




【new friends】点击标题下面蓝色字“恒生DBA公社”关注。
【old friends】点击右上角,转发或分享本页面内容。
关注福利:
关注恒生DBA公社,回复18c,即可得到Oracle 18c outline官方手册
前 言
Oracle12cR2 发布之后我们便开始关注12c带来的新特性。翻看docs.oracle.com的NewFeatures还是有比较多的新特性的。从Clusterware到Manage都有很多值得研究关注的新特性。
今天就从clusterware中的基于权重的节点驱逐这一个特性来看看。
当然,要了解12c的新特性,咱们先回顾下11g或者更低版本的集群驱逐机制。
12C之前的集群脑裂驱逐机制是怎么样的?
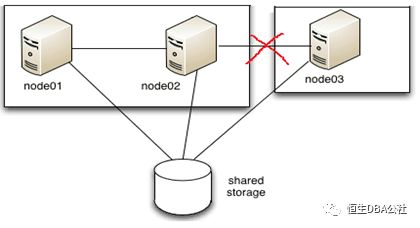
在11g或者更低版本的集群环境中。如果集群发生脑裂(Split Brain),Oracle Cluster需要对集群通过vote仲裁设备对节点驱逐以保证数据库的一致性。
一般脑裂驱逐机制遵从这样的规则;
分裂成多个子集群(subcluster)的情况下,拥有节点数据多的子集群存活
若子集群拥有的节点数一致,则拥有最低节点号的子集群存活
所以一般对于两节点的集群环境,因为心跳故障导致的脑裂基本上都是保留节点一
12c中的脑裂驱逐机制又是怎样的?
我们以常见的两节点集群来分析。
实质上,12c中默认的脑裂驱逐机制是11g是一样的。但是12c中引入了基于权重的节点驱逐(Server Weight-Based Node Eviction)。在发生脑裂的时候不会无脑地一味地驱逐节点二,而是会根据一定的权重来分析保留哪个存活的节点。这给了我们一个选择的空间。

什么是基于权重?
什么是权重?Oracle是根据哪些权重来权衡的。这是我们今天要分析的重点。
在Oracle 12.2的Newfeature Guide和Administrator Guide对这个特性是这样解释的;
由于老的驱逐机制存在,可能会在关键的脑裂时刻驱逐掉了正在运行关键应用的节点。这样对应用来说将会发生较大的一个切换代价。设置12C的权重之后Oracle将会保留负载较大的节点存活。
实质上,RAC节点发生切换上升到中间件层面上会显得比较复杂。可能会涉及到很多问题,具体可以参考前面的公众号关乎RAC节点切换及as中间件的配置文章。
你的Oracle 12C Transaction Guard已到账
所以Oracle考虑将部分权利交给人民。DBA们可以通过对节点或者对节点的具体资源配置权重(通过设置集群或集群的某个资源的CSS_CRITICAL=yes)来提高他们的权重。权重设置可以这样实现,不过有以下注意点;
权重设置生效只支持administrator-managed 管理的节点
如果设置了权重的节点从admin管理切换到policy管理权重将会失效
对于节点的权重修改需要重启集群才能生效,资源的修改则不需要重启集群
另外:
如果想将权重分配给数据库实例或者数据库的服务,可以通过srvctl add database or srvctl add service的-css_critical属性来实现。
对于已经存在的实例或服务资源使用srvctl modify同样可以修改。
对于非ora.*资源可以通过crsctl指令设置其-attr "CSS_CRITICAL=yes"实现权重分配。
如果将权重分配给某个节点,可以通过设置crsctl set server的-css_critical实现权重分配。

实践出真知
到这里只回答了第一个问题,什么是权重。但是没有说明Oracle是如何计算具体负载的,是否Oracle只是根据我们设定的CSS_CRITICAL优先级来保留存活的节点或资源呢。
我们可以先做一下简单的猜想,可能是根据哪些来计算的?操作系统负载? IO/DB AAS这些?
让我们来做下面的试验:
设置css_critical 我们将节点二集群优先级提高
[grid@12crac1 ~]$ crsctl query crs softwareversion -all Oracle Clusterware version on node [12crac1] is [12.2.0.1.0] Oracle Clusterware version on node [12crac2] is [12.2.0.1.0]
[root@12crac2 ~]# u01/grid/12.2.0/bin/crsctl set server css_critical yes CRS-4416: Server attribute 'CSS_CRITICAL' successfully changed. Restart Oracle High Availability Services for new value to take effect. [root@12crac2 ~]# /u01/grid/12.2.0/bin/crsctl stop cluster [root@12crac2 ~]# /u01/grid/12.2.0/bin/crsctl start cluster [grid@12crac2 ~]$ crsctl get server css_critical CRS-5092: Current value of the server attribute CSS_CRITICAL is yes. |
2. 尝试发生一次脑裂并收集日志查看是否驱逐过程有变化
[grid@12crac1 ~]$ oifcfg getif eth0 192.168.56.0 global public eth1 100.100.100.0 global cluster_interconnect,asm [root@12crac1 ~]# ifdown eth1
这里节点一的OS被Reboot了,有点出乎意料。按理说reboot-less的存在只会清理节点一的crs资源,除非特殊情况一般不会重启操作系统。
12c集群的日志体系和11g相比发生了较大的变化,11g的日志体系及收集方法: https://docs.oracle.com/cd/E14791_01/doc/rac.112/e10717/troubleshoot.htm
12c中是这样的 主要是将集群日志放到了ADR下 默认的位置 $ORACLE_BASE/diag/crs/host_name/crs: https://docs.oracle.com/en/database/oracle/oracle-database/12.2/cwadd/troubleshooting-oracle-clusterware.html#GUID-75A99456-75D1-4BC8-B0D8-9F353EB51B7C
尝试使用tfa收集12c的日志信息: https://docs.oracle.com/en/database/oracle/oracle-database/12.2/atnms/managing-configuring-tfa.html#GUID-E52F3ADB-B210-4135-8D7D-D9A10FF8665B
[root@12crac1 grid]# tfactl print hosts Host Name : 12crac1 Host Name : 12crac2
[root@12crac1 grid]# tfactl diagcollect -since 1h
|
3. 分析日志查看线索 帮节点二打胜了第一仗
==> 在发生心跳超时timeout之后,集群日志便明确指出由于心跳问题需要驱逐节点一本节点。说明在超时期间Oracle已经做出决定了。 2018-04-11 12:52:54.432 [OCSSD(23382)]CRS-1611: Network communication with node 12crac2 (2) missing for 75% of timeout interval. Removal of this node from cluster in 7.380 seconds 2018-04-11 12:52:59.435 [OCSSD(23382)]CRS-1610: Network communication with node 12crac2 (2) missing for 90% of timeout interval. Removal of this node from cluster in 2.370 seconds 2018-04-11 12:53:02.861 [OCSSD(23382)]CRS-1609: This node is unable to communicate with other nodes in the cluster and is going down to preserve cluster integrity; details at (:CSSNM00008:) in u01/grid/grid/diag/crs/12crac1/crs/trace/ocssd.trc.
2018-04-11 12:53:02.861 [OCSSD(23382)]CRS-1656: The CSS daemon is terminating due to a fatal error; Details at (:CSSSC00012:) in /u01/grid/grid/diag/crs/12crac1/crs/trace/ocssd.trc
==> 尝试清理crs 释放资源 2018-04-11 12:53:02.953 [OCSSD(23382)]CRS-1652: Starting clean up of CRSD resources.
==> 明确指出当前节点被节点二驱逐 2018-04-11 12:53:06.130 [OCSSD(23382)]CRS-1608: This node was evicted by node 2, 12crac2; details at (:CSSNM00005:) in u01/grid/grid/diag/crs/12crac1/crs/trace/ocssd.trc.
==> 下面出现了css 超时无响应系统被重启,这里先不深究为何reboot less没有生效 2018-04-11 12:53:17.677 [CSSDAGENT(23359)]CRS-1661: The CSS daemon is not responding. Reboot will occur in 13430 milliseconds; Details at (:CLSN00111:) in /u01/grid/grid/diag/crs/12crac1/crs/trace/ohasd_cssdagent_root.trc 2018-04-11 12:53:17.726 [CSSDMONITOR(23332)]CRS-1661: The CSS daemon is not responding. Reboot will occur in 13430 milliseconds; Details at (:CLSN00111:) in /u01/grid/grid/diag/crs/12crac1/crs/trace/ohasd_cssdmonitor_root.trc 2018-04-11 12:53:23.878 [CSSDAGENT(23359)]CRS-1661: The CSS daemon is not responding. Reboot will occur in 7110 milliseconds; Details at (:CLSN00111:) in /u01/grid/grid/diag/crs/12crac1/crs/trace/ohasd_cssdagent_root.trc 2018-04-11 12:53:23.898 [CSSDMONITOR(23332)]CRS-1661: The CSS daemon is not responding. Reboot will occur in 7110 milliseconds; Details at (:CLSN00111:) in /u01/grid/grid/diag/crs/12crac1/crs/trace/ohasd_cssdmonitor_root.trc 2018-04-11 12:53:28.788 [CSSDAGENT(23359)]CRS-1661: The CSS daemon is not responding. Reboot will occur in 2800 milliseconds; Details at (:CLSN00111:) in /u01/grid/grid/diag/crs/12crac1/crs/trace/ohasd_cssdagent_root.trc 2018-04-11 12:53:28.904 [CSSDMONITOR(23332)]CRS-1661: The CSS daemon is not responding. Reboot will occur in 2800 milliseconds; Details at (:CLSN00111:) in /u01/grid/grid/diag/crs/12crac1/crs/trace/ohasd_cssdmonitor_root.trc 2018-04-11 12:53:30.547 [OCSSD(23382)]CRS-1604: CSSD voting file is offline: AFD:CRSDG1; details at (:CSSNM00058:) in u01/grid/grid/diag/crs/12crac1/crs/trace/ocssd.trc. 2018-04-11 12:53:30.565 [OCSSD(23382)]CRS-1605: CSSD voting file is online: AFD:CRSDG1; details in u01/grid/grid/diag/crs/12crac1/crs/trace/ocssd.trc.
==>节点一的ocssd.log显示在脑裂投票期间通过检查和对比weight clssnmrCheckNodeWeight/clssnmCompareNodeWeights最终得到当前节点的cohort为1,节点二的cohort为2. Cohort为2的节点存活。可以看出来节点一被驱逐是因为weight不够大导致的。 ##ocssd1.trc 2018-04-11 12:53:02.808 : CSSD:4054488832: clssnmrCheckSplit: Waiting for node weights, stamp(418912308) 2018-04-11 12:53:02.861 : CSSD:4060796672: clssnmvDHBValidateNCopy: node 2, 12crac2, has a disk HB, but no network HB, DHB has rcfg 418912309, wrtcnt, 1000869, LATS 6654714, lastSeqNo 1000868, uniqueness 1523417494, timestamp 1523422382/14119414 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmrCheckNodeWeight: node(1) has weight stamp(418912308) pebbles (0) goldstars (0) flags (3) SpoolVersion (0) 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmrCheckNodeWeight: node(2) has weight stamp(418912308) pebbles (0) goldstars (1) flags (3) SpoolVersion (0) 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmrCheckNodeWeight: Server pool version not consistent 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmrCheckNodeWeight: stamp(418912308), completed(2/2) 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmCompareNodeWeights: count(1), low(1), bestcount(0), best_low(65535), cur_weight: pebbles(0) goldstars(0) pubnw(1) flexasm(1)best_weight: pebbles(0) goldstars(0)pubnw(0) flexasm(0) 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmFindBestMap: Using base map(2) of node(1) count(1), low(1), bestcount(1), best_low(1), cur_weightpebbles (0) goldstars (0) flags (3) SpoolVersion (0)best_weightpebbles (0) goldstars (0) flags (3) SpoolVersion (0) 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmCompareNodeWeights: count(1), low(2), bestcount(1), best_low(1), cur_weight: pebbles(0) goldstars(1) pubnw(1) flexasm(1)best_weight: pebbles(0) goldstars(0)pubnw(1) flexasm(1) 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmFindBestMap: Using base map(2) of node(2) count(1), low(2), bestcount(1), best_low(2), cur_weightpebbles (0) goldstars (1) flags (3) SpoolVersion (0)best_weightpebbles (0) goldstars (1) flags (3) SpoolVersion (0) 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmCheckDskInfo: My cohort: 1 2018-04-11 12:53:02.861 : CSSD:4054488832: clssnmCheckDskInfo: Surviving cohort: 2
==>节点二做同样的对比工作最终确定自动的cohort大于节点一进而发起驱逐 ##ocssd2.trc 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmCheckSplit: nodenum 1 curts_ms 14118964 readts_ms 14118964 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmCheckSplit: Node 1, 12crac1, is alive, DHB (1523422382, 6653974) more than disk timeout of 27000 after the last NHB (1523422352, 6624174) 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmrCheckNodeWeight: node(1) has weight stamp(418912308) pebbles (0) goldstars (0) flags (3) SpoolVersion (0) 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmrCheckNodeWeight: node(2) has weight stamp(418912308) pebbles (0) goldstars (1) flags (3) SpoolVersion (0) 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmrCheckNodeWeight: Server pool version not consistent 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmrCheckNodeWeight: stamp(418912308), completed(2/2)
2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmCompareNodeWeights: count(1), low(1), bestcount(0), best_low(65535), cur_weight: pebbles(0) goldstars(0) pubnw(1) flexasm(1)best_weight: pebbles(0) goldstars(0)pubnw(0) flexasm(0) 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmFindBestMap: Using base map(2) of node(1) count(1), low(1), bestcount(1), best_low(1), cur_weightpebbles (0) goldstars (0) flags (3) SpoolVersion (0)best_weightpebbles (0) goldstars (0) flags (3) SpoolVersion (0) 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmCompareNodeWeights: count(1), low(2), bestcount(1), best_low(1), cur_weight: pebbles(0) goldstars(1) pubnw(1) flexasm(1)best_weight: pebbles(0) goldstars(0)pubnw(1) flexasm(1) 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmFindBestMap: Using base map(2) of node(2) count(1), low(2), bestcount(1), best_low(2), cur_weightpebbles (0) goldstars (1) flags (3) SpoolVersion (0)best_weightpebbles (0) goldstars (1) flags (3) SpoolVersion (0) 2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmCheckDskInfo: My cohort: 2
2018-04-11 12:53:02.325 : CSSD:3110233856: clssnmRemove: Start 2018-04-11 12:53:02.325 : CSSD:3110233856: (:CSSNM00007:)clssnmrRemoveNode: Evicting node 1, 12crac1, from the cluster in incarnation 418912309, node birth incarnation 418912308, death incarnation 418912309, stateflags 0x224000 uniqueness value 1523417494 |
4. 恢复节点二的权重提高节点一的权重增加节点二的负载
交换节点一和节点二的权重。给节点二增加较为明显的数据库压力,然后发生脑裂。观察是否依然会保留权重高的节点一。即使节点权重低的节点二处于较高的load。
[root@12crac2 log]# crsctl set server css_critical no [root@12crac1 grid]# crsctl set server css_critical yes
通过Swingbench 一个免费的压力工具模拟节点二较高的AAS。模拟过程略过,可以直接起windows的界面也可以调用linux的脚本模拟。
这次是节点二被驱逐,看来即使节点在脑裂期间有较高的load。也会因为weight低而被驱逐掉。 2018-04-11 15:15:35.122 : CSSD:1480664832: clssnmvDHBValidateNCopy: node 1, 12crac1, has a disk HB, but no network HB, DHB has rcfg 418920976, wrtcnt, 1655848, LATS 22670464, lastSeqNo 1655847, uniqueness 1523426160, timestamp 1523430935/7555164 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmrCheckNodeWeight: node(1) has weight stamp(418920975) pebbles (0) goldstars (1) flags (3) SpoolVersion (0) 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmrCheckNodeWeight: node(2) has weight stamp(418920975) pebbles (0) goldstars (0) flags (3) SpoolVersion (0) 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmrCheckNodeWeight: Server pool version not consistent 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmrCheckNodeWeight: stamp(418920975), completed(2/2) 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmCompareNodeWeights: count(1), low(1), bestcount(0), best_low(65535), cur_weight: pebbles(0) goldstars(1) pubnw(1) flexasm(1)best_weight: pebbles(0) goldstars(0)pubnw(0) flexasm(0) 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmFindBestMap: Using base map(2) of node(1) count(1), low(1), bestcount(1), best_low(1), cur_weightpebbles (0) goldstars (1) flags (3) SpoolVersion (0)best_weightpebbles (0) goldstars (1) flags (3) SpoolVersion (0) 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmCompareNodeWeights: count(1), low(2), bestcount(1), best_low(1), cur_weight: pebbles(0) goldstars(0) pubnw(1) flexasm(1)best_weight: pebbles(0) goldstars(1)pubnw(1) flexasm(1) 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmFindBestMap: Using base map(2) of node(2) count(1), low(2), bestcount(1), best_low(1), cur_weightpebbles (0) goldstars (0) flags (0) SpoolVersion (0)best_weightpebbles (0) goldstars (1) flags (3) SpoolVersion (0) 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmCheckDskInfo: My cohort: 2 2018-04-11 15:15:35.122 : CSSD:992986880: clssnmCheckDskInfo: Surviving cohort: 1 |
5. 我们做一下最后的挣扎 创建一个rac服务weightsvcv 在节点二的weight提高
在目前的权重配置下,将节点二的weightsvcv service 的权重提高。
那么现状将会变成节点一的server权重高于节点的server。节点二的service权重高于节点一的。我们再次测试节点二拥有较高load的情况下发生脑裂时的节点驱逐情况。这次依然是节点二被驱逐掉。
[oracle@12crac1 ~]$ srvctl add service -db racdb -service weightsvc -preferred racdb1 -available racdb2 -tafpolicy PRECONNECT -policy automatic -failovertype SELECT
[root@12crac2 ~]# srvctl modify service -db racdb -service weightsvc -css_critical yes [root@12crac2 ~]# srvctl start service -db racdb -service weightsvc
|

总结
经过几轮测试发现,Oracle的权重驱逐机制好像只认设置了权重的级别节点,而不管系统的负载情况。
最后一轮的测试还可以接着做。比如
将节点一的server权重去除,只保留service服务的权重,
去除节点二的服务权重转而提升节点一的服务权重。
应该是什么样的情况呢,猜测依然负载较低但是具有较高service服务权重的节点存活。
那么这个特性到底该如何发挥其作用呢?
其实很多客户在部署应用的时候都将重要的节点部署在了节点一上。因为脑裂都会驱逐节点二,这样减少了中间件切换的故障。
也许这个特性只是为了给维护一个更加灵活的空间,可能在特殊情况下。比如节点的负载因为应用的突然变化突然变得重要起来。那么可以考虑设置一下节点或者相关资源的权重。
不想走丢的话,请关注公众号 恒生DBA公社:hs_dba

