




SQL优化其实是一项体力活,其实最主要关注三点:表的连接方式、访问路径和执行顺序。遇到问题SQL时,我们可以先使用自己经常使用的工具,比如PL/SQL 或者 TOAD进行格式化。首先确保统计信息的准确性,然后通过awrsqlrpt或dbms_xplan获取SQL的详细执行计划和资源消耗信息,重点关注FROM后面的表以及包含WHERE语句的条件。
1.创建索引
当查看执行计划发现瓶颈是全表扫描,对应列上没有索引,就可以使用我们之前的脚本结合实际情况,如连接方式、列的选择性等创建合适的索引。
--统计JASON表中列的选择性如下:
select /*+ NO_MERGE LEADING(a b) */
b.table_name,
a.column_name,
a.num_distinct Cardinality,
b.num_rows,
ROUND(A.num_distinct * 100 / B.num_rows, 1) selectivity
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'SCOTT'
and a.table_name = 'JASON';
--查询需要创建索引的列,查询命令如下:
select owner,
column_name,
num_rows,
Cardinality,
selectivity,
'Need create index on column ' || column_name as suggest
from (select /*+ NO_MERGE LEADING(a b) */
b.owner,
b.table_name,
a.column_name,
b.num_rows,
a.num_distinct Cardinality,
ROUND(A.num_distinct * 100 / B.num_rows, 1) selectivity
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'SCOTT'
and a.table_name = 'JASON')
where selectivity >= 15
and column_name not in (select column_name
from dba_ind_columns
where table_owner = 'SCOTT'
and table_name = 'SCOTT')
and column_name in
(select c.name
from sys.col_usage$ u, sys.obj$ o, sys.user$ oo, sys.col$ c
where o.obj# = u.obj#
and oo.user# = o.owner#
and c.obj# = u.obj#
and c.intcol# = u.intcol#
and oo.name = 'SCOTT'
and o.name = 'JASON');
复制2.无法使用索引
有时候我们会遇到一条SQL,对应列有索引且应该使用索引,但就是没使用。在确保统计信息的情况下我们还需要关注是否有隐式转换。
在执行计划谓词信息部分有说明,如果有的话看能否改写SQL消除转换。
3.直方图
直方图导致的问题表现一般是SQL语句的执行效率不稳定,时好时坏。这时候我们可以针对该列收集直方图。
--查询表格中哪些列需要收集直方图,我们可以根据以下语句直接抓取:
select /*+ NO_MERGE LEADING(a b) */
a.owner,
a.table_name,
a.column_name,
b.num_rows,
a.num_distinct,
ROUND(num_distinct * 100 / num_rows, 1) selectivity,
'Column ' || a.column_name || ' need Gather Histogram' notice
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.owner = '&1'
and a.table_name = '&2'
and a.table_name = b.table_name
AND ROUND(num_distinct * 100 / num_rows, 1) < 1
and (a.owner, a.table_name, a.column_name) in
(select oo.name owner, o.name table_name, c.name column_name
from sys.col_usage$ u, sys.obj$ o, sys.user$ oo, sys.col$ c
where o.obj# = u.obj#
and oo.user# = o.owner#
and c.obj# = u.obj#
and c.intcol# = u.intcol#
and oo.name = '&1'
and o.name = '&2')
and a.histogram = 'NONE';
复制4.联合索引
虽然使用了索引,但还是很慢,这时候我们就需要关注返回的数据量以及是否产生了大量的回表操作。
创建适当的联合索引能够有效减少范围甚至能够避免回表。
5.大表清理
对于历史数据的清理,分区表较为简单,只需要truncate分区就可以了,但是对于一张普通的大表来说,清理历史数据就比较麻烦。传统会采用delete加批量提交的方式,但速度往往不太理想。我们可以利用函数DBMS_ROWID.ROWID_CREATE帮助我们按区进行rowid分片,模拟分区表的方式。
select A.FILE_ID,
A.EXTENT_ID,
A.BLOCK_ID,
'rowid between ' || '''' ||
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id,
0) || '''' || ' and ' || '''' ||
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id + blocks - 1,
999) || ''';'
from dba_extents a,dba_objects b
where a.segment_name = b.object_name
and a.owner = b.owner
and b.object_name='JASON'
and b.owner='SCOTT'
order by a.relative_fno,a.block_id;
复制输出如下:
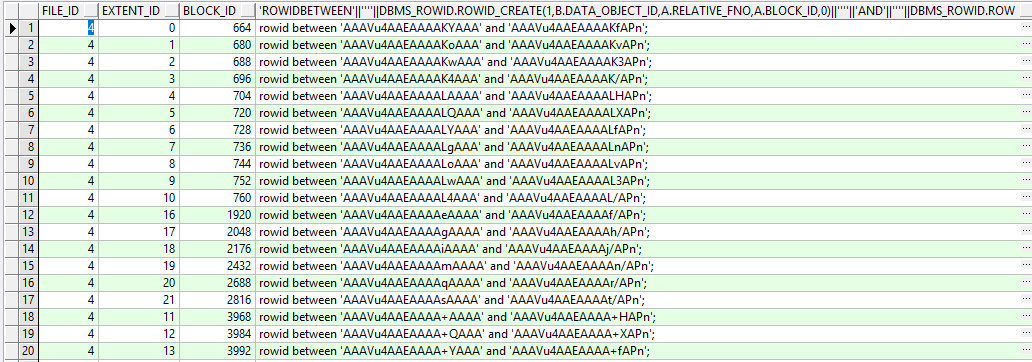
有了以上的分片信息,我们只需要带入筛选的条件,使用匿名块批量删除即可,具体实现方式如下:
declare
cursor cur_rowid is
select dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id,
0) begin_rowid,
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id + blocks - 1,
999) end_rowid
from dba_extents a,dba_objects b
where a.segment_name = b.object_name
and a.owner = b.owner
and b.object_name='JASON'
and b.owner='SCOTT'
order by a.relative_fno,a.block_id;
r_sql varchar2(4000);
begin
FOR cur in cur_rowid LOOP
r_sql := 'delete SCOTT.JASON where object_type=' || '''' || 'INDEX' || '''' || ' and rowid between :1 and :2';
EXECUTE IMMEDIATE r_sql
using cur.begin_rowid,cur.end_rowid;
COMMIT;
END LOOP;
end;
/
复制注:本文参考于:《DBA攻坚指南》
最后修改时间:2022-11-08 10:22:17
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
文章被以下合辑收录
评论
duke


2年前
评论
 0
0
2年前
点赞 评论
virvle
2年前
评论
02年前
点赞 评论
相关阅读
【纯干货】Oracle 19C RU 19.27 发布,如何快速升级和安装?
Lucifer三思而后行
817次阅读
2025-04-18 14:18:38
Oracle数据库一键巡检并生成HTML结果,免费脚本速来下载!
陈举超
610次阅读
2025-04-20 10:07:02
【ORACLE】你以为的真的是你以为的么?--ORA-38104: Columns referenced in the ON Clause cannot be updated
DarkAthena
553次阅读
2025-04-22 00:13:51
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
543次阅读
2025-04-17 17:02:24
【ORACLE】记录一些ORACLE的merge into语句的BUG
DarkAthena
513次阅读
2025-04-22 00:20:37
一页概览:Oracle GoldenGate
甲骨文云技术
509次阅读
2025-04-30 12:17:56
火焰图--分析复杂SQL执行计划的利器
听见风的声音
478次阅读
2025-04-17 09:30:30
OR+DBLINK的关联SQL优化思路
布衣
388次阅读
2025-05-05 19:28:36
Oracle数据库Hint大全,31个使用案例,速来下载!
陈举超
372次阅读
2025-04-16 21:25:19
Oracle19C低版本一天遭遇两BUG(ORA-04031/ORA-00600)
潇湘秦
342次阅读
2025-04-16 17:05:16




