




初次见面
2020年,第一次接触1.3.x版本,刚开始是新奇和怀疑,这个平台真的可以顺利迁移oracle数据到OB吗。
测试阶段问题就很多。全量迁移效率太慢。全量迁移还未结束,增量store解析的日志就断了等等。当时的任务界面虽然详细但是比较繁琐,真正配置任务的时候需要手工去跳过一些任务,全量迁移可以通过oms的8080端口登录到全量迁移界面详细查看,更不用说还有迁移表结构报错,对于无主键表需要勾选相关选项,增量迁移效率也存在问题,一条链路中配置表太多也会有白名单过长的问题,后来ob的同学一点点解决,也不断发版更新组件,后来1.4.x版本相对就好很多,但是仍然存在问题,比如白名单问题虽然有时候不报错了,但是有字符限制被截断了,在截断前的表增量同步可以正常同步,但是截断后的表没办法正常同步,可以通过修改oms的meta库的字段类型来规避相关问题,我们也总结了一些经验,一条链路中尽量配置小于2000张表,但是这款产品虽然用了挺久,但是仍然有很多不便,比如如果遇到一些故障场景需要重新拉取store或者修改store或者write的参数,只能去后台修改,通过curl停止修改拉起组件,而且监控页面也是分离的无法在迁移任务界面直接看到延迟情况。再比如有的场景需要上线ob之后还要迁移部分数据回到其他的oracle库,那就需要先配置正向链路跳过相关步骤直接发起反向,对于经验少的同学比较不友好。
对于历史版本我暂时也不吐槽太多了,大家有兴趣可以翻翻我以前记录的一些东西。
https://zhuanlan.zhihu.com/p/274768673
https://zhuanlan.zhihu.com/p/274780748
改头换面
再后来我们就用上了3.1.x的版本,整个界面都有了改头换面的变化。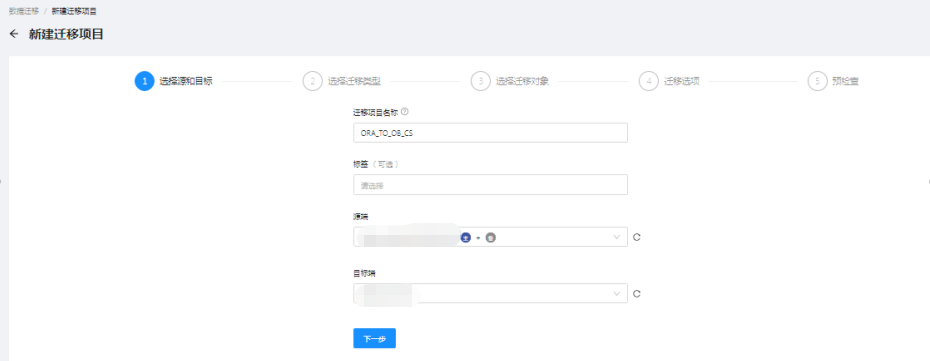
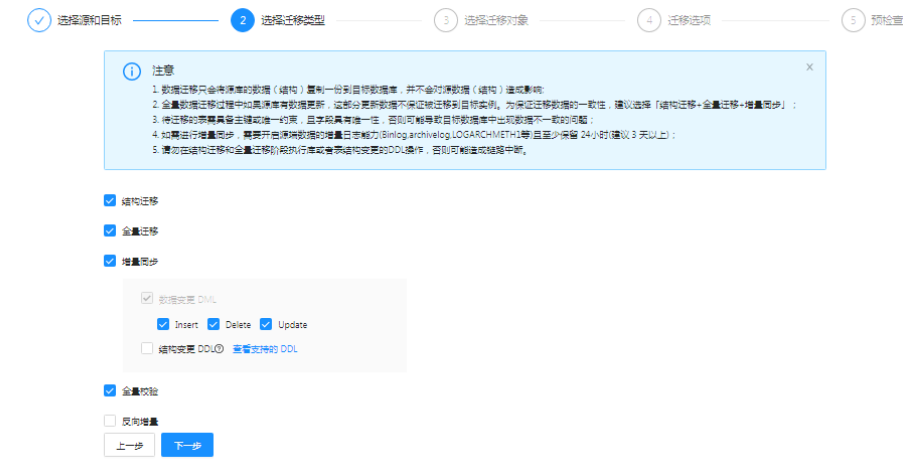
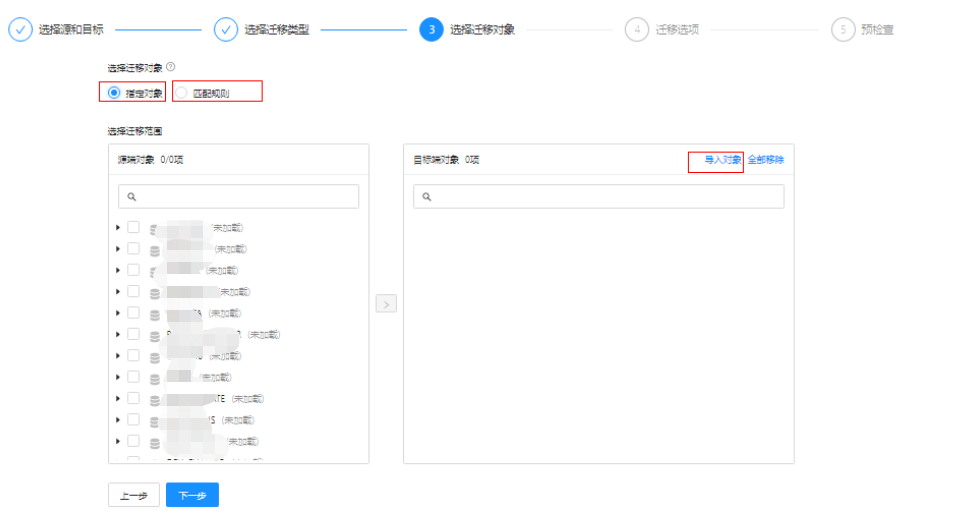
相对老版本,这个版本的任务配置更简洁合理,可以选择需要进行的子任务,可以更灵活的配置迁移选项
注意事项
1.oms平台参数配置
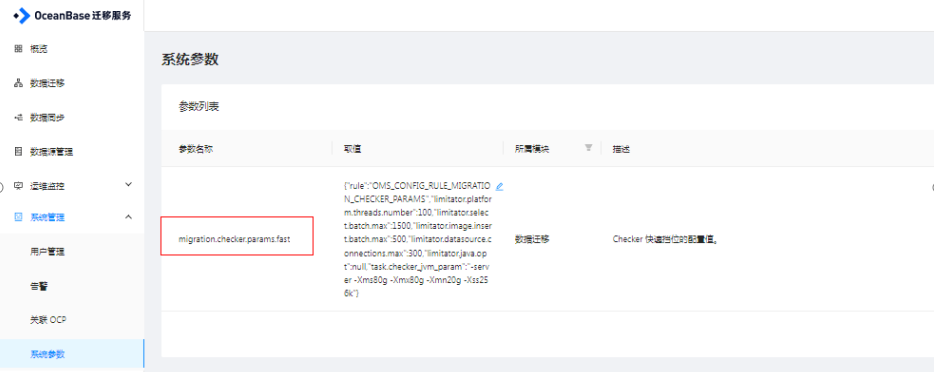
2.后台的一些修改
1>oms的meta库调整
1)备注超长
oms_rm:
alter table oms_struct_migration_record modify column extra_msg mediumtext;
alter table oms_struct_migration_record modify column post_sql mediumtext;
这个表字段在3.x的后面版本自己修改过不需要手动再去改了
2)全量迁移乱码报错跳过
oms_cm:
insert into config_template(task_type,db_type,task_version,`key`,value,scope,file_name,file_path,gmt_created,gmt_modified,dest_db_type) values('checker',null,'1.0','image.insert.error.ignore','true','datasource','checker.conf','/home/ds/run/{taskname}/conf/',now(),now(),null);
2>docker配置修改(oat安装的oms可能资源小,需要调整)
##查看docker信息
docker inspect oms
docker stats oms
docker ps -a
##停 docker
systemctl stop docker
##修改配置文件
/docker/containers/fdc3d4cd1ef5476f827fcea05c70963672a29de29d9df0e89a95241fb64f878b/hostconfig.json
##起docker
systemctl start docker
3>store的jvm修改
这个可以修改全局或者单条store的配置
在docker内修改/home/ds/kafka/bin/connect-drcdeliver.sh中的export KAFKA_HEAP_OPTS后面参数大小,之后新建store的内存大小都是新设置的
也可以在store新拉的时候停止,后台修改这个store 的目录下的kafka下参数大小,单独修改这一个store的大小
3.oms平台的一些功能变化

可以直接配置关联ocp,3.x前期版本任务强制需要关联ocp,后面版本不需要强制关联ocp,但是告警如果需要推送到ocp的话还是要配置,可以通过前台直接配置告警频率和级别
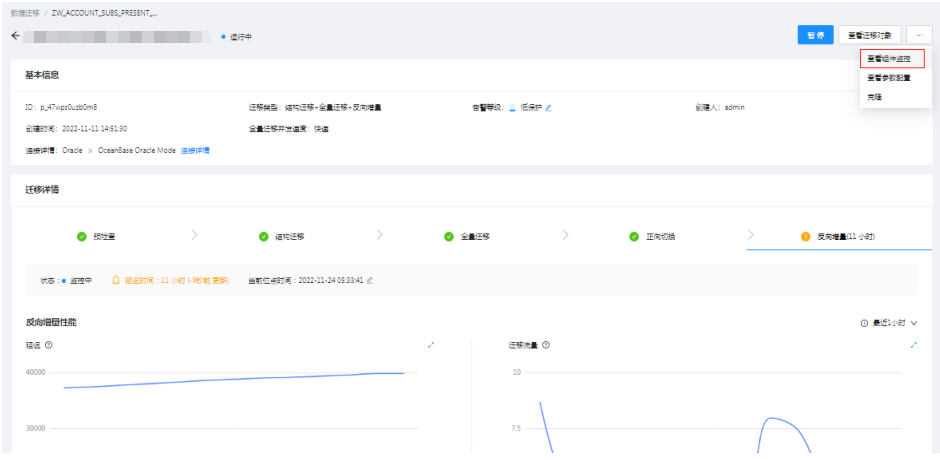
1.x版本的oms需要单独进入监控页面去查看延迟情况,如果有情况需要拉取新的store或者修改组件参数都要进入后台,3.x版本可以直接通过前台组件进行全部的监控和前台新增,也可以再前台直接更新组件参数。

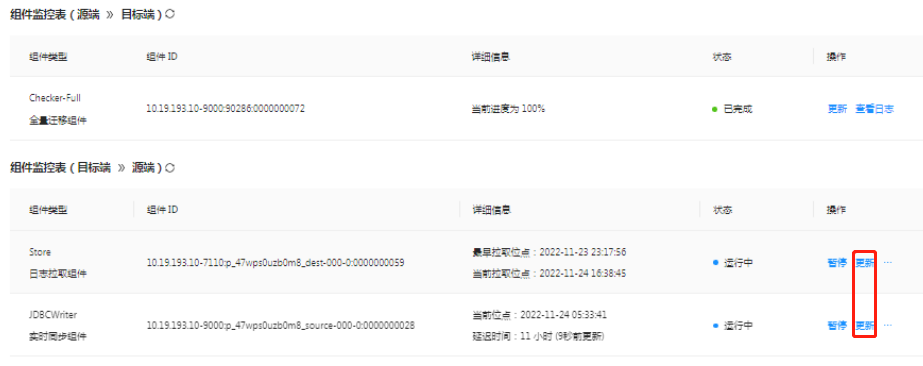
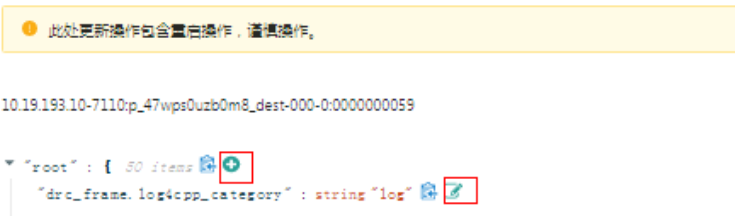
可以新增或者修改组件的参数
4.oms调度过程中的注意事项
1>需要校验了但是没有自动切换到后续任务(不止该场景)
MySQL [oms_rm]> select step_order,step_name,step_desc,step_status from oms_step where project_id='p_44qher04psxs' order by step_order;
+------------+-------------------+--------------------+-------------+
| step_order | step_name | step_desc | step_status |
+------------+-------------------+--------------------+-------------+
| 1 | PRE_CHECK | 预检查 | FINISHED |
| 2 | PREPARE | 迁移准备 | FINISHED |
| 3 | STRUCT_MIGRATION | 结构迁移 | FINISHED |
| 4 | INCR_LOG_PULL | 增量日志拉取 | FINISHED |
| 5 | FULL_MIGRATION | 全量迁移 | FINISHED |
| 6 | INCR_SYNC | 增量迁移 | MONITORING |
| 7 | FULL_VALIDATION | 全量校验 | RUNNING |
| 8 | APP_SWITCH | 正向切换 | INIT |
| 9 | REVERSE_INCR_SYNC | 反向增量 | INIT | -
+------------+-------------------+--------------------+-------------+
##修改增量任务状态,可以自动进入下个任务
update oms_step set step_status='MONITORING' where step_name='INCR_SYNC' and step_status='RUNNING' and project_id='p_44qher04psxs';
ps:比如全量任务开始,但我想跳过,可以后台杀掉全量校验的进程,后台将全量校验的状态改为FINISHED。
2>hash表校验
3.x前期版本需要单独配置校验链路添加参数,这样才能保证校验准确,但是耗时也比较长(ps:也可以修改hash分区表名来规避)
filter.verify.inmod.tables: .*;.*;.*
3.x后期版本checker组件更新可以与普通表一样校验,但是最好还是拆成单独链路,配置以下参数校验
limitator.verify.oracle.rowid.querydst.withpartition":string"false"
3>新拉store
简单介绍几个需要新拉store的场景,比如store解析有瓶颈需要多拉几个不同时间段的store同步解析,或者生产oracle是3节点rac,adg是2节点,这种主备节点不一致的情况。
curl http://10.19.xxx.xxx:8088/crawler/start -d "topic=p_3rhz1ubgb3y8_source-000-0&checkpoint=::::1654401600:&role=master&type=DELIVER2STORE&deliver2store.logminer.selector_thread_num=128&deliver2store.logminer.use_independent_fetcher_per_instance=true&deliver2store.logminer.instance_threads=1|2|3"
4>writer修改位点
1.#改位点
sudo curl -XPOST 'http://134.80.184.66:8088/JDBCWriter/update' -d "writerName=134.80.xx.xx-9000:oms_source_topic_1000125_RATING-000-0:0000063963" -d "JDBCWriter.timestamp=1660831499"
2.#拉起
sudo curl -XPOST 'http://134.80.184.66:8088/JDBCWriter/start' -d "writerName=134.80.xx.xx-9000:oms_source_topic_1000125_RATING-000-0:0000063963" -d "resuming=false"
5>store和writer的一些常用参数
1.跳过报错
比如oracle11g对于对象名称长度的字符限制比较小,如果开了ddl同步,反向切换的时候删除oms自动创建的uk,可能会报字符超长的报错,但是oracle端是没有这个索引的,所以可以跳过这个报错码
sudo curl -XPOST 'http://134.84.xx.xx:8088/JDBCWriter/update' -d "writerName= 134.84.xx.xx-9000:p_39q0zheaooqo_dest-000-0:0000000053&JDBCWriter.sinkFile.skipErrorCode=12899,01847"
在3.1版本后该参数改为了数组类型所以需要这样改
sudo curl -XPOST 'http://134.84.xx.xx:8088/JDBCWriter/update' -d "writerName= 134.84.xx.xx-9000:p_39q0zheaooqo_dest-000-0:0000000053&JDBCWriter.sinkFile.skipErrorCode=[12899],[01847]"
2.store参数调整,如果有相关效率问题可以尝试调整,可能不全,比如writer的work_num参数之类,还需要结合实际情况
###store
deliver2store.logminer.fetch_arch_logs_max_parallelism_per_instance= 日归档/500g +1
deliver2store.logminer.max_actively_staged_arch_logs_per_instance= 上面参数*2
deliver2store.logminer.staged_arch_logs_in_memory = true
###writer
JDBCWriter.sinkFile.useTargetIndex":string"true"
JDBCWriter.coordinatorFile.hotKeyMerge=true
3.注意补充点
对于一些热表大表均分到不同链路或者单独配置比较好
4.单独配置ob同步到oracle
使用sys用户登录OceanBase_Oracle数据库。
1)创建内部用户__OCEANBASE_INNER_DRC_USER。
create user '__OCEANBASE_INNER_DRC_USER'@'%' IDENTIFIED BY uy1n8666;
2) 分配all权限给__OCEANBASE_INNER_DRC_USER。
grant ALL to '__OCEANBASE_INNER_DRC_USER';
3)分析无主键数据可能还要补充一些权限
grant select on sys.dba_tables to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_part_tables to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_part_key_columns to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_subpart_key_columns to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_tab_partitions to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_objects to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_tab_subpartitions to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_indexes to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_ind_columns to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_constraints to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_tab_columns to '__OCEANBASE_INNER_DRC_USER';
grant select on sys.dba_tables to '__OCEANBASE_INNER_DRC_USER';
4)sql超时参数
limitator.sql.exec.max.noactive.time=2000000
总结
ob的迭代不止server,各种周边产品配套更新都很快,也很能解决客户的痛点,OCP和OMS是生态的两大产品,oms的进步可以看出产品的实力,也更能给予客户迁移的信心。
这篇记录可能不够全面,简单介绍了下自己的一点总结和经验,也有自己对于oms新老版本的一点看法,但是产品总是越来越好,越用越好用,也希望我的分享可以有些干货帮助到需要的同学,更希望ob发展的更好。
行之所向,莫问远方
