客户的某个SQL简化如下:
select foo4.*,
row_number() over() rn
from (select *
from (select stat1,stat2,stat3
from (select foo1.*,foo2 from foo1) foo3
union all
select sum(stat1),sum(stat2),sum(stat3)
from (select foo1.*,foo2 from foo1) foo3
) as foo4
) foo5;
复制主要的逻辑是子查询foo4里面的两个foo3子查询,union all上面的语句是做一些求和及百分比之类的运算,下面的语句再做一次汇总运算。
下面继续查看foo3子句
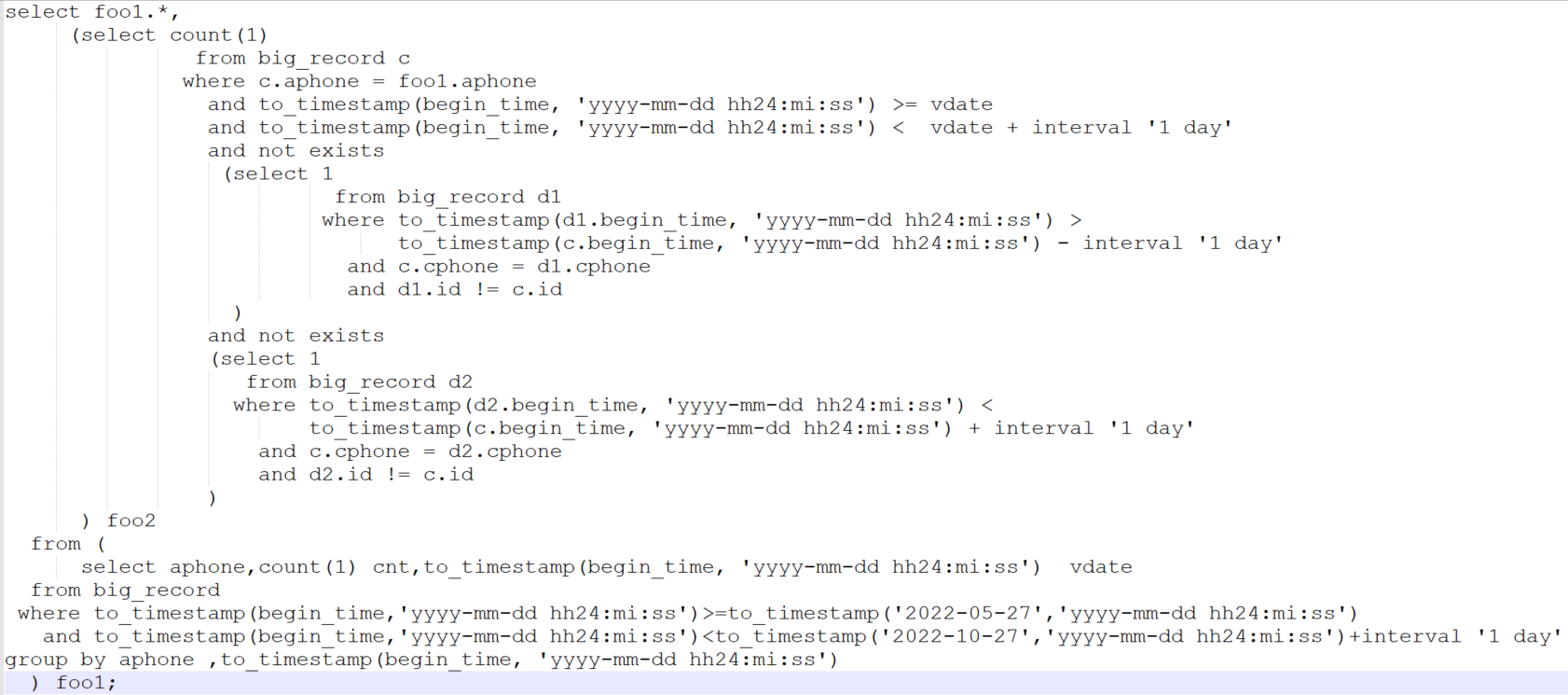
foo2子句依赖foo1子句,foo1子句可以独立执行:
select aphone,count(1) cnt,to_timestamp(begin_time, 'yyyy-mm-dd hh24:mi:ss') vdate
from big_record
where to_timestamp(begin_time,'yyyy-mm-dd hh24:mi:ss')>=to_timestamp('2022-10-27','yyyy-mm-dd hh24:mi:ss')
and to_timestamp(begin_time,'yyyy-mm-dd hh24:mi:ss')<to_timestamp('2022-10-27','yyyy-mm-dd hh24:mi:ss')+interval '1 day'
group by aphone,to_timestamp(begin_time, 'yyyy-mm-dd hh24:mi:ss')
复制foo1子句按begin_time查询一天的数据大概是200条左右,基表big_record的数据量大约是90万。
单独查询foo1子句,对基表big_record按begin_time过滤数据是可以查出结果。
foo2子句里有三次对基表big_record的查询,按照关联复杂关系,拆分为带not exists完整的foo3查询和删除两个not exists的不完整foo3查询。
删除两个not exists的不完整foo3查询可以通过修改where条件,走表达式索引可以快速查询出结果。
to_timestamp(begin_time, 'yyyy-mm-dd hh24:mi:ss')复制
表达式索引里的函数需要保证稳定性,因而需要修改替换to_timestamp函数。
CREATE OR REPLACE FUNCTION to_timestamp_immutable(text, text) RETURNS timestamp with time zone LANGUAGE internal immutable PARALLEL SAFE STRICT AS $function$to_timestamp$function$;复制
索引结构如下:
create index on big_record (to_timestamp_immutable(begin_time,'yyyy-mm-dd hh24:mi:ss'));复制
修改之后的foo3子句如下:
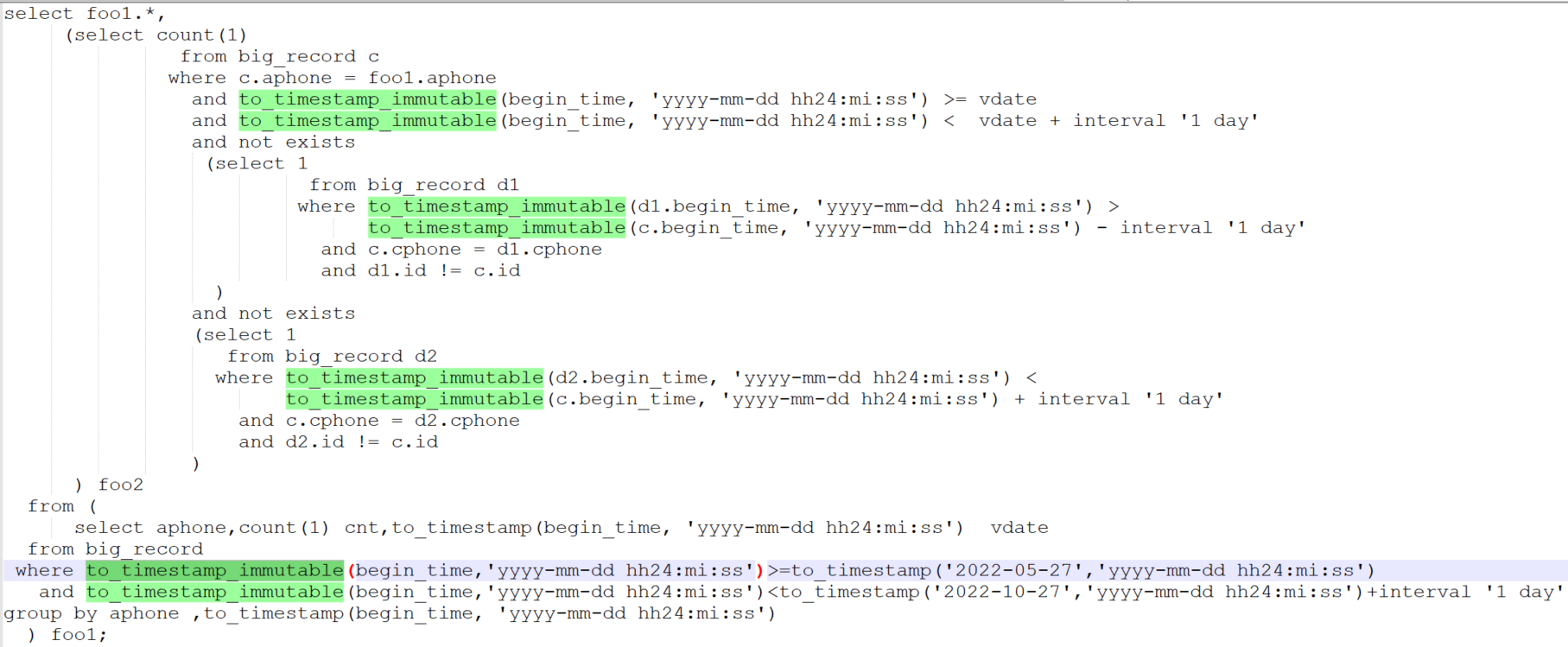
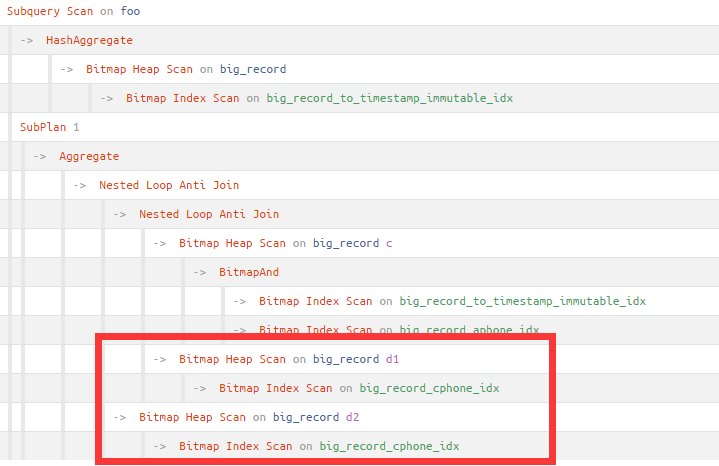
接着通过执行计划查看带not exists完整的foo3查询,主要还是两个not exists里对big_record的全表扫很慢。
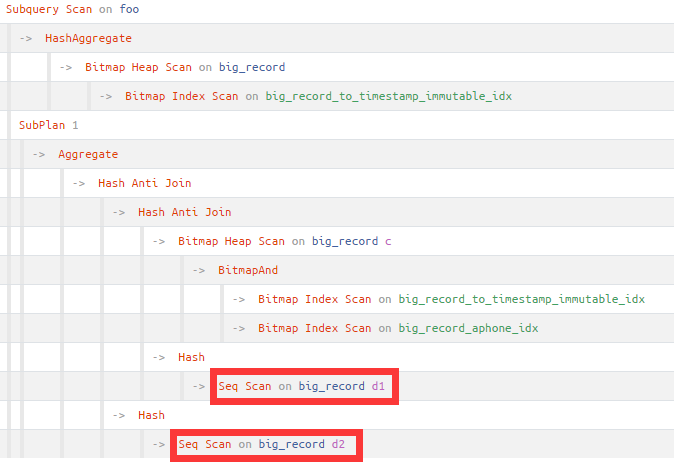
对比观察foo2子句第一次对big_record表走了Bitmap Index Scan,用到了两个索引,也就是分别用到了begin_time和aphone字段上的索引,而not exists里并没有用到索引。
根据not exists里的关联条件分析,可以对big_record表cphone字段建立索引:
create index on big_record (cphone);复制
再次查看执行计划如下:
最后在本地环境进行测试模拟:
构造测试表:
create table big_record( id int, begin_time varchar, aphone varchar, cphone varchar );复制
模拟插入大约100W数据
insert into big_record select f2,f1::varchar,get_tel(),get_tel() from generate_series('2011-05-30'::timestamp,'2022-10-30'::timestamp,'6 min') with ordinality as t(f1,f2);复制
根据begin_time查询一天的数据大约240条。
创建如下索引
create index on big_record (to_timestamp_immutable(begin_time,'yyyy-mm-dd hh24:mi:ss')); create index on big_record (aphone); create index on big_record (cphone);复制
对big_record表单天查询或按月查询,通过begin_time的索引可以很快获得结果。
select aphone,count(1) cnt,to_timestamp(begin_time, 'yyyy-mm-dd hh24:mi:ss') vdate from big_record a where to_timestamp_immutable(begin_time, 'yyyy-mm-dd hh24:mi:ss') >= to_timestamp('2022-10-27','yyyy-mm-dd hh24:mi:ss') and to_timestamp_immutable(begin_time, 'yyyy-mm-dd hh24:mi:ss') < to_timestamp('2022-10-27','yyyy-mm-dd hh24:mi:ss') + interval '1 day' group by aphone , to_timestamp(begin_time, 'yyyy-mm-dd hh24:mi:ss');复制
单天查询在几毫秒内,一个月查询在30毫秒左右。
对foo3子句的查询,单天查询在30毫秒左右,单月查询500毫秒左右,半年大约2秒左右。
保持联系
从2019年12月开始写第一篇文章,分享的初心一直在坚持,本人现在组建了一个PG乐知乐享交流群,欢迎关注我文章的小伙伴加我微信进群吹牛唠嗑,交流技术。