




带有地理定位和文本内容的流式空间文本数据,如带有定位的推文,正变得越来越有用。用户可以使用连续的查询以持续得到最新的结果,也可以提出快照查询以立即获得结果。大规模的空间文本数据流和大量的查询对当前基于位置的服务提出了巨大的挑战,因此,我们需要一个有效的数据管理系统。本篇文章将带来国际顶级的数据库会议PVLDB 2020上的论文:《SSTD: A Distributed System on Streaming Spatio-Textual Data》[1]。

1.问题背景
随着支持GPS的移动设备的普及,出现了大量包含地理位置和文本内容的数据,也被称为空间-文本数据。基于位置的服务(LBS)是空间文本数据的重要来源,例如,推特上有地理标记的推文和Facebook上有地理标记的帖子。这些数据通常会以很快的速率到达,并且传递了很多有用的信息,比如某个热门话题以及人们对它的反应。用户可以发出不同类型的查询来从中获取有用的信息。例如,一个电影制作人可以提出一个快照查询,以收集一个城市内的观众对她的最新电影的意见。与此同时,为了从家乡收到关于她的电影的新评论,她可以注册一个关于社交媒体数据流的连续查询,比如推特,以接收关于她的电影的最新评论。
然而,开发一个支持大规模空间文本数据流的快照查询和连续查询,并且具有高吞吐量和低延迟特性的分布式系统是很困难的。首先,流式空间文本数据的快速到达速度对系统性能提出了很高的要求,例如,推特每天收到多达5亿条推文。其次,处理快照和连续查询的机制存在显著差异。对快照查询的高效处理需要对流对象的有效索引结构。相比之下,对连续查询的高效处理还需要对查询进行索引,从而有效地在流对象上持续产生查询结果。这就需要仔细设计系统体系结构,以无缝地处理快照查询和连续查询。
然而,现有的系统要么不能同时提供对快照和连续查询的支持,要么无法满足对空间文本数据流的低延迟和高吞吐量的系统性能要求。
因此,论文提出了一种新的处理流式空间文本数据的分布式系统SSTD。提出了各种算法以在分布式系统中支持高吞吐量和低延迟的空间文本数据流。
2.系统综述
一个空间文本对象以o=<φ,ρ,t>的形式表示,其中φ是一组关键字,ρ是该对象的地理位置(即经纬度),t是该对象的时间戳。SSTD支持以下三种查询:
范围关键字查询:范围关键字查询的查询形式为:q=<φ,r,τ>,其中φ是一组关键字,r是一个矩形区域,τ是一个时间段。对于快照查询,q返回包含q.φ的对象,它们位于q.r内,并且在最新的q.τ时间范围内(比如最近5s)。对于连续查询,q在系统中持续运行q.τ时间长度。在q的生命周期内,如果一个新到达的对象包含q.φ并且位于q.r的内部,则它被视为q的结果。
KNN查询:kNN查询的形式为q=<φ,ρ,k,τ>,其中φ是一组关键字,ρ是地理位置,k是整数,τ是一个时间段。与范围关键字查询的不同之处在于,它只返回与给定地理位置最近的k个对象。
Top K频繁关键字查询:该查询的形式为q=<r,k,τ>
,其中r是一个矩形区域,k是整数,τ是一个时间段。该查询返回的是在给定空间范围以及时间段内出现最频繁的k个关键字。
简洁起见,范围关键字查询的快照版本简称为SRQ,连续版本称为CRQ;KNN查询查询的快照版本简称为SKQ,连续版本称为CKQ;Top K频繁关键字查询查询的快照版本简称为STQ,连续版本称为CTQ。
SSTD建立在Apache Storm之上,其系统框架如图 1所示。
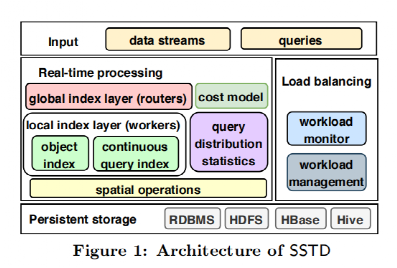
图1 SSTD的系统框架
Routers:为了划分工作负载并方便快照和连续查询的处理,我们设计了一种新的全局索引结构,称为QT-tree。QT-tree的目标是实现负载平衡,同时最小化总工作负载。当接收到新的对象或查询时,Router将其发给对应的Worker(s)。
Workers:每个worker为对象维护一个本地索引,为各种类型的连续查询维护索引,根据连续查询检查传入的数据对象并更新查询结果,通过对象索引检查传入的快照查询以产生结果。
负载均衡:负载均衡模块定期收集对象和查询的统计信息,以估计workers的工作负载,并判断是否发生负载不平衡。如果发生这种情况,SSTD将采用三种不同的方法来改变工作量分配,并相应地调整worker的工作量。具体的方法将在之后介绍。
存储:由于数据流是无限的,而用户通常对相对“新鲜”的数据感兴趣。因此,每隔一段时间,SSTD就会将过时的数据写入持久存储,以释放内存空间。
容错机制:SSTD扩展了Storm的容错机制,由Nimbus和Supervisor两个守护线程组成。Nimbus负责调度和监控Supervisor。Supervisor主管负责启动和杀死承担router和worker的线程。当router/worker发生故障时,Supervisor将重新启动它。如果它在启动时持续失败,Nimbus将创建一个新的router/worker。恢复后,新的worker将从磁盘加载QT-tree,并继续接收流对象和查询;新的worker将从持久存储中加载丢失的对象(如果它们已经持久化),以支持后续查询。对于Nimbus的容错能力,我们维护了由Zookeeper管理的多个Nimbus进程。如果目前的Nimbus死亡,另一个Nimbus将被选为新的领导人。
3.全局索引
SSTD在router上部署一个全局索引,称为QT-tree,将工作负载进行分区,旨在实现负载均衡。当路由器接收到一个对象或一个查询时,它会查找全局索引,并分派对应的worker(s)。
QT-tree是四叉树的一种变体,它允许节点根据对象的空间或文本属性进行分割。图 2给出了一个QT-tree的示例,其中节点N2基于空间属性进行划分,而N4基于文本属性进行划分。
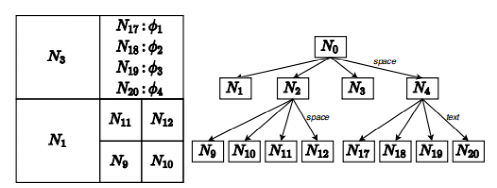
图 2 QT-tree示例
为了最小化总工作负载,同时保持所有worker之间的负载平衡,SSTD提出了新的成本模型用于估计一个区域的工作量。
为了计算该成本模型,我们需要查询分布统计信息,它表示每种类型的查询到达特定区域的概率以及查询关键字在该区域中的分布。如图 3所示,我们用J表示该四叉树。最初的统计数据来源于历史的对象和查询数据。对于J中的每个网格P,通过统计各类与P相交的查询数量并规范化,我们可以得到各类查询的概率,比如psrq代表与P相交的SRQ查询的数量。SSTD还统计了每单元时间内接收到的对象的平均数量Eobj。基于查询中收集到的关键字频率,SSTD估计了SRQ和SKQ在P中的查询关键字的分布(即Msrq和Mskq)。另外,SSTD还统计了查询关键字的平均数量、查询的时间窗口长度信息。
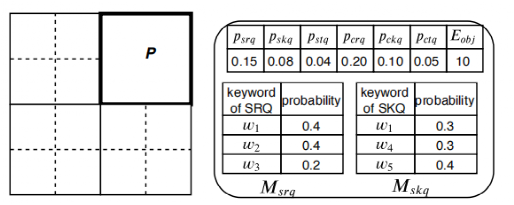
图 3 查询分布统计信息
SRQ的成本模型:给定分区P和位于P中的对象O,令P.r,P.φ分别表示P的MBR和从O中提取的关键字集。我们估计P在SRQ q下的工作负载为Wsrq=Pr(q.r∩P.r)∙Pr(q.φ⊆P.φ|q.r∩P.r)∙|O|。通过统计的psrq可以估计Pr(q.r∩P.r)。我们假设查询中各个关键字的分布是独立的,在满足空间约束的情况下q中的每个关键字被包含在的概率为: ,其中,Pw代表Msrq中w出现的概率。此时,
,其中,Pw代表Msrq中w出现的概率。此时,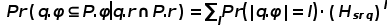 。其中,l是q中关键字的数量,Pr(|q.φ|)=l可以从统计数据中获得。
。其中,l是q中关键字的数量,Pr(|q.φ|)=l可以从统计数据中获得。
SKQ的成本模型:给定分区P和位于P中的对象O。当SRQ q到达时,我们估计P在SKQ q下的工作负载为Wskq=Pr(d(q,P)<d(q,q.r< span="">k))∙Pr(q.φ⊆P.φ|d(q,P)<d(q,q.r_k))∙|o|< span="">其中,q.Rk代表q中排名k的结果,我们使用pskq估计Pr(d(q,P)<d(q,q.r< span="">k))。其它部分的计算方式与SRQ类似。</d(q,q.r<></d(q,q.r_k))∙|o|<></d(q,q.r<>
STQ的成本模型:当STQ q到达时,我们使用Wstq (P)=Pr(q.r∩P.r)∙|O|表示其工作负载。其中,我们使用pstq来估计Pr(q.r∩P.r)。
连续查询的成本模型:当一个CRQ q到达时,如果q.r与P.r重叠,那么对于在q的生命周期内P中的每个传入流对象o,我们需要检查o是否更新了q的结果。因此,我们估计在一个CRQ下P的工作负载为Wcrq (P)=Pr(q.r∩P.r)∙EP.O。其中Pr(q.r∩P.r)由pcrq估计,EP.O为q存在期间P中新到达对象的预期数量,由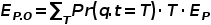 估计,其中T为q的时间窗口长度,Ep为每个时间单位到达P的对象的平均数量。Pr(q.t=T)和Ep都可以从查询分布统计数据中检索到。CKQ和CTQ的更新方式类似。
估计,其中T为q的时间窗口长度,Ep为每个时间单位到达P的对象的平均数量。Pr(q.t=T)和Ep都可以从查询分布统计数据中检索到。CKQ和CTQ的更新方式类似。
对于每个节点P,其工作负载的估计值为各种查询的工作负载之和。即W(P)=Pr(srq)∙Wsrq(P)+⋯+Pr(ctq)∙Wctq(P)。
我们采用离线方式构建QT-tree,首先根据历史数据生成查询分布统计数据。接着构建一个覆盖所有空间范围的根节点,其包含所有的对象。之后我们递归地对叶节点进行分割,直到叶节点的数量到达给定的阈值。在分割节点时有两种方案:(1) 空间分区,将一个节点分成4个空间大小相同的子节点,并根据对象的位置将父节点上的对象划分给子节点,如图 4中(a)所示。(2) 文本分区,如图4中(b)所示,四个子节点与父节点拥有相同的MBR,而父节点中的对象是根据文本内容分配给四个子节点。我们希望具有相似文本内容的对象分配到一个节点中,具体而言,在选择将一个对象插入哪个节点时,我们计算该对象对每个子节点带来的负载的提升,并选择将其插入到提升最小的那个子节点。然后,我们对比空间分区和文本分区后的子节点工作负载之和,选择工作负载较小的那一种分区方式。最后,为了使各个worker之间负载均衡,SSTD使用启发式算法将叶节点分配给不同的worker。
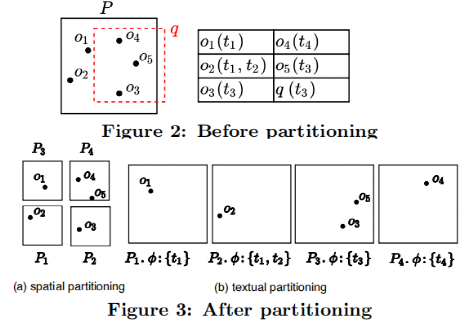
图 4 节点分割
SSTD中的每个router从磁盘中加载QT-tree的一个副本,在接收到新对象或查询时以轮询调度的方式选择router。当接收到新对象时,我们遍历QT-tree以将其分配给对应的worker,当节点以空间的方式进行分区时,接下来根据对象的空间属性访问对应的子节点,当节点以文本的方式进行分区时,访问对工作负载量影响最小的那个子节点。在处理查询时,由于在更新对象后每个router维护的RT-tree可能有所不同(节点维护的关键字列表会可能会变化),因此我们遍历RT-tree时只检查空间约束。对于SKQ和CKQ查询,由于无法获得对应的空间范围,因此SSTD会将其发送给所有的worker进行处理。并且,只有在重新平衡工作负载时,我们才更改真正的RT-tree。重新调整工作负载的方法将在下一节介绍。
4.负载均衡
由于数据和查询分布随着时间的推移可能会发生变化,分配给worker的工作负载会逐渐变化,这可能导致负载不平衡。为了避免系统性能下降,SSTD需要进行工作负载调整,以重新平衡负载。
SSTD定期从worker收集每个叶节点的统计信息,并计算他们的工作负载,令Lmax为worker中工作负载最大值,Lmin为worker中工作负载最小值,当Lmax / Lmin>λ 时(λ是给定值),我们需要重新调整工作负载。
SSTD中提出了两种工作量调整策略。(1) 工作负载重新分配:目的是改变叶节点分配方案,打乱叶节点并将其重新分配给工作节点。(2) QT-tree调整:旨在更新QT-tree的结构,然后将更新后的叶节点分配给worker。工作负载重新分配可以有效地进行工作负载调整,并且网络成本较小。在许多情况下,它可以有效地恢复负载平衡。当它不能平衡的时候再调整QT-tree。
对于方案(1),我们首先通过Karmarkar-Karp算法将叶节点分成k个集合,k为worker的数量。然后,我们找到使得传输的总成本最小的方式来将集合分配给worker。比如当前某个worker对应的子节点为{P1,P2,P3},若新分配的集合为{P2,P5},那么传输成本为P5的成本(原来没有节点P5)。在传输时我们只分配节点的连续查询到新的worker,因为这样相对于传输对象而言网络开销更小,这样可能会导致快照查询出问题,之后会讨论解决方案。我们使用匈牙利算法找到使得传输成本总和最小化的分配方案,该调整方案用FM表示。为了降低网络开销,我们还可以只调整负载最大的worker和负载最小的worker,该方案用PM表示。
仅传输连续查询的设计所带来的一个问题是,该方案将导致在工作负载重新分配后到达的一些快照查询的不完整结果,因为在调整时间之前的对象是查询不到的。为了解决这个问题,router维护不同版本的叶节点映射表,并且每个版本都与验证时间戳相关联。当接收到快照查询q时,路由器会检查这些映射表,并找到可能包含结果对象的worker。
在工作负载重新分配无法重新平衡负载的情况下,这意味着当前的QT-tree不能很好地分配工作负载,例如,一些叶节点负载很大,而其他叶节点负载很小。为了重新平衡负载,SSTD通过迭代调用两个操作来更新当前QT-tree的结构:分割工作负载大的叶节点,以及合并工作负载小的叶节点。在更新QT-tree后,我们在更新后的QT-tree上调用FM来执行工作负载的重新分配。这个策略表示为FG。
在分割叶节点时,如果我们采用构建QT-tree时采用的算法,那么我们需要从worker那儿检索有关对象的详细信息,这会造成巨大的网络开销。这里,SSTD采用启发式算法来选择使用空间分区还是文本分区。大致的思想是:如果我们想分割节点P,我们首先找到覆盖P的MBR的最小节点N,然后计算N和N的子节点之间的查询分布相似性(该分布只与空间相关),相似度越小,说明查询在空间分区之后是可区分的,此时采用空间分区方式可能较好。假如给定阈值ε,那么相似度小于ε 的话我们采用空间分区方式,否则我们选择文本分区方式。
合并操作:合并仅适用于非叶节点P,其四个子节点均为叶节点。它将连续查询从所有四个子节点移动到P,并删除子节点(使P成为一个新的叶节点)。
接下来介绍如何使用分割和合并算法来调整负载:记四叉树为G,我们使用Lmax来记录G中叶节点的最大工作负载,并使用最小堆H来存储可以合并子节点的节点。对于每个候选节点,如果它的工作负载小于Lmax,我们将其插入到H中。然后,我们递归地对G应用分割和合并操作,直到负载均衡约束得到满足。在每次迭代中,分割负载最大的叶节点P,并相应地更新Lmax的值。接下来,从H中弹出一个节点P0,如果它的工作负载大于Lmax,那么我们就不能通过更多的合并操作来进一步减少叶节点之间的工作负载差异,因此我们终止。否则,我们将对P0执行合并操作。如果合并操作导致一个新的候选节点(即 的父节点),我们将新的候选节点推入H。然后,我们通过调用Karmarkarar-Karp算法来检查是否满足负载平衡约束,如果满足,则终止。
的父节点),我们将新的候选节点推入H。然后,我们通过调用Karmarkarar-Karp算法来检查是否满足负载平衡约束,如果满足,则终止。
5.本地索引和查询处理
在工作负载分配之后,每个worker都被分配了QT-tree的多个叶节点。对于分配给worker的每个叶节点,worker将为其中的对象和连续查询构建和维护单独的索引结构。
对于对象,SSTD将数据划分为不同的时间间隔,例如,[t0,t0+Δ), [t0+Δ,t0+2Δ)…并为每个时间间隔构建索引结构(现有的空间-文本索引)。当接收到一个新的对象o时,工作者会找到覆盖o的时间戳的时间间隔,并将o插入到相应的索引结构中。为了提高STQ的查询效率,SSTD还维护了一个统计对象索引中每个节点的关键字频率的哈希表。
对于CRQ和CTQ,SSTD采用现有的索引技术。对于CTQ,SSTD报告每个δ时间单位出现最频繁的关键字。现有工作没有为CTQ查询设计专门的索引结构。SSTD扩展了哈希表和订阅组技术[4]用于索引CTQ。其主要思想是根据CTQ的查询区域将其划分为组。图 5给出了一组CTQ的索引示例。对于每个组,我们维护一个公共哈希表,它存储了所有查询的交叉区域的关键字频率存储(图 5中的阴影),以及一个单独的哈希表,它存储在每个查询除了交叉区域以外的区域的关键字频率。
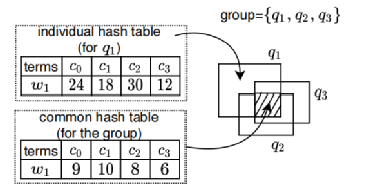
图 5 CTQ索引
处理快照查询:worker接收到一个SRQ查询q后,它访问对象索引找到满足q的时间约束的,之后访问对应的空间文本索引找到符合空间和文本约束的对象,然后将它们发给一个特定的worker以合并得到最终的结果。SSTD处理STQ的方式类似于SRQ。具体来说,当工作人员接收到一个STQ时,它会在索引中搜索满足时间约束的对象,然后结合对应的关键字频率表,将结果发送到合并过程中。SSTD分两个阶段处理一个SKQ q。在第一阶段,router找到最接近q.ρ的叶节点,并将q发送给相应的worker。然后,worker根据对象索引检索q的k个初始结果,并输出半径r,即q与初始结果中第k个最远对象之间的距离。如果初始结果包含的对象小于k个,则我们将r设置为一个大值。然后,工作人员将(q,r)发送回路由器。在第二阶段,路由器从worker那里接收到(q,r)后,使用r来构造q的范围约束,并以与处理SRQ相同的方式处理q。在第二阶段结束时,workers报告它们的k个结果进行合并。
处理连续查询:每个worker通过将这三种类型的连续查询插入到相应的索引结构中来处理这些查询。在插入新对象时,根据查询索引可以得知受影响的查询,之后需要更新对应的结果:(1)对于每个受影响的CRQ q,worker发送o用于合并。(2)对于每个受影响的CKQ q,worker发送o用于合并。如果合并发现d(o,q)>r,(r是q与其最新的第k个结果对象之间的距离),那么忽略o。(3)对于CTQ,worker更新了每个受影响的CTQ组的哈希表。每δ时间,worker将存储关键字频率信息的哈希表发送给用于处理合并的worker。
6.实验评估
SSTD部署在Amazon EC2平台上,它运行在一个包含10个c5.2xlarge实例的集群上。每个实例都有8个运行Intel Xeon E5-2680@3.4GHz的vcpu和16GB内存。所有实例都通过一个10Gbps的网络连接,并在Ubuntu16.04LTS上使用Storm1.1.0和Kafka1.1.0运行。
我们使用了来自推特的两个真实数据集。第一个数据集在2014年8月包含6300万条推文,其大小为5.9GB,第二个数据集在2015年8月包含5200万条推文,大小为4.6GB。每条推文平均包含10个关键词。词汇量的大小大约为800k。我们将它们分别表示为TW14和TW15。由于我们没有真正的查询,我们以以下方式合成它们:我们采样一小组推文,对于每条推文,我们利用其文本内容和地理位置生成查询,查询关键字的范围从1到3(默认为1),查询区域的面积为0.0001%到1%(默认为0.01%),k值从10到40(默认值为10),时间从24小时到168小时(默认值为72)。我们为每种类型的查询生成400k个查询。
比较方法。我们使用两种最先进的空间数据流处理系统,即Tornado[2]和PS2[3],作为基线来评估全局索引的性能。我们还采用了两个简化版本的QT-tree作为基线。Quadtree:在QT-tree的构造中,我们总是应用空间划分。Text:在QT-tree的构造中,我们总是应用文本划分。
我们首先研究了SSTD在不同的数据集上的性能差异,Uni和Gau为合成数据集,其中Uni中的对象分布均匀,Gau中对象的位置分布满足二维高斯分布。结果如图 6所示,SSTD在不同的数据集上表现出相似的变化趋势,即使Gau数据集中数据倾斜较严重。由于TW14和TW15的结果相似,在其余的实验中只说明TW14的结果。
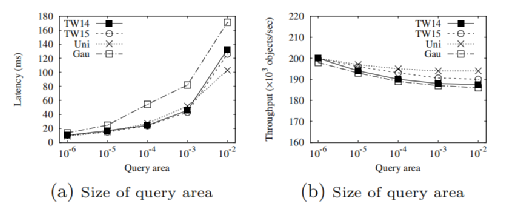
图 6 不同数据集
接下来我们展示SRQ在不同系统中的查询延迟(其它类型查询参考原论文[1]),如图 7所示。可以发现SSTD在查询区域以及关键字数量变化时始终保持最低的延迟。当查询区域为整个空间的0.0001%时,SSTD比基线快2-4倍。随着查询区域大小的增加,差异会变大。(b)显示了查询关键字数量的影响。当查询关键字的数量增加时,查询延迟就会变小,SSTD的性能最好,其查询延迟总是小于10ms。
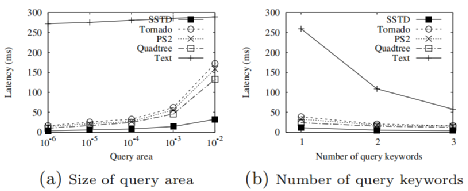
图 7 SRQ查询延迟
接下来展示的是SSTD的可伸缩性。在图8(a)中,数据均来源于TW14,查询延迟为10000个SRQ的平均延迟,可以发现,SSTD速度始终比基线快3-4倍。随着对象数量的增加,SSTD和基线之间的差异会变大。评估查询数量的影响时,我们分别将0.5M、1M、5M和10M的CRQ预加载到系统中,并以每秒20万个对象的到达率作为流式数据,图8 (b)给出了系统的吞吐量。可以观察到SSTD的吞吐量始终最大。
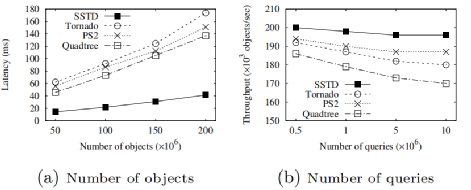
图 8 可伸缩性
为了评估SSTD提出的工作量调整方法的有效性和效率,我们比较了六种调整策略下的查询延迟等的不同。为了模拟负载不平衡的发生,我们随机选择一个区域并插入大量的连续查询和对象。我们接下来展示在插入不同数量的对象后各类调整策略的表现,如图 9和图 10所示。可以发现,PM、FM和FG极大地改善了负载均衡,从而提高了查询延迟和吞吐量。例如,在50M对象下,PM、FM和FG分别降低了69.3%、76.6%和85.1%的查询延迟(c),分别提高了78.4%、86.6%和97.9%的吞吐量(d)。比较(c)和(d),可以发现FG的查询延迟和吞吐量最好,其次是FM,然后是PM。然而,(a)和(b)表明,FG产生的网络成本最大,并且进行负载调整的时间最长。
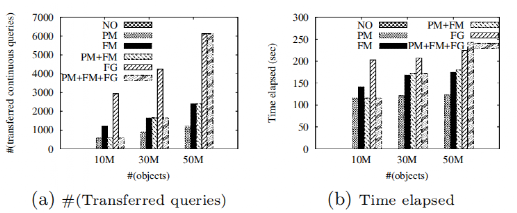
图 9 插入对象(1)
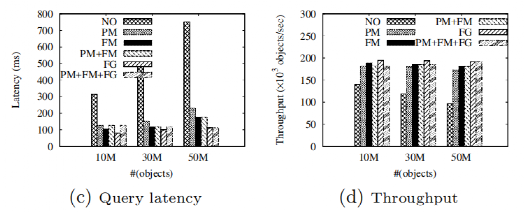
图 10 插入对象(2)
接下来论文还研究了在插入不同大小的连续查询之后各类调整策略的表现,综合调整时间和对负载均衡的改善,论文提倡使用PM+FM+FG策略。
论文也研究了不同给定参数下系统性能的差异,如QT-tree中最小叶节点数的阈值,具体结果可参考[5]。
参考文献:
[1].Chen, Yue, et al. "SSTD: a distributed system on streaming spatio-textual data." Proceedings of the VLDB Endowment 13.12 (2020): 2284-2296.
[2].A. Mahmood, A. Aly, T. Qadah, E. Rezig, A. Daghistani, A. Madkour, A. Abdelhamid, M. Hassan, W. Aref, and S. Basalamah. Tornado: A distributed spatio-textual stream processing system. PVLDB, 8(12):2020–2023, 2015.
[3].Z. Chen, G. Cong, Z. Zhang, T. Fu, and L. Chen. Distributed publish/subscribe query processing on the spatio-textual data stream. In ICDE, pages 1095–1106, 2017.
[4].L. Chen, S. Shang, Z. Zhang, X. Cao, C. S. Jensen, and P. Kalnis. Location-aware top-k term publish/subscribe. In ICDE, pages 749–760, 2018.
[5].https://www.ntu.edu.sg/home/gaocong/sstdfull.pdf
