




一、缘起
写了一个讲义,发现内容太多了,于是把这部分内容从讲义中移出,发到这里。本文所有代码都经过运行验证。
二、环境
Win 10 中文专业版64位 + Python 3.65 64位 + 8G RAM
三、正文
(一) struct标准库介绍
pack("格式串", 一到多个其它类型的表达式)
unpack("格式串", 字节串类型的对象)
格式串中至少包含一个格式符,格式符前面还有一个可选的字节顺序标识符。
部分格式符如表1所示。
表1 struct标准库的pack和unpack方法的格式符
格式符 | 参数类型 | 在字节串中所占字节数 |
x | 无效类型,转换字节串时对应的一个字节无效 | 1 |
? | 布尔类型 | 1 |
b、B | 字符、无符号字符;值小的整数 | 1 |
h、H | 短整数、无符号短整数 | 2 |
i、I | 整数、无符号整数 | 4 |
l、L | 长整数、无符号长整数 | 4 |
f | float类型的浮点数 | 4 |
d | Double类型的浮点数 | 8 |
s | 字符串,它的每个字符占1字节 | 1 |
这里的字节序可以用字节序标识符来规定,常用的字节序标识符有>和<这两个:
>表示自然顺序,高位在前低位在后;
<表示逆序,字节顺序跟自然顺序完全相反。
下面分别举例介绍struct标准库的pack和unpack这两个方法的使用。
(二)用struct.pack将其它数据类型转为字节串
1 布尔值转为字节串
>>> from struct import pack
>>> pack("?", False)
b'\x00'
>>> pack("?", True)
b'\x01'
2 整数转为字节串
>>> from struct import pack
>>> pack("b", 25)
b'\x19'
>>> pack("h", 258)
b'\x02\x01'
>>> pack("i", 258)
b'\x02\x01\x00\x00'
>>> pack(">i",258)
b'\x00\x00\x01\x02'
>>> from struct import pack
>>> pack("b", 258)
Traceback (most recent call last):
File"<pyshell#77>", line 1, in <module>
pack("b", 258)
struct.error: byte format requires -128 <= number<= 127
>>> from struct import pack
>>> pack(">bhi", 1, 2, 3)
b'\x01\x00\x02\x00\x00\x00\x03'
>>> from struct import pack
>>> pack(">hhh", 1, 2, 3)
b'\x00\x01\x00\x02\x00\x03'
>>> pack(">3h", 1, 2, 3)
b'\x00\x01\x00\x02\x00\x03'
3 浮点数转为字节串
>>> from struct import pack
>>> pack("f", 3.14159)
b'\xd0\x0fI@'
>>> pack("f", -3.14159)
b'\xd0\x0fI\xc0'
>>> pack(">f", 3.14159)
b'@I\x0f\xd0'
4 字符串转为字节串
>>> name = "胡凤国"
>>> name.encode("gb18030")
b'\xba\xfa\xb7\xef\xb9\xfa'
>>> from struct import pack
>>> name = "胡凤国"
>>> pack("10s",name.encode("gb18030"))
b'\xba\xfa\xb7\xef\xb9\xfa\x00\x00\x00\x00'
>>> from struct import pack
>>> name, age = "张三", 23
>>> r = pack(">10si",name.encode("gb18030"), age)
>>> r
b'\xd5\xc5\xc8\xfd\x00\x00\x00\x00\x00\x00\x00\x00\x00\x17'
(三) 用struct.unpack将字节串转为其它数据类型
1 字节串转为布尔值
>>> from struct import unpack
>>> unpack("?", b'\x00')
(False,)
>>> unpack("?", b'\x01')
(True,)
>>> unpack("??", b'\x01\x05')
(True, True)
2 字节串转为整数
>>> from struct import unpack
>>> b = b'\xba\xfa'
>>> unpack("bb", b) # 转换成两个单字节整数
(-70, -6)
>>> unpack("BB", b) # 转换成两个单字节无符号整数
(186, 250)
>>> unpack("h", b) # 以默认字节序转换成一个双字节整数
(-1350,)
>>> unpack("H", b) # 以默认字节序转换成一个双字节无符号整数
(64186,)
>>> unpack(">h", b) # 以自然顺序转换成一个双字节整数
(-17670,)
3 字节串转为浮点数
>>> from struct import pack, unpack
>>> a = 3.14
>>> b = pack("f", a)
>>> b
b'\xc3\xf5H@'
>>> c = unpack("f", b)
>>> c
(3.140000104904175,)
4 字节串转为字符串
>>> name = "胡凤国"
>>> bname =name.encode("gb18030")
>>> bname
b'\xba\xfa\xb7\xef\xb9\xfa'
>>> bname.decode("gb18030")
'胡凤国'
>>> from struct import unpack
>>> b = b'\xd5\xc5\xc8\xfd\x00\x00\x00\x00\x00\x00\x00\x00\x00\x17'
>>> bname, age =unpack(">4s6xi", b)
>>> bname
b'\xd5\xc5\xc8\xfd'
>>> age
23
>>> bname.decode("gb18030")
'张三'
Ø >表示其中的格式符i按自然顺序去解读对应的4个字节;
Ø 4s表示前4个字节是一个数据;
Ø 6x表示接下来的6个字节放弃,不予解读;
Ø i表示接下来的4个字节解读成整数。
(四)用struct标准库读写二进制文件示例
a = [(李逍遥,19), (赵灵儿,16), (林月如,18), (阿奴,14)]
【例1】 用struct标准库将数据写入二进制文件示例

这个二进制文件中每7个字节表示一个人的信息,这7个字节的前6个字节表示姓名,需要用gb18030来解码,最后一个字节表示年龄。
【例2】 用struct标准库从二进制文件读取数据示例

(五) 用其它标准库读写二进制文件
1 用pickle标准库读写二进制文件
【例3】 用pickle标准库将数据写入二进制文件示例

【例4】 用pickle标准库从二进制文件读取数据示例

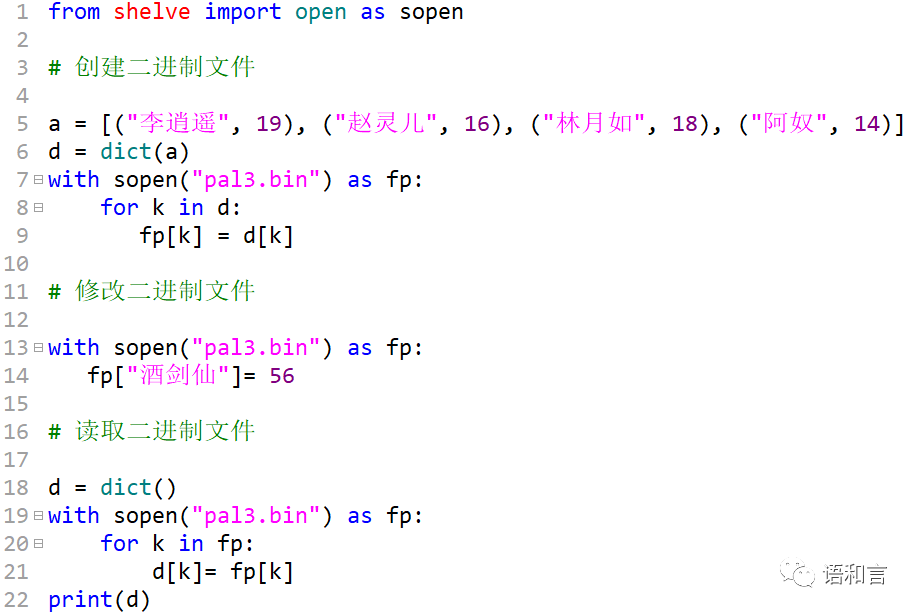
3 用shelve标准库读写二进制文件
【例5】 用shelve标准库读写二进制文件
四、后记

