




本文基于Mysql5.7版本和InnoDB存储引擎。
1、InnoDB索引组织表
该表如果有非空唯一索引,则该列为主键;如果有多个,则取第一个;
如果没有非空唯一索引,则InnoDB自动创建一个大小为6字节的指针作为主键;
为什么推荐使用自增ID做主键而不是UUID?
这是由于B+树的性质决定的,UUID无序,占用空间大,每(磁盘)页能存放的索引少,这会导致磁盘IO次数增加,效率变慢;
什么是堆表?
与索引组织表相对应,堆表是按照行数据的插入顺序存放,无组织,在某些情况下,堆表比索引组织表更快;
2、索引原理
2.1、什么是索引?
索引是一个单独的、存储在磁盘上的数据库结构。
InnoDB支持B+树索引;B+树索引由于一个结点存储的是一个磁盘页的数据,因此只能先找到被查找数据所在的页,然后将页读进内存中,最后再在内存中查找;
关于B+树数据结构的相关知识请看 什么是B-树、B树、B+树、B*树?
2.2、B+树索引分类
聚集(主键)索引
辅助(非聚集、二级)索引
普通索引
唯一索引
联合索引
聚集索引和主键索引的相同点:
叶子结点存放所有数据(这是由B+树的性质所决定的);
不同点:
聚集索引的叶子结点存放一整行数据,而辅助索引的叶子结点只存放该列数据和主键;
2.3、联合索引原理
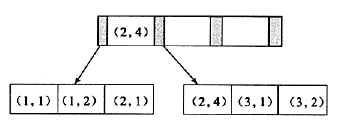
如上图所示,联合索引的结点以(a列的值,b列的值)形式存储。
下面看看如何使用联合索引进行查询:
select * from tb1 where a=? and b=?,走联合索引,因为a和b在一起是排序的;
select * from tb1 where a=?,走联合索引,因为单独的a是排序的;
select * from tb1 where b=?,不走联合索引,因为单独的b不是排序的,如上图,b的顺序为1,2,1,4,1,2;
联合索引的好处:
首先,a列和b列都是排好序的;比如我要查询用户最近三次的购买记录,可以使用user_id作为索引,也可以使用(user_id,buy_date)的联合索引;如果使用user_id作为索引,则需要将查询出来的结果再按buy_date进行一次排序,才能查出最近三次的购买记录;而联合索引已经将buy_date排好序了,只需要取最后三条数据,就是用户最新三次的购买记录;
2.4、什么是覆盖索引?
优化器一般会倾向于使用覆盖索引而不是聚集索引,因为聚集索引占用空间大,磁盘IO次数多;
联合索引可以当做覆盖索引使用。对于联合索引(a,b)而言,使用b作为查询条件则不走索引,但是如果此时没有针对b的索引,且要查询的列该联合索引都有,则优化器会将该联合索引视作覆盖索引(联合索引上单独的b是无序的,所以是从头到尾顺序查找,尽管如此也比在聚集索引上顺序查找效率高),explain的Extra中有Using index就表明使用了覆盖索引;
2.5、操作索引
查看某个表的索引:show index from 表名
下面解释一下各字段的意思:
Table:索引所在表名;
Non_unique:值为0表示唯一;
Key_name:索引名称;
Seq_in_index:索引中该列的位置;
Column:索引中列的名称;
Collation:列以什么方式存储在索引中,值为A或NULL,B+树索引总是A,即排序的;
Cardinality:表示该列中唯一值数目的估计值。如果该值非常小,则表示该列重复数据较多;为什么是估计值呢?因为该值不是实时更新的(代价太大),可以用analyze table命令手动更新一次Cardinality值;
Sub_part:是否只对列的一部分索引;比如某个列类型为varchar(1000),可以设置只索引该列的前100个字符,则Sub_part的值为100,如果索引的是列的全部,则Sub_part为NULL;
Packed:关键字如何被压缩。如果没有被压缩则为NULL;
Null:该列是否允许有NULL值;
Index_type:索引类型;
在select语句中使用force index(index_name)强制使用某个索引,而user index(index_name)则提示使用某个索引。
3、性能优化
查看sql的执行计划:explain select ...
下面简要介绍一下各字段的意思,详细解释请查阅Mysql5.7官方文档:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
id:select的查询序列号
select_type:查询类型
simple:简单查询,不包括连接查询和子查询
primary:主要的查询,最外层的查询
subquery:子查询
table:表示查询的表
partitions:命中的分区,如果是非分区表则为NULL
type:表的连接类型
const:只返回一行数据,查询速度很快,该列具有唯一索引或主键索引;如果是普通索引,即时真的只返回一行数据,也不会是const;
range:范围查询;
index:根据辅助索引全表扫描;
ALL:无索引(聚集索引)全表扫描;
possible_keys:通过检测where子句获得可用的索引;
key:实际使用的索引;
rows:显示Mysql在表中进行查询时必须检查的行数;
extra:表示Mysql在处理查询时的详细信息;
3.2、索引设计原则
索引优点:
唯一索引可以保证唯一性;
加快速度:查询速度、表与表连接速度、分组和排序的速度;
缺点:
索引需要占用磁盘空间;
索引的维护(增删改)需要时间,尤其是数据量大的时候;
索引设计原则:
索引并非越多越好,索引太多会影响insert、update、delete的性能;
经常更新的列不使用索引,经常查询(逻辑外键、where子句、group by子句、order by子句)的列使用索引;
数据量小的表不使用索引;
重复值很多的列不使用索引;
删除长期未使用的索引,不用的索引会造成不必要的性能消耗;
避免使用冗余索引:如(name,city)和(name)就是冗余索引,因此一般应该扩展已有的索引,而不是创建新的索引;
3.3、索引失效的情况
这是因为b+树只能对原值进行索引。
假设订单表有1000万数据,订单号为null有100条,分析如下三条sql语句:
explain select order_num from goods_order where order_num ='f035a84a-4672-4517-bd8a-2c9f2d92423e'
explain select order_num from goods_order where order_num is null
explain select order_num from goods_order where order_num is not null
通过执行结果发现,只有is not null不走索引。
使用in不走索引,用exists代替,如果是连续的数值则可以用between代替。
select a.* from bigtable a inner join (select id from bigtable LIMIT 6520000,10) b on a.id=b.id
最后看一下下面这种情况:
比如select * from order where order_id>10000 and order_id<20000,注意order_id不是主键,此时有一个辅助索引order_id,由于该索引上不包含所有的字段(注意是select *),因此还要回表。通过order_id找到的对应主键是无序的,所以回表的过程是磁盘离散读,而磁盘顺序读的速度是远大于离散读的(固态硬盘的随机读速度非常快),特别是数据量大的情况下差异更明显,这时会优化器会放弃辅助索引而走全表扫描。
总体来说,优化器选择走不走索引,也不是千篇一律的,有时候也要看实际情况。对于我们而言,要熟练使用explain查看sql执行计划,在实际项目中分析sql性能的瓶颈,进行优化。
