




最近参加了《PolarDB for PostgreSQL 开源训练营》,说实话很初级,但对于0基础的人来说又不够初级,因为介绍的少,实际动手做的多,而这个动手做只是去安装,需要具备一定的Linux基础,这不如直接让大家按照文档照着做来的实际,讲师不也是按照文档做了一遍么,感觉像糊弄事。
本着重在参与,要虚心学习的态度,因此,我在具备了一定的理论基础条件后,开始阅读了官方在github上发布的文档,主要针对架构解读部分,从这上面能够大概的了解到整个架构实现的方法及实现难度。下面就架构解读的部分做个简短的笔记和总结。
1. 先说说架构
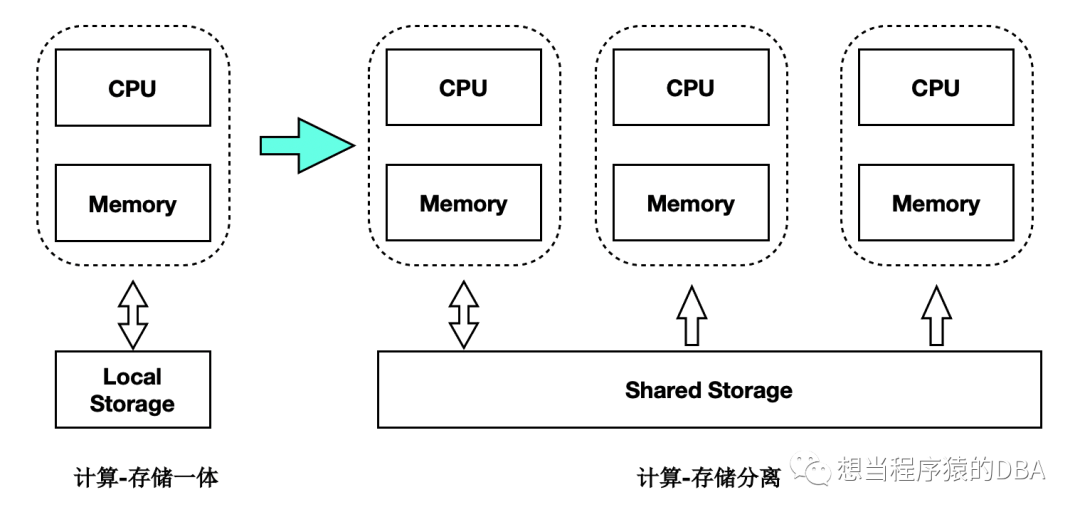
我们从官方给的图来看,是从单体数据库上进行了架构改变,原来是单一读写实例,现在变成了有读写实例和只读实例的架构,而存储部分有了变化,由共享存储替换了本地存储。这里对存储是有一定的要求的,必须是具备共享性质的存储,比如商业第三方存储具备共享属性,现在流行的分布式存储。
是不是在这样的存储上,直接部署不同的读写实例和只读实例就行了呢?最初我也是这么认为的! 读写实例只要写入提交,那么只读节点就可以从存储读到数据了,很简单嘛~
实际上,如果对数据库的原理理解的不透彻,是容易陷入这样的误区的~ 如果说对数据库的每次数据的修改操作,都同步回写到磁盘中,那么设计这种读写分离的架构是非常简单的,可实际并非如此,很多时候在内存中的操作并非实时回写到磁盘中,而是通过一些其他触发方式异步回写到磁盘,而在内存中进行了修改,没有同步到磁盘上的数据,我们通常称之为“脏数据”。在“脏数据”没有写入到磁盘的这个时期,突然数据库crash掉了,如果没有保障措施的情况,脏数据是会丢失的,这是很严重的事故,数据库为了保障这种情况不会发生,引入了“预写日志(WAL)”,即使故障时“脏数据”没有写入磁盘,那么在数据库再次启动后,也会通过“预写日志”来进行回放,将脏数据回放写入到数据文件中,没有提交的数据将进行“回滚”,来保证了数据的可靠性、一致性。
通过上面这段描述,已经大致清楚了“脏数据”和“预写日志”两个概念,对于这种共享存储的读写分离架构,需要克服的问题就是:读节点内存和读写节点内存如何能够保证一致。
PolarDB实现的方式是,仍然通过预写日志来对读节点进行回放,但这个回放只针对内存部分,数据文件是共享的,对于只读节点来说只有读权限,没有写权限。预写日志的回放是基于日志的形式,再加上日志量大,回放的延迟也是不可避免的,为了能够加快这种回放,PolarDB研究了一套精简回放方式LogIndex,过滤了一些不需要回放的事务,通过延迟回放、并行加速形式,加强了多节点读一致的能力。
我们刚说了“脏数据”,他的存在是为了提升系统的并发性,在这种共享存储读写分离的架构上,刷脏的速度和日志回放的速度并不是一致的,在只读节点上会存在两种异常情况。
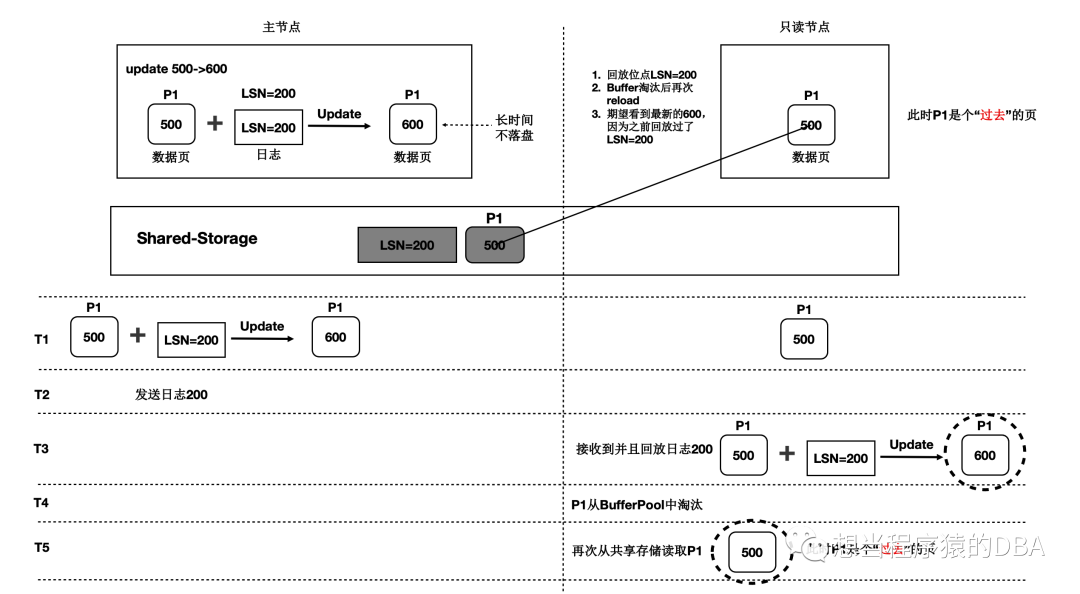
情况一、只读节点内存中回放到的数据页,读写节点没有刷脏,导致数据文件上并没有最新的数据页,当只读节点此数据页淘汰后,再从磁盘加载后,又读到了旧的数据,即过去页。参考图一:过去页。
情况二、只读节点内存中回放到的数据页,读写节点已刷脏,日志回放相对延后,当只读节点此数据页淘汰后,再从磁盘加载后,读到了超前的数据,即未来页。参考图二:未来页。
图一:过去页
图二:未来页
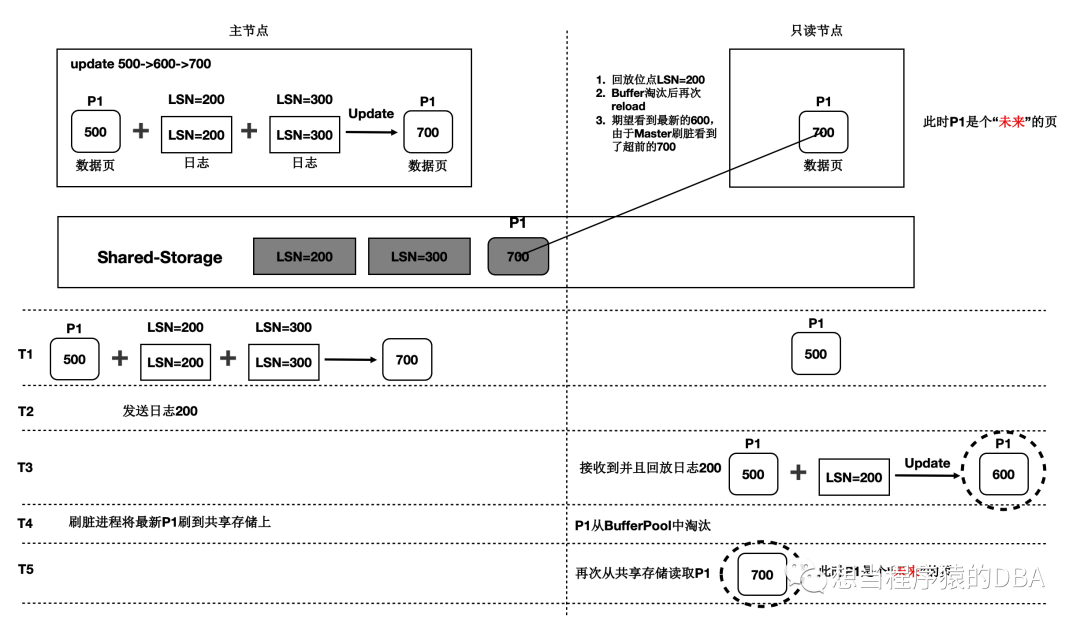
两种情况其实总结起来就是主从节点之间出现了数据的不一致,因共享存储这种架构将内存和存储进行了分离处理,导致了读节点会出现了数据不一致的情况,PolarDB通过了刷脏控制、一致性点位等技术来规避了这两种情况的发生。
2. 再说说使用场景
这种架构的优势在于降低了只读节点的数据延迟,可以几乎达到主从数据一致的能力,而且只读节点是热备节点,一旦读写节点发生故障,可以秒级提升只读节点为读写节点,这在高可用能力和业务连续性上是有高保障能力的。
这种架构只要是具备共享存储属性就可以实现,这对于多中心部署也是一种很不错的选择。
3. 未来的展望
Alibaba这次开源会经历5个版本,目前到了第二个版本,到第五个版本会逐步开源分布式架构,包括CN和GTM部分,而且我们也可以解读到现阶段这种读写分离架构也要发展到多写的架构上。
希望到最后真如解读到的那样,会开源一套完整的产品,到那时,PostgreSQL的阵容就更加强大了~
