| 作者 | 时间 | QQ技术交流群 |
|---|---|---|
| perrynzhou@gmail.com | 2022/10/01 | 672152841 |

计算机
内数据访问的时间

从
CPU L1->CPU L2->DRAM->SSD->HDD->Network Storage->Tape Archives
不同层次的访问,访问的时间差距很大。上图的左边是每个层次的硬件访问数据的时间周期,上图的右边是不同硬件访问时间的放大,越上层访问越短,越下层访问时间越长;但是从容量上看越上层的容量越小,越下层的容量越大。
PG
磁盘数据到内存概览
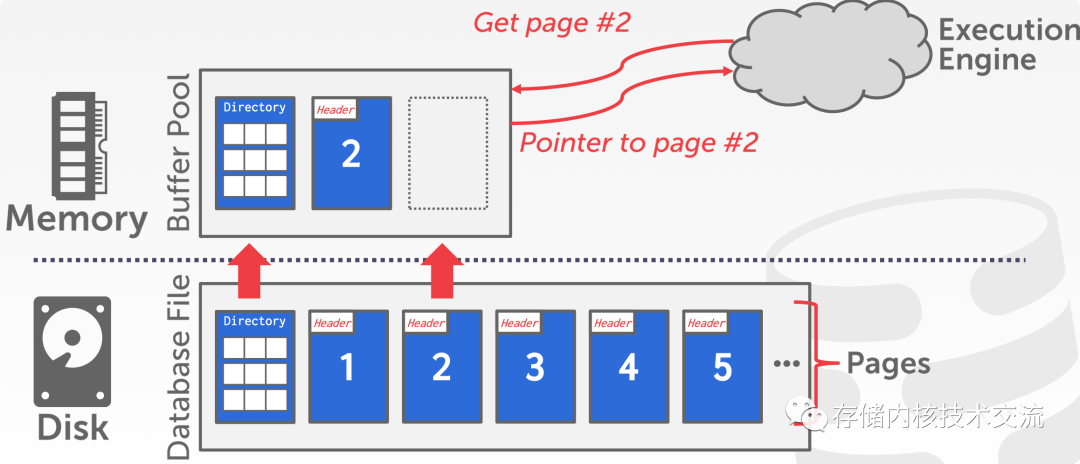
任何传统传统数据库都会借助
DRAM
来加速数据库磁盘数据的访问。比如PG
中的share_buffer
,全局为PG
数据库中表存储的数据page
提供缓冲空间。当用户执行查询语句的时候,首先会去查询share_buffer
中这个数据page
是否在缓存区中,如果在就返回page
;如果不在则去磁盘读取这个数据的page
到share_buffer
最后返回。这里涉及到两个基本的结构,一个是
share_buffer
,另外一个是page
.下面核心会聚焦到这2个点上,了解PG
是如何实现这些逻辑
PG
中的数据对象
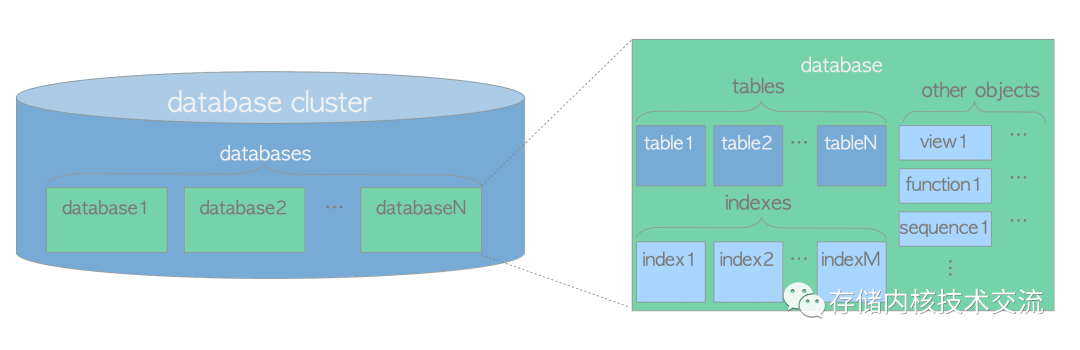
PG
中一般会有三种对象,分别是数据库
、表
、索引
.三者之间的关系如下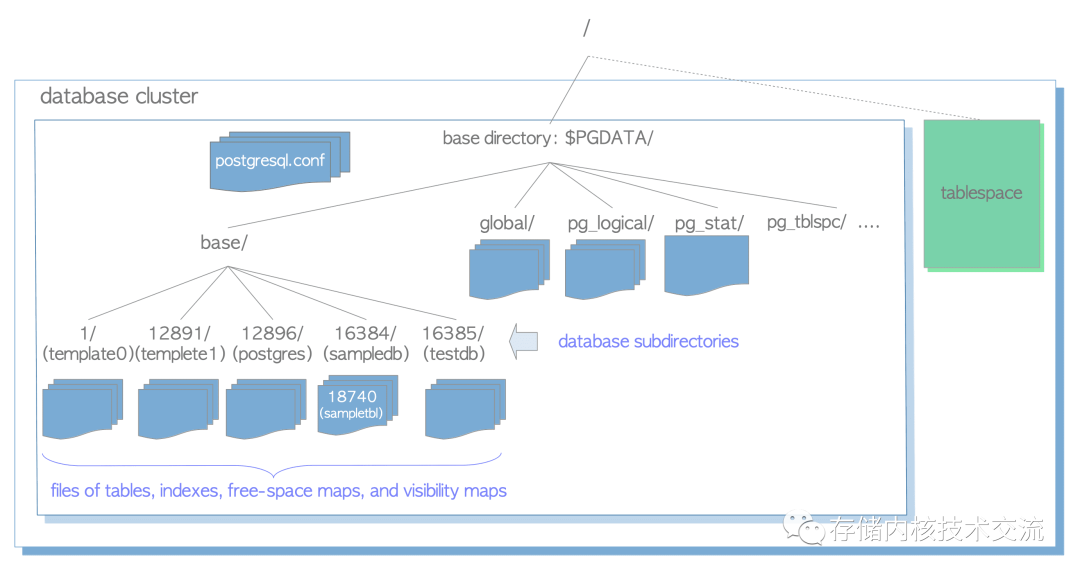
PG
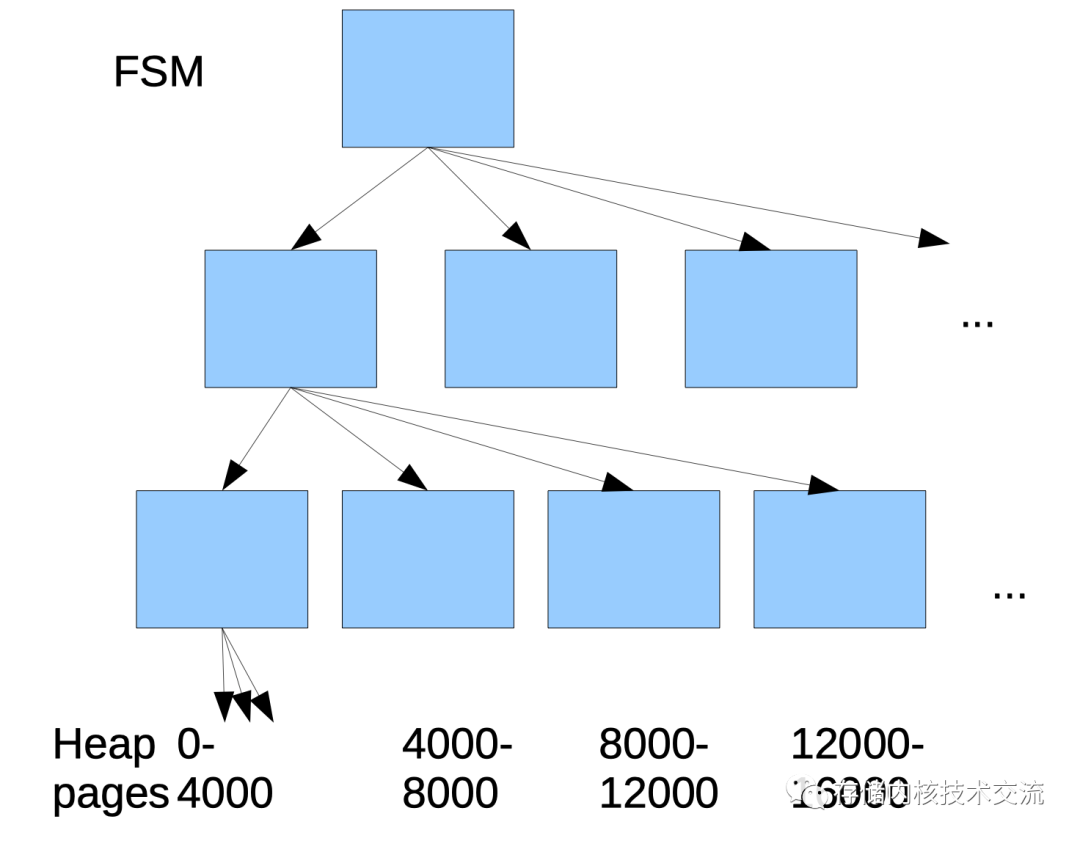
中一个表一般会有三种类型的数据,一个是fsm
文件表示当前数据表中可用的空闲空间,另外一个是vm
文件来表示数据表中数据可见性的映射,最后一个是以oid
来表示的数据文件.fsm
是基于page来管理空闲空间,其采用binary-tree
的方式进行管理。vm
中的可见性也是基于page
来管理。
// 创建测试表
perryn_demo=> create table email(id int,name varchar(255));
CREATE TABLE
// 查询的表的OID
perryn_demo=> select oid,relfilenode from pg_class where relname='email';
oid | relfilenode
-------+-------------
16386 | 16386
(1 row)
// 插入数据
perryn_demo=> insert into email SELECT generate_series(1,200000),repeat(chr(int4(random()*26)+65),200);
INSERT 0 190001

PG
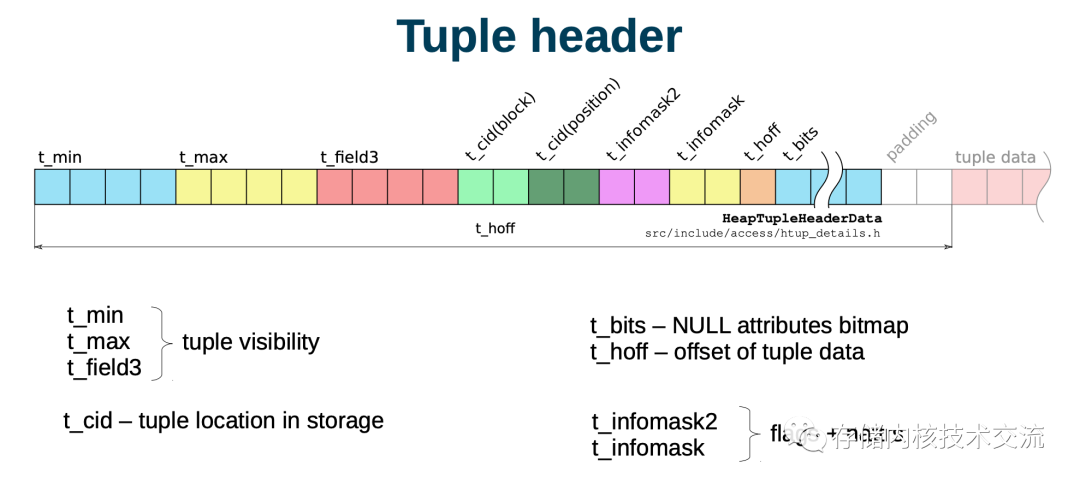
中的Page
PG
中的Page
中都有一个PageHeader
,其次是多个数据指针。数据的Page
是从尾部Special
开始写。每个Tuple
也包含了Tuple Header
和Tuple Data
.
Page
在PG
使用了PageHeaderData
来表示每个Page
的头。这里存储了每个Page
的meta信息,PageHeaderData->pd_linp
是一个数组质指向Page
内的Tuple