




1、引言
在 Elasticsearch 的 Pipeline 处理管道中,几乎所有的 Processor 均仅能对现有索引进行数据加工,如大小写转换、空白符处理、字符串切分、字符串重组等等。不论是通过 Reindex 重建索引或是通过 update_by_query 对现有索引进行修改,其操作的数据源均为当前执行的索引。但实际在生产环境中,有一种特别常见的需求,通过普通的 管道处理器是无法完成的。
2、背景
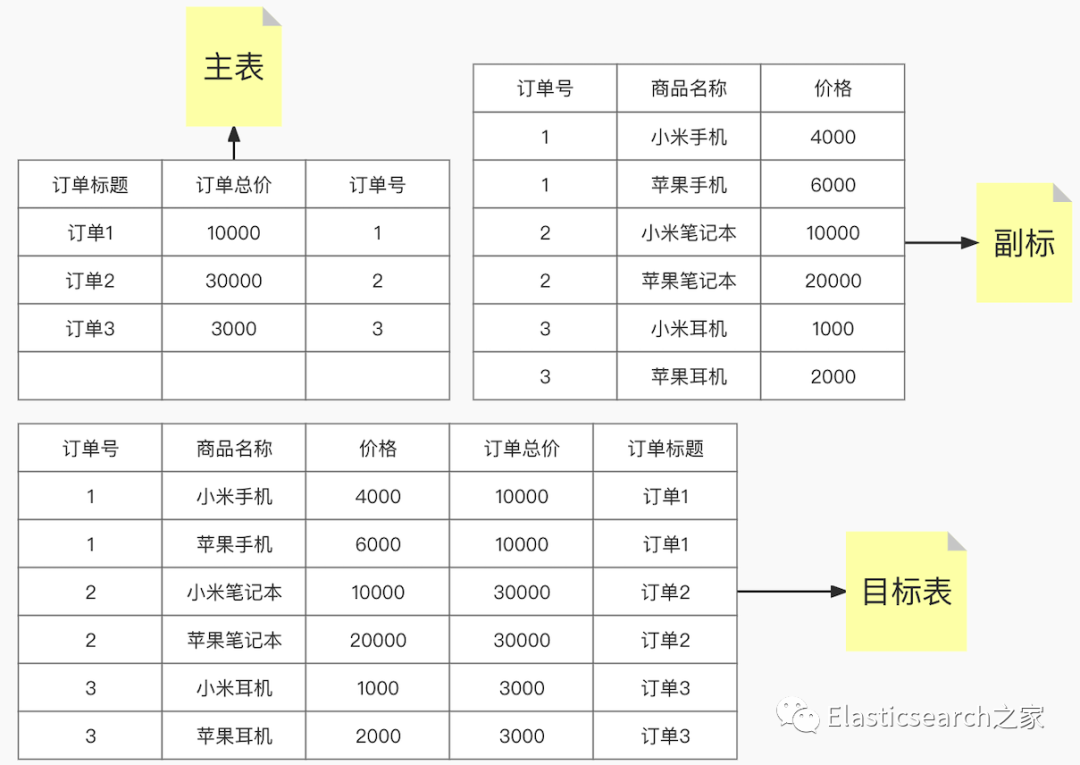
在关系型数据库中,表关联操作是非常常见的一种数据重组操作,如下图案例所示,我们假设有如下需求,需要将 order 表中的字段和 order_detail 表进行关联,生成目标表如下图中的目标表,其数据字段来源为 主表 和 副标。
3、使用场景
ES的写入实时性并不高,如果我们需要快速响应用户请求,我们常采取的手段就是使用缓存,但是在很多高并发的场景下,我们需要数据保持强一致性(如银行系统),因此需要使用具有ACID特性的数据库来支持,而MySQL就是一个比较好的选择。
但是如果单单只用MySQL,又无法解决海量数据的检索问题。其实在实际工作中常见的做法就是两者结合起来,通过数据同步的操作将MySQL的实时数据同步至Elasticsearch,两者各司其职互不干扰。
ES 是一个分布式的文档数据库,如果将上图中的主表和副表同步至 ES 的时候,在数据存储结构上,更好的方式应该是结构化存储,如下代码所示
{"_index": "order","_type": "_doc","_id": "3","_score": 1,"_source": {"order_name": "订单1","total_price": 3999,"price": 2999,"createtime": "2026-05-20","order_detail": [{"goods_name": "小米手机","price": 1999},{"goods_name": "小米手表","price": 1000}]}}
4、原理
在 ES 中,如果要讲两个类似于上述关系的索引 合并为上述代码中所示的结构,在 ES 中采取的手段即 Enrich Processor。Enrich Processor 的实现原理如下图所示(图片取自官方文档)
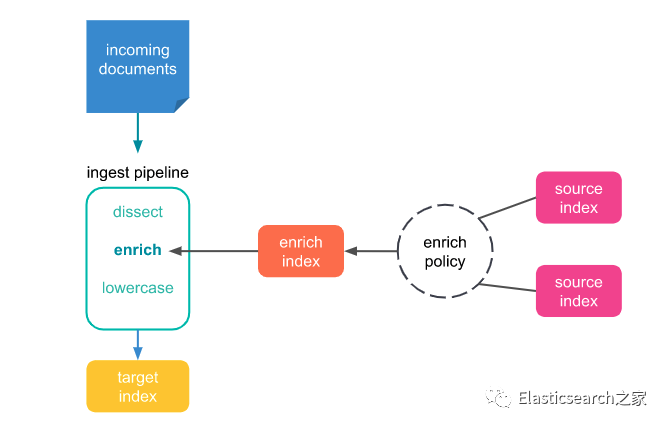
Enrich processor 本质是管道处理器的一种,只不过它可以关联外部索引,在这个过程中,source index 的作用为 target index 的源数据索引,即 target index 中所要扩展的字段,取自于 source index。比如要在 order_index 中扩展 order_detail ,那么 source index 的作用就是提供 order detail 中的索引字段。
其中 enrich policy 为丰富索引策略,所谓策略,是指在问题未发生的之前,人为对可能发生的问题做出评估和预判,并为可能会发生的问题制定解决手段以保证问题发生之后系统会按照指定策略执行的方案。所以在 Enrich Processor 中,enrich policy 所发挥的作用,即“约定”,其约定内容为:source index 中哪些字段会被关联到 target index 中,并且通过那个字段与 incoming document 进行关联。
enrich index 则为 enrich 为 policy 创建的实例,下面我将用一个形象的例子来解释整个 enrich processor 执行的过程。
5、Enrich Processor 的执行步骤
5.1 检查前置条件
•节点角色:当前执行 enrich processor 的节点是否具备 ingest 角色。•是否对索引有可读权限
5.2 检查源数据
首先,将文档添加到一个或多个源索引。这些文档应包含最终要添加到传入文档中的丰富数据。
下面的索引API请求创建一个源索引,并将新文档索引到该索引。
PUT /users/_doc/1?refresh=wait_for{"email": "mardy.brown@asciidocsmith.com","first_name": "Mardy","last_name": "Brown","city": "New Orleans","county": "Orleans","state": "LA","zip": 70116,"web": "mardy.asciidocsmith.com"}
5.3 制定 Enrich 策略
将 enrich data 添加到源索引后,使用创建 enrich policy API 创建 enrich 策略。
使用 create enrich policy API创建带有match
策略类型。该政策必须包括:
•一个或多个源索引•match_field
,源索引中用于匹配传入文档的字段•从要附加到 incoming documents 的源索引中扩展字段
PUT /_enrich/policy/users-policy{"match": {"indices": "users","match_field": "email","enrich_fields": ["first_name", "last_name", "city", "zip", "state"]}}
5.4 创建 Enrich 策略实例创建丰富策略后,使用 执行 enrich policy API 执行它以创建 enrich index。
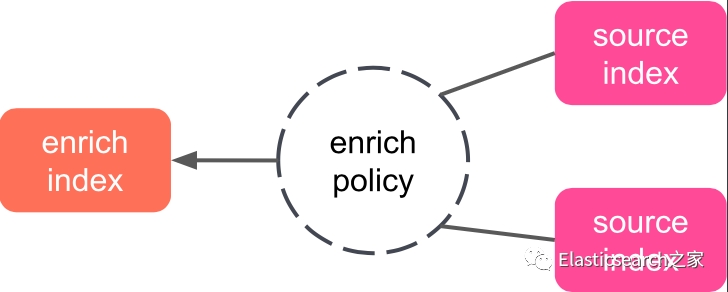
enrich 索引包含来自 policy source index的文档。enrich 索引以 .enrich-* 开头,是只读的,并且是强制合并的。
POST /_enrich/policy/users-policy/_execute
5.5 创建 Enrich Processor 并引用 Enrich Policy
一旦有了源索引、enrich policy 和相关的 enrich 索引,就可以设置一个ingest pipeline,其中包括 enrich policy。
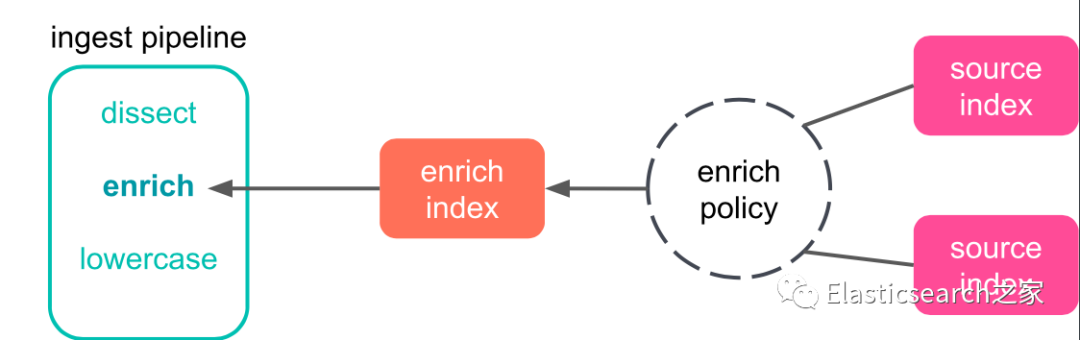
创建 enrich processor,并且符合以下要求:
•指定 enrich policy 名称•field
字段用于匹配 enrich 索引中的文档 的扩展字段,即关联字段。•这个target_field
用于存储从 source index 中传入字段的附加 enrich 字段。包含在 source index 在 enrich policy 中匹配的字段和 enrich fields。
PUT /_ingest/pipeline/user_lookup{"processors" : [{"enrich" : {"policy_name": "users-policy","field" : "email","target_field": "user","max_matches": "1"}}]}
5.6 调用 Enrich Processor 执行索引创建
PUT /my-index-000001/_doc/my_id?pipeline=user_lookup{"email": "mardy.brown@asciidocsmith.com"}
5.7 最终生成 target index 如下所示
{"found": true,"_index": "my-index-000001","_type": "_doc","_id": "my_id","_version": 1,"_seq_no": 55,"_primary_term": 1,"_source": {"user": {"email": "mardy.brown@asciidocsmith.com","first_name": "Mardy","last_name": "Brown","zip": 70116,"city": "New Orleans","state": "LA"},"email": "mardy.brown@asciidocsmith.com"}}
6、案例类比彻底搞定 Enrich
我将通过一个类比案例,彻底解释清楚,Enrich Processor 的执行过程。
假设 老王是个厨师,某天中午,老王媳妇儿想吃两道菜:干锅花菜、醋溜肥肠,下面我用类比法,把 Enrich Processor 的执行过程,用此案例来解释。
需求:(媳妇儿有交代,老王烧俩菜)
如果把 enrich processor 的执行过程比喻成做菜,那么我们可以做以下类比:
•source index => 配菜、配料•incoming document => 主食材•ingest pipeline => 厨房•enrich policy => 点菜的人心里的想法(比如要🌶,不要香菜,这里的🌶和香菜可以理解为 source index 中的某个字段)•enrich index => 菜谱清单•enrich processor => 厨师拿到菜谱、配菜、主食材做菜的这个过程•target index => 做好的菜品
6.1 检查先决条件(是不是有厨房,具不具备做菜条件)
节点角色(当前屋子是不是厨房,能不能做饭)
是否对索引有可读权限(配料是不是齐全)
6.2 准备数据(准备食材:配料):
添加 document (enrich data)到一个或者多个的 source index 中,这些 document 中应包含之后要添加到 incoming documents 中的数据。
注意:命名方式是为了方便理解,切勿学习中文命名方式
source index(配料表):
PUT /配料/_doc/1?refresh=wait_for{"菜品": "干锅花菜","调料": "食盐","配菜": "山东大葱","辅料": "酱油","配料a": "八角","配料b": "桂皮"}PUT /配料/_doc/2?refresh=wait_for{"菜品": "醋溜肥肠","调料": "食盐","配菜": "洋葱","辅料": "82年陈醋","配料a": "八角","配料b": "桂皮"}
6.3 创建 enrich policy(老婆特意交代:不要辣椒(配料a)和香菜(配料b)):
PUT /_enrich/policy/菜谱列表{"match": {"indices": "配料","match_field": "菜品","enrich_fields": ["调料", "配菜", "辅料"]}}
6.4 执行 enrich policy(把菜谱交给老王,可以理解为菜谱的实例化对象):
执行完后会自动创建相应的 enrich index, enrich index 和普通索引不同,进行了优化。
POST /_enrich/policy/菜谱列表/_execute
6.5 创建 ingest pipeline 使用 enrich processor(老王进厨房:做菜):
enrich processor 使用 enrich index 来查询。
按照菜谱准备配料
PUT /_ingest/pipeline/做俩菜{"processors" : [{"enrich" : {"policy_name": "菜谱列表","field" : "菜品","target_field": "本菜品包含的配料"}}]}
把配料加入食材,干锅花菜完成
PUT /中午的菜/_doc/1?pipeline=做俩菜{"主食材": "花菜","菜品": "干锅花菜"}PUT /中午的菜/_doc/2?pipeline=做俩菜{"主食材": "肥肠","菜品": "醋溜肥肠"}
6.6 媳妇儿品菜:嗯,不赖不赖
GET 菜品/_search
结果如下,一目了然
[{"_index": "菜品","_type": "_doc","_id": "1","_score": 1,"_source": {"主食材": "花菜","菜品": "干锅花菜","本菜品包含的配料": {"菜品": "干锅花菜","辅料": "酱油","调料": "食盐","配菜": "山东大葱"}}},{"_index": "菜品","_type": "_doc","_id": "2","_score": 1,"_source": {"主食材": "肥肠","菜品": "醋溜肥肠","本菜品包含的配料": {"菜品": "醋溜肥肠","辅料": "82年陈醋","调料": "食盐","配菜": "洋葱"}}}]
觉得内容还不错的话,给我点个“在看”呗




无论您漂泊到何处
这里都是您的灵魂树洞
长按识别二维码关注我们


