




随着存储的数据量越来越大,用户可以通过分析大规模历史数据,进行决策分析。 为了提高分析的效率和决策的效果,需要把数据从事务处理环境中提取出来,建立数据仓库,并对其进行相应的数据存储和数据分析。
定义
OLAP(Online Analytical Processing)是指一类支持对大规模数据进行较为复杂的联机分析
处理的数据库,更关注复杂查询和聚集分析。
特性
OLAP数据库分析处理的特性如下:
- OLAP系统通常并发不高,每个查询会运行较长时间,操作的数据量巨大。
- 分析中的查询,大多只需读取数据,不会对历史数据轻易修改。
- 分析中的关系代数操作,会包含非常复杂的交运算,中间结果可能种类繁多数量庞大,但最终返回给用户的结果可能较小较容易理解。
- 分析查询面向某一主题的数据,尝试从集成数据中发掘新知识,所以可能执行分析查询前,用户自身对结果的情况也是未知的。
针对上述特点,OLAP分析处理实现依赖很多技术,其中包括 [1]:
- 列存储(Column-oriented),多维存储。优势:只需要读取相关数据。劣势:对某一条记录的写操作需要多次访问。
- 通过节点间并行、多核并行、SIMD的全并行架构来提升分析速度读。
- 向量化引擎,通过向量化执行实现SIMD,从而可以加速分析处理速度。
- 通过列存编码压缩来提升分析速度。
- LLVM编译优化技术,通过静态编译AOT和动态编译JIT来提升查询速度。
- 多维索引技术可以加速聚集等操作。
- 依据历史分析记录,创建视图,通过视图来加速查询速度。
- 通过share scan等共享计算技术提升查询速度。
评测标准
TPC-H:TPC-H基准模拟商务采购应用,其数据库模式包含8张表,分别代表参与商业领域中 采购和订购的对象或行为。性能评测基准定义了22个复杂查询语句和2个更新数据语句。 数据库的规模由标度因子决定,从1GB到100TB不等。 TPC-H基准以每小时内执行的查询数作为度量标准 [18]。
TPC-DS:TPC-DS与TPC-H相比,在四方面做了改进。 首先,数据库模式使用共享的雪花模式,包含24张表,平均每张表含有18列。 其次,工作负载包含99个随机可替换的SQL查询,具有更强的代表性。 最后,还包括数据抽取、转换和加载功能。 TPC-DS基准定义了3个主要度量和4个辅助度量,主要度量包括: 1.每小时内执行完毕的查询树,已描述查询吞吐率;2.每小时内执行的查询数的性价比;3.系统生效日期,及所有在测组件全部生效的日期 [18]。
JOB: 主要用于连接顺序的选择,对数据库系统的查询效率有重要影响。 在评价数据库对连
接顺序的优化效率时,可以使用JOB(Join Order Benchmark)进行评测。
单机OLAP数据库
单机的计算资源受限,处理庞大数据分析十分困难,对复杂分析更无法应对,因此OLAP数据库很少单机和集中式架构。
集中OLAP数据库
集中数据库一般采用share storage架构,而OLAP一般是IO和计算密集型操作,这种架构不适合于OLAP操作,因此OLAP也很少采用集中式架构
分布式OLAP数据库
由于OLAP数据库数据量大,计算量大,因此分布式架构更为合适。分布式OLAP数据库一般采用全并行无共享架构、向量化执行、编译执行、列式存储来提升计算效率。分布式优化器 通过节点间计算和交互来提升计算并行度。
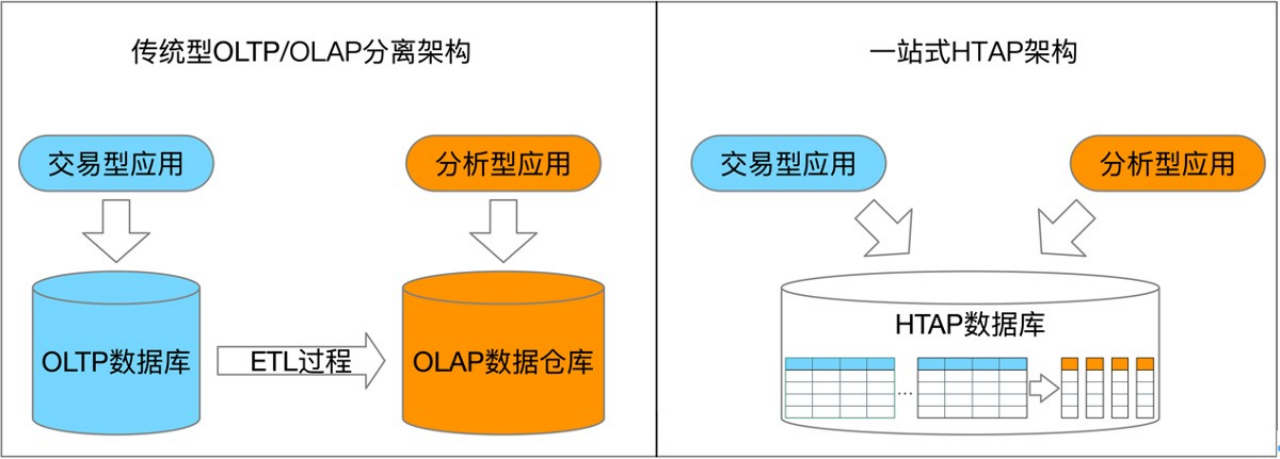
图 1: OLTP、OLAP、HTAP
分布式OLAP数据库业界代表包括TeraData、Greenplum、GaussDB(DWS)、AnalyticDB、
Bigquery、 Clickhouse等。
此外,还有大数据系统支持OLAP功能,例如HIVE、Spark SQl等,它们一般支持海量数据的离线分析。而OLAP数据库更关注在线分析。
云原生OLAP数据库
云原生OLAP数据库也需要解决计算存储分离、元数据解耦、计算下推问题,从而可以解 决扩容问题,提升了扩容速度。云服务层存储管理计算集群、查询、事务以及所有元数据(如 数据库目录、访问控制信息等)的服务集合底层存储中。
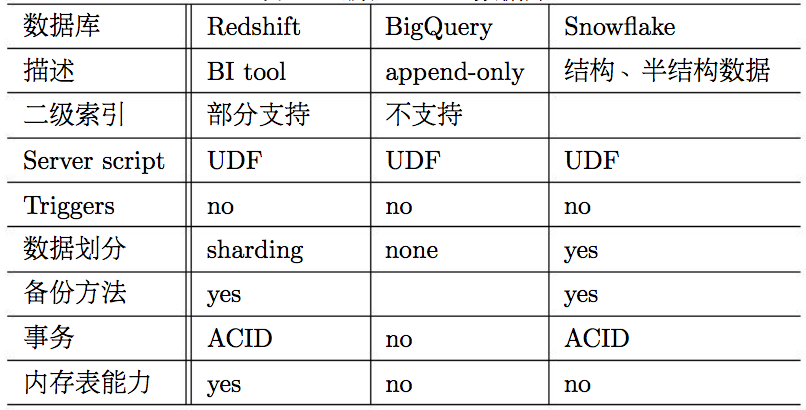
云原生OLAP业界代表包括Redshift、SnowFlake和BigQuery。
表 3: 云原生OLAP数据库
如何鉴别OLAP数据库
由于分析型数据库需要较大算力来支持数据分析,因此分析型数据库主要采用分布式架构,利用多节点来提升计算性能。
