





点击上方
蓝色
文字 关注我们吧!
做了几年的数据库管理员,依然在很多知识点上有盲区,其实也是一知半解,我也清楚不可能面面俱到。Oracle数据库是目前我用过最熟练的数据库,说熟练不说精通,不是谦虚,是从说话严禁角度来说的。Oracle内容太庞大了,官方文档就多达一个多GB,这么多内容,我是没办法精通的!
连着说了两天的字符集,关于Oracle字符集有必要去捋顺,这对后面的工作也有好处。
1. Oracle字符集
2. Oracle比较规则
先来一个熟悉的界面
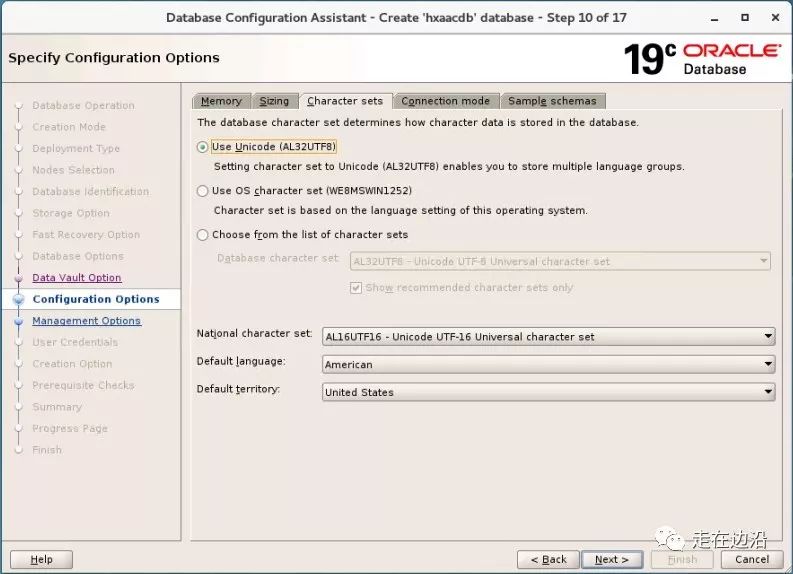
我们在通过DBCA图形化建立数据库时,都会看到这样一个界面--“字符集设置”,
这里面有两处是跟字符集有关的:
database character set
national character set
第一个是数据库字符集,其为数据库初始化参数NLS_CHARACTERSET,被用在char,varchar2,long,clob数据类型上。
*第二个是国际字符集,其为数据库初始化参数NLS_NCHAR_CHARACTERSET,被用在nchar,nvarchar2,nclob数据类型上。


Oracle字符比较规则形式比较简单,可分为两种
Binary sort
linguistic sort
1)Binary sort
针对字符,转换为二进制编码进行比较,也就是通过ASCII标准。
2)linguistic sort
a. Monolingual linguistic sort,称为单语语言排序,Oracle自己定义的一套规则,将字母拆分两部分,分别叫major,minor。字母的变音和大小写有同样的major,不通的minor。 比较要经过两个步骤,第一先比较major,然后在比较minor。
b. Multilingual linguistic sort,称为多语语言排序,也是Oracle自己定义的一套规则,将比较分为3个级别,Primary Level Sorts(比较基本字母,不区分大小写),Secondary Level Sorts(比较是否有变音符号,变音在后),Tertiary Level Sorts(比较字母大小写,小写在大写前)。
Oracle影响排序的参数为NLS_SORT,默认为BINARY,可通过ALTER SESSION进行会话级别的修改。
中文排序,有三种方式:
1)拼音(默认)
2)STROKE(第一顺序“笔画数”,第二顺序“部首”)
3)RADICAL(第一顺序“部首”,第二顺序“笔画数”)
*Oracle 12.2版本及以后,比较规则可以定义在列级别上,并且支持不区分大小写和不区分重音,进步了 。
。

Oracle数据库字符集就总结这么多,对于日常使用已经够用了,以上内容,都是经过反复验证的内容,具有可靠性。虽然内容不多,也是牺牲了很多时间去查资料及实践去推敲。知识的由来,不应该只是拿来主义,更需要去实践、去验证。
