




注:本文是前段时间在搞普罗米修斯监控时,也关注了解了下InfluxDB数据库,并在团队内部做了分享。
如要下载该文档,可链接 https://www.modb.pro/doc/90676 进行下载。
文章不足之处还望多指正。
安装数据库
1.1. influxDB介绍
InfluxDB是一个用于存储和分析时间序列数据的开源数据库
一、InfluxDB 简介
InfluxDB 是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。
类似的数据库有Elasticsearch、Graphite等。
其主要特色功能
- 基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等)
- 可度量性:你可以实时对大量数据进行计算
- 基于事件:它支持任意的事件数据
二、InfluxDB的主要特点 - 无结构(无模式):可以是任意数量的列
- 可拓展的
- 支持min, max, sum, count, mean, median 等一系列函数,方便统计
- 原生的HTTP支持,内置HTTP API
- 强大的类SQL语法
- 自带管理界面,方便使用
主要特性有:
内置HTTP接口,使用方便
数据可以打标记,这样查询可以很灵活
类SQL的查询语句
安装管理很简单,并且读写数据很高效
能够实时查询,数据在写入时被索引后就能够被立即查出
网络
InfluxDB默认使用下面的网络端口:
TCP端口8086用作InfluxDB的客户端和服务端的http api通信
TCP端口8088给备份和恢复数据的RPC服务使用
另外,InfluxDB也提供了多个可能需要自定义端口的插件,所以的端口映射都可以通过配置文件修改,对于默认安装的InfluxDB,这个配置文件位于/etc/influxdb/influxdb.conf。
NTP
InfluxDB使用服务器本地时间给数据加时间戳,而且是UTC时区的。并使用NTP来同步服务器之间的时间,如果服务器的时钟没有通过NTP同步,那么写入InfluxDB的数据的时间戳就可能不准确。
1.2. influxDB安装
influxdb 1.1版本之前提供WEB访问界面,之后的版本不再提供WEB访问界面
influxdb 1.1版本前WEB界面端口为8083,可通过如下方式访问WEB界面
http://IP:8083

可通过如下方式安装:
RedHat & CentOS (64-bit)
wget https://dl.influxdata.com/influxdb/releases/influxdb-0.13.0.x86_64.rpm
sudo yum localinstall influxdb-0.13.0.x86_64.rpm
MD5: 286b6c18aa4ef37225ea6605a729b61d
##本次以在centos & redhat操作系统上安装为例
RedHat & CentOS
RedHat和CentOS用户可以直接用yum包管理来安装最新版本的InfluxDB。
cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxDB Repository - RHEL $releasever
baseurl = https://repos.influxdata.com/rhel/$releasever/$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
EOF
一旦加到了yum源里面,就可以运行下面的命令来安装和启动InfluxDB服务:
sudo yum install influxdb
sudo service influxdb start
如果你的系统可以使用Systemd(比如CentOS 7+, RHEL 7+),也可以这样启动:
sudo yum install influxdb
sudo systemctl start influxdb
配置
安装好之后,每个配置文件都有了默认的配置,你可以通过命令influxd config来查看这些默认配置。
/usr/bin/influxd config
在配置文件/etc/influxdb/influxdb.conf之中的大部分配置都被注释掉了,所有这些被注释掉的配置都是由内部默认值决定的。配置文件里任意没有注释的配置都可以用来覆盖内部默认值,需要注意的是,本地配置文件不需要包括每一项配置。
有两种方法可以用自定义的配置文件来运行InfluxDB:
运行的时候通过可选参数-config来指定:
influxd -config /etc/influxdb/influxdb.conf
设置环境变量INFLUXDB_CONFIG_PATH来指定,例如:
echo $INFLUXDB_CONFIG_PATH
/etc/influxdb/influxdb.conf
influxd
其中-config的优先级高于环境变量
2. InfluxDB基本概念
InfluxDB与传统数据库在概念上有许多不同之处。
一、与传统数据库中的名词做比较
二、InfluxDB中独有的概念
-
Point
Point由时间戳(time)、数据(field)、标签(tags)组成。
Point相当于传统数据库里的一行数据,如下表所示: -
series
所有在数据库中的数据,都需要通过图表来展示,而这个series表示这个表里面的数据,可以在图表上画成几条线:通过tags排列组合算出来。
- InfluxDB基本操作
一、InfluxDB操作方式
InfluxDB提供三种操作方式:
- 客户端命令行方式
- HTTP API接口
- 各语言API库
二、InfluxDB数据库操作
如同MYSQL一样,InfluxDB提供多数据库支持,对数据库的操作也与MYSQL相同。 - 显示数据库:
show databases; - 新建数据库
create database test
show databases - 删除数据库
drop database test - 使用数据库
use test
三、InfluxDB数据表操作
在InfluxDB当中,并没有表(table)这个概念,取而代之的是MEASUREMENTS,MEASUREMENTS的功能与传统数据库中的表一致,因此我们也可以将MEASUREMENTS称为InfluxDB中的表。
1)显示所有的表:
show measurements
2)新建表:
influxDB中没有显示的新建表的语句,只能通过insert数据的方式来建立新表,如下所示
insert disk_free,hostname=server01 value=442221834240i 1435362189575692182
其中disk_free就是表名,hostname是索引,value=xx是记录值,记录值可以有多个,最后是指定的时间。
3)删除表:
drop measurement table_name
四、数据操作
1)增加数据
增加数据采用insert的方式,要注意的是 InfluxDB的insert中,表名与数据之间用逗号(,)分隔,tag和field之间用 空格分隔,多个tag或者多个field之间用逗号(,)分隔。
2)查询数据
查询数据和普通SQL一样
3)修改和删除数据
influxDB属于时序数据库,没有提供修改和删除数据的方法,但可以通过influxDB的保存策略(retention policies)来实现。
五、series操作
series表示这个表里的数据,可以在图表上画几条线,series主要通过tags排列组合算出来。
- InfluxDB的HTTP API写入操作
HTTP API可以执行写入和查询操作。
##此处使用curl来模拟发起http请求
一、InfluxDB通过HTTP API操作数据库
- 建立数据库
如:curl -POST http://localhost:8086/query --data-urlencode “q=CREATE DATABASE mydb”
执行这个语句后,会在本地建立一个名为mydb的数据库 - 删除数据库
curl -POST http://localhost:8086/query --data-urlencode “q=DROP DATABASE mydb”
其实使用HTTP API就是向 InfluxDB 接口发送相应的POST请求。
将语句通过POST方式发送到服务器
二、InfluxDB通过HTTP API添加数据
说明:db=mydb是指使用mydb这个数据库。
–data-binary后面是需插入数据。
cpu_load_short是表名(measurement),tag字段是host和region,值分别为:server01和us-west。
field key字段是value,值为0.64。
时间戳(timestamp)指定为1434055562000000000。
这样,就向mydb数据库的cpu_load_short表中插入了一条数据。
其中,db参数必须指定一个数据库中已经存在的数据库名,数据体的格式遵从InfluxDB规定格式,首先是表名,后面是tags,然后是field,最后是时间戳。tags、field和时间戳三者之间以空格相分隔。
三、InfluxDB通过HTTP API添加多条数据
InfluxDB通过HTTP API添加多条数据与添加单条数据相似,示例如下:
curl -i -XPOST ‘http://localhost:8086/write?db=mydb’ --data-binary ‘cpu_load_short,host=server02 value=0.67
cpu_load_short,host=server02,region=us-west value=0.55 1422568543702900257
cpu_load_short,direction=in,host=server01,region=us-west value=2.0 1422568543702900257’
四、InfluxDB 的HTTP API响应
在使用HTTP API时,InfluxDB的响应主要有以下几个: - 2xx:204代表no content,200代表InfluxDB可以接收请求但是没有完成请求。一般会在body体中带有出错信息。
- 4xx:InfluxDB不能解析请求。
- 5xx:系统出现错误。
- InfluxDB数据保留策略
InfluxDB每秒可以处理成千上万条数据,要将这些数据全部保存下来会占用大量的存储空间,有时我们可能并不需要将所有历史数据进行存储,因此,InfluxDB推出了数据保留策略(Retention Policies),用来让我们自定义数据的保留时间。
influxDB提供了两个特性——连续查询(Continuous Queries简称CQ)和保留策略(Retention Policies简称RP),分别用来处理数据采样和管理老数据。
Continuous Query (CQ)是在数据库内部自动周期性跑着的一个influxQL的查询,CQs需要在SELECT语句中使用一个函数,并且一定包括一个GROUP BY time()语句。
Retention Policy (RP)是influxDB数据架构的一部分,它描述了InfluxDB保存数据的时间。influxDB会比较服务器本地的时间戳和请求数据里的时间戳,并删除比你在RPs里面用DURATION设置的更老的数据。一个数据库中可以有多个RPs但是每个数据库的RPs是唯一的。
一、InfluxDB 数据保留策略 说明
InfluxDB的数据保留策略(RP) 用来定义数据在InfluxDB中存放的时间,或者定义保存某个期间的数据。
一个数据库可以有多个保留策略,但每个策略必须是独一无二的。
二、InfluxDB 数据保留策略 目的
InfluxDB本身不提供数据的删除操作,因此用来控制数据量的方式就是定义数据保留策略。
因此定义数据保留策略的目的是让InfluxDB能够知道可以丢弃哪些数据,从而更高效的处理数据。
三、InfluxDB 数据保留策略 操作
- 查询策略
可通过如下语句查看数据库现有策略:
show retention policies on mydb
从上看到当前mydb只有一个策略,各字段含义如下:
name–名称,此示例名称为 default
duration–持续时间,0代表无限制
shardGroupDuration–shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构,应该大于这个时间的数据在查询效率上应该有所降低。
replicaN–全称是REPLICATION,副本个数
default–是否是默认策略

- 新建策略
CREATE RETENTION POLICY “2_hours” ON “mydb” DURATION 2h REPLICATION 1 DEFAULT
show retention policies on mydb
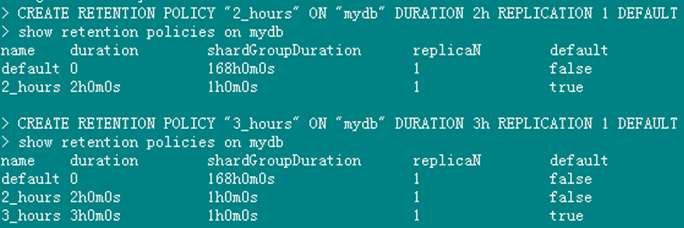
通过上面的语句可以添加策略,本例在mydb 库添加了一个2小时的策略,名字叫做 3_hours, duration为3小时,副本为1,设置为默认策略。
如果重新创建一个策略,并设置为默认策略,之前的默认策略就会失效。
3) 修改策略
使用如下语句修改策略
alter retention policy “2_hours” on “mydb” duration 4h default
show retention policies on mydb
4)删除策略
InfluxDB中策略的删除操作如下:
drop retention policy “3_hours” on “mydb”
show retention policies on mydb
从上可看到名为3_hours的策略已被删除。
从上面图片可看到当删除一个默认策略后,数据库会默认保留一个策略,会将其中一个策略设置为默认策略。


- 新建连续查询
新建连续查询的语法如下所示:
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
[RESAMPLE [EVERY] [FOR ]]
BEGIN SELECT( )[, ( )] INTO <different_measurement>
FROM <current_measurement> [WHERE] GROUP BY time( )[, ]
END
如下所示:
create continuous query cq_30m on mydb begin select mean(value) into cpu_used_30m from mem group by time(30m) end
show continuous queries
示例在mydb库中新建了一个名为 cq_30m 的连续查询,每三十分钟取一个value字段的平均值,加入cpu_used_30m 表中。使用的数据保留策略都是 default。
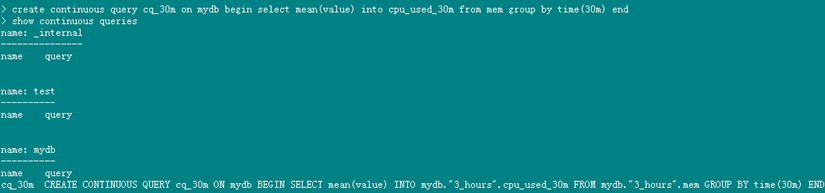
- 显示所有已存在的连续查询
show continuous queries
可以看到连续查询的名称及对应查询语句。
- 删除查询策略
删除连续查询的语句如下:
DROP CONTINUOUS QUERY <cq_name> ON <database_name>
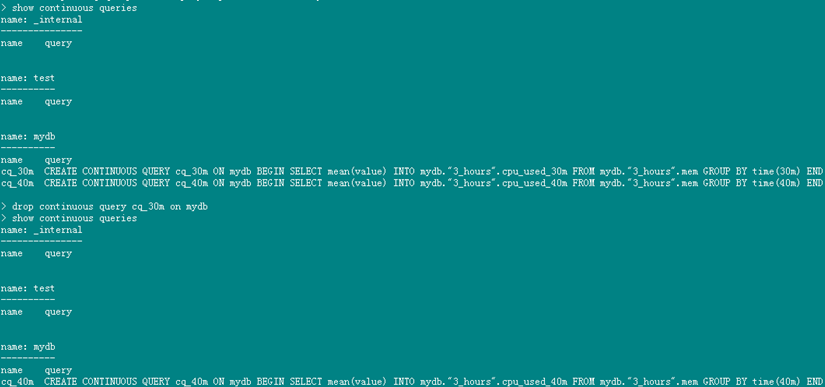
在InfluxDB中,将连续查询与数据存储策略一起使用会达到最好的效果。
比如,将精度高的表的存储策略定为一个周,然后将精度底的表存储策略定的时间久一点,这要就可以实现高低搭配,以满足不同的工作需要。
-
InfluxDB连续查询
InfluxDB设置数据保留策略,如果数据超过保存策略里指定的时间后,就会被删除。
如果不想完全删除这些数据,就需连续查询的帮助。
连续查询主要用在将数据归档,以降低系统空间占用率,主要以降低精度为代价。
一、InfluxDB连续查询 定义
InfluxDB的连续查询是在数据库中自动定时启动一组语句,语句中必须包含select关键词和group by time()关键词。
InfluxDB会将查询结果放在指定数据表中。
二、InfluxDB连续查询 目的
使用连续查询是最优降低采样率的方式,连续查询和存储策略搭配使用将会大大降低InfluxDB的系统占用量。
而且使用连续查询后,数据会存放到指定数据表中,这样就为以后统计不同精度数据提供方便。
三、InfluxDB连续查询 操作
只有管理员用户可操作连续查询 -
InfluxDB的HTTP API查询操作
一、InfluxDB进行HTTP API查询方法
使用HTTP API在InfluxDB进行查询主要是发送GET请求到InfluxDB的/query端,如下所示:
curl -GET ‘http://localhost:8086/query?pretty=true’ --data-urlencode “db=mydb” --data-urlencode “q=SELECT value FROM cpu_load WHERE region=‘us_east_cz’”
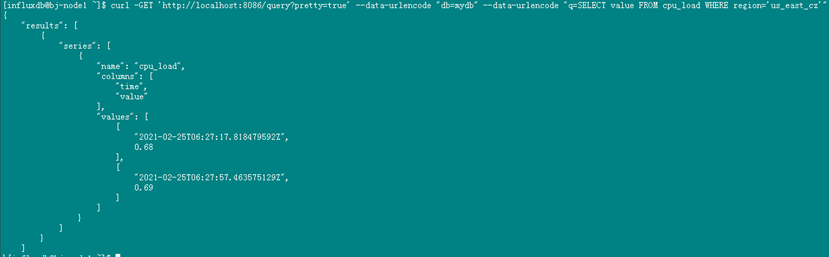
也可以在页面里执行查询,如下所示:
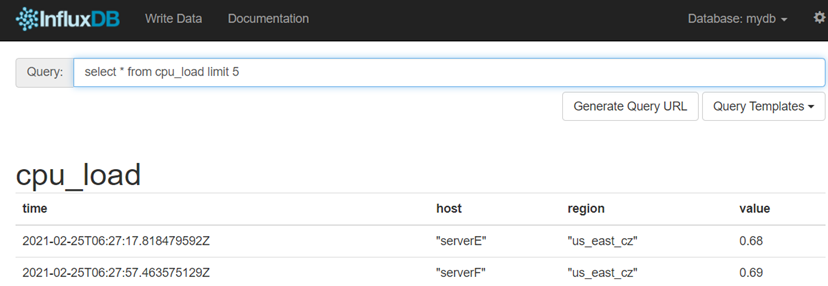
在界面上输入语句后,点击生成url就会生成http请求URL。
在浏览器执行后,会返回json格式的串。
如果查询出错的话,则会返回关键词“error”+错误信息。
二、InfluxDB进行HTTP API查询多条数据
要用InfluxDB进行多条查询,HTTP API提供的多条查询的格式如下所示:
curl -G ‘http://localhost:8086/query?pretty=true’ --data-urlencode “db=mydb” --data-urlencode “q=SELECT value FROM cpu_load WHERE region=‘us_east_cz’;
SELECT count(value) FROM cpu_load WHERE region=‘us_east_cz’”
格式与单条查询相同,只是在多条语句之间要用分号 ; 分隔。
返回值也是包含结果的json串。
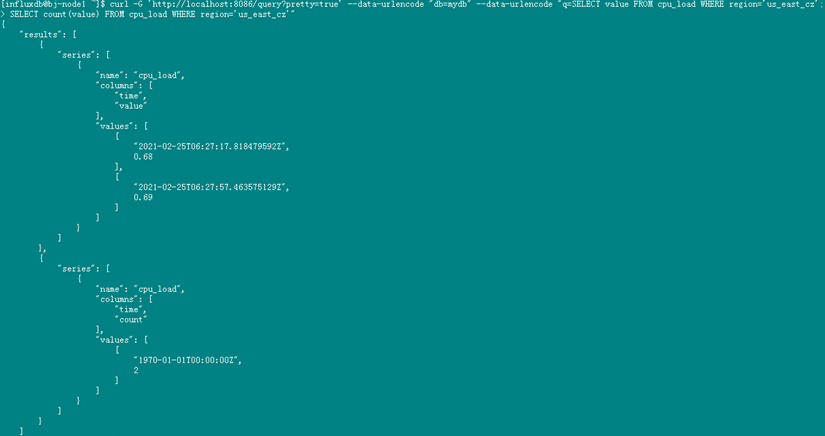
InfluxDB HTTP 查询的格式化输出
1)规定时间格式
在使用HTTP查询时可以使用 epoch 参数指定输出的时间格式。可选值有 epoch=[h,m,s,ms,u,ns]。
例如:
curl -G ‘http://localhost:8086/query’ --data-urlencode “db=mydb” --data-urlencode “epoch=s” --data-urlencode “q=SELECT value FROM cpu_load WHERE region=‘us_east_cz’”
这样会获取到以秒为单位的数据。
2)指定每次查询数据大小
可以使用 chunk_size 参数来指定每次结果的大小。比如,我要结果每次返回200个点的数据,则如下所示:
curl -G ‘http://localhost:8086/query’ --data-urlencode “db=mydb” --data-urlencode “chunk_size=200” --data-urlencode “q=SELECT value FROM cpu_load_short WHERE region=‘us-west’”
这样查询结果就会返回200个点的数据。 -
InfluxDB的备份与恢复
8.1. influxDB备份
启用influxDB用于备份与还原的RPC端口服务
influxDB数据库默认只启用了 8086 的数据库访问端口服务,而如果要使用 备份 与 还原 的功能,则需要单独另外启用一个端口服务。配置如下:
在 root 用户的级别下,在 influxdb 的配置文件influxdb.conf中,添加
bind-address = “127.0.0.1:8088”
然后重启influxDB服务。
influxDB默认采用8088端口作为备份还原端口,这个端口可以自己修改,如果要提供远程访问服务,则需要调整bind-address地址为远程访问IP地址,不然只允许127.0.0.1本地访问。
启用备份与还原端口服务后,可以采用官网提供的备份命令进行备份,其提供的备份命令如下:
$ influxd backup -portable -database mydatabase -host:8088 /tmp/mysnapshot
##实际测试发现,早期influxdb版本中,是不提供-portable这个参数的。
创建数据库
11.1. 连接influxDB数据库
##如已在服务器上安装并运行了influxDB数据库,可以使用influx命令连接到本地influxDB实例上,如下所示
influx -precision rfc3339
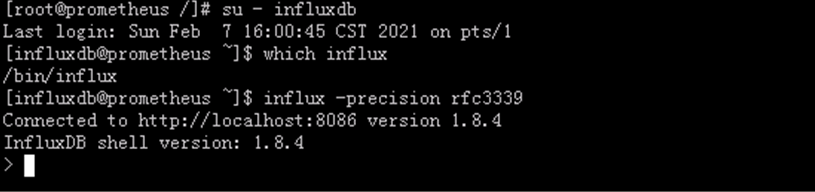
说明:
• InfluxDB的HTTP接口默认起在8086上,所以influx默认也是连的本地的8086端口,可以通过influx --help来看怎么修改默认值。
• -precision参数表明了任何返回的时间戳的格式和精度,在上面的例子里,rfc3339是让InfluxDB返回RFC339格式(YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ)的时间戳。
• rfc339是internet标准时间格式
• 使用exit可以退出命令行
• 初始安装后的influxDB除了系统自带的_internal,是没有数据库的
• _internal数据库是用来存储influxDB内部的实时监控数据的
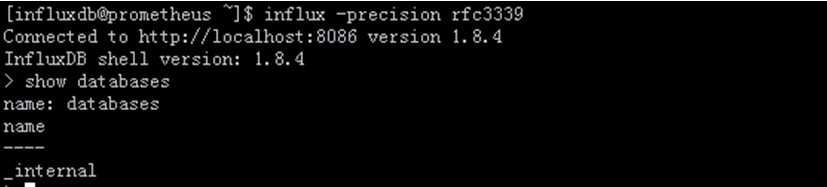
11.2. 创建数据库
##数据库的名字可以是被双引号引起来的任意Unicode字符。 如果名称只包含ASCII字母,数字或下划线,并且不以数字开头,那么也可以不用引起来。
如下是创建一个monitordb数据库

influxDB里存储的数据被称为时间序列数据,其包含一个数值,就像CPU的load值或是温度值类似的。
时序数据有零个或多个数据点,每一个都是一个指标值。数据点包括time(一个时间戳),measurement(例如cpu_load),至少一个k-v格式的field(也即指标的数值例如 “value=0.64”或者“temperature=21.2”),零个或多个tag,其一般是对于这个指标值的元数据(例如“host=server01”, “region=EMEA”, “dc=Frankfurt)。
在概念上,可以将measurement类比于SQL里面的table,其主键索引总是时间戳。tag和field是在table里的其他列,tag是被索引起来的,field没有。不同之处在于,在InfluxDB里,你可以有几百万的measurements,你不用事先定义数据的scheme,并且null值不会被存储。
可以使用方式插入和查询数据
INSERT cpu,host=serverA,region=us_west value=0.64
SELECT “host”, “region”, “value” FROM “cpu”
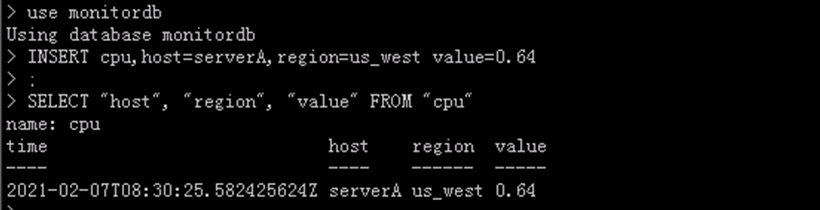
##说明:在写入的时候没有包含时间戳,当没有带时间戳的时候,InfluxDB会自动添加本地的当前时间作为它的时间戳
##influxDB 支持正则,比如支持golang样式的正则
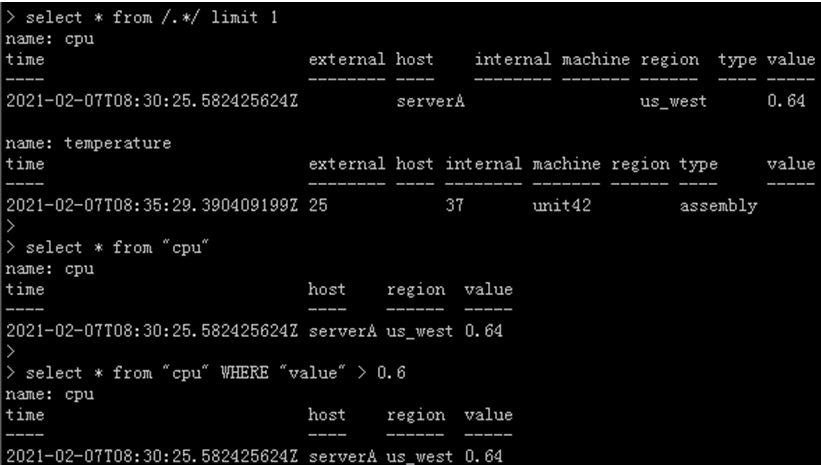
11.3. 写入数据
##有很多可以向influxDB写入数据的方式
4.3.1. 使用HTTP接口创建数据库
使用POST方式发送到URL的 /query路径,参数q为create database database_name,如下例子是发送一个请求到本地运行的InfluxDB并创建mydb数据库
curl -i -XPOST http://localhost:8086/query --data-urlencode “q=CREATE DATABASE mydb”
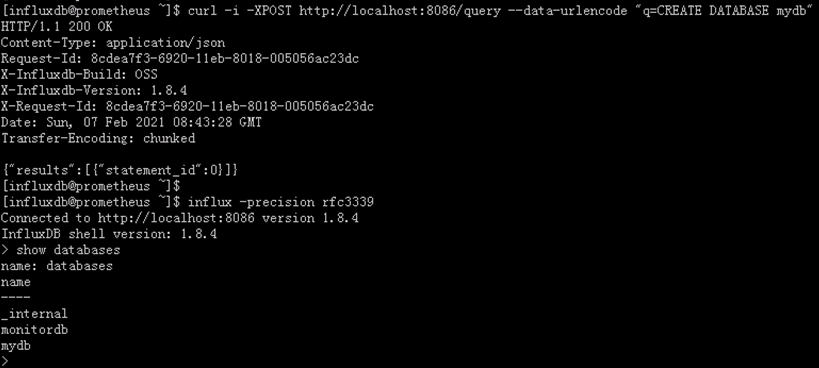
4.3.2. 使用HTTP接口写数据
通过http接口POST数据到/write路径是往influxDB写数据的主要方式
如下是通过http接口写入一条数据到mydb数据库
curl -i -XPOST ‘http://localhost:8086/write?db=mydb’ --data-binary ‘cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000’
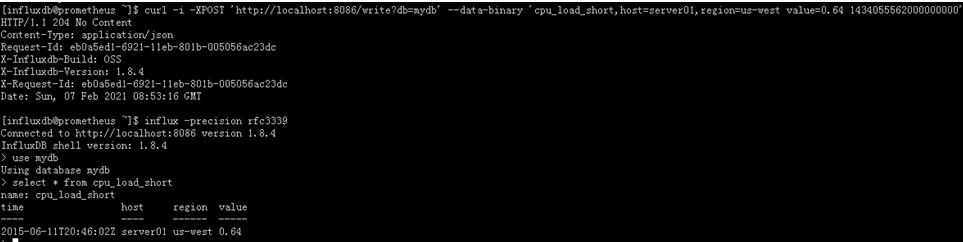
##当写入这条数据点的时候,你必须明确存在一个数据库对应名字是db参数的值。如果你没有通过rp参数设置retention policy的话,那么这个数据会写到db默认的retention policy中
POST的请求体称之为Line Protocol,包含了希望存储的时间序列数据。它的组成部分有measurement,tags,fields和timestamp。
measurement是InfluxDB必须的,严格地说,tags是可选的,但是对于大部分数据都会包含tags用来区分数据的来源,让查询变得容易和高效。
tag的key和value都必须是字符串。fields的key也是必须的,而且是字符串,默认情况下field的value是float类型的。
timestamp在这个请求行的最后,是一个从1/1/1970 UTC开始到现在的一个纳秒级的Unix time,它是可选的,如果不传,InfluxDB会使用服务器的本地的纳米级的timestamp来作为数据的时间戳,注意无论哪种方式,在InfluxDB中的timestamp只能是UTC时间。
4.3.3. 同时写入多个点
要想同时发送多个数据点到多个series【系列】(在influxDB中measurement加tags组成了一个series),可以用新的行来分开这些数据点,这种批量发送的方式可以获得更高的性能
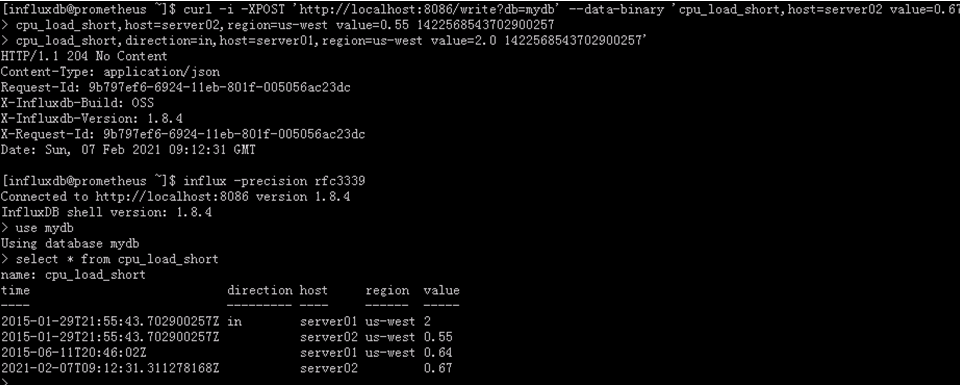
下面的例子就是写了三个数据点到mydb数据库中。
第一个点所属series的measurement为cpu_load_short,tag是host=server02,timestamp是server本地的时间戳;
第二个点同样是measurement为cpu_load_short,但是tag为host=server02,region=us-west,且有明确timestamp为1422568543702900257的series;第三个数据点和第二个的timestamp是一样的,但是series不一样,其measurement为cpu_load_short,tag为direction=in,host=server01,region=us-west
curl -i -XPOST ‘http://localhost:8086/write?db=mydb’ --data-binary ‘cpu_load_short,host=server02 value=0.67
cpu_load_short,host=server02,region=us-west value=0.55 1422568543702900257
cpu_load_short,direction=in,host=server01,region=us-west value=2.0 1422568543702900257’
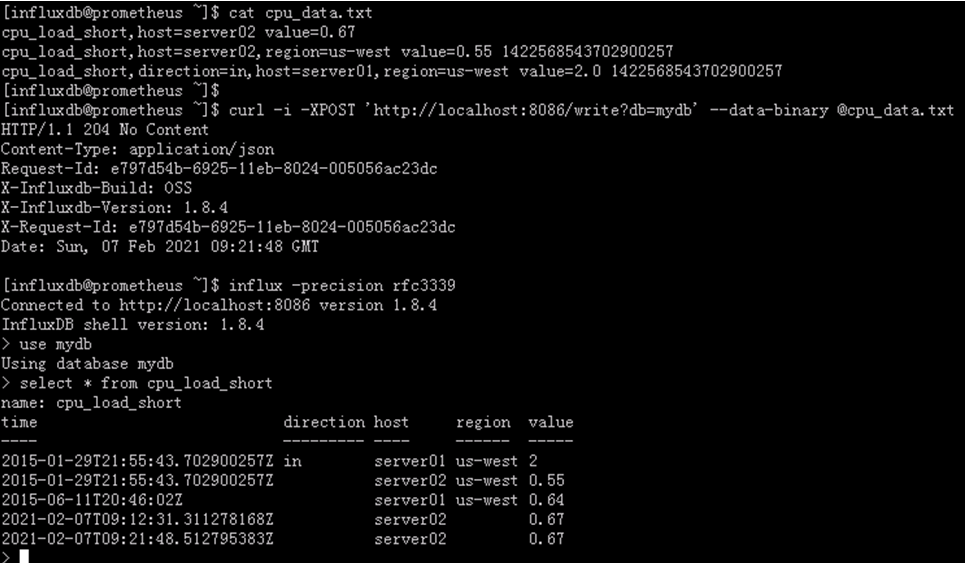
4.3.4. 写入文件中的数据
可以通过curl的@filename来写入文件中的数据,且这个文件里的数据格式需满足influxDB那种行的语法。
如下是一个cpu_data.txt的例子
cpu_load_short,host=server02 value=0.67
cpu_load_short,host=server02,region=us-west value=0.55 1422568543702900257
cpu_load_short,direction=in,host=server01,region=us-west value=2.0 1422568543702900257
然后将cpu_data.txt里的数据写入到mydb数据库:
curl -i -XPOST ‘http://localhost:8086/write?db=mydb’ --data-binary @cpu_data.txt
##说明:如果写入的数据文件的数据点大于5000时,必须把他们拆分到多个文件再写入InfluxDB。因为默认的HTTP的timeout的值为5秒,虽然5秒之后,InfluxDB仍然会试图把这批数据写进去,但是会有数据丢失的风险。
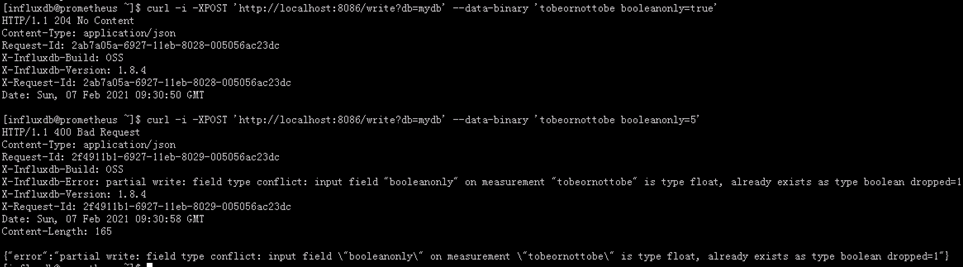
4.3.5. 无模式设计
influxDB是一个无模式(schemaless)数据库,可以在任意时间添加measurement,tags和fields,但是,注意,如果试图写入一个和之前的类型不一致的数据(例如,filed字段之前接收的是数字类型,现在试图插入字符串数据),此时influxDB会拒绝这个数据
• 2xx:如果写了数据后收到HTTP 204 No Content,说明写入成功了!
• 4xx:表示InfluxDB不知道接收的是什么数据
• 5xx:系统过载或是应用受损。
如下面插入两条数据的例子,第一条表示接收的是布尔值,第二条接收到浮点值,此时就会报错
curl -i -XPOST ‘http://localhost:8086/write?db=mydb’ --data-binary ‘tobeornottobe booleanonly=true’
curl -i -XPOST ‘http://localhost:8086/write?db=mydb’ --data-binary ‘tobeornottobe booleanonly=5’
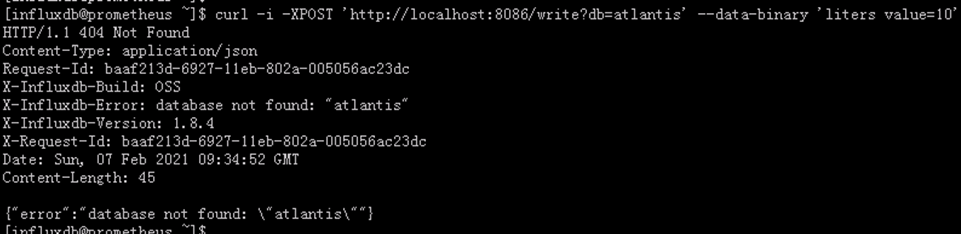
如果试图写入数据到一个不存在的数据库,会报4xx错误
如:
curl -i -XPOST ‘http://localhost:8086/write?db=atlantis’ --data-binary ‘liters value=10’
11.4. 查询数据
4.4.1. 使用HTTP接口查询数据
http接口是influxDB查询数据的主要方式,通过发送一个GET请求到 /query路径,并设置URL的db参数为目标数据库,设置URL参数q为查询语句。
如下列子:
curl -G ‘http://localhost:8086/query?pretty=true’ --data-urlencode “db=mydb” --data-urlencode “q=SELECT “value” FROM “cpu_load_short” WHERE “region”=‘us-west’”
influxDB返回一个json值,查询的结果在result列表中,如有错误发送,influxDB会在error这个key里解释错误发生的原因。
注意:添加pretty=true参数在URL里,是为了让返回的json格式化,这在调试或者直接用curl的时候很有用,但生产不建议采用,因为这样会消耗不必要网络带宽。
4.4.2. 同时执行多条查询语句
在一次API调用中发送多个influxDB查询语句,可以简单实用分号分割每个查询,例如:
curl -G ‘http://localhost:8086/query?pretty=true’ --data-urlencode “db=mydb” --data-urlencode “q=SELECT “value” FROM “cpu_load_short” WHERE “region”=‘us-west’;SELECT count(“value”) FROM “cpu_load_short” WHERE “region”=‘us-west’”

4.4.3. 查询数据时其它可选参数
时间戳格式
在InfluxDB中的所有数据都是存的UTC时间,时间戳默认返回RFC3339格式的纳米级的UTC时间,例如2015-08-04T19:05:14.318570484Z,如果想要返回Unix格式的时间,可以在请求参数里设置epoch参数,其中epoch可以是[h,m,s,ms,u,ns]之一。例如返回一个秒级的epoch:
curl -G ‘http://localhost:8086/query’ --data-urlencode “db=mydb” --data-urlencode “epoch=s” --data-urlencode “q=SELECT “value” FROM “cpu_load_short” WHERE “region”=‘us-west’”

最大行限制
可选参数max-row-limit允许使用者限制返回结果的数目,以保护InfluxDB不会在聚合结果的时候导致的内存耗尽。
在1.2.0和1.2.1版本中,InfluxDB默认会把返回的数目截断为10000条,如果有超过10000条返回,那么返回体里面会包含一个"partial":true的标记。该默认设置可能会导致Grafana面板出现意外行为,如果返回值大于10000时,这个面板就会看到截断/部分数据。
在1.2.2版本中,max-row-limit参数默认被设置为了0,这表示说对于返回值没有限制。
这个最大行的限制仅仅作用于非分块(non-chunked)的请求中,分块(chunked)的请求还是返回无限制的数据。
分块(chunking)
可以设置参数chunked=true开启分块,使返回的数据是流式的batch,而不是单个的返回。返回结果可以按10000数据点被分块,为了改变这个返回最大的分块的大小,可以在查询的时候加上chunk_size参数,例如返回数据点是每20000为一个批次。
curl -G ‘http://localhost:8086/query’ --data-urlencode “db=mydb” --data-urlencode “chunked=true” --data-urlencode “chunk_size=20000” --data-urlencode “q=SELECT * FROM cpu_load_short”

11.5. 采样和数据保留策略
influxDB提供了两个特性——连续查询(Continuous Queries简称CQ)和保留策略(Retention Policies简称RP),分别用来处理数据采样和管理老数据。
Continuous Query (CQ)是在数据库内部自动周期性跑着的一个influxQL的查询,CQs需要在SELECT语句中使用一个函数,并且一定包括一个GROUP BY time()语句。
Retention Policy (RP)是influxDB数据架构的一部分,它描述了InfluxDB保存数据的时间。influxDB会比较服务器本地的时间戳和请求数据里的时间戳,并删除比你在RPs里面用DURATION设置的更老的数据。一个数据库中可以有多个RPs但是每个数据库的RPs是唯一的。
4.5.1. 数据保存策略
influxDB是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。
- 查看当前数据库retention policies
show retention policies on db_name
如:

- 创建新的retention policies
create retention policy “rp_name” on “db_name” duration 3w replication 1 default

• rp_name:策略名
• db_name:具体的数据库名
• 3w:保存3周,3周之前的数据将被删除,influxdb具有各种事件参数,比如:h(小时),d(天),w(星期)
• replication 1:副本个数,一般为1就可以了
• default:设置为默认策略 - 修改retention policies
alter retention policy “rp_name” on “db_name” duration 30d default
如:

- 删除retention policies
drop retention policy “rp_name” on “db_name”
