




执行引擎位于优化器和存储引擎之间,负责将数据从存储引擎读取出来,根据计划将数据处理加工返回给客户端。执行器接收到的指令就是优化器应对SQL查询而翻译出来的关系代数运算符所组成的执行树,如下图所示:
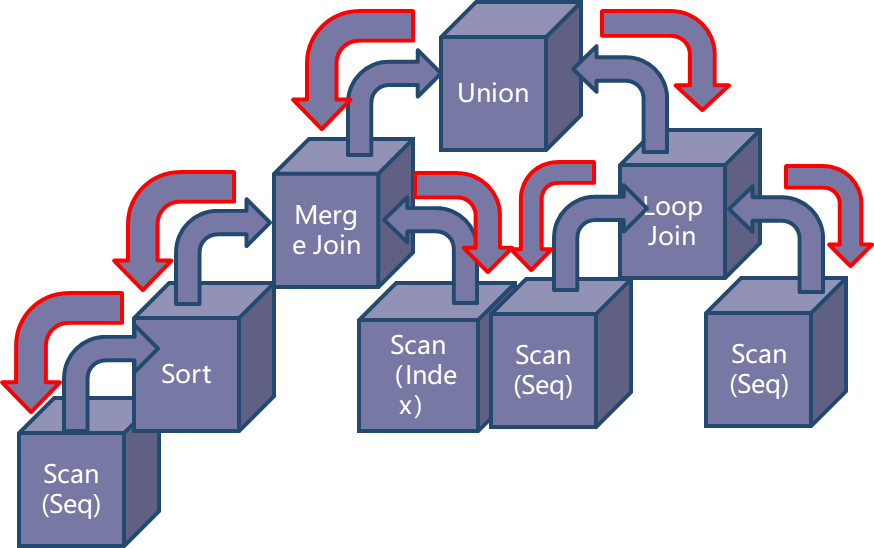
向上的流代表数据流,是指下层算子将数据返回给上层算子的过程,这是一个从下至上、从叶节点到跟节点的过程。在openGauss中,所有的叶子节点都是表数据扫描算子,这些节点是所有计算的数据源头。数据从叶子节点,通过逐层计算,然后从根节点返回给用户。 向下的流代表控制流,是指上层算子驱动下层算子执行的过程,这是一个从上至下、由根节点到叶节点的过程。从代码层面来看,即上层算子会根据需要调用下层算子的函数接口,去获取下层算子的输入。驱动流是从根节点逐层传递到叶子节点。
算子分类
关系数据库本身是对关系集合Relation的运算操作,执行引擎作为运算的控制逻辑主体也是围绕着关系运算来实现的,在传统数据库实现理论中,算子的分类可以分成以下几类:
扫描算子(Scan Plan Node)
扫描节点负责从底层数据来源抽取数据,数据来源可能是来自文件系统,也可能来自网络(分布式查询)。一般而言扫描节点都位于执行树的叶子节点,作为执行树PlanTree的数据输入来源。

控制算子(Control Plan Node)
控制算子一般不映射代数运算符,通常是为了执行器完成一些特殊的流程引入的算子。
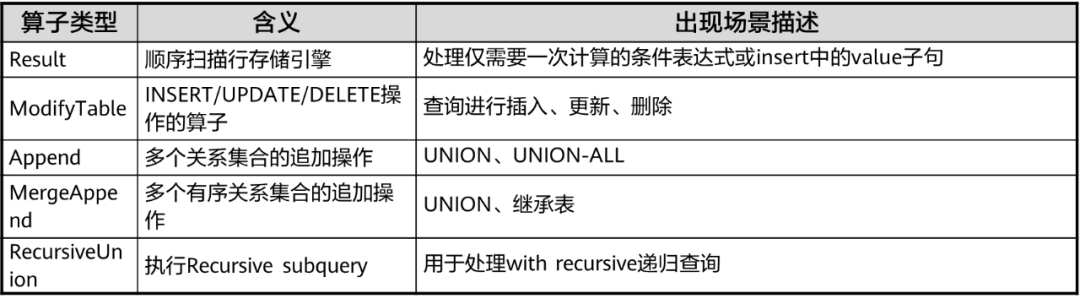
物化算子(Materialize Plan Node)

连接算子(Join Plan Node)
关键特征:多个输入。

按照连接类型有6种关联算子。
下面重点分析Seqscan算子的代码流程。

Seqscan 算子
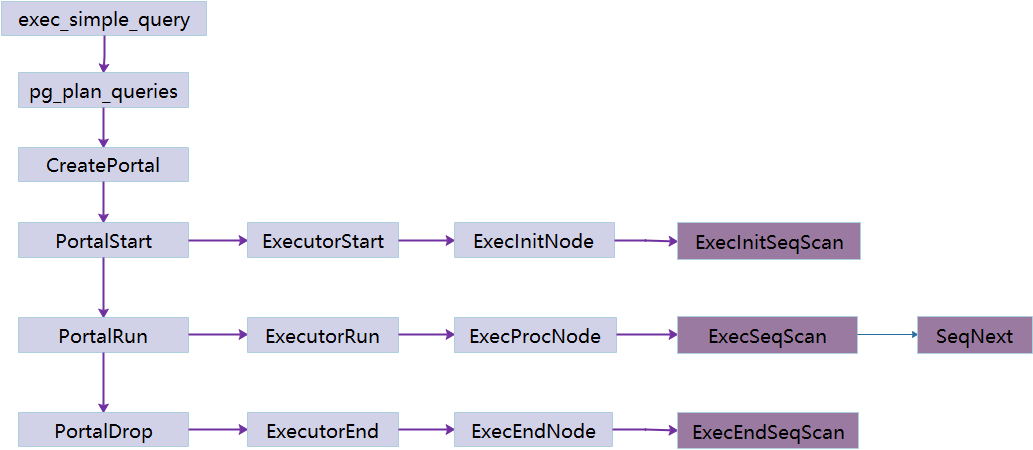
ExecInitSeqScan
ExecInitSeqScan函数初始化SeqScan状态节点,负责节点状态结构构造。
SeqScanState* ExecInitSeqScan(SeqScan* node, EState* estate, int eflags)
{……/** create state structure*/SeqScanState* scanstate = makeNode(SeqScanState); // SeqScan状态节点scanstate->ps.plan = (Plan*)node;scanstate->ps.state = estate;scanstate->isPartTbl = node->isPartTbl;scanstate->currentSlot = 0;scanstate->partScanDirection = node->partScanDirection;scanstate->rangeScanInRedis = {false,0,0};……/** tuple table initialization*/InitScanRelation(scanstate, estate, eflags); // 初始化扫描表……/** initialize scan relation*/InitSeqNextMtd(node, scanstate); // 设定获取元组的函数……return scanstate;}
InitSeqNextMtd函数设定获取元组的函数为SeqNext。
static inline void InitSeqNextMtd(SeqScan* node, SeqScanState* scanstate){if (!node->tablesample) {scanstate->ScanNextMtd = SeqNext;……}
ExecSeqScan
ExecutePlan函数循环调用ExecProcNode获取元组。
static void ExecutePlan(EState *estate, PlanState *planstate, CmdType operation, bool sendTuples, long numberTuples,ScanDirection direction, DestReceiver *dest, JitExec::JitContext* motJitContext){TupleTableSlot *slot = NULL;long current_tuple_count = 0; // 初始化……/** Loop until we've processed the proper number of tuples from the plan.*/for (;;) { // 循环调用ExecProcNode……if (unlikely(recursive_early_stop)) {slot = NULL;} else if (motJitContext && !IS_PGXC_COORDINATOR && JitExec::IsMotCodegenEnabled()) {// MOT LLVMint scanEnded = 0;if (!motFinishedExecution) {// previous iteration has not signaled end of scanslot = planstate->ps_ResultTupleSlot;uint64_t tuplesProcessed = 0;int rc = JitExec::JitExecQuery(motJitContext, estate->es_param_list_info, slot, &tuplesProcessed, &scanEnded);if (scanEnded || (tuplesProcessed == 0) || (rc != 0)) {// raise flag so that next round we will bail out (current tuple still must be reported to user)motFinishedExecution = true;}} else {(void)ExecClearTuple(slot);}} else {slot = ExecProcNode(planstate); // 调用ExecProcNode}……/** if the tuple is null, then we assume there is nothing more to* process so we just end the loop...*/if (TupIsNull(slot)) { // 元组为空即中止循环if(!is_saved_recursive_union_plan_nodeid) {break;}ExecEarlyFreeBody(planstate);break;}……{(*dest->receiveSlot)(slot, dest); // 简单select语句调用printtup函数}……/** check our tuple count.. if we've processed the proper number then* quit, else loop again and process more tuples. Zero numberTuples* means no limit.*/current_tuple_count++; // 计数元组数if (numberTuples == current_tuple_count) {break;}}……}
ExecProcNode函数根据nodeTag执行g_execProcFuncTable对应的函数。
TupleTableSlot* ExecProcNode(PlanState* node){TupleTableSlot* result = NULL;……{int index = (int)(nodeTag(node))-T_ResultState;Assert(index >= 0 && index <= T_StreamState - T_ResultState);result = g_execProcFuncTable[index](node);}……return result;}
ExecProcFuncType g_execProcFuncTable[] = {ExecResultWrap,……ExecSeqScanWrap,ExecIndexScanWrap,ExecIndexOnlyScanWrap,……};
ExecSeqScanWrap->ExecSeqScan->ExecScan->ExecScanFetch,ExecScanFetch函数回调SeqNext获取元组。
static TupleTableSlot* ExecScanFetch(ScanState* node, ExecScanAccessMtd access_mtd, ExecScanRecheckMtd recheck_mtd){……/** Run the node-type-specific access method function to get the next tuple*/return (*access_mtd)(node); // 回调SeqNext}
ExecEndSeqScan
ExecEndSeqScan完成清理工作。
