




python机器人视觉编程——入门篇(下)
本篇主要阅读对象、目标及概要
如今,Python语言已经成为人工智能领域最热门的开发语言之一,她正在被越来越多的从事人工智能(包括机器人、机器视觉)的机构、和个人所使用,人们在使用python语言的灵活性、易用性及强大的应用模块的同时,也贡献她们的专业优秀模块,在科学各专业领域形成了科学计算的python模块资源,使得初学者便捷快速进行应用开发,降低重复劳动,避免重复制造“轮子”,快速实现程序的专业领域应用及设计规划落地,尤其,在机器人领域,作为机器人工程应用最重要的组成部分——机器视觉,python及其生态开发者为我们提供了诸如opencv-python、numpy、pillow等图像处理所需的模块库,任何人可以通过python自带的工具(pip)方便的安装相对应的版本,进行研究或工程应用。
本篇的阅读对象是致力于使用python或者通过python编程想敲门进入机器人视觉领域的零python基础者,假设具备有一定的其它编程语言的基础经验,掌握了诸如“函数”、“类”、“变量”、“数据类型”、“条件判断”、“循环”、“线程”等概念。
本篇的目标是抛砖引玉地介绍从事机器视觉python研究开发或工程应用所需的最基础知识点,简要介绍图像结构及基础运算、图像处理python基础库、图像识别基本流程、图像坐标变化等知识,帮助初学者入门python的机器视觉开发。
本篇讲述的内容如下:
(1)Python知识点一。主要讲述python的安装,及依赖环境的搭建,以及上手基础操作。
(2)Python知识点二。主要讲述python机器视觉编程的基础而重要的概念,并配以相应的程序进行说明,重要的概念有:”缩进”、”函数”、”类“、”循环“、基础数据类型等。
(3)Python知识点三。主要讲述python机器视觉编程所需的较为高级的概念,有助于提高性能及简化算法。如:”生成器“、“线程”、”队列“、”装饰器“等。
(4)图像的读取与运算基础(A5)。主要讲述图像从摄像头获取后,图像的数据结构形式、图像的类型、及简单的运算。
(5)图像处理基础库简介(B5)。主要介绍图像处理核心库opencv,以及人机界面PySimpleGUI,两者结合可以达到事半功倍的效果。
(6)桌面物体识别基本流程(B14)。主要介绍了当摄像头获取一张桌面物体的图像后,如果通过以上的知识、工具对图像中的物体进行有效识别,并标记出来。
(7)图像的坐标计算(B13)。主要介绍了如何将图像中的像素与摄像头外的现实空间坐标进行关联,从而实现图像中物体对应于现实世界的坐标定位,为机器人的抓取提供坐标。
本篇大部分凭笔者的经验及认识所写,难免会有不系统及遗误,还请读者批评指正。
A5 图像的读取与运算基础
5.1 图像的读取
对于初、中级图像处理人员,可以使用opencv的python库进行图像的读取,包括:
5.1.1 从磁盘的图像(.jpg,.npg,.gif等等)读取
比如从D盘读取一张名叫test.jpg的图片到计算机的内存,并显示在窗口,可以在python编辑器里敲入如下代码:
import cv2
image=cv2.imread("D:\\test.JPG")#""内输入图像文件路径即可
cv2.imshow("test",image)

5.1.2 从摄像头里读取图像
如果想要从计算机自带的摄像头,或者USB摄像头读取采集的图像,可以这样进行读取和显示:
import cv2
cap=cv2.VideoCapture(0)
while(True):
sucess,frame=cap.read()#连续读取图像帧
if sucess==True:#如果读取图像成功
cv2.imshow("video",frame)#通过窗口显示更新图像
key=cv2.waitKey(1)#通过函数获取按下监盘的值
if key == ord("q"):#当按下q键时
cap.release()#当按下q键时,关闭摄像头
cv2.destroyAllWindows() #当按下q键时,关闭显示窗口
break#当按下q键时,退出while循环
5.2 图像的运算
5.2.1图像的数据结构
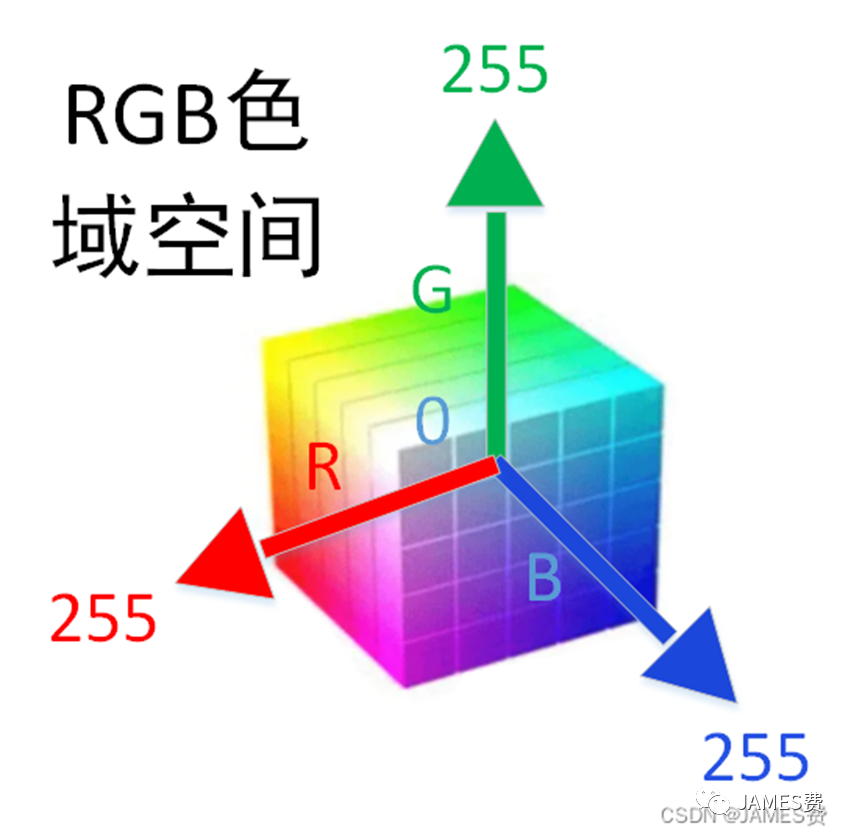
在结构上面,图像是由一个一个像素横竖排列组成的,每个像素都是有颜色的。本质上,对计算机来说,图像就是很多个按一定的组合顺序排列的数字组合。可以认为一副彩色的图像,是由三个二维的数组组合而成的数字集合。如下图所示,左上角是一副人类看到的,具有9个像素的RGB图像。这副图像,在计算机看来是几个二维数字组合,如下图:
如上图所示,左上角的图像(RGB格式),计算机用三个二维的数字组合来存储,显示时,根据RGB的格式显示规则,即,每个像素显示,根据此像素在对于三个通道的对应位置的数值(可以认为是一个坐标,如(255,150,12))在RGB色域空间上查找到颜色后就显示出来(土黄色)。色域空间如下图:

我们可以用python读取一张小的图片,然后把他的数据打印出来:
import cv2
image=cv2.imread("D:\\test.JPG")
print("图像的数据结构",image.shape)
print("图像的像素数量",image.shape[0]*image.shape[0])
print("图像的详细数据",image)
打印输出如下:

上图所示,所读取的图像,结构是,有3个维度(或三个通道),每个维度中:竖着有30组数字,横着有28组数字,总共有840个数字。每个数字都是0-255之间的整数。在python里,我们可以通过*.shape*函数查看图像的结构。
PS:opencv对rgb色域的图像存储,1-3通道先后顺序分别对应的是(B、G、R),而不是通常的RGB顺序。还需要注意的是,除了RGB格式存储外,还有其它如HSV、LAB等色域空间的存储,有些色域空间的通道值最大不是255,有可能是180. 由于深度有限,本篇只对BGR空间的图像进行探讨。
5.2.2图像的像素与数据存储结构的对应规则
图像像素一般规定的坐标是以左上角为原点,分别向右向下增加坐标的数值,如下图:
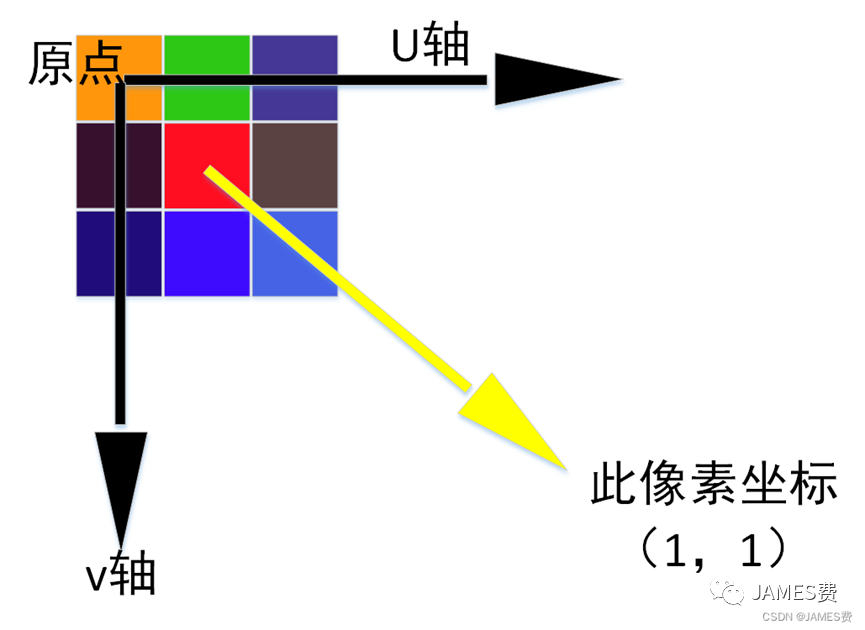
像素坐标一般以u,v称呼,横着叫u轴,竖着叫v轴。比如上图红色像素的坐标是(1,1),左上角的像素的坐标是(0,0)。如果我们要知道图像某个像素的各通道数值是多少,我们可以利用python的“[u,v,x]”操作,操作如下:
import cv2
image=cv2.imread("D:\\test.JPG")
#获取图像左上角像素,的第一个通道(B通道)的值
print("图像左上角像素,的第一个通道(B通道)的值是:",image[0,0,0])
#获取图像中坐标为(u,v)=(9,10)的像素,的第二通道(G通道)的值
print("获取图像中坐标为(u,v)=(9,10)的像素,的第二通道G通道)的值是:",image[10,9,1])
#获取图像中坐标为(u,v)=(9,10)的像素,的3个通道(的值
print("获取图像中坐标为(u,v)=(9,10)的像素,的3个通道(的值是:",image[10,9,:3])
输出结果:

5.2.3图像的像素信息获取、运算
知道了图像本质是3个维度的二维数据后,以及图像各个像素坐标与数据存储结构的对应关系,我们就可以很容易的对图像中的任意位置像素进行计算,包括:指定像素的提取、同种颜色像素的查找及个数的统计、或者是更改一下特定像素的三个RGB“坐标”数值,改变像素的颜色等等。简单演示如下:
(1)像素的统计运算
直方图的本质其实就是对图像象素进行同类项合并,并统计出0-255(或最大值)的颜色域内,各个像素的分布情况。
import cv2
import matplotlib.pyplot as plt#用于绘制统计图
image=cv2.imread("D:\\test.JPG")
B=[0 for i in range(256)]#创建一个具有256个长度的列表,分别用于存储0-255值得象素个数
G=[0 for i in range(256)]#创建一个具有256个长度的列表,分别用于存储0-255值得象素个数
R=[0 for i in range(256)]#创建一个具有256个长度的列表,分别用于存储0-255值得象素个数
#对图像得B通道的数值进行遍历,将通道内同类的数值个数,根据数值放入创建的列表value中
for u in range(image.shape[1]):
for v in range(image.shape[0]):
B[image[v,u,0]]=B[image[v,u,0]]+1
G[image[v,u,1]]=G[image[v,u,1]]+1
R[image[v,u,2]]=R[image[v,u,2]]+1
#画出直方图
x=[i for i in range(256)]#横坐标
fig=plt.figure()
fig.canvas.set_window_title('直方图')
plt.subplot(3,1,1)
plt.bar(x,B,color='b')
plt.subplot(3,1,2)
plt.bar(x,G,color='g')
plt.subplot(3,1,3)
plt.bar(x,R,color='r')
plt.show()
输出结果:
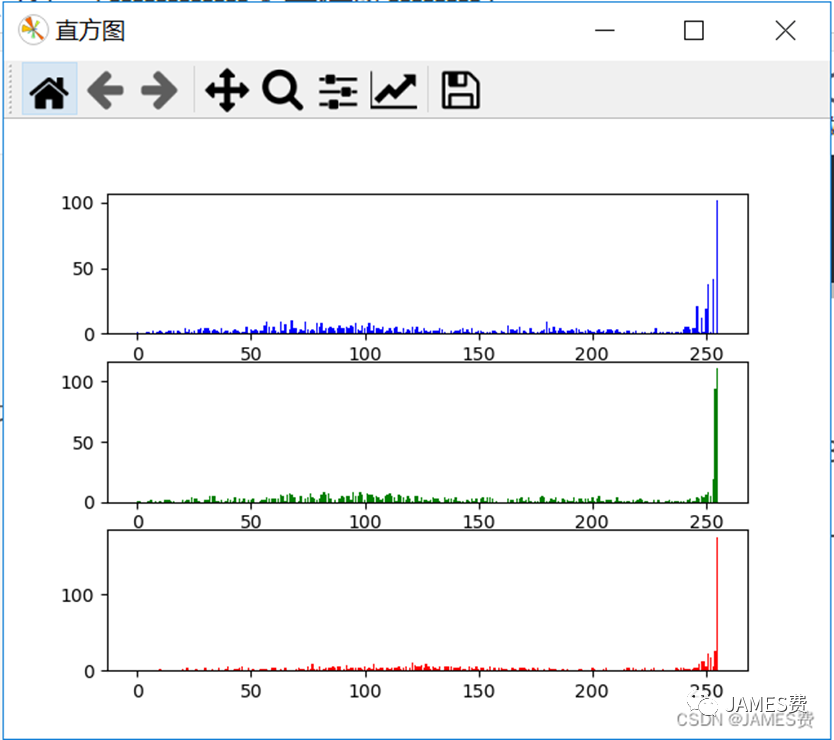
由上图可以看出,图像在各通道,数值>250的象素个数分布是比较多的,即亮的区域比较多。
(2)像素的过滤与查询
我们可以根据图像的颜色特点,设置查找条件,找出图像中感兴趣的部位,过滤掉其它不感兴趣的部位,下面例子是设置条件,找到图像中红色块,并把这个区域单独显示:
import cv2
import matplotlib.pyplot as plt#用于绘制统计图
image=cv2.imread("D:\\test.JPG")
black=image*0#这是一张全为0的黑色底图,图的大小和image是一样的
#设置查找颜色的条件 红色
B=[0,255]#蓝色通道的范围
G=[0,50]#绿色通道的范围
R=[130,255]#红色通道的范围
#下面我们将同时符合以上条件的象素给找出来,并放入底图black中
for u in range(image.shape[1]):
for v in range(image.shape[0]):
if image[v,u,0]>=B[0] and image[v,u,0]<=B[1]:
if image[v,u,1]>=G[0] and image[v,u,1]<=G[1]:
if image[v,u,2]>=R[0] and image[v,u,2]<=R[1]:
black[v,u,:] = image[v,u,:]
cv2.imshow('',black)
输出结果如下:
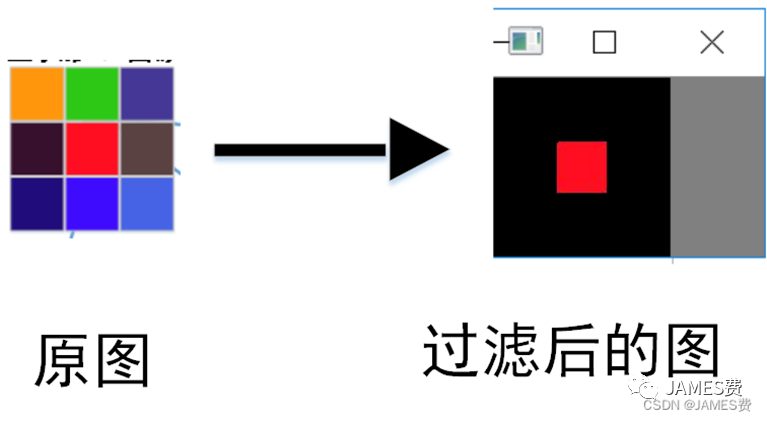
如上图所示,对象素进行按照条件过滤,可以筛选出我们感兴趣的部分。
以上是通过常用的数值比较等运算,对图像进行的一些基础运算,可以对图像进行分析、和区域查找。然而,图像的处理原不止这些操作,幸运的是,现在已经不需要从0开始造轮子,牛人们已经帮我们实现了绝大多数的图像处理应用,并提供给我们调用,opencv库里面现成的图像处理函数非常多,我们稍微了解一下原理,就可以拿来,根据需要灵活应用了。
B5 图像处理基础库简介
本节将介绍强大的图像处理库opencv的一些实用函数,及一个强大的gui库,两者结合起来应用,能起到事半功倍的效果。
5.1 opencv常用处理函数纪要
首先,我们来熟悉一下一个OpenCV这个软件库。OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。OpenCV提供的视觉处理算法非常丰富,并且它部分以C语言编写,加上其开源的特性,处理得当,不需要添加新的外部支持也可以完整的编译链接生成执行程序,所以很多人用它来做算法的移植,OpenCV的代码经过适当改写可以正常的运行在DSP系统和ARM嵌入式系统中。对于python语言,opencv提供了模块支持。
Ps:需要指出的是,opencv这个多适用于对性能、可靠性要求不是很高的场景,在正式的工业场景,应用opencv,可能需要进行性能、及稳定性的优化,或者使用其它商业成熟的视觉产品。Opencv对机器视觉的研究学习人员是应用较多的。
Opencv在python中,主要是通过cv2.函数名(参数1,参数2…约定常数)的形式进行应用,其中约定的常数基本为整数,以类似cv2.IMREAD_COLOR的大写字符串表示。
比较核心的函数如下表所示:
序号 | 函数名 | 用途 | 参数含义 |
1 | cv2.imread(参数1,参数2) 例: img=cv2.imread(“D:\\image.jpg”) | 读取指定路径的图像 | 参数1: 图片的路径,如:D:\\image.jpg 参数2(非必选,为cv的常数): cv2.IMREAD_COLOR:读入彩色图像,忽略图像的透明度,默认参数。 cv2.IMREAD_GRAYSCALE:以灰度模式读入图像 cv2.IMREAD_UNCHANGED:读入一幅图像,并且包括图像的alpha通道 ps:对于png格式图片,有时候会有第四个通道,即alpha透明通道,存储了象素的透明度信息 |
2 | cv2.imshow(参数1,参数2) 例: cv2.imshow(“name”,img) | 创建窗口并显示图像 | 参数1: 窗口名字,字符串格式 参数2: 读入的图像变量 |
3 | cv2.destroyWindow(参数1) 例: cv2.destroyWindow(‘name’) | 关闭并销毁指定的窗口 | 参数1: 窗口名,字符串 |
4 | cv2.destroyAllWindows() 例: cv2.destroyAllWindows() | 关闭并销毁所有已建窗口 | 无 |
5 | cv2.imwrite(参数1 ,参数2) 例: cv2.imwrite(“D:\\image.jpg” ,img) | 保存图片 | 参数1: 保存的路径及文件名 参数2: 图像变量 |
6 | cv2.VideoCapture(参数1) 例: cap= cv2.VideoCapture(0) | 获取摄像头返回对象cap | 参数1: 为摄像头的设备号,如:0,1,… |
7 | cap.read() 例: res,frame=cap.read() | 从摄像头对象读取一副实时图像 | 无 |
8 | cv2.cvtColor(参数1,参数2) 例: hsv_img=cv2.cvtColor(img,cv2.COLOR_BGR2HSV) | 转换图像的颜色空间 | 参数1: 被转换的图片 参数2:(cv2.COLOR_*2*) 转换的类型,包括:BGR转灰度图cv2.COLOR_BGR2GRAY,BGR转RGB图cv2.COLOR_BGR2RGB,BGR转HSV空间cv2.COLOR_BGR2HSV,BGR转Lab空间cv2.COLOR_BGR2Lab |
9 | cv2.inRange(参数1,参数2,参数3) 例: new_img= cv2.inRange(img,np.array([20,20,25]), np.array([80,150,255])) | 根据参数2和参数3最小最大范围,过滤出范围内的区域为白色255,其余为黑色0 | 参数1: 指的被处理的图像 参数2:(lower,三个值) 条件最小值,指的是图像中如低于这个值,图像值变为0,如:np.array([20,20,25]) 参数3:(upper,三个值) 条件最大值,指的是图像中高于这个值,图像值变为0 而在参数1lower~参数2upper之间的值变成255, 如:np.array([20,20,25]) |
10 | cv2.blur(参数1,参数2) 例: Blur_img= cv2.blur(img,(3,3)) | 均值模糊 | 参数1: 指的被处理的图像 参数2:(奇数,奇数) 卷积核大小,如(3,3),(5,5) 其他参数一般为默认 |
11 | cv2.GaussianBlur(参数1,参数2) 例: GBlur_img= cv2. GaussianBlur (img,(3,3)) | 高斯模糊 | 参数1: 指的被处理的图像 参数2:(奇数,奇数) 卷积核大小,如(3,3),(5,5) 其他参数一般为默认 |
12 | cv2.Canny(参数1, 参数2, 参数3, apertureSize=参数4) 例: #先转灰度图 gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) Canny_img= cv2.Canny(gray_img, 100, 200, apertureSize=3) | 图像边缘检测 | 参数1: 指的被处理的灰度图像 参数2: 过滤最小阈值 参数3: 最大阈值,使用此参数进行明显的边缘检测 参数4: sobel算子大小(可不设定),扩大算子大小,会获得更多的细节 |
13 | cv2.threshold(参数1, 参数2, 参数3,参数4) 例: #先转灰度图 gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) thred_img= cv2.threshold(gray_img,127,255, cv2.THRESH_BINARY) | 阈值分割,分割成黑白图 | 参数1: 指的被处理的灰度图像 参数2: 过滤最小阈值 参数3: 最大阈值 参数4:(0-4常数) 二值方法 cv2.THRESH_BINARY(黑白二值,0) cv2.THRESH_BINARY_INV(黑白二值反转,1) cv2.THRESH_TRUNC (得到的图像为多像素值,2) cv2.THRESH_TOZERO(3) cv2.THRESH_TOZERO_INV(4) |
14 | cv2.resize(参数1, 参数2,fx=参数3,fy=参数4, interpolation=参数5) 例: resize_img=cv2.resize(img,(2*img.shape[0],2*img.shape[1]),fx=1,fy=1,interpolation=cv2.INTER_LINEAR) | 缩放图像 | 参数1: 指的被处理的图像 参数2: 被缩放后的图像长宽,如(100,200) 参数3: 图像宽度的缩放比例,可默认不设 参数4: 图像高度的缩放比例,可默认不设 参数5:(0-4的常数) 插值方法,可默认不设 |
15 | cv2.erode(参数1,参数2,参数3) 例: #定义核 kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3)) # 椭圆结构 erode_img=cv2.erode(b_img,kernel,3) | 腐蚀图像,使前景部分变细,去细小噪点 | 参数1: 指的被处理的二值或灰度图像 参数2: 各形状及大小的卷积核, 矩形:MORPH_RECT; 交叉形:MORPH_CROSS; 椭圆形:MORPH_ELLIPSE; 参数3: 迭代次数 |
16 | cv2.dilate(参数1,参数2,参数3) 例: #定义核 kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3)) # 椭圆结构 dilate_img=cv2.dilate (b_img,kernel,3) | 膨胀图像,将前景物体变大,连接较近的部分 | 参数1: 指的被处理的二值或灰度图像 参数2: 各形状及大小的卷积核, 矩形:MORPH_RECT; 交叉形:MORPH_CROSS; 椭圆形:MORPH_ELLIPSE; 参数3: 迭代次数 |
17 | cv2.findContours(参数1,参数2,参数3) 例: image,contours,hierarchy=cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE) #contours即为轮廓像素坐标点 | 获取图像物体轮廓(多个像素的坐标点集合) | 参数1: 指的被处理的二值或灰度图像 参数2:(0-3常数) 轮廓的模式。 cv2.RETR_EXTERNAL只检测外轮廓;cv2.RETR_LIST检测的轮廓不建立等级关系; cv2.RETR_CCOMP建立两个等级的轮廓,上一层为外边界,内层为内孔的边界。如果内孔内还有连通物体,则这个物体的边界也在顶层; cv2.RETR_TREE建立一个等级树结构的轮廓 参数3:(1-4常数) 轮廓的近似方法。 cv2.CHAIN_APPROX_NOME存储所有的轮廓点,相邻的两个点的像素位置差<=1; cv2.CHAIN_APPROX_SIMPLE压缩水平方向、垂直方向、对角线方向的元素,只保留该方向的终点坐标;cv2.CHAIN_APPROX_TC89_L1 和 cv2.CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法 |
18 | cv2.drawContours(参数1, 参数2, 参数3, 参数4, 参数5) 例: cv2.drawContours(img, contours,-1, (255,0,255),3) | 根据查找的轮廓,绘制轮廓 | 参数1: 同源同尺寸的图像 参数2: 轮廓变量,list类型。 参数3: 指定绘制轮廓list中的哪条轮廓,如果是-1,则绘制其中的所有轮廓 参数4: 轮廓的颜色,如(255,0,255)。 参数5: 轮廓厚度,如,3。 |
19 | cv2.goodFeaturesToTrack(参数1,参数2,参数3,参数4) 例子: corners = cv2.goodFeaturesToTrack(gray,25,0.01,10) # 返回的结果是[[311,...250]] 两层括号的数组 | 获取灰度图像角点 | 参数1: 灰度图像 参数2: 想要检测到的角点数目。 参数3: 置角点的质量水平,0到 1 之间。 参数4: 两个角点之间的最短欧式距离。 |
20 | … |
5.2 PySimpleGUI ——一个快速搭建视觉处理应用的好工具
根据笔者的切身感受,PySimpleGUI真是一个非常便捷、快捷的gui库,它封装了基于大名鼎鼎的tkinter,同时提供了一套运用“数据驱动”定义UI布局的方法。虽然界面没有那么华丽,但是确实非常实用。下面对这个库做一个简单介绍:

官方说明,PySimpleGUI是一个Python包,使所有级别的Python程序员能够创建GUI。您可以使用包含小部件的“布局”来指定GUI窗口(它们在PySimpleGUI中称为“元素”)。您的布局用于使用 4 个受支持的框架之一创建窗口,以显示窗口并与之交互。支持的框架包括tkinter,Qt,WxPython或Remi。术语“包装器”有时用于这些类型的包。你的 PySimpleGUI 代码比直接使用底层框架编写更简单、更短,因为 PySimpleGUI 为你实现了大部分的“样板代码”。此外,接口也得到了简化,需要尽可能少的代码来获得所需的结果。根据所使用的程序和框架,PySimpleGUI程序可能需要1/2到1/10的代码量才能直接使用其中一个框架创建相同的窗口。
下面列出一些图像处理所需要的调参的ui工具,用PySimpleGUI实现:
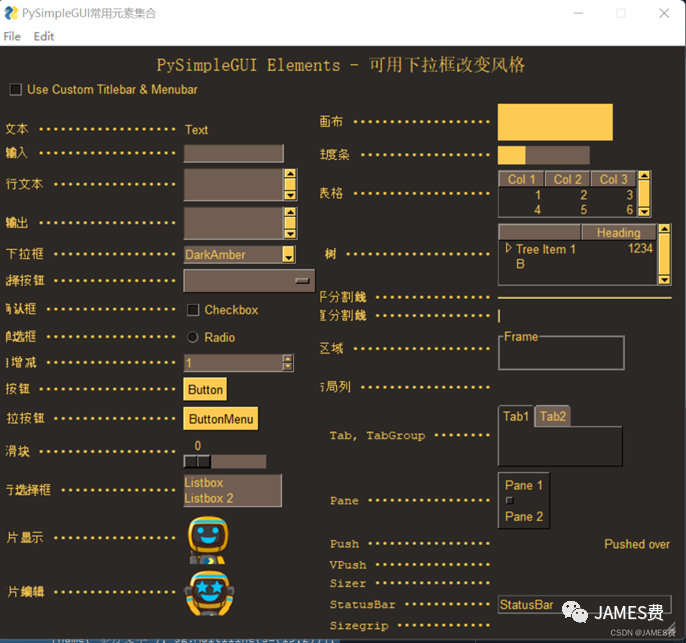
实现代码如下:
# -*- coding: utf-8 -*-
import PySimpleGUI as sg
"""
Demo - Element List
All elements shown in 1 window as simply as possible.
Copyright 2022 PySimpleGUI
translated by JAMESFEI
"""
use_custom_titlebar = True if sg.running_trinket() else False
def make_window(theme=None):
NAME_SIZE = 23
def name(name):
dots = NAME_SIZE-len(name)-2
return sg.Text(name + ' ' + '•'*dots, size=(NAME_SIZE,1), justification='r',pad=(0,0), font='Courier 10')
sg.theme(theme)
# NOTE that we're using our own LOCAL Menu element
if use_custom_titlebar:
Menu = sg.MenubarCustom
else:
Menu = sg.Menu
treedata = sg.TreeData()
treedata.Insert("", '_A_', 'Tree Item 1', [1234], )
treedata.Insert("", '_B_', 'B', [])
treedata.Insert("_A_", '_A1_', 'Sub Item 1', ['can', 'be', 'anything'], )
layout_l = [
[name('文本'), sg.Text('Text')],
[name('输入'), sg.Input(s=15)],
[name('多行文本'), sg.Multiline(s=(15,2))],
[name('输出'), sg.Output(s=(15,2))],
[name(' 下拉框'), sg.Combo(sg.theme_list(), default_value=sg.theme(), s=(15,22), enable_events=True, readonly=True, k='-COMBO-')],
[name('选择按钮'), sg.OptionMenu(['OptionMenu',],s=(15,2))],
[name('确认框'), sg.Checkbox('Checkbox')],
[name('单选框'), sg.Radio('Radio', 1)],
[name('自增减'), sg.Spin(['1','2','3','4','5'], s=(15,2))],
[name('按钮'), sg.Button('Button')],
[name('下拉按钮'), sg.ButtonMenu('ButtonMenu', sg.MENU_RIGHT_CLICK_EDITME_EXIT)],
[name('滑块'), sg.Slider((0,10), orientation='h', s=(10,15))],
[name('多行选择框'), sg.Listbox(['Listbox', 'Listbox 2'], no_scrollbar=True, s=(15,2))],
[name('图片显示'), sg.Image(sg.EMOJI_BASE64_HAPPY_THUMBS_UP)],
[name('图片编辑'), sg.Graph((125, 50), (0,0), (125,50), k='-GRAPH-')] ]
layout_r = [[name('画布'), sg.Canvas(background_color=sg.theme_button_color()[1], size=(125,40))],
[name('进度条'), sg.ProgressBar(100, orientation='h', s=(10,20), k='-PBAR-')],
[name('表格'), sg.Table([[1,2,3], [4,5,6]], ['Col 1','Col 2','Col 3'], num_rows=2)],
[name('树'), sg.Tree(treedata, ['Heading',], num_rows=3)],
[name('水平分割线'), sg.HSep()],
[name('垂直分割线'), sg.VSep()],
[name('区域'), sg.Frame('Frame', [[sg.T(s=15)]])],
[name('布局列'), sg.Column([[sg.T(s=15)]])],
[name('Tab, TabGroup'), sg.TabGroup([[sg.Tab('Tab1',[[sg.T(s=(15,2))]]), sg.Tab('Tab2', [[]])]])],
[name('Pane'), sg.Pane([sg.Col([[sg.T('Pane 1')]]), sg.Col([[sg.T('Pane 2')]])])],
[name('Push'), sg.Push(), sg.T('Pushed over')],
[name('VPush'), sg.VPush()],
[name('Sizer'), sg.Sizer(1,1)],
[name('StatusBar'), sg.StatusBar('StatusBar')],
[name('Sizegrip'), sg.Sizegrip()] ]
# Note - LOCAL Menu element is used (see about for how that's defined)
layout = [[Menu([['File', ['Exit']], ['Edit', ['Edit Me', ]]], k='-CUST MENUBAR-',p=0)],
[sg.T('PySimpleGUI Elements - 可用下拉框改变风格', font='_ 14', justification='c', expand_x=True)],
[sg.Checkbox('Use Custom Titlebar & Menubar', use_custom_titlebar, enable_events=True, k='-USE CUSTOM TITLEBAR-', p=0)],
[sg.Col(layout_l, p=0), sg.Col(layout_r, p=0)]]
window = sg.Window('PySimpleGUI常用元素集合', layout, finalize=True, right_click_menu=sg.MENU_RIGHT_CLICK_EDITME_VER_EXIT, keep_on_top=True, use_custom_titlebar=use_custom_titlebar)
window['-PBAR-'].update(30) # Show 30% complete on ProgressBar
window['-GRAPH-'].draw_image(data=sg.EMOJI_BASE64_HAPPY_JOY, location=(0,50)) # Draw something in the Graph Element
return window
window = make_window()
while True:
event, values = window.read()
# sg.Print(event, values)
if event == sg.WIN_CLOSED or event == 'Exit':
break
if event == 'Edit Me':
sg.execute_editor(__file__)
if values['-COMBO-'] != sg.theme():
sg.theme(values['-COMBO-'])
window.close()
window = make_window()
if event == '-USE CUSTOM TITLEBAR-':
use_custom_titlebar = values['-USE CUSTOM TITLEBAR-']
sg.set_options(use_custom_titlebar=use_custom_titlebar)
window.close()
window = make_window()
elif event == 'Version':
sg.popup_scrolled(sg.get_versions(), __file__, keep_on_top=True, non_blocking=True)
window.close()
5.3 opencv+PySimpleGUI实现图片颜色查找应用实例
本小节示例,利用opencv的颜色查找函数cv2.inRange和PySimpleGUI的滑动条等工具,做了一个可对任意图片进行手动颜色查找的小工具:
效果如下:
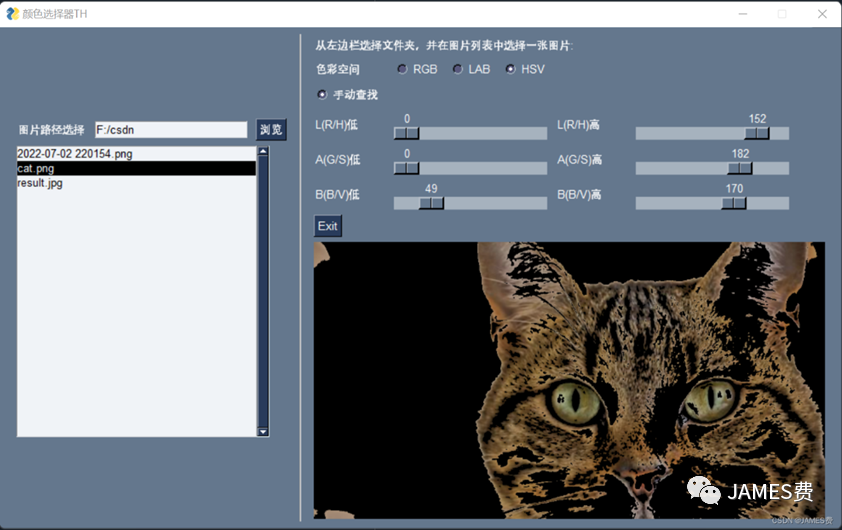
如上图所示,小程序可以在左边栏选择对应的文件夹并显示带有图片的列表,部分代码如下:
(1)利用PySimpleGUI打开文件夹并读入图片文件到列表框
left_column = [
[
sg.Text("图片路径选择"),
sg.In(size=(25, 1), enable_events=True, key="-FOLDER-"),
sg.FolderBrowse('浏览'),
],
[
sg.Listbox(
values=[], enable_events=True, size=(40, 20), key="-FILE LIST-"
)
],
]
"""
此部分省略
"""
if event == "-FOLDER-":
folder = values["-FOLDER-"]
try:
file_list = os.listdir(folder)
except:
file_list = []
fnames = [
f
for f in file_list
if os.path.isfile(os.path.join(folder, f))
and f.lower().endswith((".png", ".gif",".jpg"))
]
win["-FILE LIST-"].update(fnames)
if len(fnames)==0:
loaded=None
if event == "-FILE LIST-":
try:
imgname = os.path.join(
values["-FOLDER-"], values["-FILE LIST-"][0]
)
inputimg=cv2.imread(imgname)
print(imgname)
loaded=1
except:
pass
(2)利用PySimpleGUI创建以滑动条为主的颜色查找UI
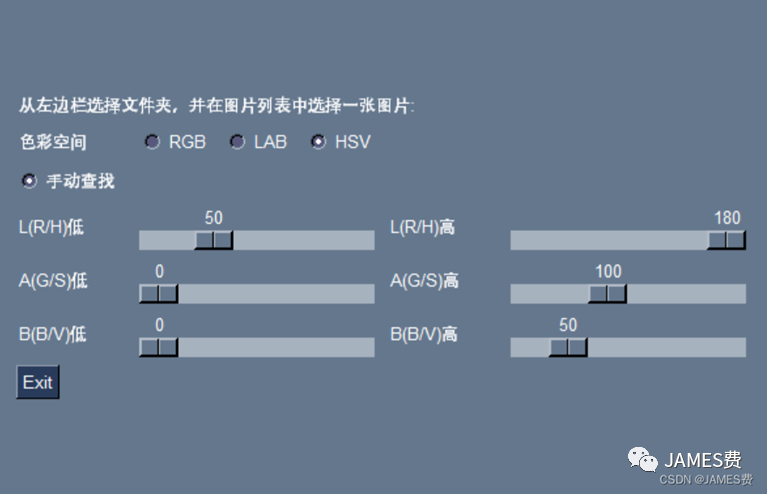
right_column = [
[sg.Text("从左边栏选择文件夹,并在图片列表中选择一张图片:")],
[ sg.Text('色彩空间',size=(10, 1)),sg.Radio('RGB', "333",key="-RGB-"),
sg.Radio('LAB', "333",key="-LAB-"),
sg.Radio('HSV', "333",default=True,key="-HSV-")],
[sg.Radio('手动查找', "111",default=True,key="-manhand-") ],
[sg.Text('L(R/H)低',size=(10, 1)),sg.Slider((0, 255), argTH["LOW"][0], 1, orientation='h', size=(20, 15), key='-lrhlow-'),
sg.Text('L(R/H)高',size=(10, 1)), sg.Slider((0, 255), argTH["UPE"][0], 1, orientation='h', size=(20, 15), key='-lrhup-'),
],
[sg.Text('A(G/S)低',size=(10, 1)),sg.Slider((0, 255), argTH["LOW"][1], 1, orientation='h', size=(20, 15), key='-agslow-'),
sg.Text('A(G/S)高',size=(10, 1)),sg.Slider((0, 255), argTH["UPE"][1], 1, orientation='h', size=(20, 15), key='-agsup-'),
],
[sg.Text('B(B/V)低',size=(10, 1)),sg.Slider((0, 255), argTH["LOW"][2], 1, orientation='h', size=(20, 15), key='-bbvlow-'),
sg.Text('B(B/V)高',size=(10, 1)), sg.Slider((0, 255), argTH["UPE"][2], 1, orientation='h', size=(20, 15), key='-bbvup-')
],
[sg.Button('Exit')],
[sg.Image(filename='', key='-IMAGE-')],
]
(3)颜色查找后台我们用opencv的cv2.inRange函数(可以参考上面的表格)
核心代码如下:
"""
通过颜色上下限,过滤图像
"""
if inputimg.shape[2]==3:
if mod=='rgb'or mod==0:
rhl=cv2.cvtColor(inputimg,cv2.COLOR_BGR2RGB)
elif mod=='hsv'or mod==1:
rhl = cv2.cvtColor(inputimg, cv2.COLOR_BGR2HSV)
elif mod=='lab'or mod==2:
rhl = cv2.cvtColor(inputimg, cv2.COLOR_BGR2LAB)
#变换图像 = cv2.GaussianBlur(变换图像, (7, 7), 0)
if type(LOW)==type([]):
LOW=np.array(LOW)
if type(UPE)==type([]):
UPE=np.array(UPE)
mask = cv2.inRange(rhl, LOW, UPE)
output = cv2.bitwise_and(inputimg, inputimg, mask = mask)
B14 桌面物体识别基本流程
摄像头获取一张图像之后,要对图像中的特定物体进行识别,在机器人项目的任务中主要是获取目标物体的位置信息,本篇讨论的是固定场景在某一水平桌面中的物体识别任务,且不通过深度神经网络等高级识别算法识别。想要利用机器视觉识别桌面中的特定物体,并获得该物体的位置信息,最基本的流程如下所示:
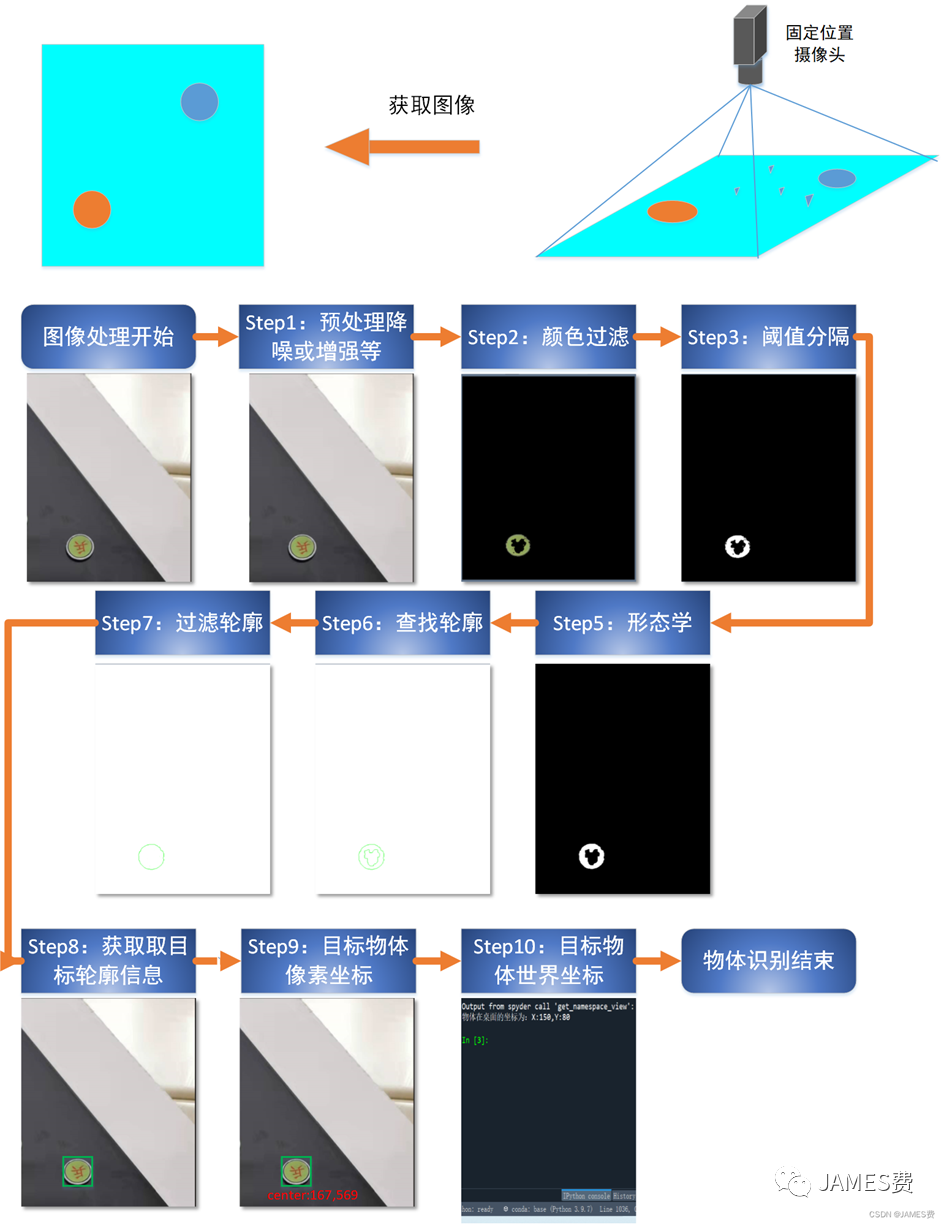
如上图解所示,一个固定场景桌面物体识别的基本流程主要是通过:
(1) 读取摄像头彩色图像,对应的函数为:
img=cv2.imread(“D:\\image.jpg”)
(2) 对读取的图像进行预处理(这一步非必要),图像中如果存在影响物体的识别噪点,或者由于光线等原因相机拍摄色彩失真等,可以通过一些去噪、色彩增强等方法进行预处理。
(3) 对图像进行颜色的过滤查找。本例场景较为简单,通过查找绿色就能把目标物体给分离出来。代码见前5.2.3-2小节。
(4) 对分离出来的物体颜色进行阈值分割,进一步突出,并转换为二值图,对应函数为:
#先转灰度图
gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
thred_img= cv2.threshold(gray_img,127,255, cv2.THRESH_BINARY)
(5) 利用形态学去掉一些周边相同颜色的小噪点,以免影响轮廓查找的准确性。对应函数为:
#定义核
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
# 椭圆结构
erode_img=cv2.erode(b_img,kernel,3)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
# 椭圆结构
dilate_img=cv2.dilate (b_img,kernel,3)
(6) 利用opencv轮廓查找函数进行查找轮廓,对应的函数为:
image,contours,hierarchy=cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
#contours即为轮廓像素坐标点
(7)对找到的轮廓进行进一步过滤,如过滤掉相互包含的轮廓,认为是同一个物体。
(8)根据过滤后的轮廓的信息,计算物体的中心点,得到像素坐标
(9)根据相机位置、焦距等参数信息,将像素坐标转化为真实桌面上的物理坐标(坐标转化详见下一节)。
以上就是桌面图像中物体识别基本流程。
总的来讲,图像的识别可以认为是一条流水线,从图像源头(好比是原料)开始,经过一个一个具有先后顺序的加工处理模块,最后输出一个目标值(好比是最终的产品)。
B13 图像的坐标变换(从像素坐标到机械臂坐标)
当一副原始的图像经过图像识别“流水线”得到一个目标输出时(通常是目标物体的像素坐标),我们需要跟据这个像素坐标,找到较为准确的与之对应的现实世界的坐标,然后就可以让处于同一现实世界坐标系的机器人或者机器去执行相应的抓取物体等行为。将图片中的像素坐标与现实世界坐标(一般称“世界坐标”)建立对应联系的过程,就叫做图像的坐标变换。
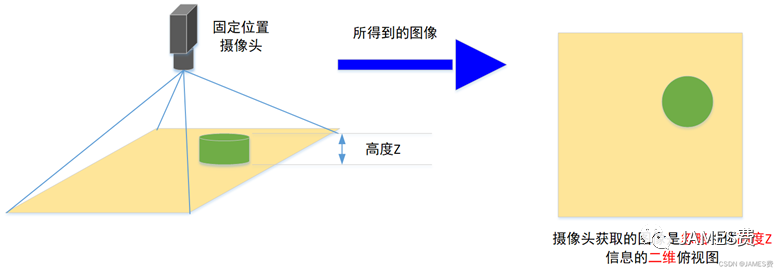
要建立图像像素与现实世界位置的完全的精确的联系,是十分复杂的推演过程,且对摄像头的性能、精度、和功能也有极高的要求,需要用到双目摄像头、或者是激光摄像头等较高级的成像设备,不在本篇的讨论范围之内。本篇主要讨论的是一般的家用500万(或以上)像素的单目摄像头获取的水平桌面的图像,建立图像像素与水平桌面的坐标的关系的原理。所谓的水平桌面,如下图所示,是指忽略高度维度的一个二维等高平面,摄像头摆放的位置是固定的且接近对水平面的俯视状态,这样桌面上的物体的图像,可以近似的认为是物体在桌面的投影即忽略高度的俯视图:
本小节接下来的内容是说明图像上像素坐标系(U,V)与水平桌面坐标(X,Y)的对应关系建立的简单数学过程,如下图:
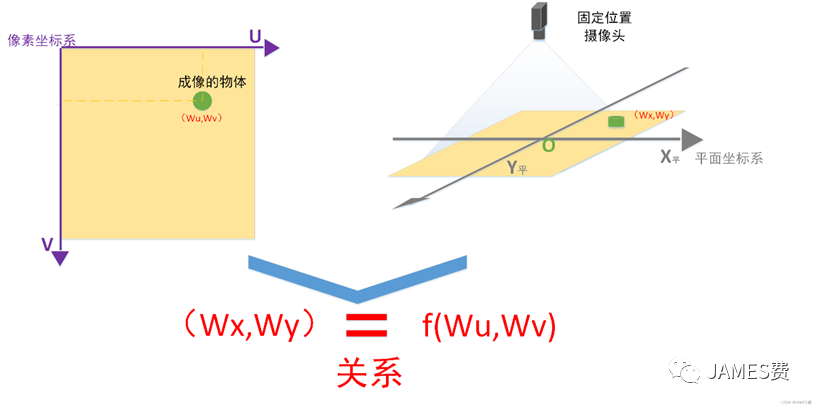
如上图所示,建立两个坐标系统的关系,我们做一些必要的约束和假设:
(1)假设摄像头是正对着平面坐标系统的原点,且镜头与平面是平行的,因此,成像后图像的中心与平面坐标的原点重合。
(2)假设摄像头的焦距是已知的且没有畸变(摄像头获取的图像没有变形)
(3)摄像头到平面坐标原点的距离是固定的,并且摄像头的镜头相对平面是没有水平方向的旋转的(直观的认为成像后,图像的U轴与平面的X轴是平行的,图像的V轴与平面的Y轴是平行的)
根据以上的解释,我们就可以建立起了两者的联系,(用初小知识)计算过程图解如下:
(---下篇完---)
