




作者:马顺华
从事运维管理工作多年,目前就职于某科技有限公司,熟悉运维自动化、OceanBase部署运维、MySQL 运维以及各种云平台技术和产品。并已获得OceanBase认证OBCA、OBCP证书。

测试环镜资源信息
| 机器类型 | 主机配置 | 备注 |
|---|---|---|
| OS | Centos 7.4 | |
| 中控机 /OBD | CPU:8C | 内存:16G |
| 目标机器 /OBserver | CPU:8C | 内存:32G |
| 系统盘 / | dev/vda 100G | LVS分区、文件系统:EXT4 |
| 数据盘 /data | dev/vdb 200G | GPT分区、文件系统:xfs |
| 事务日志盘 /redo | dev/vdc 100G | GPT分区、文件系统:xfs |

资源规划
| 角色 | 机器IP | 备注 |
|---|---|---|
| OBD | 172.10.3.131 | 中控机 |
| OBserver | 172.10.3.20 | {2881,2882}, {3881,3882} zone1 |
| 172.10.3.21 | {2881,2882}, {3881,3882} zone2 | |
| 172.10.3.22 | {2881,2882}, {3881,3882} zone3 | |
| OBproxy | 172.10.3.20 | {2883,2884} 反向代理 |
| 172.10.3.21 | {2883,2884} 反向代理 | |
| 172.10.3.22 | {2883,2884} 反向代理 | |
| OBAgent | 172.10.3.20 | 监控采集框架 默认端口 8088、8089 |
| 172.10.3.21 | 监控采集框架 默认端口 8088、8089 | |
| 172.10.3.22 | 监控采集框架 默认端口 8088、8089 | |
| OBclient | 172.10.3.131 | OB命令行客户端 |
前言
OceanBase 集群有强一致和高可用能力,还有高性能。用户容易理解高性能,可能不理解强一致和高可用背后的要付出的成本。如集群节点间要保持时间同步误差和网络延时最小。集群节点之间的网络延时太大、时间同步延时太大会影响集群的性能甚至稳定性。
所以性能诊断首先要学会观察租户整体性能 ORACLE 数据库有 AWR 报表,可以方便诊断人员快速了解数据库在某个时间点的性能问题和原因。AWR 依赖很多内部视图,其中部分视图在 OceanBase 里也实现了。只是暂时 OceanBase 还没有实现 AWR 报表(研发中)。OceanBase 运维平台 OCP 里提供了丰富的性能展示功能方便对 OceanBase 进行诊断。
OceanBase 里也记录了会话和 SQL 的等待事件,这一块功能还不是很成熟,大部分性能问题只要分析 SQL 就能解决。所以等待事件就不看了。OceanBase 的 SQL 诊断,建议关注 租户的 QPS(每秒 SQL 请求数,包括 SELECT 、INSERT、UPDATE、DELETE )以及其 RT(SQL 执行耗时)、TPS(每秒事务数,跟 ORACLE 一致 )以及其 RT(事务提交延时)。此外,关注这些指标在 OceanBase 集群节点上的性能信息。
OceanBase 集群的性能瓶颈不会首先在 IO ,而更容易在内存,其次是 CPU 。所以还需要关注 每秒内存的变化。具体是指增量内存的使用情况。使用 OceanBase 自带的命令行监控脚本 dooba 可以观察很方便实时观察 OceanBase 租户性能。
一、部署准备
DOOBA
DOOBA 是 OceanBase 数据库内部的一个运维脚本,用于性能监控,使用 Python 语言开发,且仅支持 Python 2.7。本文将详细介绍如何使用 DOOBA 对 OceanBase 数据库性能进行监控。详细的使用说明,请参考 DOOBA。
1、安装依赖工具 Python 2.7
[root@CAIP131 admin]# python --version
Python 2.7.5

2、安装依赖工具 MySQL 5.7
运行 DOOBA 需要使用 MySQL 客户端,若您没有 MySQL 客户端,需要安装一个。
说明;早期的 OBPROXY(版本低于 2.0.0)可能不完全兼容 MySQL 8.0 的连接协议,因此,您需尽量安装版本为 5.5/5.6/5.7 的 MySQL 客户端。
[root@CAIP131 admin]# mysql -V
mysql Ver 14.14 Distrib 5.7.16, for Linux (x86_64) using EditLine wrapper
[root@CAIP131 admin]#

二、DOOBA 使用方法
DOOBA 的原理是使用 MySQL 命令连接到 OceanBase 的 SYS 租户中,实时展示租户 SQL 的 QPS(包括 select、update、insert、delete、commit)以及相应 SQL 的平均延时(RT)。同时还可以展示各个节点的 SQL 的 QPS 以及 RT 等。
1、下载 DOOBA 工具脚本文件
DOOBA 工具的脚本文件 dooba.py,可以在 OceanBase 数据库开源社区中查看下载。
GitHub 项目地址:https://github.com/oceanbase/oceanbase/blob/master/tools/scripts/dooba.py
Gitee 项目地址:https://gitee.com/oceanbase/oceanbase/blob/master/tools/scripts/dooba.py
https://www.oceanbase.com/docs/community-tutorials-cn-10000000000012309
2、DOOBA 使用命令如下:
python dooba.py -h OBPROXY地址 -u root@sys#集群名 -P OBPROXY端口 -p密码
// 例如:
python dooba.py -h 172.20.249.54 -u root@sys#obce-3zones -P 2883 -pxxxxxx
[root@CAIP131 admin]# python dooba.py -h 171.10.3.20 -uroot@sys#obce-test -P3883 -p#######

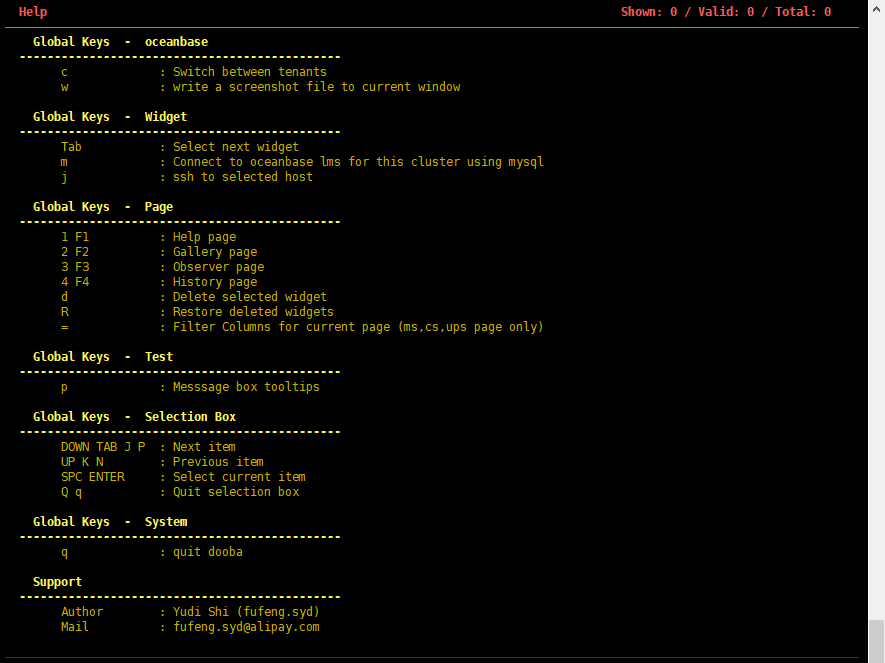
3、登录后常用的快捷键如下:
c:选择租户,一般是观察业务租户的性能。
1):查看快捷键。
注意
快捷键界面中没有提到的快捷键尽量不要使用,我们不保证其功能正确。
2):查看租户性能概览。
3):查看租户各个节点的性能概览,但如果节点很多则会显示不全。
tab:在各个 widget 之间跳转。
d:删除 tab 焦点所在的 widget。
R:恢复当前界面所有的 widget 布局(包括被删除的)。
4、编辑查看脚本
脚本 DOOBA 的源码可以直接编辑查看,您可使用命令 vim dooba.py 进行查看。工具中各个缩写对应的含义在源码里都能找到解释。
[root@CAIP131 admin]# vim dooba.py
5、DOOBA 查看租户性能概览
使用快捷键 2 可查看租户性能概览,主要是查看租户层面的 SQL 语句的 QPS、RT 以及内存、IO 等实时信息。
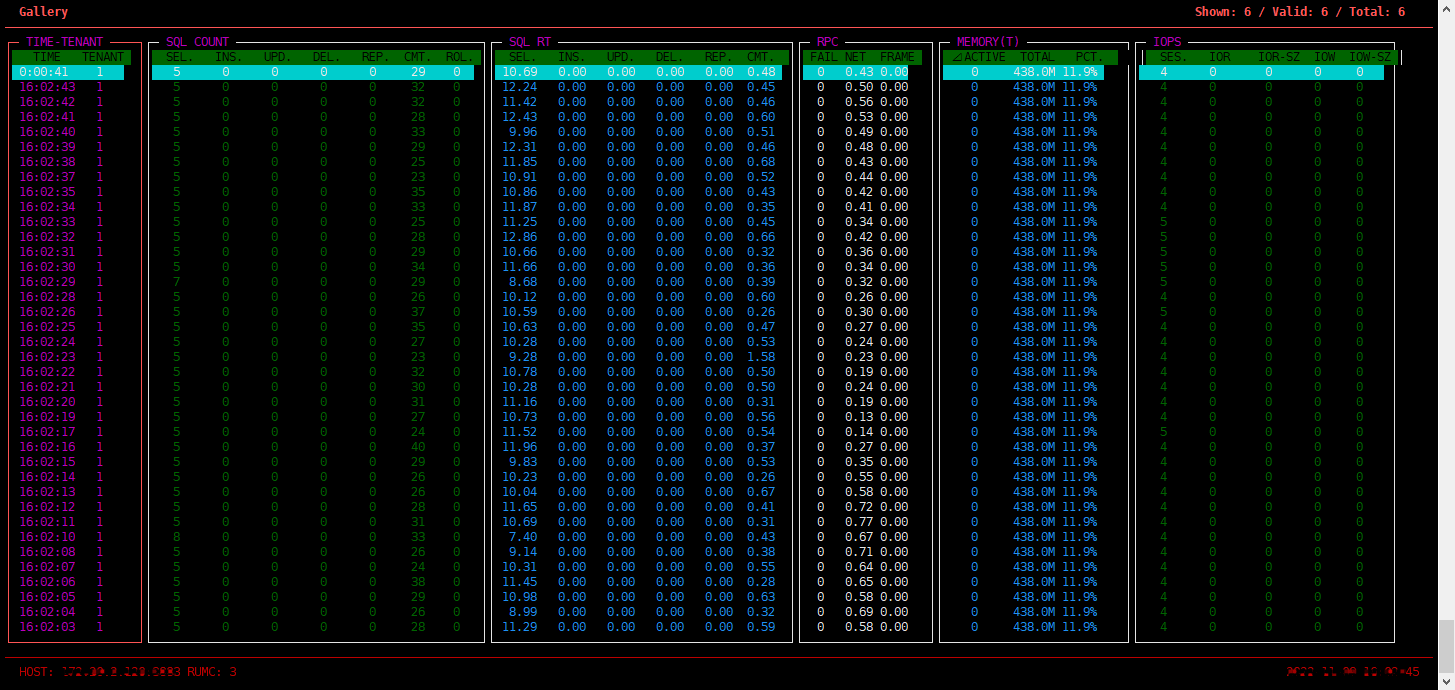
DOOBA 的性能数据取自 SYS 租户的内部视图 gv$sysstat。DOOBA 的监控信息均可使用 SQL 语句直接查看,可以参考 DOOBA 做类似的监控产品。
# 取 QPS 和 RT 信息
MySQL [oceanbase]> SELECT t1.con_id tenant_id,t2.zone, t1.svr_ip,t1.svr_port , t1.stat_id, t1.name, t1.value
-> FROM gv$sysstat t1 JOIN __all_server t2 ON (t1.svr_ip=t2.svr_ip and t1.svr_port=t2.svr_port) JOIN __all_resource_pool t3 ON (t1.con_id=t3.tenant_id) JOIN __all_unit_config t4 ON (t3.unit_config_id=t4.unit_config_id)
-> WHERE t1.con_id IN (1001)
-> and stat_id in (10000,10004,10005,10006,30007,30008,30009,40000,40001,40002,40003,40004,40005,40006,40007,40008,40009,40010,40011,40012,40013,50000,50001,50002,50003,50004,50005,50006,50007,50008,50009,50010,50011,60000,60002,60003,60005,130000,130001,130002,130004)
-> ORDER BY t1.con_id, t2.zone, t1.svr_ip, t1.svr_port;
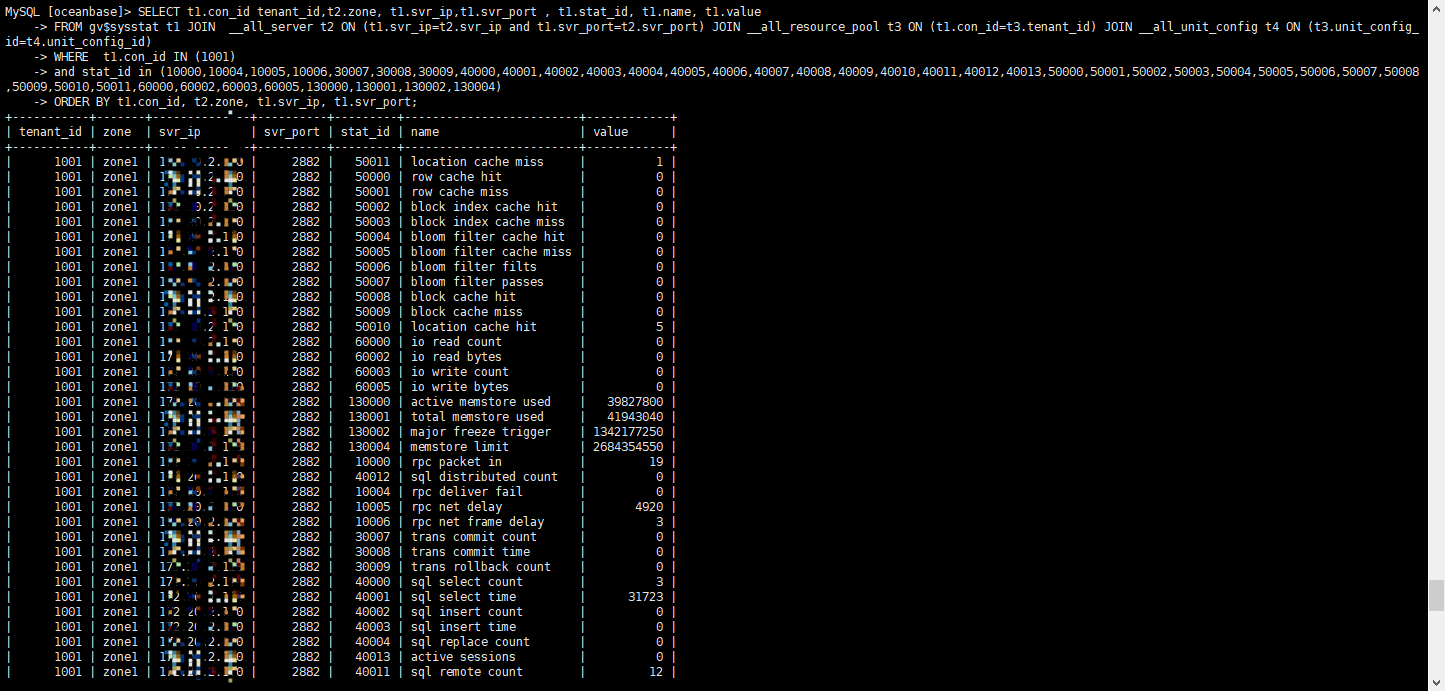
使用该 SQL 语句可以取出所有节点的性能数据,汇总就是整个租户的性能数据。
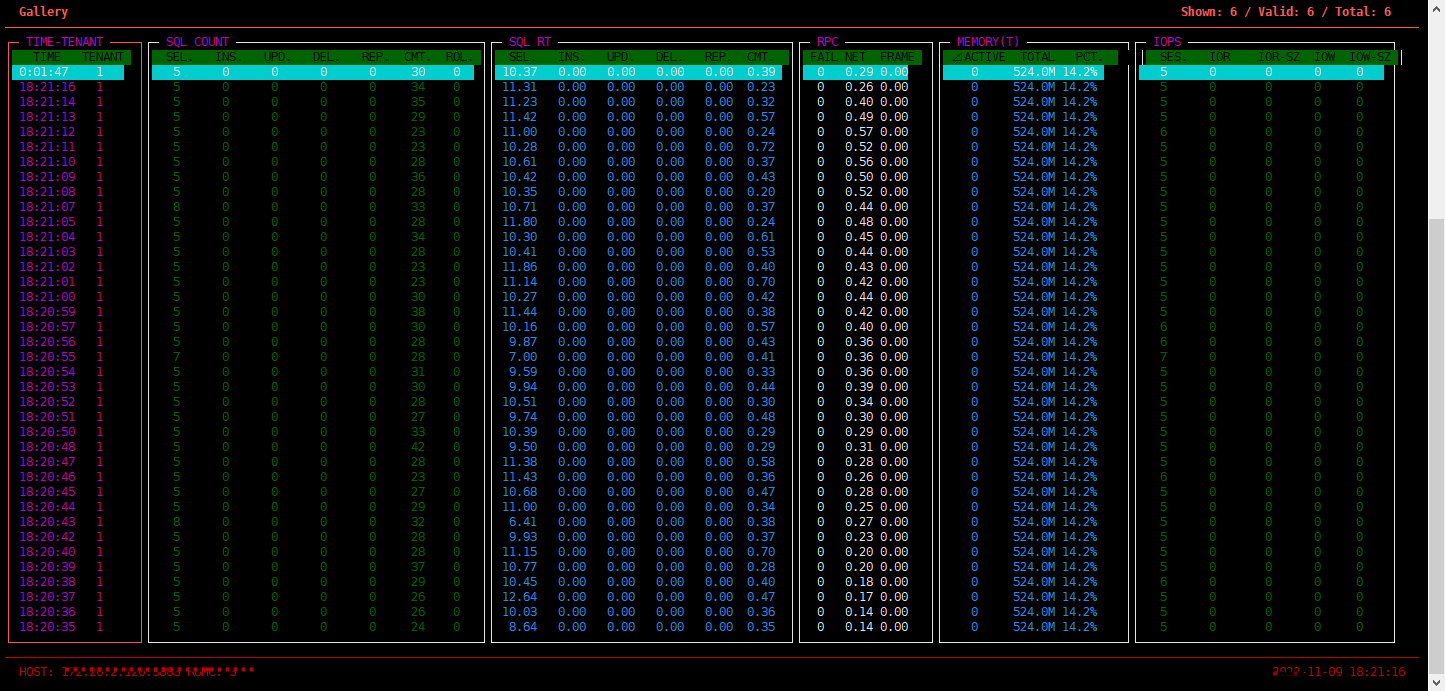
这个界面主要关注点:
SQL COUNT
QPS 信息,包括各类 SQL 语句的每秒执行次数。 SQL 类型分别为 select、insert、update、 delete、replace、commit、rollback。
其中,前四类 SQL 总数和 commit 的比值大致可以推出事务的平均语句数。rollback 是回滚的信息,如果太高,很有可能是数据库有问题或者业务设计有问题。
SQL RT
SQL 每次平均执行耗时,包括各类 SQL 语句的每次平均执行耗时,单位为毫秒(ms)。SQL 类型分别为 select、insert、update、 delete、replace、commit。
其中,前四类可以看出 SQL 正常情况下的执行耗时水平。如果有大幅变动,可能是因为数据量突增、有 SQL 缺乏索引、有锁等待或 CPU 瓶颈等等,具体分析需要结合 SQL 审视视图 gv$sql_audit 验证。
commit 的平均执行耗时也可以反映事务的大小。OceanBase 数据库的 commit 会同步事务所有的事务日志(clog)到多数派节点(包括自身),这个时间会反映在 commit 的耗时里,即 commit 耗时包含多数派同步事务日志的时间。如果这个值突然增长很大,说明可能有突发的大事务。当节点网络性能下降时或者时间同步误差变大时,都可能导致 commit 耗时增长。
RPC
反馈网络信息,后续待完善,您暂时可不用关注。
Memory
Memstore 内存的实时监控。默认情况下,租户可用内存的一半用于 Memstore 的内存,用于存放业务写操作带来的变化的数据。
OceanBase 数据库的特色之一就是写只记录数据的变化部分,并且数据会尽可能的维持在内存里不落盘,直到增量内存利用率达到阈值(参数 freeze_trigger_percentage)后触发转储或合并才将数据落盘并释放内存。
下面介绍一下转储和合并的概念:
转储是内存中增量数据直接写到磁盘暂存。类似与传统数据库的 checkpoint,对租户性能影响很小并且可以调优。
合并是内存中增量数据跟磁盘中基线数据在内存中合并为最新的数据块(sstable)再写回到数据文件中。合并对租户性能影响稍大一些并且也是可以调优的。
通常会建议尽量发起转储,等凌晨低峰期时再发起合并操作。合并可以定时触发,也可以手动触发。当转储次数(参数 minor_freeze_times )用尽时也会自动触发合并。
Memory 显示的就是增量内存的变化量、累积量和增量内存使用水位。监控结果结合视图 gv$mem_store 基本上可以定位所有的增量内存不足问题。
当内存水位增长到参数 freeze_trigger_percentage 的值就会触发转储。
当水位继续增长到租户限速阈值(租户参数 writing_throttling_trigger_percentage )会触发租户写入限速。
当水位增长到接近 100% 的时候,租户内存耗尽,业务写会大量报错(Over tenant memory limit1)。
调优参数 freeze_trigger_percentage 和转储内部并发数可以将租户的内存水位控制在一个合理的安全的范围内。
IOPS
磁盘 IO 的实时监控。
SESS:会话数,仅供参考,量大的时候可能会不准。
IOR:读 IOPS。
IOR-SZ:读 IO 吞吐量,当第一次读入数据或者数据不在内存中就会有读物理 IO。读物理 IO 如果非常高,会导致 SQL 的平均延时水平很高,说明内存不足,对 IO 依赖性变大,很可能导致 IO 触达瓶颈。
IOW:写 IOPS。
IOW-SZ:写吞吐量,平时很少有写 IO,因为 OceanBase 数据库的写都在内存里,只有转储和合并的时候能获取到短暂的密集的写 IO。
6、租户节点性能概览
使用快捷键 3 可查看租户各个节点的性能概览,主要查看租户在各个节点使用 SQL 语句的 QPS、RT 以及一些缓存命中率等。
# 取节点 CPU
MySQL [oceanbase]> SELECT t1.con_id tenant_id,t2.zone, t1.svr_ip,t1.svr_port , round(t1.value/(100*t4.max_cpu), 3) cpu_usage
-> FROM gv$sysstat t1 JOIN __all_server t2 ON (t1.svr_ip=t2.svr_ip and t1.svr_port=t2.svr_port) JOIN __all_resource_pool t3 ON (t1.con_id=t3.tenant_id) JOIN __all_unit_config t4 ON (t3.unit_config_id=t4.unit_config_id)
-> WHERE t1.con_id IN (1001) and t1.stat_id=140006
-> ORDER BY t1.con_id, t2.zone, t1.svr_ip, t1.svr_port;
+-----------+-------+--------------+----------+-----------+
| tenant_id | zone | svr_ip | svr_port | cpu_usage |
+-----------+-------+--------------+----------+-----------+
| 1001 | zone1 | 172.10.3.20 | 2882 | 0.000 |
| 1001 | zone2 | 172.10.3.21 | 2882 | 0.000 |
| 1001 | zone3 | 172.10.3.22 | 2882 | 0.002 |
+-----------+-------+--------------+----------+-----------+
3 rows in set (0.053 sec)

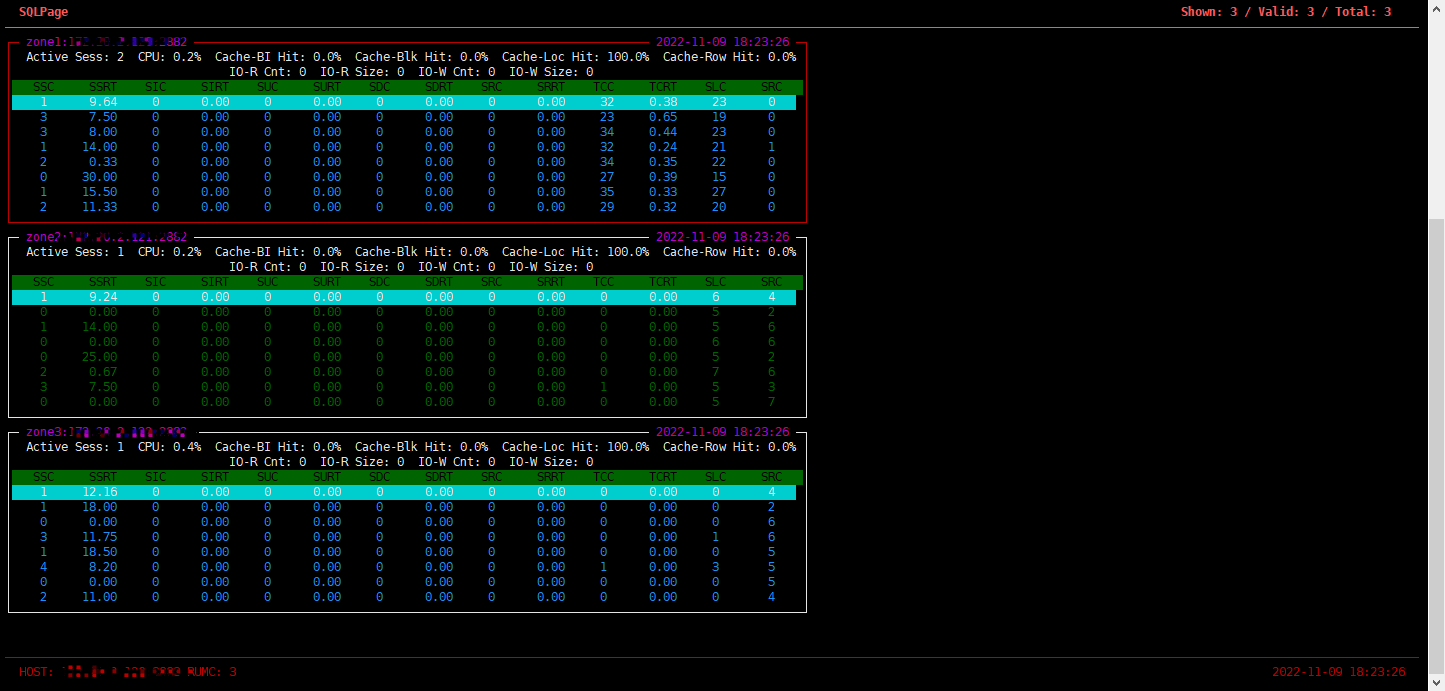
这个界面主要关注点有:
活跃会话数
仅供参考,不是严格精准。
CPU 利用率
这里显示的是 OceanBase 数据库内部统计的各个节点的 CPU 利用率,不是 OS 里看到的 CPU 利用率(OceanBase 是单进程软件)。
各个缓存的命中率
这里有 Cache Block 以及 Cache Block Index 的缓存命中率。主要关注前者(即 Cache Block),理想情况是 99% 或者 100%。当初次读入大量数据、或者内存有瓶颈、或者合并后,这个利用率会低于 99%,甚至低于 90%。如果长期低于 80%,则说明内存瓶颈问题很严重。其他行缓存命中率则不需要太过关注。
物理 IO 读写
这里是各个节点的物理 IO 信息,具有很大参考意义。
SQL 的 QPS 以及 RT 信息
各个节点的 QPS 可以看出租户请求在各个节点的流量比例关系,相应的 RT 可以看出各个节点的性能状况。
其中,最后两个 SLC 和 SRC 表示节点上的本地 SQL 和远程 SQL 执行次数信息。通常本地 SQL 的性能会比远程 SQL 性能好,所以这里需要留意远程 SQL 的比例。
如果比例很高,这个节点的 CPU 利用率、SQL 的 RT 均值都会比较高。这种情况下就需要分析原因。可能是租户 PRIMARY_ZONE 不适合打散或者表结构设计不合理,可以考虑使用表分组、调整 PRIMARY_ZONE 或 UNIT_NUM 等等。
