




执行计划中统计信息分析
1、recursive calls
我们知道在很多情况下会产生recursive calls(递归调用),比如做一些操作的分配空间,执行ddl,或者触发trigger,或者在解析的时候数据字典缓存需要一些对象的信息。这里只看select 的情况,因此本例中可以认为主要是因为需要数据字典信息,解析和分配空间导致了递归调用的产生。
SQL> alter system flush shared_pool;
System altered.
SQL> alter system flush buffer_cache;
System altered.
SQL> set timing on
SQL> set autotrace traceonly
SQL> select * from tmp_a where object_id='240';
16 rows selected.
Elapsed: 00:00:00.03
Execution Plan
----------------------------------------------------------
Plan hash value: 761549492
--------------------------------------------------------------------------------
--------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
me |
--------------------------------------------------------------------------------
--------
| 0 | SELECT STATEMENT | | 16 | 3312 | 18 (0)| 00
:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TMP_A | 16 | 3312 | 18 (0)| 00
:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TMPA | 16 | | 3 (0)| 00
:00:01 |
--------------------------------------------------------------------------------
--------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=240)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
82 recursive calls
0 db block gets
179 consistent gets
339 physical reads
0 redo size
3059 bytes sent via SQL*Net to client
530 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
16 rows processed
多执行几次,让recursive calls 和physical reads 都变为零,即完全从内存中读取
SQL>
16 rows selected.
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 761549492
--------------------------------------------------------------------------------
--------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
me |
--------------------------------------------------------------------------------
--------
| 0 | SELECT STATEMENT | | 16 | 3312 | 18 (0)| 00
:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TMP_A | 16 | 3312 | 18 (0)| 00
:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TMPA | 16 | | 3 (0)| 00
:00:01 |
--------------------------------------------------------------------------------
--------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=240)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
21 consistent gets
0 physical reads
0 redo size
3059 bytes sent via SQL*Net to client
530 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
16 rows processed
可以看到至少需要21个逻辑读,或者21个读block 操作。
consistent gets从原来的179变为21个
recursive calls为递归调用从82变为了0,shared_pool 的作用就体现出来了,是存放解析过得sql的,温习一下:
SGA&PGA
(1)SGA:System Global Area是Oracle Instance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。
(2)共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义,主要包括:Library cache(共享SQL区)和Data dictionary cache(数据字典缓冲区)。 共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。
(3)缓冲区高速缓存:Database Buffer Cache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能。
(4)大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server环境。
(5)Java池:Java Pool为Java命令的语法分析提供服务。
(6)PGA:Process Global Area是为每个连接到Oracle database的用户进程保留的内存。 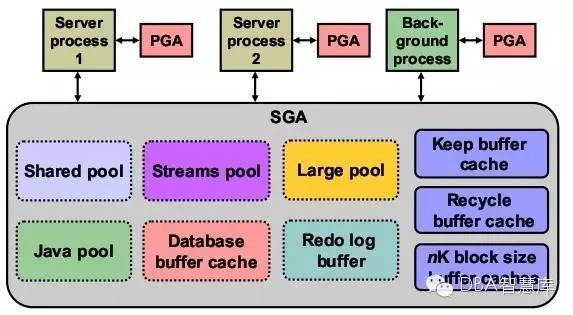
再次清除shared_pool,shared_pool 的作用就体现的更清楚了
SQL> alter system flush shared_pool;
System altered.
Elapsed: 00:00:00.02
SQL> select * from tmp_a where object_id='240';
16 rows selected.
Elapsed: 00:00:00.03
Execution Plan
----------------------------------------------------------
Plan hash value: 761549492
--------------------------------------------------------------------------------
--------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
me |
--------------------------------------------------------------------------------
--------
| 0 | SELECT STATEMENT | | 16 | 3312 | 18 (0)| 00
:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TMP_A | 16 | 3312 | 18 (0)| 00
:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TMPA | 16 | | 3 (0)| 00
:00:01 |
--------------------------------------------------------------------------------
--------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=240)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
111 recursive calls
0 db block gets
254 consistent gets
0 physical reads
0 redo size
3059 bytes sent via SQL*Net to client
530 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
10 sorts (memory)
0 sorts (disk)
16 rows processed
recursive calls和consistent gets都增多了,再次执行:
SQL>
16 rows selected.
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 761549492
--------------------------------------------------------------------------------
--------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
me |
--------------------------------------------------------------------------------
--------
| 0 | SELECT STATEMENT | | 16 | 3312 | 18 (0)| 00
:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TMP_A | 16 | 3312 | 18 (0)| 00
:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TMPA | 16 | | 3 (0)| 00
:00:01 |
--------------------------------------------------------------------------------
--------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=240)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
21 consistent gets
0 physical reads
0 redo size
3059 bytes sent via SQL*Net to client
530 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
16 rows processed
recursive calls又变为了0,consistent gets又变为了21
2、DB Block Gets(当前请求的块数目)
当前模式块意思就是在操作中正好提取的块数目,而不是在一致性读的情况下而产生的块数。正常的情况下,一个查询提取的块是在查询开始的那个时间点上存在的数据块,当前块是在这个时刻存在的数据块,而不是在这个时间点之前或者之后的数据块数目。
3、Consistent Gets(数据请求总数在回滚段Buffer中的数据一致性读所需要的数据块)
这 里的概念是在处理你这个操作的时候需要在一致性读状态上处理多少个块,这些块产生的主要原因是因为由于在你查询的过程中,由于其他会话对数据块进行操作, 而对所要查询的块有了修改,但是由于我们的查询是在这些修改之前调用的,所以需要对回滚段中的数据块的前映像进行查询,以保证数据的一致性。这样就产生了一致性读。
在一致性模式下所读的块数。consistent_gets 是从回滚段中读到的前映(或叫读取一致性影象), 看见的数据是查询开始的时间点的,所以若存在 block 在查询开始后发生了变化的情况,则必须产生 before image 然后读数据.
可以认为一致性读就是从 databuffer 中读取的次数.
Buffer_pool是存放数据的内存,现在清除buffer_pool会怎么样?
SQL> alter system flush buffer_cache;
System altered.
Elapsed: 00:00:00.05
SQL> select * from tmp_a where object_id='240';
16 rows selected.
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 761549492
--------------------------------------------------------------------------------
--------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
me |
--------------------------------------------------------------------------------
--------
| 0 | SELECT STATEMENT | | 16 | 3312 | 18 (0)| 00
:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TMP_A | 16 | 3312 | 18 (0)| 00
:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TMPA | 16 | | 3 (0)| 00
:00:01 |
--------------------------------------------------------------------------------
--------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=240)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
21 consistent gets
19 physical reads
0 redo size
3059 bytes sent via SQL*Net to client
530 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
16 rows processed
清除buffer_pool后物理读又回来了。
综上所述sql执行过程是这样的:
Sql进入数据库后:
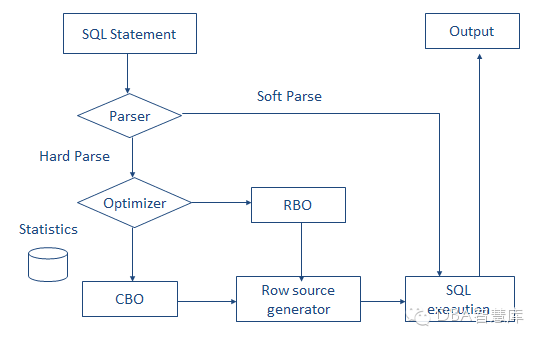
1)先判断是应解析还是软解析,主要看shared_pool里面是否有对应相同的sql,如果有就是软解析,不会产生递归调用recursive calls,如果没有就是应解析,会产生递归调用recursive calls
2)判断bufferpool中是否有要读取的数据,如果没有,就要从磁盘中读取到内存中,也就是bufferpool中,此时会产生物理读physical reads;如果bufferpool中有要读取的数据,就不会产生物理读。不过不管bufferpool中是否有要读取的数据,都会产生逻辑读
4、Physical Reads(物理读)
就是从磁盘上读取数据块的数量,其产生的主要原因是:
1、 在数据库高速缓存中不存在这些块
2、 全表扫描
3、 磁盘排序
PHYSICAL READS(物理读次数)当数据块第一次读取到,就会缓存到 buffer cache 中,而第二次读取和修改该数据块时就在内存 buffer cache 了数据块被重新读入 buffer cache ,这种发生在如果有新的数据需要被读入 Buffer Cache中,而 Buffer Cache 又没有足够的空闲空间,Oracle 就根据 LRU 算法将 LRU 链表中 LRU
端的数据置换出去。当这些数据被再次访问到时,需要重新从磁盘读入。
LOGIC IO(逻辑读次数)= db block gets + consistent gets逻辑读指的就是从(或者视图从)Buffer Cache 中读取数据块。按照访问数据块的模式不同,可以分为即时读(Current Read)和一致性读(Consistent Read)。注意:逻辑 IO只有逻辑读,没有逻辑写。
============================逻辑读和物理读===========================
对于全表扫描一个表获取全部行产生的一致性读的一个计算公式:
consistent gets=numrows/arraysize + blocks
=============================arraysize 解释============================
arraysize 定义了一次返回到客户端的行数,当扫描了 arraysize 行后,停止扫描,返回数据,然后继续扫描。
这个过程就是统计信息中的 SQL*Net roundtrips to/from client。因为 arraysize 默认是15行,那么就有一个问题,因为我们一个 block 中的记录数一般都会超过15行,所以如果按照15行扫描一次,那么每次扫描要多扫描一个数据块,一个数据块也可能就会重复扫描多次。
重复的扫描会增加 consistent gets 和 physical reads。增加 physical reads,这个很好理解,扫描的越多,物理的可能性就越大。
consistent gets,这个是从 undo 里读的数量,Oracle 为了保证数据的一致性,当一个查询很长,在查询之后,数据块被修改,还未提交,再次查询时候,Oracle 根据 Undo 来构建 CR 块,这个 CR 块,可以理解成数据块在之前某个时间的状态。这样通过查询出来的数据就是一致的。
那么如果重复扫描的块越多,需要构建的 CR 块就会越多,这样读 Undo 的机会就会越多,consistent gets 就会越多。
如果数据每次传到客户端有中断,那么这些数据会重新扫描,这样也就增加逻辑读,所以调整 arraysize 可以减少传的次数,减少逻辑读。
所以通过上面的说明,arraysize 参数如果过低,会影响如 physical reads,consistentgets 还有 SQL*Net roundtrips to/from client 次数。
永久保存 arraysize 参数:
-- 查看默认值
SYS@anqing2(rac2)> show arraysize
arraysize 15
--手工修改 arraysize
SYS@anqing2(rac2)> set arraysize 100
SYS@anqing2(rac2)> show arraysize
arraysize 100
