




一、任务
目录下有若干个Word文件,包含*.doc和*.docx这两种文件。现要求写一个Python程序读取所有Word文件的文本内容。
二、环境
Win7中文旗舰版64位 + Python 3.64 64位 + Office2010 64位
三、安装
pywin32是一个非常强大的Python扩展库,是Python调用Windows系统底层功能的最佳接口,也是爬虫框架scrapy所依赖的重要扩展库之一。
据说在Python 3.5之前的3.x版本中,安装pywin32非常容易,只需要在保证联网的情况下执行pip install pywin32即可,或者在网站
http://www.lfd.uci.edu/~gohlke/pythonlibs/#pywin32
下载对应版本的whl文件然后本地离线安装即可。
然而,在Python 3.6.x中,按照上面的步骤安装时,有时候即使提示安装成功也总是无法正确使用。
如果遇到这样的情况,在命令行窗口中将当前目录切换至python3.6.x的安装目录的scripts目录,执行命令
python pywin32_postinstall.py -install
即可。
如果还不成功的话,那估计就是人品问题,卸载Python,再重新安装吧。我就是重新安装Python才把pywin32安装成功的。
四、代码
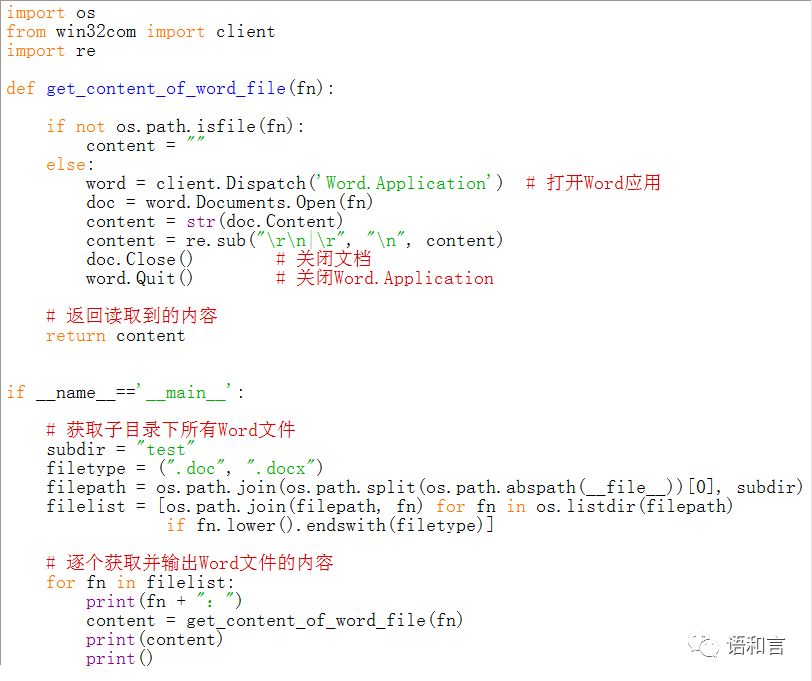
五、注意
之前是32位的系统,安装32位的Python和32位的Office2010,上述代码运行无误。
后来升级了内存,换了64位的Win7,顺便换了64位的Python,但是Office2010还是32位的,运行这段代码的时候,结果杯具了。每次运行到
content = str(doc.Content)
这句话的时候就报错。
后来换了64位的Office2010,马上就好了。但是又带来一个问题:读取到content里面之后,原来Word里面的换行符统统变成了'\r',那我们用print()函数输出的时候,就丢了换行符了。所以,代码里面要加上一个语句:
content = re.sub("\r\n|\r", "\n", content)
这个语句用正则表达式替换功能将'\r\n'和'\r'替换为换成'\n'。
六、测试
某一次的测试结果如下:
D:\test\test.doc:
12345
金木水火土
天地分上下
日月明今古
D:\test\test.docx:
一二三四五
金木水火土
天地分上下
日月明今古
如果不加正则替换那一句,在IDLE中的输出结果看起来就变成了如下的样子('\r'还在字符串中,但起不到换行的作用):
D:\test\test.doc:
12345金木水火土天地分上下日月明今古
D:\test\test.docx:
一二三四五金木水火土天地分上下日月明今古
