




导语1:
我们在进行性能测试过程中会出现数据库CPU过高,内存使用率过高,IO繁忙等问题。我们可以根据以下几点进行数据库性能调优。
缓冲池(BuffPool)命中率调优
首先进入db2数据库安装路径(cd/opt/ibm/db2/V10.1/instance)的使用(./db2ilist)命令,查看当前db2数据库的实例:

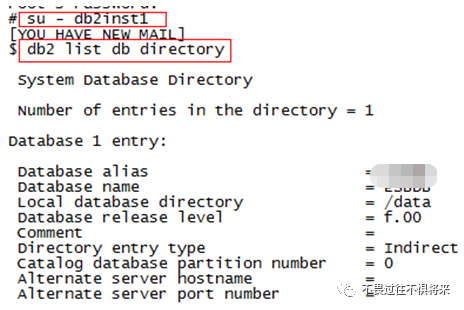
使用su - db2inst1命令切换到当前db2数据库实例用户。
注意:数据库实例(db2inst1)是数据库运行的一个环境,而数据库实例用户(db2inst1),是操作系统下能操作数据库的一个系统用户。
使用db2 list dbdirectory命令查看当前数据库名称:
在压测过程中使用db2inst1(数据库所在的实例用户还比如db2usr)用户
执行db2pd –d dbName –buff(dbName为数据库名称)去查看缓冲池,如果遇到如下提示:

开启监视快照开关
表明此时快照开关未捕获到快照数据或者db2数据库本身未开启快照开关;
使用db2 "update monitor switches using lock ON sort ON bufferpool ON uow ON table
ON statement ON"命令打开db2的快照开关。
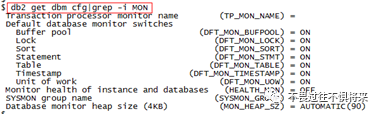
使用db2 get dbmcfg|grep -i MON命令来查看数据库是否开启快照开关:
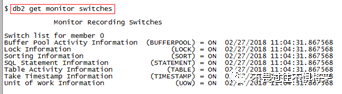
或者使用db2 getmonitor switches 命令查询快照各个快照开关是否被打开。
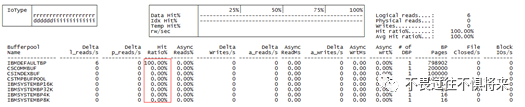
如下图为结果执行db2pd–d dbname –buff命令的第一部分:

从上图中可以看到所有缓冲池信息及编号。主要看第四列(PageSz)和第五列(PA-NumPgs)分别为缓冲池页大小(单位:K)和页数量。这两个数的乘积为该缓冲池所占的内存,一般可以在总内存的10%。第8列(NumTbsp)为使用该缓冲池的表空间数量。
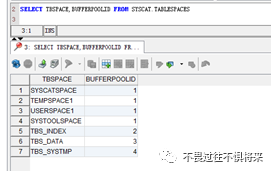
一个表空间只能放在一个缓冲池里,一个缓冲池可以放多个表空间。表空间与缓冲池对应关系可以去执行sql:SELECT TBSPACE,BUFFERPOOLID FROM SYSCAT.TABLESPACES查看。
如下图为db2pd –d dbname–buff命令的第二部分:
该图第1列(BPID)对应图1里的第2列(ID)。图2的第2列(DatLRds)为逻辑数据页读取数,图2的第3列(DatPRds)为物理数据页读取数。第4列(HitRatio)为逻辑和物理读取数据页的命中率。第8列(IdxLRds)为逻辑索引页读取数,第9列(IdxPRds)为物理索引页读取数。第10列(HitRatio)为逻辑和物理读取的索引页的命中率。命中率的值理论上应该大于95%,并接近100%,此时也可以说明缓冲池是被合理利用了的。
使用db2top -d dbname -R命令进入界面后按b后,可以在压测过程中实时查看缓冲池的使用情况。如下图所示:

如果发现缓冲池命中率不高,就需要增加缓冲池大小,增加缓冲池页数量即可。命令为:db2 ALTER BUFFERPOOL "BUFF_NAME"IMMEDIATE SIZE 5000 。其中BUFF_NAME为缓冲池名称,5000为缓冲池页数,IMMEDIATE表示立即就可以生效。但是注意增加缓冲池页数量时不要一次加太大,而且不要在压测时增加,否则可能导致数据库内存不足而崩溃。示例如下所示:
适当增加缓冲池可以减少IO和CPU的繁忙度。但是会增加服务器内存使用率。
sql调优
db2top工具使用:
首先在压测过程中使用db2inst1数据库实例用户执行db2top–d dbname -R(dbname为数据库名称,-R可以重置数据),出现图3所示结果:
图3
在这个界面按下键盘大写的D键进入动态sql界面,如图4:
按下R再输入y回车可以刷新界面。
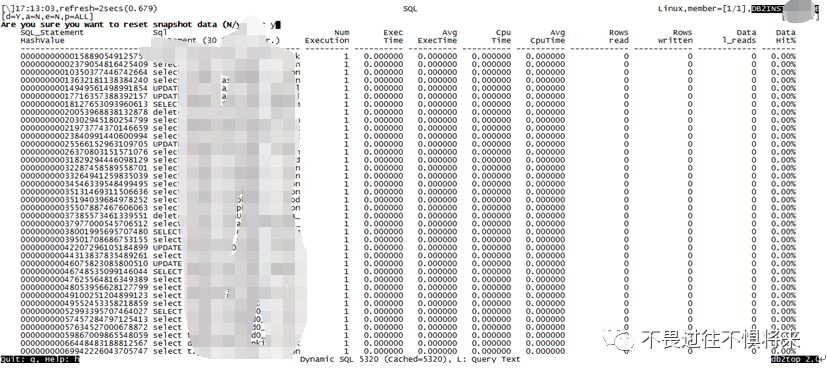
图4
其中第1列(HashValue)为动态sql的hash值,
第2列(Statement)为sql语句,
第3列(Num Execution)为该sql的总执行次数,
第4列(Exec Time)为该sql的总执行时间,
第5列(Avg Exectime)为该sql平均执行时间,
第6列(Cpu Time)为该sql的总执行CPU时间,
第7列(Avg CPUTime)为该sql 的平均CPU时间,
第8列(Rows read)为该sql总的读取行数,
第9列(Rows Written)为该sql总的写入行数。
在这个界面可以对任意列进行排序,操作方法为:在图4界面按’z’键在右上角会出现图5红圈标记文字:
图5
此时输入数字即可,需要注意的是这里的第一列对应的数字为0,依次类推。一般情况下根据平均执行时间和平均消耗CPU时间进行排序,也就是第4列和第6列进行排序。可以查看压测过程中耗时最长的sql 和最消耗CPU的sql。
找到问题sql后,可以查看这条sql 的完整语句,方法为:在图4界面按下键盘的大写的’L’键,会出现图6的红圈标记文字:
图6
此时,复制该sql 对应的第一列的值,粘贴到红圈后,按回车即可出现该hash值对应的sql语句。如图7所示:
图7
此时可以查看该sql 的完整语句。查看sql的执行计划可以直接按小写e来查看,按:q回车返回动态SQL界面。
或者按大写E直接把完整sql语句写入临时文本,选中复制即可,键入:q并回车即可回到刚才的动态sql界面。(按任意键关闭该sql弹窗界面)
db2expln工具查看sql 的执行计划:
查看sql的执行计划需要执行如下:
db2expln-d dbName -u userName password -f a.sql -z @ -output a1.out -graph
db2expln-d MDDB -u db2inst1 db2inst1 -f a.sql -z @ -output a1.out -graph
db2expln-d echannel -u db2inst1 db2inst1 -f as.sql -z @ -output as.out -graph
db2expln-d pbpdb -u db2inst1 db2inst1 -f ah.sql -z @ -output ah.out -graph
db2expln-d fwapdb -u db2inst1 db2inst1 -f aa.sql -z @ -output as.out -graph
SQL5193N The current session user does not have usage privilege on any
enabled workloads. SQLSTATE=42524 报错需授予dbadm权限的用户使用下面的命令:
db2 "GRANT DBADM ON DATABASE TO USERdb2inst1"
(dbName为数据库名,userName为用户名,password为密码, a.sql内的为sql语句,此sql的执行计划存储在a.out)
在这里只需要把sql写到a.sql(echo “sql语句” >a.sql)这个文件里就行了。这里使用的是相对路径,也可以指定绝对路径指定文件。如下图所示:
执行db2expln命令后,a.out会出现很多结果,需要我们重点关注的结果如图8:
图8
首先查看statement是否为我们需要执行命令的sql,这一个一定要看,否则有可能导致你看到的结果并不是你想要的那条sql的结果。
然后在看EstimatedCost(预估代价)这个的值。一般情况下,这个值越小越好,小于100就已经不错了,在100-1000之间的值可以暂时不用调优,超过1000的可以选择调优,超过1万的必须要进行调优。怎样进行调优呢?可以看最后的一个二叉树一样的图。这个图可以反映每一步的CPU时间和是否使用了索引。比如我们来分析图9的结果:
图9
这个结果执行的sql语句为:
会发现他的执行过程为小括号里的顺序,分别去查询两个索引:P_MALL_MEMBER_MEMNBERID和P_MALL_MEMBER_MEMBERID2,其中IXSCAN为索引扫描,SORT为排序,RIDSCAN为行号扫描,每一步的CPU时间均在每一步的下方,最终会把每一步的cpu时间相加得到最终的CPU时间。
有时候会出现下图的结果
TBSCAN为全表扫描,这种全表扫描在数据量大的情况下会导致CPU时间很大,特别是如果还有排序操作的话更消耗CPU,因此遇到这种情况,最好给这个表加上sql语句中where条件的索引。如果where后面有or语句则分别对or左右的两个条件做索引。
CPU时间和平均执行sql时间不完全成正比,还需要看实际情况来进行分析。有时候sql执行时间长,但CPU时间并不是很高;有时候CPU时间很高,但sql执行时间却不长。总的来说,(Estimated Cost)CPU时间过长的sql是肯定需要调优的。一般情况下加索引就可以解决大部分CPU时间长的问题,实在不行就得考虑改变sql语句了。
db2advis工具(sql优化建议工具):
使用命令db2advis -d dbName -n schema -i 11.sql>11sql.txt查看sql优化建议
(dbName为数据库名,schema为模式名, 11.sql里的sql语句以;结束, 11sql.txt里为此sql优化的建议)
db2advis -d cbsdb -n cbsdb -i qq.sql>qqsql.txt
db2advis -d mddb -i aa.sql -m i -l-1 -t 0 -o product.txt
db2advis -d cmsdb -i a.sql -m i -l-1 -t 0 -o product.txt
db2advis -drcbdata -n db2inst1 -i12.sql>12sql.txt
db2advis -dechannel -n db2inst1 -i as1.sql>as1sql.txt
db2advis -d cntdb -n db2usr1 -i as1.sql>as1sql.txt
db2advis -d pbpdb -n db2usr1 -i ah.sql>ah.txt
如果使用db2advis命令时报错如下:
则表明还未创建db2advis工具使用的环境,需操作如下步骤:
id
cd opt/IBM/db2/V10.1/misc
ls -ltr
su - root
chown -R xxdb:db2iadm1 EXPLAIN.DDL
su - xxdb
db2connect to xxdb
db2 -tf EXPLAIN.DDL
创建好环境后,使用示例如下所示:
如何建索引(index):
执行 db2"select * from syscat.indexes whereupper(tabname)='AFA_MAINTRANSDTL'"
命令在CRT上查看表已经建立的索引。
删除索引 dropindex indexname;(使用此命令需谨慎)
执行db2 "create index 表名_字段名 on 表名(字段名 asc) "命令来建立索引。
Eg:db2 "create index MALL_xxxID on MALL_MEMBER (xxxIDasc) "
Eg:db2 " CREATE INDEX "ACCOUNT"."IDX_ELE_ACCOUNT_ACCOUNT_NO" on "ACCOUNT"."T_ELE_ACCOUNT"("ACCOUNT_NO","AVAILABLE_BALANCE")" --组合索引
db2look查看建表语句:
db2look -d dbname -e -z schemaname -ttablename --查看建表语句
db2look -d xxdb -e -z db2usr1 -t tablename
db2pd工具(捕获引起锁等待的sql)
db2 get snapshot for database on dbname|grep -i lock --搜集数据库锁快照
(dbname为数据库名称)
while true
do
db2pd -d afa-lock
sleep 1
done --找apphandl 27147 TranHdl(事务句柄) 34 一直有的且sts为W Ctrl +C 退出
-- -wlock --lock
----db2pd -d db2inst1-tran 34 --找AppHandl 27147
db2pd -d afa-app27147 ----是L-AnchID L-StmtUID 495 1
db2pd -d afa-dyn> dyn.out
more dyn.out --找L-AnchID L-StmtUID 495 1
db2pd -d db2inst1 -dyn> dyn.out --找sql语句 495 1
more dyn.out
/495 --找相应sql语句
具体操作如下所示:
db2pd -d db2inst1 -locks show detail | awk'{if($4~/(TableLock|Type)/) print $0}'
执行这个命令后,你也许会看到很多的锁,分析的入手点一定是正在等待的应用程序,也就是下面所列,状态(Sts)为W(waiting)的应用。--sts列的W表示等待,G表示授予。
查看所有锁,TranHdl为34的状态为锁
db2pd -d dbname -transactions | awk '{if($4== 34 || $4 == "TranHdl")print $0}'
找到transaction handle 为34的那一行找到其AppHandl 为27147
注意,当LogSpace不为0的时候,这个应用一定有未提交的更改操作
db2pd -d dbname -applications | awk '{if($2== 27147|| $2 =="AppHandl") print $0}'
找到 L-AnchID和L-StmtUID(句柄标识和上条语句的句柄标识)对应的为495 和1
db2pd -d dbname -dyn> dyn.txt
more dyn.txt 495再回车来查找具体sql
通过动态语句的对应(AnchID StmtUID分别为495和1),对应的sql语句为insertinto test_lock..
DB2数据库日常维护工具理解:
runstats:运行时统计信息,如表行数、表页数、表有效数据页数,表的列分布、索引统计信息等,当db2优化器选择最佳路径提供数据runstats的统计信息存在syscat模式下的9张表视图(view)里。
reorg:类似于磁盘碎片整理,对表和索引做数据物理上的重组,便于提高性能。
reorgchk:重组检查,一般reorgchk后表的后面带符号*时,即表示需要reorg。
rebind:主要针对存储过程或静态嵌入。当数据库发生较大变动时执行此命令。
DB2数据库日常执行语句:
su - db2inst1
dbname=`db2 list db directory | grep -i"Database name" |head -n 1 |awk -F= '{print $2}'`
echo $dbname
db2 connect to $dbname
db2top -d $dbname -R
D
su - db2inst1
dbname=` db2 list db directory| grep -i"Database name" |head -n 1 |awk -F= '{print $2}'`
echo $dbname
db2 connect to $dbname
db2 reorgchk on table all
db2rbind $dbname -l db2rbind.out
df -g -- db2rbind重新绑定,一般数据库表数据全部删除后执行有明显效果
之后挑出有*号的表执行reorg
db2 reorg table XXX表 --reorg XXX表
db2 reorgchk on table XXX表 -- runstats 单表
db2 reorg indexes all for table XXX表 --reorg XXX表的索引
db2 runstatson table XXX表with distribution on all columns and indexes all - runstats该表所有的索引
db2 runstatson table XXX表for sampled detailed index XXX索引 –runstats具体索引
db2 list tables for all --查看此数据库下所有表
当runstats表索引时报错如下时,表示有些统计数据处于不一致的状态,需要重新整理。
则需db2 reorg TABLE XXX表,之后再runstats相关表索引。
Eg:
db2 reorg TABLE DB2USR1.AGENT_MERCHANT_TRANSACTION
db2 runstats on table"DB2USR1"."AGENT_MERCHANT_TRANSACTION" with distribution onall columns and indexes all
db2 "RUNSTATS ON TABLE"DB2USR1"."AGENT_MERCHANT_TRANSACTION" FOR SAMPLED DETAILEDINDEX "DB2USR1"."IDX1905290207430""
使用get snapshot 命令得到快照信息。
监视快关打开后,可以使用get snapshot 命令得到快照信息。
db2 "update monitor switches using lock ON sort ON bufferpool ON uow ON table
ON statement ON"命令打开db2的快照开关。
db2 get snapshot for [ bufferpools | locks| dynamic sql | applications | tablespaces | database | all ] on 数据库名
--比如:查看动态sql快照
db2 get snapshot for dynamic sql on afa> sql1.out
--比如查看locks
db2 get snapshot for locks onafa>lock.out
db2pd -d dbname -locks -app -dyn>dyn111.out
db2pd -d dbname -app -tran -dyn -wlocks show details> dyn116.out
db2pd -d mddb -app -tran -dyn -wlocks show details> dyn116.out
当db2top工具卡顿时直接查db2数据库看问题sql
--查看耗CPU的sql
select a.STMT_TEXT,a.* fromsysibmadm.snapdyn_sql a order by a.total_usr_cpu_time desc fetch first 10 rowsonly
--运行时间长的前10条
select * from sysibmadm.long_running_sqlorder by elapsed_time_min desc fetch first 10 row only
--排序次数最多的前10条
select STMT_TEXT,STMT_SORTS fromsysibmadm.top_dynamic_sql order by stmt_sorts desc fetch first 10 rows only
--执行次数最多的前10条
select * from sysibmadm.SNAPDYN_SQL orderby NUM_EXECUTIONS desc,TOTAL_SYS_CPU_TIME_MS desc fetch first 10 rows only>> num_executions.txt
离线备份与数据库还原
直接切换到数据库实例用户(su – db2inst1)
执行db2 force applications all
之后直接执行db2 backup dbmddb to data进行离线备份即可
在有日志的情况下回滚数据库
db2 rollforward db echannel to end of logsand complete
db2 backup db cntdb --备份cntdb数据库,前提要db2 force applications all,不必连数据库
db2 backup db cntdb to/home/db2inst1/backup compress --离线备份并压缩
db2 backup db cntdb online to/home/db2inst1/backup compress --在线备份(必须是在归档模式下进行)
还原数据库
db2 restore database YANYIN(旧) from .(备份文件所在路径)taken at 20370616104315(时间戳,备份文件名里面有) into YANYIN(新)
MDDB.0.db2inst1.DBPART000.20181015150839.001
db2 restore database mddb from data takenat 20181015150839 into mddb
cpu高(或者db2top按D后z后输5即查看cputime)
db2pd -edus interval=10 top=5 stacks
db2pd -agents|grep -i 54237
db2 get snapshot for application agentid 18929>18929.txt
cpu高时使用db2top查看具体sql
db2top -d cmsdb-R按l
按a输入cpu使用率高的application handle的id
按z显示sql,按回车可以往下翻sql
