





点击上方
蓝色
文字 关注我们吧!
在《[干货]重新认识字符集Part1》中简单的说了一下字符集是怎么一回事以及乱码是怎样产生的。在我们接下来要认识Oracle,MySQL等字符集的之前,还需要有一个过渡阶段,关于字符编码的历史,这部分内容网上有很多详细资料,想详细学习的童鞋,可以做专项学习
>>>>>>>>>>>>>>>
进字符编码家族
计算机是美国人发明的,所以对他们来说,满足日常使用,除了26个英文字母大小写以外,再就是标点符号,以及控制符号了。总共定义了128个字符,使用7位编码(他们只用128个字符就搞定了计算机世界,恐怖吧!),这就是ASCII码。而后随着一些欧洲国家等使用,又在7位编码的基础上加一位,成为8位编码,总共收录256个字符,称其为Latin1,比较常用。
随着计算机的普及,并传递到了各个国家,对于非英语国家来说,可是遇到了大麻烦,比如我们具有5000年悠久历史文化的中国,一直用的是汉字,总不能因为使用计算机,让我们去改变母语吧,太不现实。所以各个国家都开始在ASCII码的基础上扩充了自己的文字,俗称ANSI标准。
ANSI标准,其实就是区域性语言,各个国家都自己玩自己的,不通用。为了解决这个难题,又有一个组织冒出来,搞了一套统一的编码方案,这就是UNICODE,还有个霸气测漏的名字“万国码”。
虽然“万国码”很牛叉,却不灵活,本来一个英文字母需要单字节就能搞定的,可它非得要2字节,这对我们这些节俭主义的人来说完全不能接受,因此慢慢的衍生出来一些中间字符集格式,如我们常见的UTF8,就是其最受欢迎的一员。
不得不说,在字符编码的世界,人们追求完美的一面被体现的淋漓尽致。而有人又发现了一个小问题,就是在网络传输的一些不可见字符,不同的设备处理的方式不同,这就可能在改变了本来的意思。因此一种叫BASE64的编码应运而生。
文字描述不够直观,下面用一张图进行总结。
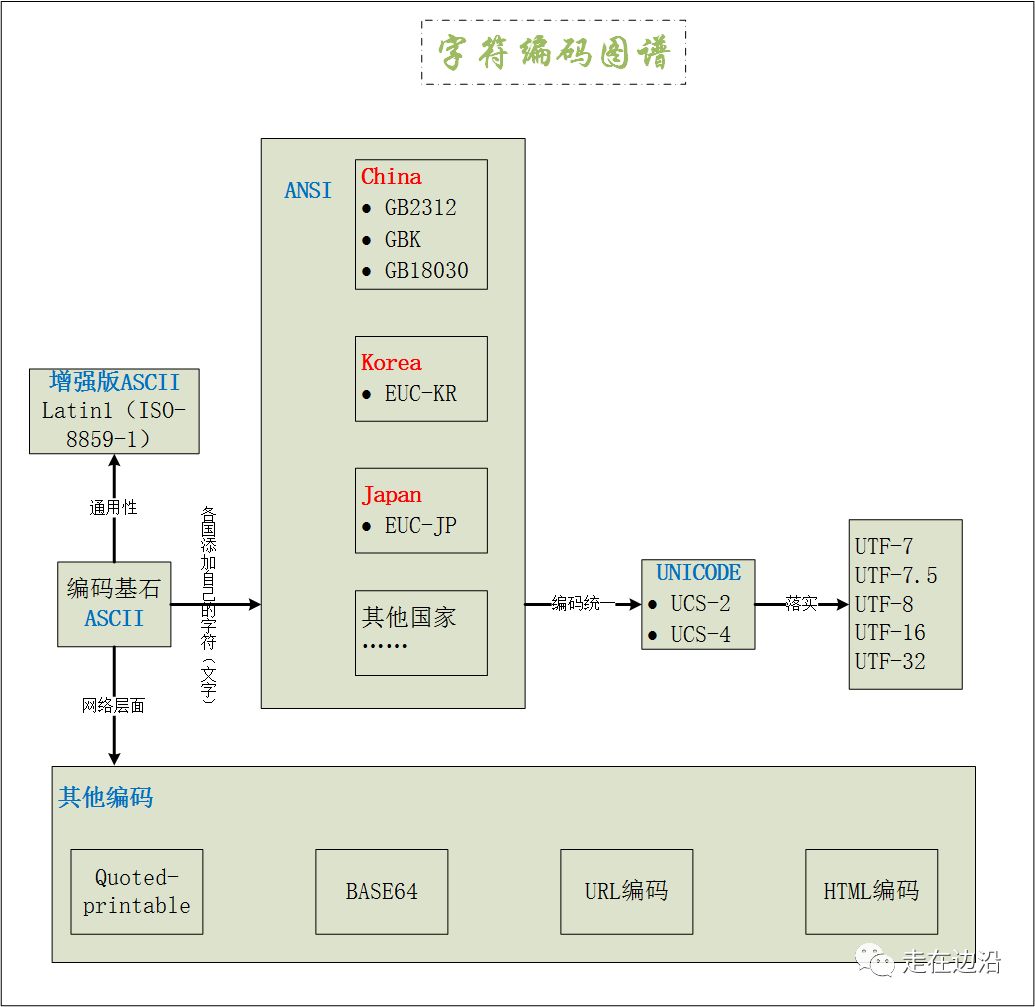
在粗略的述说了字符编码家族的情况后,我们沿着ASCII-ANSI-UNICODE这条主线再细致说一下,以便更好的了解
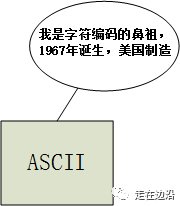
ASCII,也就是American Standard Code for Information Interchange,即美国标准信息交换代码。它是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的【单字节】编码系统。ASCII码是目前计算机中用得最广泛的字符编码。
1字节为8bit,即8位。用7位表示一个字符,组合起来共2^7=128个,最高位(左数第一位)统一定为0。我们一般称7位编码的ASCII码为标准ASCII码。
128个字符,对很多国家来说是完全不够的,因此有些国家对7位进行了扩展,将最高位进行了使用,理论上是可以达到2^8=256个字符的。与ASCII一样,在经历了多年不断的验证与使用,一个叫做Latin1(ISO-8859-1)成为时下最流行的8位单字节编码,其向下兼容标准ASCII,我们在这里称它为增强版ASCII。
ASCII简单记忆规律:
十进制值48到57代表数字0到9。
十进制值65到90代表26个大写字母A到Z。
十进制值97到122代表26个小写字母a到z。
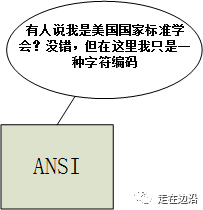
ANSI的说法,应该源于微软的windows操作系统,并没有一个组织对其负责,我们广泛能够看到的就是在windows计算机上。它的出现,就是解决地域化文字的编码,我们以中文为例。
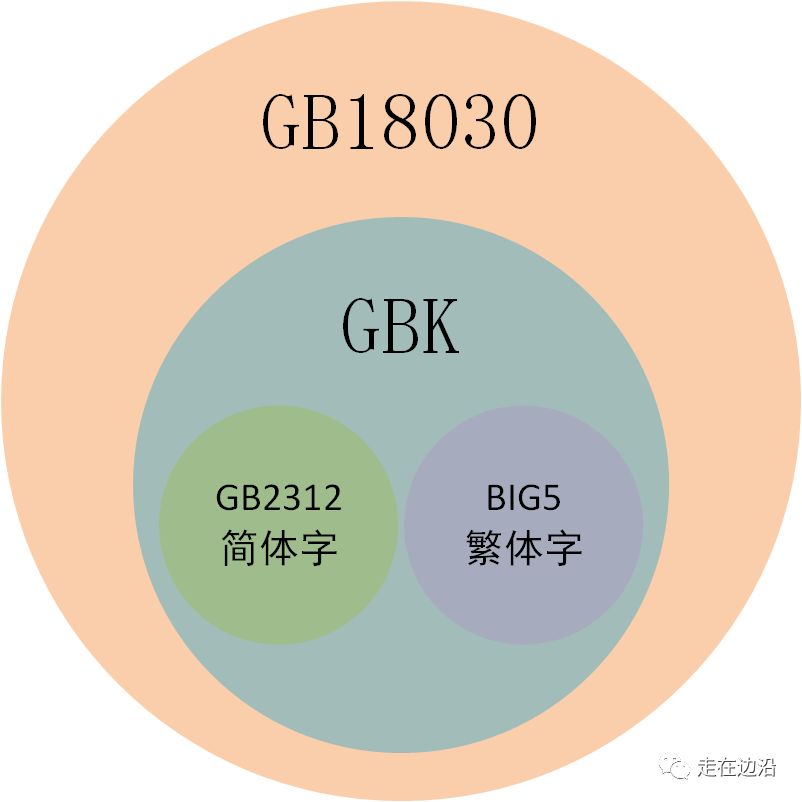
最早出现的为GB2312,两字节表示,高字节称为区,低字节称为位,合起来称作区位码,共收录6763个汉字,现在也叫做常用字。可覆盖中国大陆99.75%使用率。
当我们逐渐发现一些生僻字在人名、文言文中出现的频率也比较高,可在GB2312中却不存在,为此,又创建了GBK编码,在GB2312基础上增加了14240个汉字,并且将台湾等地区使用的BIG5也容纳进来。
中国的汉字多达7万多个,GBK编码也无法能够满足所有要求,因此我们国家祭出了杀手锏,GB18030编码。它采用4字节编码,总共收录了7万多汉字,涵盖少数名族文字。(相信有朋友会问,这么大而全的编码,为什么会很少听到呢?我觉得两方面原因,一个是国家推行力度不强;另一个是国外很多软件不支持,到GBK就为止了。)
UNICODE网上众说纷纭,尤其是和UTF8扯在一起时,更是云里雾里。下面我将思路简单捋一下。
UNICODE是作为字符编码大一统而来,若算下来,可以容纳100万以上个字符。其存在两种编码标准:UCS-4,采用31位编码形式,编码固定占用4字节,可容纳20亿个编码空间;UCS-2,采用16位编码形式,编码固定占用2字节,可容纳65536个编码空间。
之前说过,这样的编码因为固定占用字节,因此存在大量空间浪费的问题。UTF8就是解决字符编解码浪费问题而存在的一种最受欢迎的字符集。
那么究竟UNICODE,UTF8是什么关系呢?
我们打个比方,UNICODE可以理解为字典,UTF8则为在字典基础上再加工的更符合人类使用的字典,所有编码规则都依赖原字典。这样说来,UTF8其实就是UNICODE的改造版,它存储字符更灵活,长度可变。

