




作者:稀饭
1、实际场景中需要消息队列的原因
在实际应用中,不同的数据生产者(服务器)产生的日志,比如指标监控数据、用户检索日志等,需要同时传递到多个系统中以便进行相关的逻辑处理或分析挖掘。由于涉及一对多或多对多的情况,为了降低数据生产者和消费者之间的耦合性,平衡两者处理能力的不对等,就需要有一个中间件 +—— 消息队列来解除生产者和消费者之间的直接依赖关系,使得软件架构更容易扩展和伸缩。
2、中间件的作用
可以缓冲生产者产生的数据,防止消费者无法及时处理生产者生产的数据。在大数据领域,最常用的中间件是Kafka。
3、大数据场景中使用Kafka的动机
为了降低数据生产者(如Web Server)和消费者(如Hadoop集群)之间的耦合性,使得系统更容易扩展,需要引入一层“中间件”,Kafka是大数据领域的中间件代表,引入它可以带来的收益有:
(1)避免生产者和消费直接互通产生的彼此高度依赖;
(2)可以缓存生产者生产的数据,使得消费者可以重复消费历史数据;
(3)消费者可以订阅某类主题的数据,当生产者产生对应主题的数据后,所有订阅者可以快速获取到数据,即消费者可快速获取新增数据;
(4)所有收集到的数据会流经Kafka,之后由Kafka分流后,进入各个消费者系统。
4、Kafka与Flume的区别
Kafka和Flume在架构和应用上均有较大不同:
(1)Kafka中存储的数据是多副本的,能够做到数据不丢,而Flume提供的memory channel和file channel均无法做到;
(2)Kafka可以将数据暂存一段时间,使得消费者可以重复读取;但Flume Sink发送成功数据后会立即将其删除;
(3)Kafka的生产者和消费者均需要用户使用API编写,仅提供少量的与外部系统集成的组件,而Flume则提供了大量的Source和Sink实现,能更容易地完成数据收集工作。
5、Kafka的特点
(1)高性能
相比于其他一些老款消息队列,Kafka具有更高的性能和吞吐率。经LinkedIn对比测试,单台机器同等配置下,Kafka单位时间内处理的消息数是RabbitMQ等的40~50倍。
(2)良好的扩展性
Kafka采用的是分布式设计架构,数据经过分片后写入多个结点,既可以突破单节点数据存储和处理的瓶颈,也可以实现容错等功能。
(3)数据持久性
数据消息均会持久化到磁盘上,并通过多副本策略避免数据丢失。Kafka采用了顺序写、顺序读和批量写等机制,提升了磁盘的操作效率。
6、Kafka的基本架构
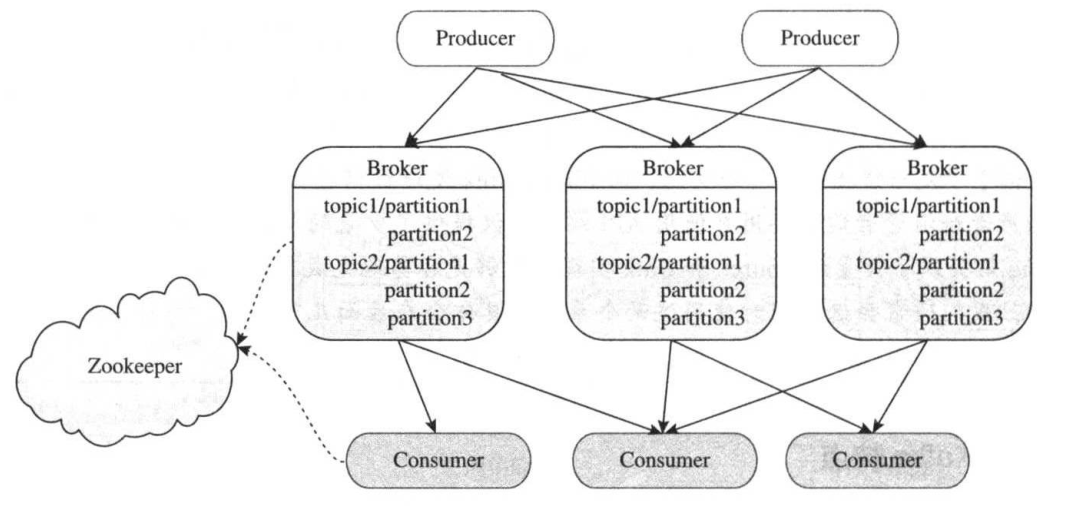
Kafka的架构由Producer、Broker和Consumer三类组件构建。其中Producer将数据写入Broker,Consumer则从Broker上读取数据进行处理,而Broker构成了连接Producer和Consumer的“缓冲区域”。Broker和Consumer通过Zookeeper做协调和服务发现。多个Broker构成一个可靠的分布式消息存储系统,避免数据丢失。此外,Broker中的消息被划分成多个Topic,同属一个topic的所有数据按照某种策略被分成多个partition,以实现负载分摊和数据并行处理。
广告区↓

