_lock实现相当简单,做完各种断言前置项验证就通过以下两种方式实现对记录加锁:
switch (lock_rec_lock_fast(impl, mode, block, heap_no, index, thr))
{
case LOCK_REC_SUCCESS:
return (DB_SUCCESS);
case LOCK_REC_SUCCESS_CREATED:
return (DB_SUCCESS_LOCKED_REC);
case LOCK_REC_FAIL:
return (lock_rec_lock_slow(impl, sel_mode, mode, block, heap_no, index, thr));
default:
ut_error;
复制首先尝试通过lock_rec_lock_fast快速加锁
如果快速加锁失败,则通过lock_rec_lock_slow慢加锁
我们先看快速加锁过程,首先是通过lock_rec_get_first_on_page查看page上有没有锁,如果没有就直接通过rec_lock.create(trx)创建lock_t。
lock_t *lock = lock_rec_get_first_on_page(lock_sys->rec_hash, block);
trx_t *trx = thr_get_trx(thr);
ut_ad(!trx_mutex_own(trx));
lock_rec_req_status status = LOCK_REC_SUCCESS;
if (lock == nullptr)
{
if (!impl)
{
RecLock rec_lock(index, block, heap_no, mode);
trx_mutex_enter(trx);
rec_lock.create(trx);
trx_mutex_exit(trx);
status = LOCK_REC_SUCCESS_CREATED;
}
}
复制具体创建lock_t实例是由lock_alloc实现的,主要就是分配一些内存,再设置事务请求记录锁的模式、行锁的page_id、n_bits等。
lock_t *RecLock::lock_alloc(trx_t *trx, dict_index_t *index, ulint mode,const RecID &rec_id, ulint size)
{
ut_ad(locksys::owns_page_shard(rec_id.get_page_id()));
/* We are about to modify structures in trx->lock which needs trx->mutex */
ut_ad(trx_mutex_own(trx));
lock_t *lock;
if (trx->lock.rec_cached >= trx->lock.rec_pool.size() || sizeof(*lock) + size > REC_LOCK_SIZE)
{
ulint n_bytes = size + sizeof(*lock);
mem_heap_t *heap = trx->lock.lock_heap;
lock = reinterpret_cast<lock_t *>(mem_heap_alloc(heap, n_bytes));
}
else
{
lock = trx->lock.rec_pool[trx->lock.rec_cached];
++trx->lock.rec_cached;
}
lock->trx = trx;
lock->index = index;
/* Note the creation timestamp */
ut_d(lock->m_seq = lock_sys->m_seq.fetch_add(1));
/* Setup the lock attributes */
lock->type_mode = LOCK_REC | (mode & ~LOCK_TYPE_MASK);
lock_rec_t &rec_lock = lock->rec_lock;
/* Predicate lock always on INFIMUM (0) */
if (is_predicate_lock(mode)) {
rec_lock.n_bits = 8;
memset(&lock[1], 0x0, 1);
} else {
ut_ad(8 * size < UINT32_MAX);
rec_lock.n_bits = static_cast<uint32_t>(8 * size);
memset(&lock[1], 0x0, size);
}
rec_lock.page_id = rec_id.get_page_id();
/* Set the bit corresponding to rec */
lock_rec_set_nth_bit(lock, rec_id.m_heap_no);
MONITOR_INC(MONITOR_NUM_RECLOCK);
MONITOR_INC(MONITOR_RECLOCK_CREATED);
return (lock);
}
复制其中n_bits=8 * size,size是由下面的逻辑得到,size = 1 + (page内记录数 + 64)/8,这里额外+1是为了避免因为整除导致数值偏小的问题,64是额外预留64个记录的bit位,因为目前page记录数只有一条,所以size=9,n_bits=72
static size_t lock_size(const page_t *page) {
ulint n_recs = page_dir_get_n_heap(page);
/* Make lock bitmap bigger by a safety margin */
return (1 + ((n_recs + LOCK_PAGE_BITMAP_MARGIN) / 8));
}
复制通过追踪代码得到page_id = (m_space = 11, m_page_no = 4), n_bits = 72符合预期
(lldb) p *lock_alloc(trx, m_index, m_mode, m_rec_id, m_size)
(ib_lock_t) $51 = {
trx = 0x00007fe833f09fa8
trx_locks = {
prev = nullptr
next = nullptr
}
index = 0x00007fe83ab29908
hash = nullptr
= {
tab_lock = {
table = 0x000000040000000b
locks = {
prev = 0x0000000000000048
next = nullptr
}
}
rec_lock = {
page_id = (m_space = 11, m_page_no = 4)
n_bits = 72
}
}
复制m_psi_internal_thread_id = 0
m_psi_event_id = 0
type_mode = 1059
m_seq = 82
其中type_mode = 1059,下面详细说下type_mode的结构,type_mode占32位bit,被分为lock_mode、lock_type、rec_lock_type三部分:

| rec_lock_type | lock_type | lock_mode |
|---|---|---|
| 0表示next-key锁 | 第5位为1表示表级锁 | 0 表示IS锁 |
| 10位设置为1时表示gap锁 | 第6位为1表示行级锁 | 1 表示IX锁 |
| 11位设置为1表示正常记录锁 | NULL | 2 表示S锁 |
| 12位设置为1时表示插入意向锁 | NULL | 3 表示X锁 |
| NULL | NULL | 4 表示自增锁 |
只有rec_lock_type的值为LOCK_REC时,才会出现细分:
LOCK_ORDINARY:为0表示next-key锁
LOCK_GAP:为512即当第10位设置为1时表示gap锁
LOCK_REC_NOT_GAP:为1024即当第11位设置为1表示正常记录锁
LOCK_INSERT_INTENTION:为2048即当第12位设置为1时表示插入意向锁
type_mode = 1059换算成二进制是10000100011,通过以上我们知道这是上了一把行记录X排他锁。
具体上锁是通过 lock_rec_set_nth_bit 设置bitmap的位图信息,将对应byte上相应的bit位设置为1
static inline void lock_rec_set_nth_bit(lock_t *lock, /*!< in: record lock */ ulint i) /*!< in: index of the bit */
{
ulint byte_index;
ulint bit_index;
ut_ad(lock);
ut_ad(lock_get_type_low(lock) == LOCK_REC);
ut_ad(i < lock->rec_lock.n_bits);
byte_index = i / 8;
bit_index = i % 8;
byte *const the_byte = ((byte *)&lock[1]) + byte_index;
ut_ad(!(*the_byte & (1 << bit_index)));
*the_byte |= 1 << bit_index;
lock->trx->lock.n_rec_locks.fetch_add(1, std::memory_order_relaxed);
}
复制创建完lock_t后接着通过lock_add将他加入到lock_sys的hash table中和事务的锁链表中。
void RecLock::lock_add(lock_t *lock)
{
ut_ad((lock->type_mode | LOCK_REC) == (m_mode | LOCK_REC));
ut_ad(m_rec_id.matches(lock));
ut_ad(locksys::owns_page_shard(m_rec_id.get_page_id()));
ut_ad(locksys::owns_page_shard(lock->rec_lock.page_id));
ut_ad(trx_mutex_own(lock->trx));
bool wait = m_mode & LOCK_WAIT;
hash_table_t *lock_hash = lock_hash_get(m_mode);
lock->index->table->n_rec_locks.fetch_add(1, std::memory_order_relaxed);
if (!wait)
{
lock_rec_insert_to_granted(lock_hash, lock, m_rec_id);
} else
{
lock_rec_insert_to_waiting(lock_hash, lock, m_rec_id);
}
#ifdef HAVE_PSI_THREAD_INTERFACE
#ifdef HAVE_PSI_DATA_LOCK_INTERFACE
/* The performance schema THREAD_ID and EVENT_ID are used only
when DATA_LOCKS are exposed. */
PSI_THREAD_CALL(get_current_thread_event_id)
(&lock->m_psi_internal_thread_id, &lock->m_psi_event_id);
#endif /* HAVE_PSI_DATA_LOCK_INTERFACE */
#endif /* HAVE_PSI_THREAD_INTERFACE */
locksys::add_to_trx_locks(lock);
if (wait) {
lock_set_lock_and_trx_wait(lock);
}
}
复制至此完成了page上面如果没有锁的快速加锁操作。
另外page上如果有一把锁,则走下面这个分支:如果1)page上面多于一个锁,2)拥有锁的事务不是当前事务 ,3)已有锁和要加的锁模式不相同, 4)n_bits 小于 heap_no。如果以上四个任意一个为True则返回LOCK_REC_FAIL从而走慢加锁方式。如果上面都不满足,则直接通过lock_rec_set_nth_bit在这个锁上设置bitmap的位图信息。
if (lock_rec_get_next_on_page(lock) != nullptr||lock->trx != trx
||lock->type_mode != (mode | LOCK_REC) ||lock_rec_get_n_bits(lock) <= heap_no)
{
status = LOCK_REC_FAIL;
} else if (!impl)
{
/* If the nth bit of the record lock is already set
then we do not set a new lock bit, otherwise we do
set */
if (!lock_rec_get_nth_bit(lock, heap_no))
{
lock_rec_set_nth_bit(lock, heap_no);
status = LOCK_REC_SUCCESS_CREATED;
}
}
复制通过以下两个session模拟一个简单的阻塞场景,两个session都是通过字段c上面的二级索引更新同一行,此时session2会hang在这里,接下来,我们看看InnoDB锁阻塞实现的细节(code基于MySQL 8.0.28):
Create Table: CREATE TABLE `AWR` (
`id` int NOT NULL,
`c` int DEFAULT NULL,
`d` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
session1:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update AWR set d=20 where c=6;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
session2:
mysql> update AWR set d=88 where c=6; --hang
复制还是从sel_set_rec_lock这里出发,因为是针对二级索引做当前读,接下来会走入lock_sec_rec_read_check_and_lock这个分支
if (index->is_clustered())
{
err = lock_clust_rec_read_check_and_lock(
lock_duration_t::REGULAR, block, rec, index, offsets, sel_mode,
static_cast<lock_mode>(mode), type, thr);
} else
{
if (dict_index_is_spatial(index))
{
if (type == LOCK_GAP || type == LOCK_ORDINARY)
{
ut_ad(0);
ib::error(ER_IB_MSG_1026) << "Incorrectly request GAP lock " "on RTree";
return (DB_SUCCESS);
}
err = sel_set_rtr_rec_lock(pcur, rec, index, offsets, sel_mode, mode, type, thr, mtr);
} else
{
err = lock_sec_rec_read_check_and_lock(
lock_duration_t::REGULAR, block, rec, index, offsets, sel_mode,
static_cast<lock_mode>(mode), type, thr);
}
}
复制lock_sec_rec_read_check_and_lock会首先判断二级索引上面有没有隐式锁,判断的逻辑比聚合索引要复杂的多,因为聚合索引上每条记录都有trx_id,只要判断这个trx是不是活跃的就能确认有没有隐式锁。二级索引每个记录上面并没有这个隐藏列trx_id,但是每个page里保存了max_trx_id,当这个max_trx_id小于事务活跃列表的最小trx_id,说明这个事务已经提交了代表了没有隐式锁的存在,如果>=则进入lock_rec_convert_impl_to_expl这个分支里通过lock_sec_rec_some_has_impl判断二级索引有没有隐式锁。
if ((page_get_max_trx_id(block->frame) >= trx_rw_min_trx_id() ||recv_recovery_is_on()) && !page_rec_is_supremum(rec))
{
lock_rec_convert_impl_to_expl(block, rec, index, offsets);
}
复制lock_sec_rec_some_has_impl如果发现max_trx_id不满足小于事务活跃列表的最小trx_id,则认为有可能其他事务持有了隐式锁,则需要通过聚簇索引去判断,这个动作是由row_vers_impl_x_locked_low完成的:
通过获取保存在聚集索引记录上的trx_id做以下判断:
如果该trx_id对应的事务已提交,返回0不含有隐式锁。
如果事务未提交,需要通过undo找到是哪个事务修改了二级索引记录,并获取上一个版本记录和获取上一个版本的trx_id,构造上一个版本tuple,同时构造上一个版本二级索引tuple,再进行以下判断:
如果上一个版本没找到,说明这是一个新增的记录,则二级索引记录含有隐式锁。
如果两个版本的二级索引记录相同:
但是deleted_flag位不同,表示某活跃事务删除了记录,因此二级索引记录含有隐式锁。
deleted_flag位也相同,则需要查看trx_id和上一个版本trx_id是不是同一个,如果不同,说明之前的事务修改了记录,则二级索引记录不含有隐式锁,如果相同代表是同一个事务无法判断,需要继续通过undo查找前一个版本进行判断。
如果两个版本的二级索引记录不同:
且二级索引记录的deleted_flag为0,表示某活跃事务更新了二级索引记录,因此二级索引含有隐式锁。
且二级索引记录的deleted_flag为1,则需要查看trx_id和上一个版本trx_id是不是同一个,如果不同,说明之前的事务修改了记录,则二级索引记录不含有隐式锁,如果相同代表是同一个事务无法判断,需要继续通过undo查找前一个版本进行判断。
通过以上复杂的判断,如果有隐式锁则通过lock_rec_convert_impl_to_expl_for_trx将隐式锁转化为显式锁。
针对我们当前的case,因为是通过c字段的二级索引更新d的值,因此session1 不会更新c 字段上面的二级索引max_trx_id,因此不满足page内的max_trx_id >=事务活跃列表的最小trx_id跳过lock_rec_convert_impl_to_expl
(lldb) p page_get_max_trx_id(block->frame)
(trx_id_t) $3 = 22818
(lldb) p trx_rw_min_trx_id()
(trx_id_t) $4 = 23309
if ((page_get_max_trx_id(block->frame) >= trx_rw_min_trx_id() || recv_recovery_is_on()) && page_rec_is_supremum(rec))
{
lock_rec_convert_impl_to_expl(block, rec, index, offsets);
}
复制如果是以下语句update的是c字段的值,那么就会掉入lock_rec_convert_impl_to_expl从而通过以上复杂的判断看有没有隐式锁。
mysql> update AWR set c=66 where c=6;
-> 5554 if ((page_get_max_trx_id(block->frame) >= trx_rw_min_trx_id() ||
5555 recv_recovery_is_on()) &&
5556 !page_rec_is_supremum(rec)) {
5557 lock_rec_convert_impl_to_expl(block, rec, index, offsets);
Target 0: (mysqld) stopped.
(lldb) p page_get_max_trx_id(block->frame) >= trx_rw_min_trx_id()
(bool) $151 = true
(lldb) p trx_rw_min_trx_id()
(trx_id_t) $152 = 23337
(lldb) p page_get_max_trx_id(block->frame)
(trx_id_t) $153 = 23337
复制接下来则通过lock_rec_lock尝试给记录加锁,一样的套路首先是通过lock_rec_lock_fast去快速加锁,因为这个page上面有一把锁但是持有锁的事务不是本身,所以返回LOCK_REC_FAIL快速加锁失败。
if (lock_rec_get_next_on_page(lock) != nullptr || lock->trx != trx ||
lock->type_mode != (mode | LOCK_REC) ||
lock_rec_get_n_bits(lock) <= heap_no)
{
status = LOCK_REC_FAIL;
复制接下来进入lock_rec_lock_slow慢加锁过程,首先通过lock_rec_has_expl查看当前事务在这个记录上有没有更强的锁存在,如果存在则直接返回成功重用这个锁,InnoDB通过锁重用尽可能的减少锁的开销。
auto checked_mode =
(heap_no != PAGE_HEAP_NO_SUPREMUM && lock_mode_is_next_key_lock(mode))
? mode | LOCK_REC_NOT_GAP
: mode;
const auto *held_lock = lock_rec_has_expl(checked_mode, block, heap_no, trx);
if (held_lock != nullptr)
{
if (checked_mode == mode)
{
/* The trx already has a strong enough lock on rec: do nothing */
return (DB_SUCCESS);
}
复制lock_rec_has_expl中如果都满足以下条件则说明当前事务已经持有一个更强的锁:
持有锁的是同一个事务且不是一个insert intention lock
根据锁强弱关系矩阵判断现在持有的锁更强且这不是一个等待中的锁
return (Lock_iter::for_each(rec_id, [&](const lock_t *lock)
{
return (!(lock->trx == trx && !lock->is_insert_intention() &&
lock_mode_stronger_or_eq(lock_get_mode(lock), mode) &&
!lock->is_waiting() &&
(is_on_supremum ||
(p_implies_q(lock->is_record_not_gap(), is_rec_not_gap) &&
p_implies_q(lock->is_gap(), is_gap)))));
复制lock_mode_stronger_or_eq是通过以下锁强弱矩阵判断持有锁和申请锁的强弱,因为我们持有锁的和申请锁的不是同一个事务,因此不满足返回空代表当前事务并没有持有一个更强的锁。
/* STRONGER-OR-EQUAL RELATION (mode1=row, mode2=column)
IS IX S X AI
IS + - - - -
IX + + - - -
S + - + - -
X + + + + +
AI - - - - +
See lock_mode_stronger_or_eq().
*/
static const byte lock_strength_matrix[5][5] =
{
/** IS IX S X AI */
/* IS */ {TRUE, FALSE, FALSE, FALSE, FALSE},
/* IX */ {TRUE, TRUE, FALSE, FALSE, FALSE},
/* S */ {TRUE, FALSE, TRUE, FALSE, FALSE},
/* X */ {TRUE, TRUE, TRUE, TRUE, TRUE},
/* AI */ {FALSE, FALSE, FALSE, FALSE, TRUE}};
复制接下来通过lock_rec_other_has_conflicting查看有没有与其他事务存在锁冲突,判断锁冲突的核心逻辑由lock_rec_has_to_wait完成,首先判断申请的锁和持有的锁是不是同一个事务,如果是则返回false没有冲突。如果不是同一个事务且通过锁兼容矩阵判断申请的锁和持有的锁兼容则返回false没有冲突,锁的兼容性是通过以下矩阵去判断的,可以看到意向锁是互相兼容的。
static const byte lock_compatibility_matrix[5][5] =
{
/** IS IX S X AI */
/* IS */ {TRUE, TRUE, TRUE, FALSE, TRUE},
/* IX */ {TRUE, TRUE, FALSE, FALSE, TRUE},
/* S */ {TRUE, FALSE, TRUE, FALSE, FALSE},
/* X */ {FALSE, FALSE, FALSE, FALSE, FALSE},
/* AI */ {TRUE, TRUE, FALSE, FALSE, FALSE}};
复制如果锁不兼容那么还需要继续判断,满足以下任意条件都返回false不冲突,否则返回true冲突:
如果申请的是gap lock或者heap_no是supremum,且不是insert intention lock,返回false不冲突,因为非insert intention lock的gap锁是不用等待的,都不冲突.
如果申请的是非insert intention lock,且当前锁是一个gap lock,返回false不冲突
如果申请的是gap lock,且当前锁是lock_rec_not_gap锁也就是record lock,返回false不冲突
如果当前锁是insert intention lock,返回false不冲突
if (trx != lock2->trx && !lock_mode_compatible(static_cast<lock_mode>(LOCK_MODE_MASK & type_mode),lock_get_mode(lock2)))
{
/* If our trx is High Priority and the existing lock is WAITING and not high priority, then we can ignore it. */
if (is_hp && lock2->is_waiting() && !trx_is_high_priority(lock2->trx))
{
return (false);
}
/* We have somewhat complex rules when gap type record locks cause waits */
if ((lock_is_on_supremum || (type_mode & LOCK_GAP)) && !(type_mode & LOCK_INSERT_INTENTION))
{
/* Gap type locks without LOCK_INSERT_INTENTION flag do not need to wait for anything. This is because
different users can have conflicting lock types on gaps. */
return (false);
}
if (!(type_mode & LOCK_INSERT_INTENTION) && lock_rec_get_gap(lock2))
{
/* Record lock (LOCK_ORDINARY or LOCK_REC_NOT_GAP does not need to wait for a gap type lock */
return (false);
}
if ((type_mode & LOCK_GAP) && lock_rec_get_rec_not_gap(lock2))
{
/* Lock on gap does not need to wait for a LOCK_REC_NOT_GAP type lock */
return (false);
}
if (lock_rec_get_insert_intention(lock2))
{
/* No lock request needs to wait for an insert intention lock to be removed.
This is ok since our rules allow conflicting locks on gaps.
This eliminates a spurious deadlock caused by a next-key lock waiting for an insert intention lock;
when the insert intention lock was granted, the insert deadlocked on the waiting next-key lock.
Also, insert intention locks do not disturb each other. */
return (false);
}
return (true);
}
return (false);
}
复制当前case session2申请的锁和session1持有锁的lock_mode都是3为X互斥,type_mode = 35说明是next key lock不满足以上条件,所以返回true需要等待。
接下来进入add_to_waitq,首先是创建一个锁lock_t并加入等待队列,通过函数lock_create_wait_for_edge从waiter到blocker创建一条边到wait-for graph,8.0对死锁检测做了优化由后台线程异步去做的,最后通过set_wait_state设置事务的状态,如等待开始时间以及线程挂起等。
dberr_t RecLock::add_to_waitq(const lock_t *wait_for, const lock_prdt_t *prdt)
{
ut_ad(locksys::owns_page_shard(m_rec_id.get_page_id()));
ut_ad(m_trx == thr_get_trx(m_thr));
/* It is not that the body of this function requires trx->mutex, but some of
the functions it calls require it and it so happens that we always posses it
so it makes reasoning about code easier if we simply assert this fact. */
ut_ad(trx_mutex_own(m_trx));
DEBUG_SYNC_C("rec_lock_add_to_waitq");
if (m_trx->in_innodb & TRX_FORCE_ROLLBACK)
{
return (DB_DEADLOCK);
}
m_mode |= LOCK_WAIT;
/* Do the preliminary checks, and set query thread state */
prepare();
/* Don't queue the lock to hash table, if high priority transaction. */
lock_t *lock = create(m_trx, prdt);
lock_create_wait_for_edge(lock, wait_for);
ut_ad(lock_get_wait(lock));
set_wait_state(lock);
MONITOR_INC(MONITOR_LOCKREC_WAIT);
return (DB_LOCK_WAIT);
}
复制最后返回DB_LOCK_WAIT错误码给上层处理,至此session2线程hang住,等待被唤醒。
当按照如下顺序依次在三个trx中跑对应的SQL,会构造这样的一个等待链:trx3–>trx 2–>trx1–>trx3,最终会造成死锁将trx3回滚,接下来,我们看看InnoDB死锁检测实现的细节(code基于MySQL 5.7.34):
mysql> show create table amazon\G
*************************** 1. row ***************************
Table: amazon
Create Table: CREATE TABLE `awr` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
1 row in set (0.00 sec)
mysql> select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
trx1:
insert into awr values (6,6,6);
trx2:
update awr set d=22 where id=5;
trx3:
update awr set d=33 where id=4;
trx1:
update awr set d=11 where id=4;
trx2:
insert into awr values (6,22,22);
trx3:
update awr set d=33 where id=5;
复制触发死锁检测的条件是当一个事务进入慢加锁流程,由于与其他事务存在冲突,那么就需要通过add_to_waitq加入到等待队列并在此做死锁检测,死锁检测入口是deadlock_check。
* thread #30, stop reason = breakpoint 1.1
* frame #0: 0x000000010e2587c6 mysqld`RecLock::add_to_waitq(this=0x0000700003c30ea0, wait_for=0x00007f8d7b010218, prdt=0x0000000000000000) at lock0lock.cc:1740:31
frame #1: 0x000000010e27369b mysqld`lock_rec_lock_slow(impl=0, mode=1027, block=0x0000000118d49970, heap_no=3, index=0x00007f8d7d2602c0, thr=0x00007f8d732d1868) at lock0lock.cc:2001:19
frame #2: 0x000000010e263bb5 mysqld`lock_rec_lock(impl=false, mode=1027, block=0x0000000118d49970, heap_no=3, index=0x00007f8d7d2602c0, thr=0x00007f8d732d1868) at lock0lock.cc:2069:10
frame #3: 0x000000010e2649d3 mysqld`lock_clust_rec_read_check_and_lock(flags=0, block=0x0000000118d49970, rec="\x80", index=0x00007f8d7d2602c0, offsets=0x0000700003c32050, mode=LOCK_X, gap_mode=1024, thr=0x00007f8d732d1868) at lock0lock.cc:6422:8
frame #4: 0x000000010e3e56d0 mysqld`sel_set_rec_lock(pcur=0x00007f8d732d12b8, rec="\x80", index=0x00007f8d7d2602c0, offsets=0x0000700003c32050, mode=3, type=1024, thr=0x00007f8d732d1868, mtr=0x0000700003c32370) at row0sel.cc:1260:9
dberr_t err = deadlock_check(lock);
复制deadlock_check通过调用DeadlockChecker::check_and_resolve获得victim_trx从而将其回滚,check_and_resolve首先判断是不是开启了innobase_deadlock_detect,如果开启了则调用核心方法DeadlockChecker::search,其中使用了深度优先搜索算法,通过事务对象上的trx_t::lock.wait_lock构造事务的wait-for graph再进行判断,如果在搜索过程中检测到一个锁请求等待闭环就证明发生了死锁。DeadlockChecker::search首先是通过get_first_lock从lock_sys->rec_hash找到m_wait_lock对应的heap_no的第一个 lock。
/* We are only interested in records that match the heap_no. */
*heap_no = lock_rec_find_set_bit(lock);
ut_ad(*heap_no <= 0xffff);
ut_ad(*heap_no != ULINT_UNDEFINED);
/* Find the locks on the page. */
lock = lock_rec_get_first_on_page_addr(lock_hash,lock->un_member.rec_lock.space, lock->un_member.rec_lock.page_no);
/* Position on the first lock on the physical record.*/
if (!lock_rec_get_nth_bit(lock, *heap_no))
{
lock = lock_rec_get_next_const(*heap_no, lock);
}
复制具体检测逻辑是由下面这个大的循环去实现的:
for (;;)
{
/* We should never visit the same sub-tree more than once. */
ut_ad(lock == NULL || !is_visited(lock));
while (m_n_elems > 0 && lock == NULL)
{
//如果一行存在多个lock,当前路径已搜索完毕,需要回溯到未被访问过的节点
pop(lock, heap_no);//DFS回退一步
lock = get_next_lock(lock, heap_no);//获得相同heap_no的next_lock
}
if (lock == NULL)
{
break;
} else if (lock == m_wait_lock)
{
//DFS回溯,因一行存在多个lock,当掉入lock == m_wait_lock说明后面lock都是wait状态的,标记该子树已被访问过即可,不需要再继续查找
ut_ad(lock->trx->lock.deadlock_mark <= m_mark_start);
lock->trx->lock.deadlock_mark = ++s_lock_mark_counter;
/* We are not prepared for an overflow.
This 64-bit counter should never wrap around.
At 10^9 increments per second, it would take 10^3 years of uptime. */
ut_ad(s_lock_mark_counter > 0);
/* Backtrack */
lock = NULL;
} else if (!lock_has_to_wait(m_wait_lock, lock))
{
lock = get_next_lock(lock, heap_no);//不冲突继续查找next lock
} else if (lock->trx == m_start)
{//检测到环说明存在死锁
notify(lock);
return(select_victim());
} else if (is_too_deep())
{
/* Search too deep to continue. */
m_too_deep = true;
return(m_start);
} else if (lock->trx->lock.que_state == TRX_QUE_LOCK_WAIT)
{
/* Another trx ahead has requested a lock in an incompatible mode, and is itself waiting for a lock. */
++m_cost;
if (!push(lock, heap_no))
{//将<lock,m_wait_lock,heap_no>入栈,如果栈长度超过4096则说明栈太深也认为发生死锁,返回m_start
m_too_deep = true;
return(m_start);
}
m_wait_lock = lock->trx->lock.wait_lock;
lock = get_first_lock(&heap_no);
if (is_visited(lock))
{//已遍历过查找同一个heap_no上的next lock
lock = get_next_lock(lock, heap_no);
}
} else
{
lock = get_next_lock(lock, heap_no);
}
复制循环从m_start开始,就是触发死锁检测的事务,m_start自始至终不变,m_wait_lock初始值就是m_start等待的锁,m_wait_lock随着DFS搜索的进行不断被赋值,lock 就是m_wait_lock对应的heap_no的第一个 lock。
判断m_wait_lock需不需要等待lock,如果不需要,继续找对应heap_no的下一个lock。
如果需要等待,查看持有lock的trx是不是m_start,如果是的,则检测到环,返回m_wait_lock trx与m_start trx两者之中权重小的作为victim trx从而进行回滚,权重大小通常是根据事务的undo数量和持有的锁个数来决定,权重低的被回滚,权重高的获得锁。
如果需要等待,且第三步不满足,则查看DFS检测是不是超过阈值了,其中有两个阈值,一个是栈中元素超过了200,另外一个是访问的节点数目超过了100万,超过其中任一阈值也认为发生死锁,返回m_start作为victim trx。这主要是为了避免死锁检测的开销过大从而及时止损。
如果需要等待,且第三,四步不满足,判断lock所在的trx是不是处在等待状态中,如果是的,则将当前的lock入栈,深度加1,同时将lock所在的trx处于等待中的wait_lock赋值给m_wait_lock,接着继续取m_wait_lock对应的heap_no的第一个lock。如果此lock遍历过,则继续取这个heap_no上的下一个lock。持续以上循环。
接下来,我们从上面的例子中trx3的最后一条语句触发死锁检测开始跟踪:
进入循环前:
m_start就是trx3且一直保持不变,m_wait_lock是trx3正在等待中的锁,type_mode是1315,对应的锁类型是LOCK_X|LOCK_WAIT|LOCK_REC|LOCK_REC_NOT_GAP
lock是trx2持有的锁,type_mode是1059,对应的锁类型是LOCK_X|LOCK_REC|LOCK_REC_NOT_GAP
第一次循环:
直接掉入这个分支后:
else if (lock->trx->lock.que_state == TRX_QUE_LOCK_WAIT)
m_wait_lock是trx2正在等待中的锁,type_mode是1314,对应的锁类型是LOCK_S|LOCK_WAIT|LOCK_REC|LOCK_REC_NOT_GAP
lock是trx1持有的锁,type_mode是1059,对应的锁类型是LOCK_X|LOCK_REC|LOCK_REC_NOT_GAP
(lldb) p m_n_elems
(size_t) $58 = 0
(lldb) p m_cost
(ulint) $59 = 0
(lldb) p lock->trx->lock.que_state
(trx_que_t) $60 = TRX_QUE_LOCK_WAIT
/** DFS state information, used during deadlock checking. */ struct state_t { const lock_t* m_lock; /*!< Current lock */ const lock_t* m_wait_lock; /*!< Waiting for lock */ ulint m_heap_no; /*!< heap number if rec lock */ };复制
(lldb) p m_wait_lock
(const ib_lock_t *) $62 = 0x00007f8d7b010360
(lldb) p *m_wait_lock
(const ib_lock_t) $63 = {
trx = 0x00007f8d7c9fe8a0
trx_locks = {
prev = 0x00007f8d7b010218
next = nullptr
}
index = 0x00007f8d7d2602c0
hash = 0x00007f8d7b012760
un_member = {
tab_lock = {
table = 0x000000030000002e
locks = {
prev = 0x0000000000000048
next = nullptr
}
}
rec_lock = (space = 46, page_no = 3, n_bits = 72)
}
type_mode = 1314
}
(lldb) p/t 1314
(int) $64 = 0b00000000000000000000010100100010
第9个比特位置代表LOCK_WAIT:为1时,表示is_waiting为true
-> 7462 check_trx_state(m_wait_lock->trx);
7463 ut_ad(m_mark_start <= s_lock_mark_counter);
7464
7465 /* Look at the locks ahead of wait_lock in the lock queue. */
Target 0: (mysqld) stopped.
(lldb) p m_start
(const trx_t *) $0 = 0x00007f8d7c9ff120
(lldb) p *m_wait_lock
(const ib_lock_t) $1 = {
trx = 0x00007f8d7c9ff120
trx_locks = {
prev = 0x00007f8d7b012618
next = nullptr
}
index = 0x00007f8d7d2602c0
hash = nullptr
un_member = {
tab_lock = {
table = 0x000000030000002e
locks = {
prev = 0x0000000000000048
next = nullptr
}
}
rec_lock = (space = 46, page_no = 3, n_bits = 72)
}
type_mode = 1315
}
(lldb) p/t 1315
(int) $2 = 0b00000000000000000000010100100011
(lldb) p m_wait_lock->index->name
(id_name_t) $3 = (m_name = "PRIMARY")
get_first_lock
(lldb) p heap_no
(ulint *) $46 = 0x0000700003c30d48
(lldb) p *heap_no
(ulint) $47 = 3
(lldb) p lock
(const ib_lock_t *) $48 = 0x00007f8d7b010218
(lldb) p *lock
(const ib_lock_t) $49 = {
trx = 0x00007f8d7c9fe8a0
trx_locks = {
prev = 0x00007f8d6ff06568
next = 0x00007f8d7b010360
}
index = 0x00007f8d7d2602c0
hash = 0x00007f8d7b012618
un_member = {
tab_lock = {
table = 0x000000030000002e
locks = {
prev = 0x0000000000000048
next = nullptr
}
}
rec_lock = (space = 46, page_no = 3, n_bits = 72)
}
type_mode = 1059
}
(lldb) p lock_rec_get_nth_bit(lock, *heap_no)
(ulint) $50 = 1
复制(lldb) p lock
(const ib_lock_t *) $65 = 0x00007f8d7b00f160
(lldb) p *lock
(const ib_lock_t) $66 = {
trx = 0x00007f8d7c9fe460
trx_locks = {
prev = 0x00007f8d7b00f018
next = nullptr
}
index = 0x00007f8d7d2602c0
hash = 0x00007f8d7b010360
un_member = {
tab_lock = {
table = 0x000000030000002e
locks = {
prev = 0x0000000000000048
next = nullptr
}
}
rec_lock = (space = 46, page_no = 3, n_bits = 72)
}
type_mode = 1059
}
(lldb) p/t 1059
(int) $67 = 0b00000000000000000000010000100011
第二次循环:
依旧掉入这个分支后:
else if (lock->trx->lock.que_state == TRX_QUE_LOCK_WAIT)
m_wait_lock是trx1正在等待中的锁,type_mode是1315,对应的锁类型是LOCK_X|LOCK_WAIT|LOCK_REC|LOCK_REC_NOT_GAP
lock是trx3持有的锁,type_mode是1059,对应的锁类型是LOCK_X|LOCK_REC|LOCK_REC_NOT_GAP
(lldb) p m_cost
(ulint) $69 = 1
(lldb) p m_n_elems
(size_t) $70 = 1
(lldb) n
frame #0: 0x000000010e268475 mysqld`DeadlockChecker::search(this=0x0000700003c30d80) at lock0lock.cc:7537:19
7534
7535 lock = get_first_lock(&heap_no);
7536
-> 7537 if (is_visited(lock)) {
7538 lock = get_next_lock(lock, heap_no);
7539 }
7540
Target 0: (mysqld) stopped.
(lldb) p m_wait_lock
(const ib_lock_t *) $71 = 0x00007f8d7b00f018
(lldb) p *m_wait_lock
(const ib_lock_t) $72 = {
trx = 0x00007f8d7c9fe460
trx_locks = {
prev = 0x00007f8d6ff05e08
next = 0x00007f8d7b00f160
}
index = 0x00007f8d7d2602c0
hash = 0x00007f8d7b00f160
un_member = {
tab_lock = {
table = 0x000000030000002e
locks = {
prev = 0x0000000000000048
next = nullptr
}
}
rec_lock = (space = 46, page_no = 3, n_bits = 72)
}
type_mode = 1315
}
(lldb) p/t 1315
(int) $73 = 0b00000000000000000000010100100011
(lldb) p lock
(const ib_lock_t *) $74 = 0x00007f8d7b012618
(lldb) p *lock
(const ib_lock_t) $75 = {
trx = 0x00007f8d7c9ff120
trx_locks = {
prev = 0x00007f8d6ff07408
next = 0x00007f8d7b012760
}
index = 0x00007f8d7d2602c0
hash = 0x00007f8d7b00f018
un_member = {
tab_lock = {
table = 0x000000030000002e
locks = {
prev = 0x0000000000000048
next = nullptr
}
}
rec_lock = (space = 46, page_no = 3, n_bits = 72)
}
type_mode = 1059
}
(lldb) p/t 1059
(int) $76 = 0b00000000000000000000010000100011
(lldb) n
复制第三次循环:
此时lock因为是trx3持有的锁,所以满足lock->trx == m_start,检测到死锁,通过select_victim()比较trx3和m_wait_lock的trx也就是trx1的权重,最终返回trx3作为victim trx。
(lldb) p m_cost (ulint) $77 = 2 (lldb) p m_n_elems (size_t) $78 = 2 (lldb) p lock->trx == m_start (bool) $82 = true (lldb) p lock (const ib_lock_t *) $83 = 0x00007f8d7b012618 (lldb) p lock->trx (trx_t *const) $84 = 0x00007f8d7c9ff120 (lldb) p m_start (const trx_t *) $85 = 0x00007f8d7c9ff120 select_victim (lldb) p thd_trx_priority(m_start->mysql_thd) (int) $86 = 0 (lldb) p thd_trx_priority(m_wait_lock->trx->mysql_thd) (int) $87 = 0 (lldb) p trx_weight_ge(m_wait_lock->trx, m_start) (bool) $88 = true (lldb) p select_victim() (const trx_t *) $89 = 0x00007f8d7c9ff120复制
上述过程整理关系如下:
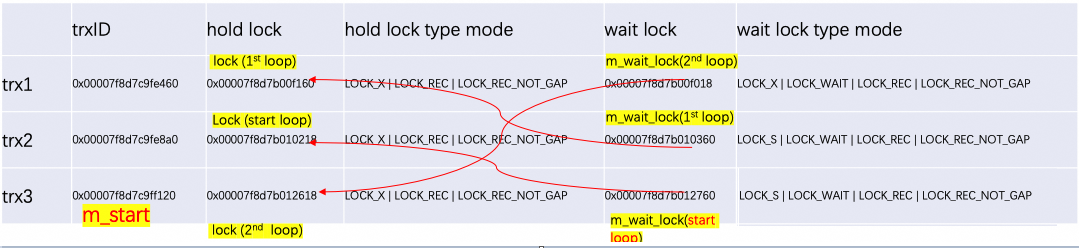
lock_sys->rec_hash的结构:

这个例子相对简单,没有涉及到一行数据上有多个锁,因此没有出现出栈回溯,实际情况可能要更复杂。
以上是5.7.34老的死锁检测机制,实际上从8.0.18开始,死锁检测发生了较大改变。老的死锁检测机制是由用户线程触发,在深度优先搜索wait-for graph时候会持有lock_sys->mutex,在热点行大量更新的时候比如秒杀场景下会引发大量线程等待lock_sys->mutex,从而有可能引发DB雪崩,在8.0.21中采用了分区latch来解决lock_sys->mutex过重的情况。从8.0.18开始,将原先的死锁检测机制交由后台线程lock_wait_timeout_thread异步来处理, 在检测锁超时的时候同时做死锁检测,具体实现是将当前DB中的事务lock信息做一个snapshot,在此snapshot上检测有没有死锁存在.
