




接着之前的文章《浅谈基于JDBC实现虚拟专用数据库(VPD)》的内容,今天我们重点来说一下SQL解析的问题。
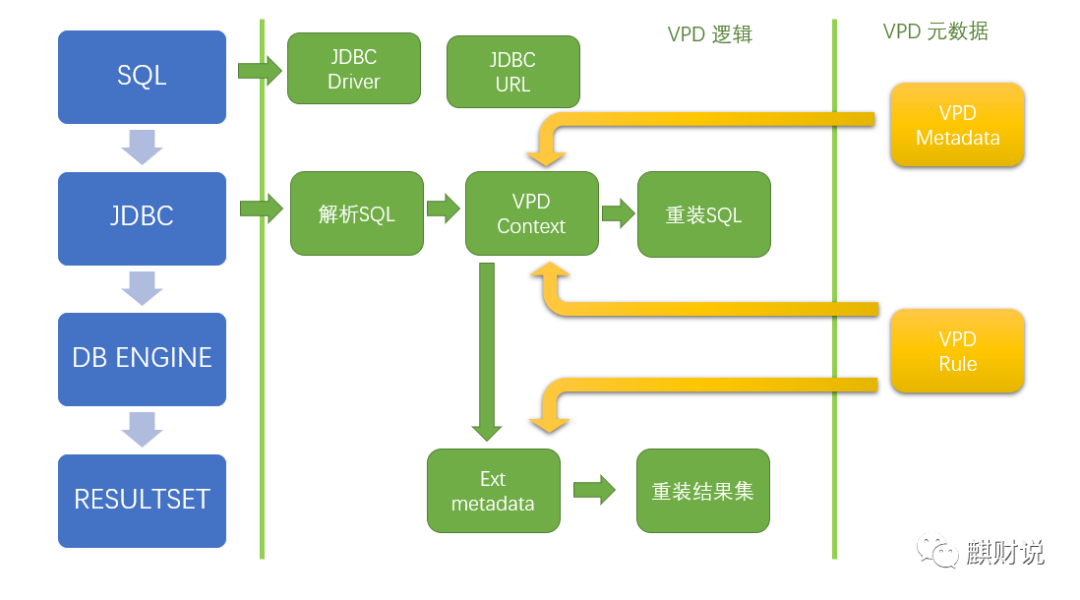
从架构上我们可以看出来,如果要基于JDBC做VPD,不能绕开的一个问题,就是要解析SQL,那么如何解析SQL呢?其实可供选择的方案还是很多的,比如JSqlParser、Saprk的Catalyst,亦或是直接使用Antlr,不过这里我还是更推荐使用Apache的Calcite。
首先,我们需要构建一个解析器,这里为了方便,使用Mysql语法
SqlParser.Config config = SqlParser.configBuilder()
.setLex(Lex.MYSQL) //使用mysql 语法
.build();
String sql = "select id,name,age FROM orders";
SqlParser sqlParser = SqlParser
.create(sql, config);复制
然后,构建一颗AST树
SqlNode sqlNode = sqlParser.parseStmt();复制
接下来,就需要各种分支判断,来对这个语法树进行遍历,举个简单的例子,我们将标示,以及select项打印出来。
if(SqlKind.SELECT.equals(sqlNode.getKind())){
SqlSelect sqlSelect = (SqlSelect) sqlNode;
SqlNode from=sqlSelect.getFrom();
SqlNode where=sqlSelect.getWhere();
SqlNodeList selectList=sqlSelect.getSelectList();
if(SqlKind.IDENTIFIER.equals(from.getKind())){
System.out.println(from.toString());
}
selectList.getList().forEach(x->{
System.out.println("==> "+x);
});
}复制
所有的SQL语法都会被转换,我们的demo使用select语句,类似的,还有SqlInsert,SqlUpdate,SqlJoin等,解析Sql是一个非常细致的工作,有兴趣的同学也可以读一下Antlr的Sql语法文件,也很有意思。
解析Sql只是整个VPD中的一环,我们还需要进行Sql的构建。举个简单,我们来构建一个简单的sql查询
SqlParserPos sqlParserPos = new SqlParserPos(1, 1);
SqlIdentifier all = new SqlIdentifier("*", null, sqlParserPos);
SqlIdentifier o = new SqlIdentifier("o", null, sqlParserPos);
SqlNodeList snl = new SqlNodeList(sqlParserPos);
snl.add(all);
SqlSelect sqls = new SqlSelect(sqlParserPos,null,snl,o,null,null,null,null,null,null,null);
System.out.println(sqls);复制
完整代码如下:
package cn.flinkhub.bigdata;
import org.apache.calcite.config.Lex;
import org.apache.calcite.sql.*;
import org.apache.calcite.sql.parser.SqlParseException;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.sql.parser.SqlParserPos;
public class VPDDemo {
public static void main(String[] args) {
SqlParser.Config config = SqlParser.configBuilder()
.setLex(Lex.MYSQL) //使用mysql 语法
.build();
String sql = "select id,name,age FROM orders";
SqlParser sqlParser = SqlParser
.create(sql, config);
SqlNode sqlNode = null;
try {
System.out.println("sql = "+ sql);
sqlNode = sqlParser.parseStmt();
if(SqlKind.SELECT.equals(sqlNode.getKind())){
SqlSelect sqlSelect = (SqlSelect) sqlNode;
SqlNode from=sqlSelect.getFrom();
SqlNode where=sqlSelect.getWhere();
SqlNodeList selectList=sqlSelect.getSelectList();
if(SqlKind.IDENTIFIER.equals(from.getKind())){
System.out.println(from.toString());
}
selectList.getList().forEach(x->{
System.out.println("==> "+x);
});
}
} catch (SqlParseException e) {
throw new RuntimeException("", e);
}
SqlParserPos sqlParserPos = new SqlParserPos(1, 1);
SqlIdentifier all = new SqlIdentifier("*", null, sqlParserPos);
SqlIdentifier o = new SqlIdentifier("o", null, sqlParserPos);
SqlNodeList snl = new SqlNodeList(sqlParserPos);
snl.add(all);
SqlSelect sqls = new SqlSelect(sqlParserPos,null,snl,o,null,null,null,null,null,null,null);
System.out.println(sqls);
}
}复制
好了,今天就写到这了,希望对大家能有所启发,如果你对Calcite有兴趣,可以与我讨论,接下来,也许会进一步说说构建Sql的事...
作为延伸阅读,推荐大家读读王蒙大神的BLOG。非常有帮助,我以前也转过他的文章
文章转载自麒思妙想,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
