




- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
- GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。
- 作者:Q
MySQL 提供了许多聚合函数,常见的如sum,avg,count,min,max等。
那这些聚合函数在MySQL 底层是怎么实现的?
聚合函数(Aggregate Function)实现的大部分代码在item_sum.h和item_sum.cc。
聚合函数在代码中具体的枚举如下:
enum Sumfunctype { COUNT_FUNC, // COUNT COUNT_DISTINCT_FUNC, // COUNT (DISTINCT) SUM_FUNC, // SUM SUM_DISTINCT_FUNC, // SUM (DISTINCT) AVG_FUNC, // AVG AVG_DISTINCT_FUNC, // AVG (DISTINCT) MIN_FUNC, // MIN MAX_FUNC, // MAX STD_FUNC, // STD/STDDEV/STDDEV_POP VARIANCE_FUNC, // VARIANCE/VAR_POP and VAR_SAMP SUM_BIT_FUNC, // BIT_AND, BIT_OR and BIT_XOR UDF_SUM_FUNC, // user defined functions GROUP_CONCAT_FUNC, // GROUP_CONCAT JSON_AGG_FUNC, // JSON_ARRAYAGG and JSON_OBJECTAGG ROW_NUMBER_FUNC, // Window functions RANK_FUNC, DENSE_RANK_FUNC, CUME_DIST_FUNC, PERCENT_RANK_FUNC, NTILE_FUNC, LEAD_LAG_FUNC, FIRST_LAST_VALUE_FUNC, NTH_VALUE_FUNC, ROLLUP_SUM_SWITCHER_FUNC, GEOMETRY_AGGREGATE_FUNC };复制
本文以下列示例来讲解:
CREATE TABLE test_agg (c1 int NULL) INSERT into test_agg values(1),(2),(3),(3),(4),(4),(5),(5),(5); SELECT count(DISTINCT c1) from test_agg;复制
聚合函数的类设计大概如下
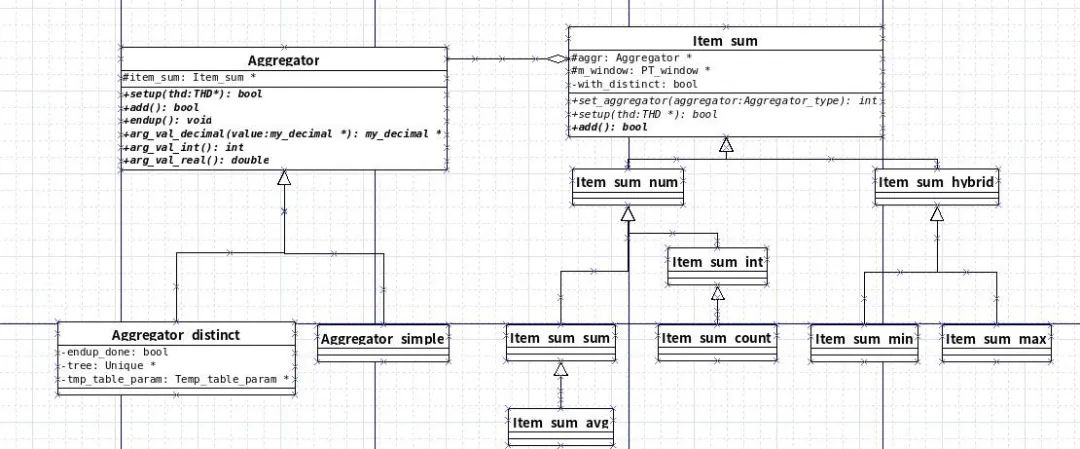
由上图可以发现MySQL 聚合函数实现是把distinct逻辑抽离出来,变成了aggregator_distinct和aggregator_simple,
服务于继承了Item_sum的所有聚合类。(当然Item_sum本身是继承于Item)
class Aggregator_simple : public Aggregator { public: Aggregator_simple(Item_sum *sum) : Aggregator(sum) {} Aggregator_type Aggrtype() override { return Aggregator::SIMPLE_AGGREGATOR; } bool setup(THD *thd) override { return item_sum->setup(thd); } void clear() override { item_sum->clear(); } bool add() override { return item_sum->add(); } void endup() override {} }; class Aggregator_distinct : public Aggregator { public: ~Aggregator_distinct() override; Aggregator_type Aggrtype() override { return DISTINCT_AGGREGATOR; } bool setup(THD *) override; void clear() override; bool add() override; void endup() override; };复制
上面是2个类的部分代码,由此我们发现 Aggregator_simple 基本只是个调用wrap,表示非distinct的Item_sum处理,
直接调用的是聚合类的逻辑。
在 MySQL 中要实现聚合函数要有3个重要的步骤:setup, add, endup。
- setup 在处理之前初始化
- add 表示每条记录的处理
- endup 收尾后最后计算聚合的结果。
回到代码
setup 阶段
(Aggregator_distinct::setup 截取部分代码)
if (!(table = create_tmp_table(thd, tmp_table_param, list, nullptr, true, false, query_block->active_options(), HA_POS_ERROR, ""))) if (all_binary) { cmp_arg = (void *)&tree_key_length; compare_key = simple_raw_key_cmp; } else { if (table->s->fields == 1) { compare_key = simple_str_key_cmp; cmp_arg = (void *)table->field[0]; } else { uint32 *length; compare_key = composite_key_cmp; .... } } tree = new (thd->mem_root) Unique(compare_key, cmp_arg, tree_key_length, item_sum->ram_limitation(thd)); if (!tree) return true;复制
由上知 setup 阶段主要做的是创建临时表和 tree ,设置比较函数。
add 阶段
(Aggregator_distinct::add 截取部分代码)
if (tree) { return tree->unique_add(table->record[0] + table->s->null_bytes); } if (!check_unique_constraint(table)) return false; if ((error = table->file->ha_write_row(table->record[0])) && !table->file->is_ignorable_error(error))复制
这边看到当 tree 存在时,MySQL 把记录加入 tree (实际为红黑树)中来去重复。
如果tree不存在,就用临时表来持久存储。在 ha_write_row 写入临时表之前会 check_unique_constraint 去重。
而 tree 和临时表就是 setup 阶段所创建的。setup 的 tree 是存在,什么时候销毁了呢。看下面:
inline bool unique_add(void *ptr) { DBUG_TRACE; DBUG_PRINT("info", ("tree %u - %lu", tree.elements_in_tree, max_elements)); if (tree.elements_in_tree > max_elements && flush()) return true; return !tree_insert(&tree, ptr, 0, tree.custom_arg); } bool Unique::flush() { Merge_chunk file_ptr; elements += tree.elements_in_tree; file_ptr.set_rowcount(tree.elements_in_tree); file_ptr.set_file_position(my_b_tell(&file)); if (tree_walk(&tree, unique_write_to_file, this, left_root_right) || file_ptrs.push_back(file_ptr)) return true; /* purecov: inspected */ delete_tree(&tree); return false; }复制
可以看到MySQL 的策略是维护一颗红黑树这样的数据结构来去重。
当tree的数量过大时,内存放不下,就会flush到磁盘上,采用临时表来持久化,同时销毁tree。
endup 阶段
if (tree && tree->is_in_memory()) { sum->count = (longlong)tree->elements_in_tree(); endup_done = true; } if (!tree) { table->file->info(HA_STATUS_VARIABLE | HA_STATUS_NO_LOCK); if (table->file->ha_table_flags() & HA_STATS_RECORDS_IS_EXACT) sum->count = table->file->stats.records; else { if (table->file->inited) table->file->ha_index_or_rnd_end(); ha_rows num_rows = 0; table->file->ha_records(&num_rows); if (table->hash_field) table->file->ha_index_init(0, false); sum->count = static_cast<longlong>(num_rows); } endup_done = true; }复制
可以看到最后取结果的时候
如果 tree 存在而且在内存中,直接取 tree 的节点个数。
如果 tree 不存在就取临时表的行数。
GreatSQL社区:
捉虫活动详情:https://greatsql.cn/thread-97-1-1.html
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html





