




什么是log file sync
顾名思义,log file sync 日志文件同步:即在事务的提交过程中,LGWR将修改产生的redo日志文件写入磁盘的过程,这个过程从开始到完成所耗费的时间就是log file sync等待事件。因此log file sync基本上可以说是在Oracle数据库中最普遍的等待事件之一。
从用户commit事务到事务提交完成这整个过程可以大概描述为六个环节,分别是:
1) 用户进程发起commit(主要是进程间通信的时间,采用post/wait的方式,典型的这种post/wait一般利用的是操作系统的信号量(IPC)实现,如果系统CPU资源充足,一般不会出现大的延迟)
2) 用户进程通知lgwr写日志(lgwr接收到前台进程的信号量后苏醒,为了获取CPU资源,等待CPU调度的时间,如果系统CPU资源充足,一般不会出现大的延迟。)
3) lgwr接收到请求开始写入磁盘(真正的物理IO时间,lgwr通知os把log buffer的内容写入到磁盘,然后lgwr进入睡眠,进入log file parallel write等待)
4) lgwr写入结束(os调度lgwr 重新获得CPU资源,lgwr 通知前台进程写完成)
5) lgwr通知用户进程写完成(前台进程接受到lgwr的通知,返回CPU运行队列,处理其他事务,到此log file sync结束。
6) 用户进程获得通知,继续做其他事
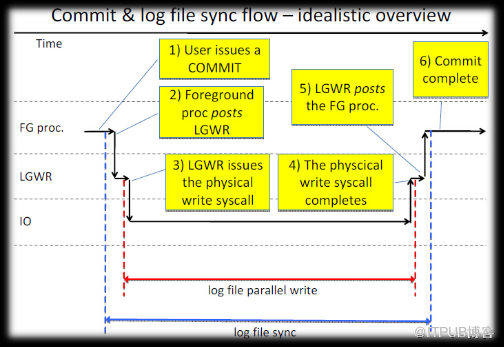
借用Tanel Poder画的流程图,我们可以更好更直观的看到这六个步骤的具体实现过程。
常见引起log file sync等待事件的原因
1、由于需要等待lgwr写redo logfile,因此,log file sync的等待时间涵盖了log file parallel write的时间
也就是上文说到的真正的物理IO时间,lgwr通知os把log buffer的内容写入到磁盘,然后lgwr进入睡眠,进入log file parallel write等待,由于写磁盘是比较慢的操作,因此这个时间正常情况下的延迟占整个log file sync的大部分时间,log file parallel write的时间大小主要取决于磁盘的IO性能和需要写入的日志量,如果磁盘的IO性能越好、需要写入的日志量越少,那么log file parallel write的时间就会越小。还需要指出,lgwr在获取CPU资源后,可能并不能马上通知os写磁盘,只有在确保所有的重做复制闩锁都已经被释放,才能开始真正的IO操作。
2、频繁的事务操作引起:
· commit操作
· rollback操作
· DDL操作(DDL操作实施前都会首先进行一次commit)
· DDL操作导致的数据字典修改所产生的log file sync
· 某些能递归修改数据字典的操作:比如查询SEQ的next值,可能会导致修改数据字典。一个典型的情况是,SEQ的cache属性设置为nocache,那么会导致每次调用SEQ都要修改数据字典,产生递归的log file sync。
一个正常的系统里,绝大多数的log file sync等待都应该是commit操作造成的log file sync等待,某些异常的系统,比如频繁的rollback、seq的cache设置为nocache的系统,也可能会造成比较多的log file sync等待。
具体样例
这里我们可以参考了张维照大神的一篇文章: Oracle redo file on SSD 之等待事件 ‘log file sync’
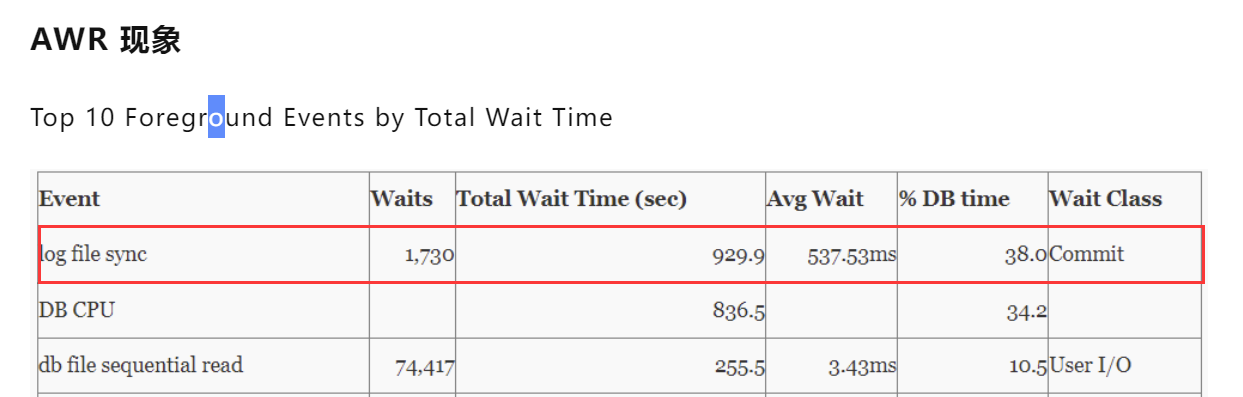
这里可以看到log file sync已经高达500ms,属于极其不正常的情况。并且查询到当时的CPU负载和IO吞吐量都是不高的水平。
具体情况请参考原文:https://www.modb.pro/course/article/160?lsId=6885&catalogId=1
