




1. 字符集与编码
字符集(character set) 是某些字符的集合,为每个字符分配一个唯一的 ID,称为 “Code Point(码位或码点)”。
编码规则 是将 Code Point 转换为字节序列(即 0 和 1)的规则。
通俗地理解,就是不同的字符集规定了字符集中都包含哪些字符,而 编码规则 规定了每个字符在计算机中的 0、1 表达方式。
常用的字符集编码有:
- ASCII 字符编码:既是字符集,又是编码。
- latin1 字符编码:既是字符集,又是编码。
- GB2312 字符编码:既是字符集,又是编码。
- GBK 字符编码:既是字符集,又是编码。
- UTF-8:只是字符编码,对应的字符集为 Unicode。
为了便于统一管理各地区、各国家的编码规则,标准化组织用 “页码” 对众多的编码规则进行了编号,如 GBK 的页码为 956,而 UTF-8 的页码为 65001。这样,直接通过页码即可找到所需的编码规则。
1.1. ASCII 字符集
ASCII 共收录 128 个字符,包含空格、标点符号、数字、大小写字母和一些不可见字符。由于总共才 128 个字符,所以可以使用 1 个字节来进行编码。即 ASCII 既是字符集又是编码规则。我们看一些字符的编码方式:
'L' -> 01001100(十六进制:0x4C,十进制:76) 'M' -> 01001101(十六进制:0x4D,十进制:77)
1.2. ISO 8859-1 字符集
ISO 8859-1(别名 latin1) 共收录 256 个字符,在 ASCII 字符集的基础上又扩充了 128 个西欧常用字符(包括德法两国的字母),也可以使用 1 个字节来进行编码。即 ISO 8859-1 既是字符集又是编码规则。
1.3. GB2312 字符集
GB2312 是第一个汉字编码国家标准,由中国国家标准总局于 1980 年发布,1981 年 5 月 1 日开始使用。GB2312 编码共收录汉字 6763 个,其中一级汉字 3755 个,二级汉字 3008 个。同时,GB2312 编码收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682 个全角字符。即 GB2312 既是字符集,又是编码规则。
有关 GB2312 字符编码,详见 https://www.qqxiuzi.cn/zh/hanzi-gb2312-bianma.php
1.4. GBK 字符集
GBK 是对 GB2312 的补充,完全兼容 GB2312。同 GB2312 一样,GBK 也既是字符集,又是编码规则。
1.5. Unicode 字符集
Unicode(Universal Multiple-Octet Coded Character Set)是由名为 Unicode 的学术机构推出的字符集,旨在收录人类目前已知在用的所有字符, 给它们进行统一的分类和编号。但是,Unicode 只负责给字符编号,却未规定具体的编码规则。即 Unicode 只规定了字符集。
而 UTF-8, UTF-16, UTF-32 就是对 Unicode 字符集具体的编码规则。
1.5.1. UTF-8 编码
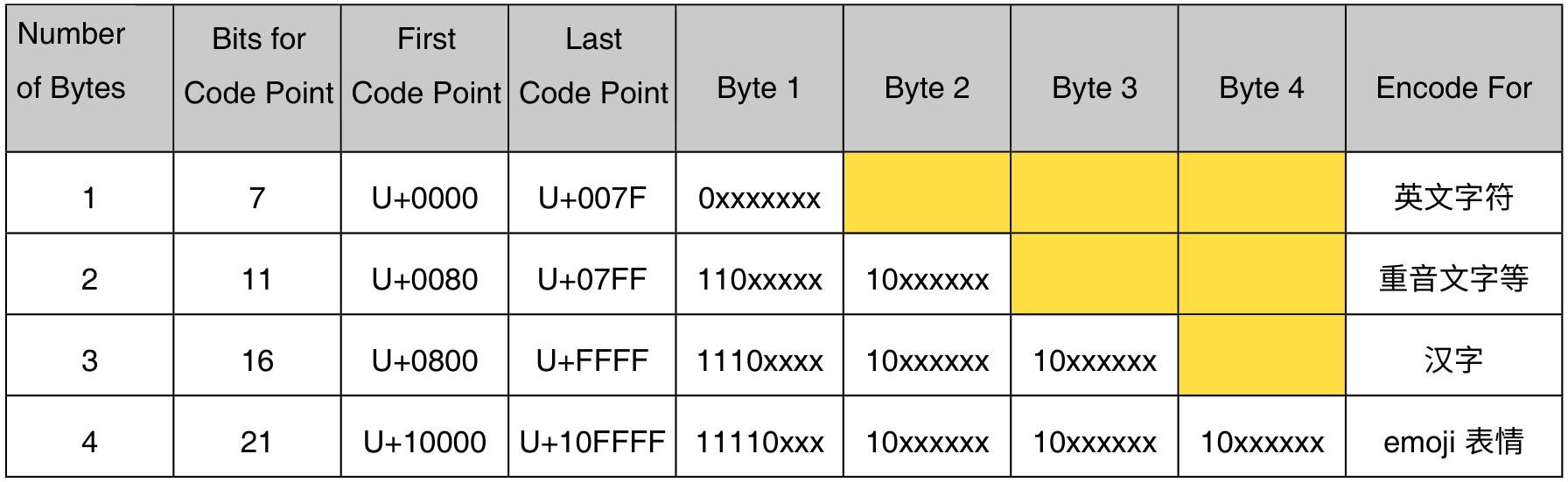
UTF-8 编码使用 变长编码 规则,用 1-4 个字节表示 Unicode 中的 1 个字符。UTF-8 编码规定:
- 最高位以 0 开头的字节,用 1 个字节表示 1 个字符,如英文字符;
- 最高位以 110 开头的字节,与其后 1 个以 10 开头的字节拼接为一个整体,即用 2 个字节表示 1 个字符;
- 最高位以 1110 开头的字节,与其后 2 个以 10 开头的字节拼接为一个整体,即用 3 个字节表示 1 个字符,如汉字。
- 最高位以 11110 开头的字节,与其后 3 个以 10 开头的字节拼接为一个整体,即用 4 个字节表示 1 个字符,如 emoji 表情。
1.5.2. UTF-16 编码
UTF-16 编码使用 定长编码 规则,固定地使用 2 个字节来表示 Unicode 中的 1 个字符。
在 Windows 系统中,常常会同时出现 UTF-8 和 Unicode 两个编码规则。按道理,Unicode
只是字符集,不应出现在编码规则当中。原因是,微软默认将 Unicode 当作 UTF-16 来处理。
1.5.3. UTF-32 编码
UTF-32 编码使用 定长编码 规则,固定地使用 4 个字节来表示 Unicode 中的 1 个字符。直接根据 Unicode 中的字符编号对字符进行编码。优点是无需额外的解析工作,缺点是常用字符有大量的高位被 0 填充,而造成空间浪费。
2. MySQL 中的字符集与排序规则
如下所示,可通过系统表 INFORMATION_SCHEMA.CHARACTER_SETS 查看 MySQL 中支持的字符集及默认的排序规则(省略了部分不常用的字符集)。
mysql> SELECT CHARACTER_SET_NAME,DEFAULT_COLLATE_NAME,MAXLEN FROM INFORMATION_SCHEMA.CHARACTER_SETS ORDER BY 1,2;
+--------------------+----------------------+--------+
| CHARACTER_SET_NAME | DEFAULT_COLLATE_NAME | MAXLEN |
+--------------------+----------------------+--------+
| ascii | ascii_general_ci | 1 |
| big5 | big5_chinese_ci | 2 |
| gb18030 | gb18030_chinese_ci | 4 |
| gb2312 | gb2312_chinese_ci | 2 |
| gbk | gbk_chinese_ci | 2 |
| latin1 | latin1_swedish_ci | 1 |
| latin2 | latin2_general_ci | 1 |
| latin5 | latin5_turkish_ci | 1 |
| latin7 | latin7_general_ci | 1 |
| utf16 | utf16_general_ci | 4 |
| utf16le | utf16le_general_ci | 4 |
| utf32 | utf32_general_ci | 4 |
| utf8 | utf8_general_ci | 3 |
| utf8mb4 | utf8mb4_0900_ai_ci | 4 |
+--------------------+----------------------+--------+
41 rows in set (0.00 sec)
2.1. utf8 与 utf8mb4
utf8(utf8mb3)
在 MySQL 中,utf8 是 utf8mb3 的别名,是严格过的 utf8 编码。用 1-3 个字节来编码 Unicode 字符集中的 1 个字符。该编码中,不包含 Emoji 表情等特殊字符。MySQL 从 8.0.30 开始,将 utf8 名称调整为 utf8mb3,如字符集 utf8mb3 及以 utf8mb3_ 为前缀的排序规则。
utf8mb4
正宗的 utf8 编码。使用 1-4 个字节来编码 Unicode 字符集中的 1 个字符,在 utf8mb3 的基础上,增加了对 Emoji 表情等特殊字符的编码支持;
2.2. 排序规则
排序规则(Collation)定义了字符集中每个字符的大小、先后顺序以及等价规则等。如在排序时,哪个字符在前、哪个字符在后、哪个字符与哪个字符相等。Collation 依赖于字符集(Character Set),比如 utf8mb4_general_ci 排序规则要求字符集需要为 utf8mb4;gbk_chinese_ci 排序规则要求字符集为 gbk。
若将字符看作人,Character Set 就相当于为每个字符发放一个身份证号,所有的身份证号组成了字符集。而 Collation 相当于规定在排队时,谁在前、谁在后。Collation 可以有多个,就相当于可灵活按身高、体重、年龄、出生地等维度来对每个人排序,却完全不会受到身份证号的干扰。
2.2.1. MySQL 中常用的排序规则
如下所示,可通过系统表 INFORMATION_SCHEMA.COLLATIONS 查看 MySQL 中主要字符集所支持的排序规则(省略部分不常用的规则)。
mysql> SELECT character_set_name, collation_name, is_default, pad_attribute FROM INFORMATION_SCHEMA.COLLATIONS WHERE character_set_name in ('utf8','utf8mb4','gbk','gb2312','ascii') ORDER BY 1,2;
+--------------------+----------------------------+------------+---------------+
| character_set_name | collation_name | is_default | pad_attribute |
+--------------------+----------------------------+------------+---------------+
| ascii | ascii_bin | | PAD SPACE |
| ascii | ascii_general_ci | Yes | PAD SPACE |
| gb2312 | gb2312_bin | | PAD SPACE |
| gb2312 | gb2312_chinese_ci | Yes | PAD SPACE |
| gbk | gbk_bin | | PAD SPACE |
| gbk | gbk_chinese_ci | Yes | PAD SPACE |
| utf8 | utf8_bin | | PAD SPACE |
| utf8 | utf8_general_ci | Yes | PAD SPACE |
| utf8 | utf8_general_mysql500_ci | | PAD SPACE |
| utf8 | utf8_german2_ci | | PAD SPACE |
| utf8 | utf8_spanish2_ci | | PAD SPACE |
| utf8 | utf8_spanish_ci | | PAD SPACE |
| utf8 | utf8_unicode_520_ci | | PAD SPACE |
| utf8 | utf8_unicode_ci | | PAD SPACE |
| utf8mb4 | utf8mb4_0900_ai_ci | Yes | NO PAD |
| utf8mb4 | utf8mb4_0900_as_ci | | NO PAD |
| utf8mb4 | utf8mb4_0900_as_cs | | NO PAD |
| utf8mb4 | utf8mb4_0900_bin | | NO PAD |
| utf8mb4 | utf8mb4_bin | | PAD SPACE |
| utf8mb4 | utf8mb4_cs_0900_ai_ci | | NO PAD |
| utf8mb4 | utf8mb4_cs_0900_as_cs | | NO PAD |
| utf8mb4 | utf8mb4_general_ci | | PAD SPACE |
| utf8mb4 | utf8mb4_german2_ci | | PAD SPACE |
| utf8mb4 | utf8mb4_spanish2_ci | | PAD SPACE |
| utf8mb4 | utf8mb4_spanish_ci | | PAD SPACE |
| utf8mb4 | utf8mb4_unicode_520_ci | | PAD SPACE |
| utf8mb4 | utf8mb4_unicode_ci | | PAD SPACE |
| utf8mb4 | utf8mb4_zh_0900_as_cs | | NO PAD |
+--------------------+----------------------------+------------+---------------+
109 rows in set (0.00 sec)
排序规则名称中的关键字解释如下:
utf8(utf8mb3):用 1-3 个字节来编码 Unicode 字符集中的 1 个字符;MySQL 从 8.0.30 开始,将 utf8 名称调整为 utf8mb3,如字符集 utf8mb3 及以 utf8mb3_ 为前缀的排序规则。TiDB 因兼容 MySQL 5.7,所以仍延用旧的名称 utf8;utf8mb4:使用 1-4 个字节来编码 Unicode 字符集中的 1 个字符,增加了对 Emoji 表情的支持;_bin:二进制存储,区分大小写。如 E 与 e 不等价;_cs(case sensitivity):区分大小写。如 E 与 e 不等价;_ci(case insensitivity):不区分大小写。如 E 与 e 等价;_as(accent sensitivity):区分音调,如 e、ē、é、ě、è 不等价;_ai(accent insensitivit):不区分音调,如 e、ē、é、ě、è 等价;_general:排序速度快,准确度低;_unicode:排序遵循 UCA 4.0.0 规范,速度慢,准确度高;MySQL 依据 UCA(Unicode Collation Algorithm)4.0.0 实现了 xxx_unicode_ci 排序规则;_520、_0900:排序遵循 UCA 5.2.0、UCA 9.0.0 规范;MySQL 在实现遵循 > UCA 4.0.0 的排序规则时,在排序规则名称中包含 UCA 版本号。如,utf8_unicode_520_ci 遵循 UCA 5.2.0 规范进行排序;utf8mb4_0900_ai_ci(MySQL 8.0 引入)遵循 UCA 9.0.0 规范进行排序;_chinese:按中文拼音排序,如如 ē<é<ě<è;_zh:特定于中文的 Unicode 排序。类似的还有:ja 特定于日语的排序、ru 特定于俄语的排序等;
2.3. 各级别字符集与排序规则
MySQL 有 4 个级别的字符集和比较规则,分别是:
- 服务器级别
- 数据库级别
- 表级别
- 列级别
- 字符串级别
2.3.1. 服务器级别
| 系统参数 | 动态设置 | 作用域 | 说明 |
|---|---|---|---|
| character_set_server | Y | BOTH | 用于设置服务器级别的默认字符集 |
| collation_server | Y | BOTH | 用于设置服务器级别的默认排序规则 |
可通过 SHOW GLOBAL VARIABLES 与 SET 来查看和修改服务器级别的字符集与排序规则。
mysql> SHOW GLOBAL VARIABLES LIKE 'character_set_server';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| character_set_server | utf8mb4 |
+----------------------+---------+
1 row in set (0.01 sec)
mysql> SHOW GLOBAL VARIABLES LIKE 'collation_server';
+------------------+--------------------+
| Variable_name | Value |
+------------------+--------------------+
| collation_server | utf8mb4_general_ci |
+------------------+--------------------+
1 row in set (0.00 sec)
mysql> SET PERSIST character_set_server='utf8mb3';
Query OK, 0 rows affected, 1 warning (0.00 sec)
也可在 MySQL 配置文件中,指定服务器级别的字符集与排序规则。
[mysqld] character_set_server= utf8mb4 collation-server = utf8mb4_general_ci
当修改了服务器级别的默认字符集后,排序规则会自动随之修改为该字符集对应的默认排序规则。
2.3.2. 数据库级别
在创建数据库时,可显式为其指定默认字符集及排序规则。也可通过 ALTER DATABASE 来变更数据库的默认字符集与排序规则。若在建库时,不显式指定字符集与排序规则,默认将继承服务器级别的设置。
mysql> CREATE DATABASE dbtest CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
mysql> ALTER DATABASE dbtest CHARACTER SET gbk COLLATE gbk_chinese_ci;
可通过只读系统参数 character_set_database 与 collation_database 来查看当前数据库的默认字符集与排序规则。参数值会随着数据库的变化而变化。
mysql> use dbtest;
mysql> SHOW VARIABLES LIKE 'character_set_database';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| character_set_database | utf8mb4 |
+------------------------+---------+
1 row in set (0.00 sec)
mysql> SHOW VARIABLES LIKE 'collation_database';
+--------------------+--------------------+
| Variable_name | Value |
+--------------------+--------------------+
| collation_database | utf8mb4_general_ci |
+--------------------+--------------------+
1 row in set (0.00 sec)
2.3.3. 表级别
在创建表时,可显式为其指定默认字符集及排序规则。也可通过 ALTER TABLE 来变更表的默认字符集与排序规则。若在建表时,未为其显式指定字符集与排序规则,则默认将继承自数据库级别的设置。
mysql> CREATE TABLE tbl01 (id int, name varchar(32)) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
mysql> ALTER TABLE tbl01 CHARACTER SET gbk COLLATE gbk_chinese_ci;
可通过 SHOW CREATE TABLE 来查看表的默认字符集与排序规则。
mysql> SHOW CREATE TABLE tbl01\G
*************************** 1. row ***************************
Table: tbl01
Create Table: CREATE TABLE `tbl01` (
`id` int DEFAULT NULL,
`name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=gbk
1 row in set (0.00 sec)
2.3.4. 列级别
对于存储字符串的列,同一个表中的不同列也可有不同的字符集和排序规则。可以在创建和修改列定义的时候指定该列的字符集和排序规则。若在建表时,未为字符串列指定字符集和排序规则,则默认继承自表级别的设置。
mysql> ALTER TABLE tbl01 MODIFY name varchar(32) CHARACTER SET gbk COLLATE gbk_chinese_ci;
2.3.5. 字符串级别
若 SELECT 字符串 时未指定字符集及排序规则,则默认继承自系统变量 character_set_connection 和 collation_connection。
mysql> SELECT _utf8mb4'盛京征信' COLLATE utf8mb4_bin;
+--------------------------------------------+
| _utf8mb4'盛京征信' COLLATE utf8mb4_bin |
+--------------------------------------------+
| 盛京征信 |
+--------------------------------------------+
1 row in set (0.00 sec)
3. 字符集转换
3.1. 转换过程
汉字 “我” 的 UTF-8 编码为 “0xE68891”,而其对应的 GBK 编码为 “0xCED2”。
当将汉字 “我” 的 UTF-8 编码 0xE68891 进行解码后,再按 GBK 字符集进行重编码为 0xCED2。我们将这个过程称为 字符集的转换,也就是汉字“我”从 UTF-8 字符集转换为 GBK 字符集。
可通过如下链接:http://www.mytju.com/classcode/tools/encode_utf8.asp 可查询汉字的编码。
3.2. MySQL 中的字符集转换
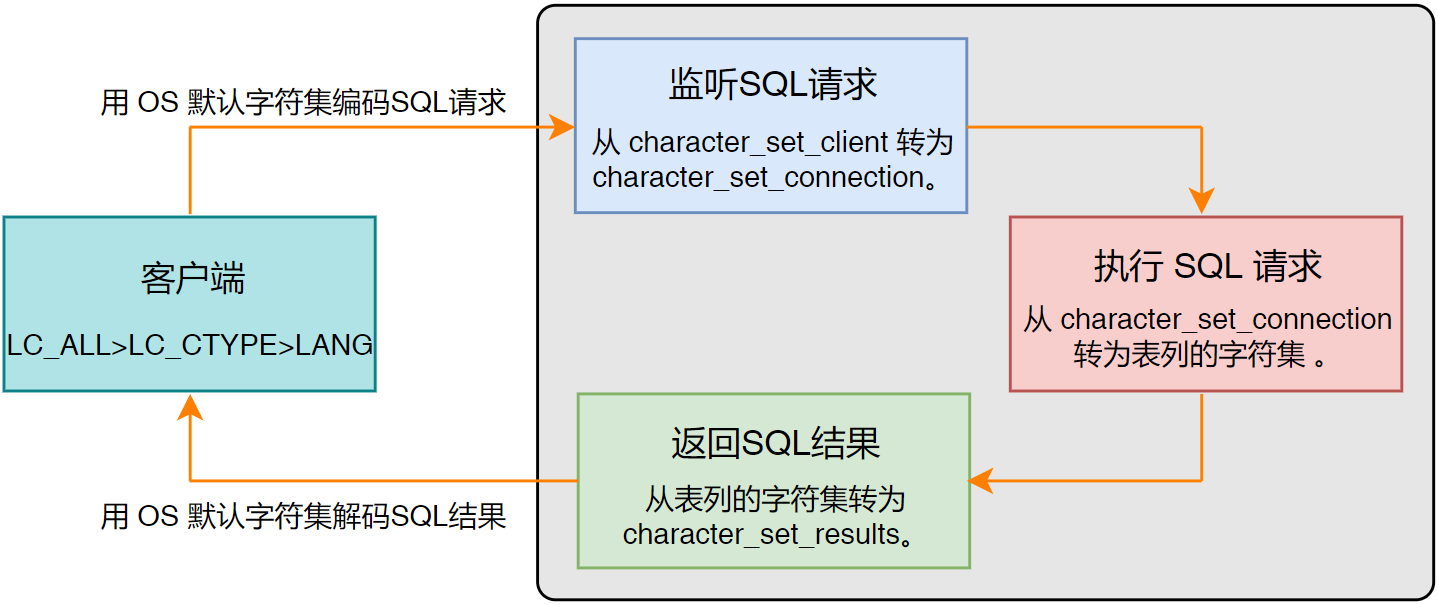
客户端在向 MySQL 服务器发送 SQL 请求,并从服务器获取返回结果的这个过程中,伴随着多次字符集的转换。在此过程中会用到 3 个系统参数:
| 系统参数 | 动态修改 | 作用域 | 说明 |
|---|---|---|---|
| character_set_client | Y | Both | 服务器解码客户端发送的 SQL 语句和数据时,使用的字符集。 即服务器总是假设客户端是按 character_set_client 设置的字符集来传输数据和 SQL 请求。 |
| character_set_connection | Y | Both | 服务器在处理客户端请求前,先将请求数据由 character_set_client 转换为 character_set_connection 字符集,再进行处理。若表列的字符集与 character_set_connection 不一致,在处理数据时还需要再次将请求转换为表列对应的字符集。 |
| character_set_results | Y | Both | 服务器向客户端返回结果数据时,使用的字符集。 即服务器先将结果数据转换为 character_set_results 字符集之后,再返回给客户端。 |
-
客户端使用 OS 默认的字符集将 SQL 语句及数据编码后,发送给 MySQL 服务器。如 Windows 默认字符集为 gbk,类 Unix 默认为 utf8。
-
服务器接收到 SQL 请求和数据后,按
character_set_client字符集进行解码,并按character_set_connection字符集重新编码。 -
服务器执行 SQL 处理时,比对表列的字符集与
character_set_connection是否一致。若不一致,则需将请求数据转换为表列中设置的字符集。 -
服务器得到执行结果后,将字符集从表列对应的字符集转换为
character_set_results后,发送给客户端。 -
客户端收到服务器返回的结果后,按照客户端的默认字符集进行解码,读取内容。
3.3. 如何避免乱码
当出现如下情况,即编码与解码使用的字符集不一致时,即可出现乱码。
- 当客户端 OS 默认字符集与 MySQL 系统参数
character_set_client不一致时。 - 当客户端 OS 默认字符集与 MySQL 系统参数
character_set_results不一致时。
通常要确保 character_set_client character_set_connection character_set_results 这三个参数值与客户端使用的字符集一致,可避免出现乱码。
为配置文件 my.cnf 增加 default-character-set 选项,可统一设置 character_set_client character_set_connection character_set_results 这三个系统参数的值。
[client]
default-character-set=utf8mb4
或通过命令 SET NAMES <字符集> 统一设置会话级系统参数 character_set_client character_set_connection character_set_results 的值。
mysql> SET NAMES utf8mb4;




