




Antdeck是平安好医生DBA团队开发的一套自动化任务调度和数据库数据统一归档的平台,用于解决数据库管理任务统一调度管理和大表数据归档问题。可以说目前的Antdeck系统就是一个基于任务调度模块的数据库归档系统。目前已接入了平安好医生所有数据库管理任务的自动化调度,以及新的业务数据库归档需求。
Antdeck的底层核心模块为我们使用Python3自己开发的任务调度模块,曾经调研和测试过Python的Celery任务调度模块,也使用Celery搭建过一个分布式秒级监控任务的模型,不得不说Celery是一个非常棒的分布式任务调度方案,配合MQ或者Redis可以达到很高的性能。但是对于我们日常服务器的任务调度来说,不需要太高的任务调度性能,每天几千次几万次调度已经可以满足我们的需要,我们更加注重调度任务的整体功能是否满足我们的需求,比如任务状态和执行百分比的实时监控、任务队列和异常任务的监控告警、可视化的数据分析、如何将任务调度和目前我们的元数据中心打通等等。面对如此多样化的需求,所以我们考虑自己写一个定制化并且轻量级的任务调度模块,用于统一管理目前数据库的所有定时调度任务。同时把调度模块设计定位为底层任务执行模块,可以自由的开发和接入上层应用模块,比如数据库归档,分区管理,备份,自动化任务等等。
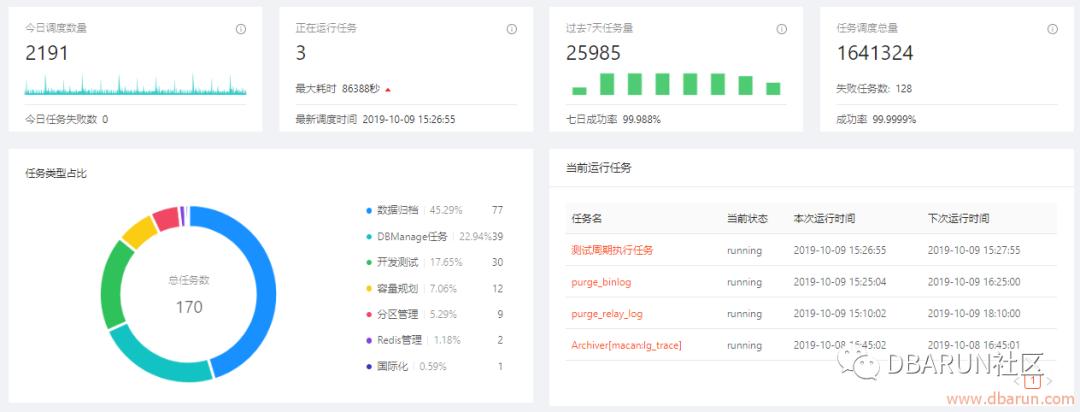
系统Dashboard如下所示,大盘的第一个作用是展示今日和7天维度监控任务的调度信息和成功率,用于判断整体平台的监控状况,第二个作用是监控当前正在运行的任务状态用于监控长时间执行的任务是否异常,第三个作用是展示24H时间范围内分钟和小时维度的任务分布统计数据,为后续任务配置提供决策支持。
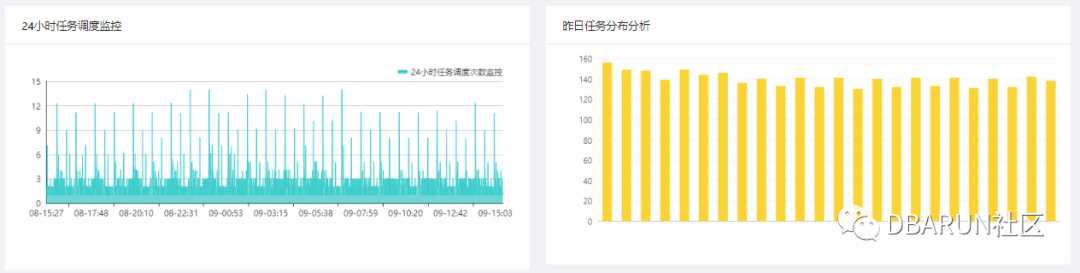
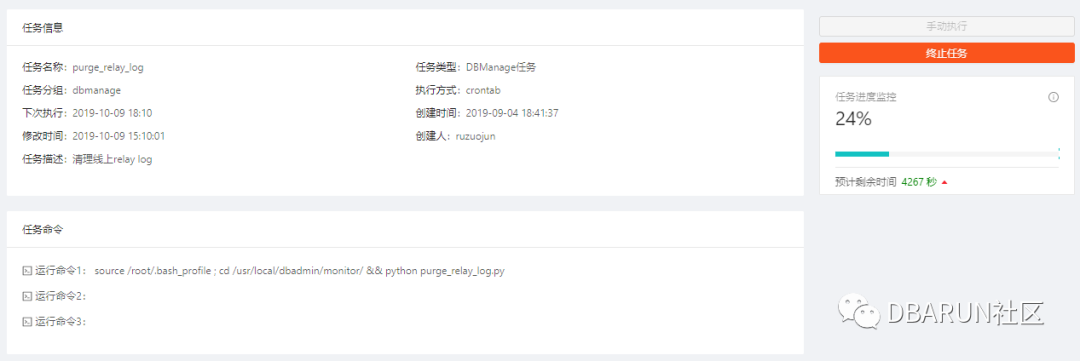
每个调度任务执行状态详细监控,通过对历史数据的分析和websocket通道实时展示当然任务执行状态和剩余时间。
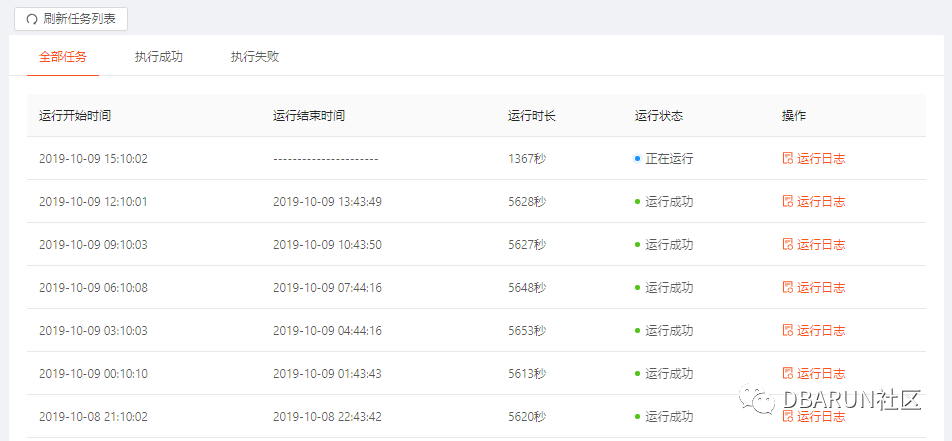
数据库归档任务配置方式如下,基于我们的元数据信息,可以直接选择需要归档的数据库和数据表,选择对应的目标tidb集群,配置好相关性能参数和调度方式,即可实现自动化归档,代替了之前传统脚本化和存储过程的归档方式。

任务调度模块架构介绍
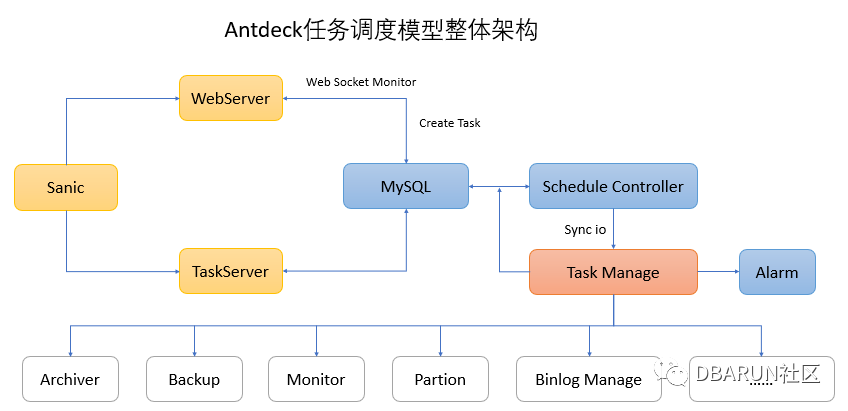
Antdeck的整体技术方案选型中,后端使用Python3+sanic框架实现,Python3的优势是可以支持异步IO,可以更好的完成异步任务。Sanic是一个由python3开发的高性能的异步IO框架,开发的模型参考了flask,使用起来非常的轻量级,但是因为支持异步IO,比起flask有着更好的性能。前端的设计开发是基于recat设计思路,使用了蚂蚁金服ant.design的一整套前端解决方案。整体架构图如下所示:
Sanic默认是运行1个WebServer,在此基本上,我们使用Sanic创建了另一个TaskServer。WebServer用于接收上层用户的信息,创建调度任务后将任务存储在MySQL中。同时TaskServer实时监控MySQL任务队列,并在Schedule Controller中解析任务(手动执行、定时执行、周期执行),在到达对应执行时间点后将任务分发到Task Manage。Task Manage在接收到任务后放入内存缓存队列中,并为每个任务Fork出对应的任务子进程进行执行,对超过设置的timeout时间或者执行异常的任务发送短信告警。另外WebServer也会通过web socket方式连接实时监控后端任务的运行状态和执行百分比。
多种调度类型:支持配置手工任务、定时任务、秒级周期任务三种任务类型,并支持随时手动触发任务及手动终止正在运行的任务。 定时任务格式兼容:定时任务兼容Linux的crontab任务类型,可以简单的将Linux的计划任务格式copy到antdeck里面。 任务运行实时监控:在任务运行时通过websocket技术和历史任务数据计算实时监控任务的执行状态和执行进度百分比。 告警支持:支持任务在运行失败、运行超时、任务队列异常时发送短信报警。 历史跟踪:可以跟踪每个任务的历史执行状况,以及运行日志。 支持多任务执行:每个任务项可以支持最多三个任务的顺序调度运行,在第一个程序运行成功后才会进行后续任务。 Dashboard大盘:通过今日任务、本周任务、24H调度监控、历史任务分布等不同维度监控和分析任务运行状态
数据库归档模块架构
数据归档模块可以理解为基于调度模块上层的应用层,当我们通过WEB界面配置归档后,会最终转换成标准的调度任务进行执行,在到达执行时间点后,归档任务会调用我们使用Python封装好的mysql_archiver归档程序,mysql_archiver会首先做相应的参数检测,检测通过后通过归档的参数读取DBINFO 元数据,远创检测tidb是否存在归档库和表,如果不存在会自动创建,然后调用pt-archiver进行数据归档,将数据归档到tidb集群。数据归档的流程如下:
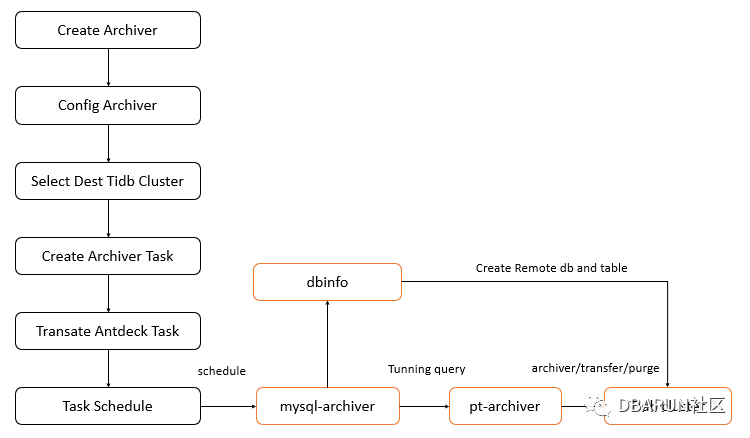
那么为什么任务调度模块不直接调度pt-archiver进行数据归档,而是通过封装mysql_archiver再进行调用呢,是不是觉得很多余呀,答案肯定是不,毕竟任何事物存在就有价值,我也不是时间多的需要靠多写代码来实现项目的价值。我们知道pt-archiver归档要必须在目标端建立对应的数据表,所以我们通过mysql-archiver的封装来实现tidb的自动建库和建表,简化人工操作。另一个优化点是如果归档条件是非id是字段时,我们会自动增加归档的max id防止全表扫描,因为我们在时间字段配置按天归档时,配置到一个case就是由于归档的数据量满足不了设置的bulk size,导致全表扫描。这个case中pt-archiver第一次查询用了半小时,扫描了三亿多行数据。
这个情况发生在老的存储过程归档到新归档平台迁移测试的过程中,在凌晨的时候,老的存储过程已经按create_time < DATE_FORMAT(DATE_SUB(NOW(), INTERVAL 70 DAY),’%Y-%m-%d’)的条件进行了数据归档,也就是说70天之前的数据已经被归档,数据量为0,然后当天使用了新的归档平台进行测试,配置了相关的归档条件create_time < DATE_FORMAT(DATE_SUB(NOW(), INTERVAL 70 DAY),’%Y-%m-%d’)。所以上面pt-archiver归档其实归档不到任何数据。
那么归档不到数据,上面那个SQL为什么会慢呢,原因是pt-archiver的设计思路是分批次查询归档,在查询语句中加入了FORCE INDEX(`PRIMARY`)强制使用主键进行查询,同时使用了ORDER BY `id` LIMIT 6000用于保证查询的id是顺序的,在每批次查询时会记录当前归档数据的max id,并在下一批次查询过程中将max id加入到查询条件中( and id>max id),用于提高查询性能 。由于强制使用主键,所以不会使用create_time时间索引,而是直接使用id排序后再通过limit 6000取出6000条数据,同时记录max id。正常情况下,如果查询能通过id直接查询拿到6000条数据的时候,性能是比较高的。但是如果归档条件包含非id字段,同时根据id顺序查询的数据无法满足非id字段时,查询就会持续向后扫描,持续寻找满足条件的数据,直到找到满足条件的6000条数据为止,可想而知,上面的SQL查到数据的最后一条也满足不了条件,所以就变更了全表扫描,对于上亿的数据,全表扫描必将是非常慢的。
那么这个问题是如何解决的呢,我们在mysql-archiver里面对非ID字段加入了一层逻辑,在归档前连接到数据库检索出max ID并带入到归档参数中,用于防止全表扫描。这样就解决了非ID字段在极端情况下全表扫描调度问题。主要逻辑示例代码如下:
query_max_id_sql = "select max(id) from %s.%s where %s" %(source_db,source_table,arch_where)
my_conn=MySQLdb.connect(host=source_host,user='xxxxxx',passwd='xxxxxx',port=int(source_port),connect_timeout=3,charset='utf8')
my_cur=my_conn.cursor()
my_conn.select_db(source_db)
my_cur.execute(query_max_id_sql)
result = my_cur.fetchone()
max_id = result[0]
if max_id==None or max_id=='' or max_id=='none':
print ('Waring: Arch max id id null. cant find any arch rows. so pt-archiver not work.')
sys.exit(0)
arch_where = "id <= %s and %s" %(max_id,arch_where)
cmd = ( """ usr/bin/pt-archiver --source h=%s,P=%s,u=dbadmin,p=xxxxxx,D=%s,t=%s --dest h=%s,P=%s,u=dbadmin,p=xxxxxx,D=%s,t=%s --where="%s" %s """)%(source_host,source_port,source_db,source_table,dest_host,dest_port,dest_db,dest_table,arch_where,ext_options)
stat,output=subprocess.getstatusoutput(cmd)
关注我,获得更多干货信息,感谢大家的关注。




