





前言
这两天在做一个测试,运行SQL的时候,发现PostgreSQL中竟然没有index skip scan
。遇到索引多列的情况,前导列的值distinct值少,而非前导列的distinct的值多,选择性较好,对非前导列做等值查询优化器竟然会走全表扫描。类似这样的SQL语句,其他数据库运行的效率明显要好于大PG啊。
为什么?
我通过搜索,发现wiki上有一篇文章写的比较清晰。地址:https://wiki.postgresql.org/wiki/Loose_indexscan
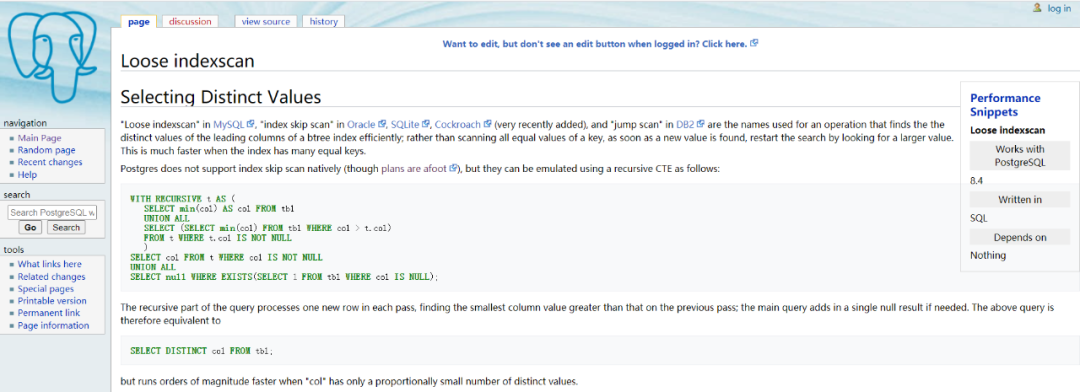
每一种数据库对这种操作的叫法不同,像MySQL就叫Loose indexsacn
,而Oracle、SQLite这些数据库叫index skip scan
。db2叫jump scan
。只有PostgreSQL暂时是not support
的。而其实这项功能也有开发计划。
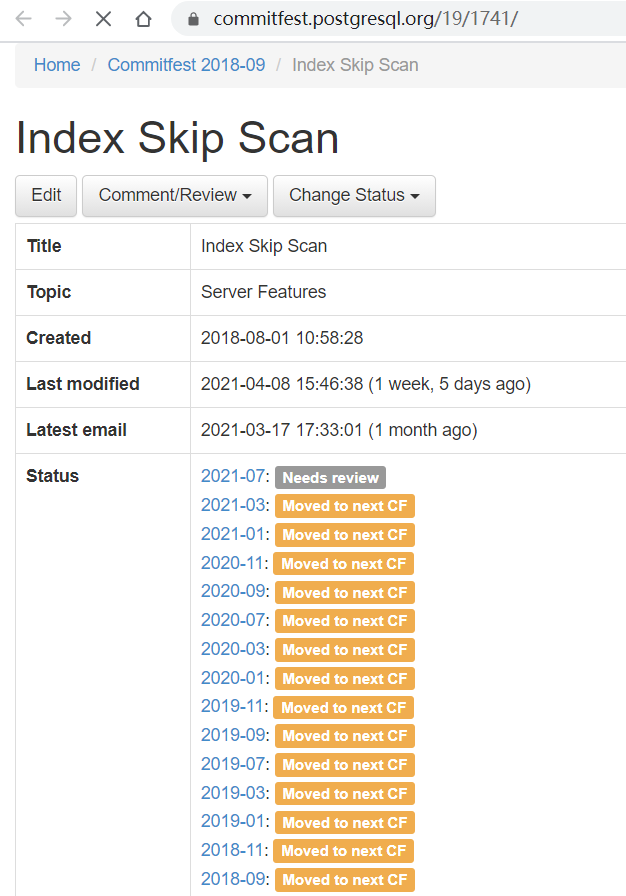
但是状态一直都是Moved to next CF
。
针对这个问题的解决办法是使用CTE,利用递归来解决这个问题。我们先用网页上提供的demo来测试一下,然后再说下实现的原理。
--创建表和索引,并插入数据CREATE TABLE tbl (col integer NOT NULL, col2 integer NOT NULL);INSERT INTO tblSELECT trunc(random()*5) AS col, (random()*1000000)::int AS col2 FROM generate_series(1,10000000);CREATE INDEX ON tbl (col, col2);ANALYZE tbl复制
我们来查索引中的第二列。可以看到正向我们前面所说,第二列的选择性好,而这个等值查询,PostgreSQL选择了全表扫描。
postgres=# explain analyze SELECT count(*) FROM tbl WHERE col2 = 9854; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (cost=76498.36..76498.37 rows=1 width=8) (actual time=349.783..349.784 rows=1 loops=1) -> Gather (cost=76497.94..76498.35 rows=4 width=8) (actual time=347.533..369.784 rows=5 loops=1) Workers Planned: 4 Workers Launched: 4 -> Partial Aggregate (cost=75497.94..75497.95 rows=1 width=8) (actual time=335.950..335.950 rows=1 loops=5) -> Parallel Seq Scan on tbl (cost=0.00..75497.93 rows=3 width=0) (actual time=206.065..335.884 rows=2 loops=5) Filter: (col2 = 9854) Rows Removed by Filter: 1999998 Planning Time: 0.154 ms Execution Time: 369.902 ms(10 rows)复制
那么改写这个SQL的办法是使用CTE递归。
explain analyze SELECT count(*) FROM tbl WHERE col2 = 9854 AND col IN ( WITH RECURSIVE t AS (SELECT min(col) AS col FROM tbl UNION ALL SELECT (SELECT min(col) FROM tbl WHERE col > t.col) FROM t WHERE t.col IS NOT NULL) SELECT col FROM t); QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=437.87..437.88 rows=1 width=8) (actual time=1.021..1.021 rows=1 loops=1) -> Nested Loop (cost=56.45..437.84 rows=11 width=0) (actual time=0.860..1.015 rows=9 loops=1) -> HashAggregate (cost=56.01..57.02 rows=101 width=4) (actual time=0.759..0.762 rows=6 loops=1) Group Key: t.col -> CTE Scan on t (cost=52.73..54.75 rows=101 width=4) (actual time=0.291..0.748 rows=6 loops=1) CTE t -> Recursive Union (cost=0.46..52.73 rows=101 width=4) (actual time=0.286..0.739 rows=6 loops=1) -> Result (cost=0.46..0.47 rows=1 width=4) (actual time=0.284..0.285 rows=1 loops=1) InitPlan 3 (returns $1) -> Limit (cost=0.43..0.46 rows=1 width=4) (actual time=0.274..0.275 rows=1 loops=1) -> Index Only Scan using tbl_col_col2_idx on tbl tbl_2 (cost=0.43..253761.58 rows=9999977 width=4) (actual time=0.259..0.259 rows=1 loops=1) Index Cond: (col IS NOT NULL) Heap Fetches: 1 -> WorkTable Scan on t t_1 (cost=0.00..5.02 rows=10 width=4) (actual time=0.073..0.073 rows=1 loops=6) Filter: (col IS NOT NULL) Rows Removed by Filter: 0 SubPlan 2 -> Result (cost=0.47..0.48 rows=1 width=4) (actual time=0.082..0.082 rows=1 loops=5) InitPlan 1 (returns $3) -> Limit (cost=0.43..0.47 rows=1 width=4) (actual time=0.080..0.080 rows=1 loops=5) -> Index Only Scan using tbl_col_col2_idx on tbl tbl_1 (cost=0.43..124646.98 rows=3333326 width=4) (actual time=0.079..0.079 rows=1 loops=5) Index Cond: ((col IS NOT NULL) AND (col > t_1.col)) Heap Fetches: 4 -> Index Only Scan using tbl_col_col2_idx on tbl (cost=0.43..3.75 rows=2 width=4) (actual time=0.035..0.041 rows=2 loops=6) Index Cond: ((col = t.col) AND (col2 = 9854)) Heap Fetches: 9 Planning Time: 1.028 ms Execution Time: 1.287 ms复制
我们把执行计划格式化一下。
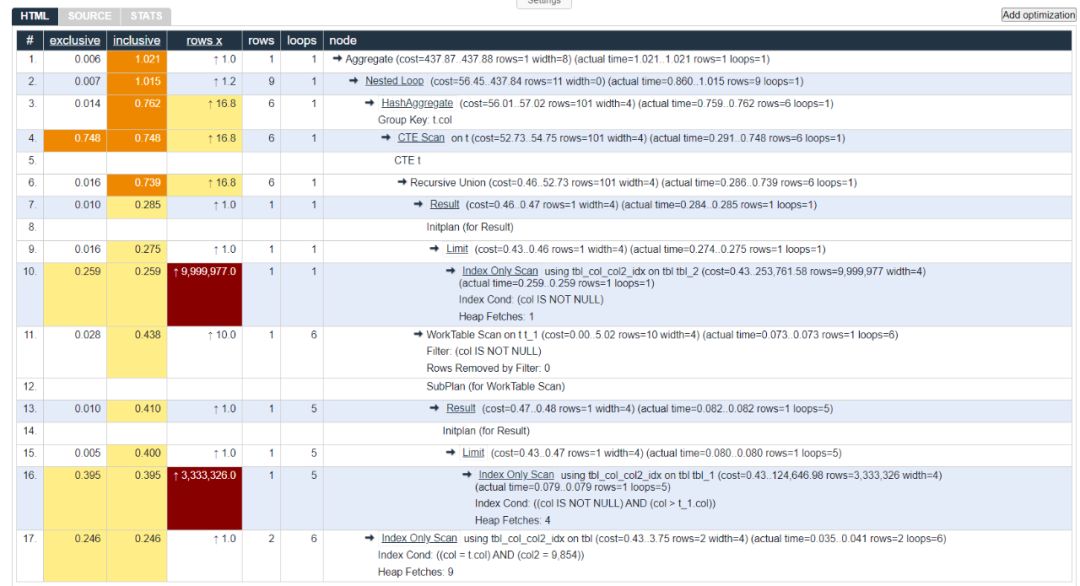
整个过程有点多,但是实际执行时间只有1.2ms左右。速度大幅的提示。
实现原理
我们来分析一下这个原理。首先我们的第一列是trunc(random()*5) AS col
,这个值它肯定是在0-5之间。那么如果我们知道第一列的值,查询最简单改写办法就是:
select count(1) from tbl where col in (0,1,2,3,4) and col2=9854;postgres=> explain analyze select count(1) from tbl where col in (0,1,2,3,4) and col2=9854; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=18.68..18.69 rows=1 width=8) (actual time=0.268..0.269 rows=1 loops=1) -> Index Only Scan using tbl_col_col2_idx on tbl (cost=0.43..18.66 rows=10 width=0) (actual time=0.068..0.255 rows=5 loops=1) Index Cond: ((col = ANY ('{0,1,2,3,4}'::integer[])) AND (col2 = 9854)) Heap Fetches: 5 Planning Time: 0.456 ms Execution Time: 0.363 ms(6 rows)复制
执行上面的查询把col的值换成in (0,1,2,3,4)。因为同时用了前面的引导列和非引导列,所以它可以走索引的,这个查询的速度非常快。
我们现在要做的一件事就是把前面列的distinct值,给算出来。直接distinct它肯定不行,效率太低了。所以就只能使用递归的方式,那么这里递归的原理就是我首先找到col列的最小值。
SELECT min(col) AS col FROM tbl复制
然后进行递归,找到col大于最小值的,存入到中间表。完成递归之后,就能算出全部col列的值。最后在代入到上面的in条件中。
SELECT count(*) FROM tbl WHERE col2 = 9854 AND col IN (.....)复制
以上比较厉害的地方就在于当它求大于0的值,一旦看到值1,它是大于0的,这个时候它将跳过其它=1的所有行,这归功于索引扫描。通过索引查找每个元素,每个单独的元素只需执行一次索引扫描。由于表中只有5个元素。因此只需要执行6次索引(第6次发现没有大于前面的值就结束扫描)。这类扫描比distinct这样的聚合操作要快的多。
如果前导列的值distinct出来很多个值,这样的写法是没有什么效果的。因为他没办法通过索引跳过剩下的行。Oracle遇到这样的情况也将使用全表扫描,不会使用
index skip scan
。
当然这个还有一个重要的前提就是col这个列不能为null,如果它为null,这个写法又会复杂很多。
后记
最后说说缺陷,虽然我们能使用CTE实现像Oracle中的index skip scan,加快查询速度。但是实际应用的时候没有这么简单,因为有时候我们往往面临的是一个很复杂的SQL,在这种情况下再去写CTE这种递归,非常容易出错的。
所以还是建议官方早日出相关的功能,实际上也有相关的补丁。只是官方的还没过审。

参考链接
1.https://wiki.postgresql.org/wiki/Loose_indexscan
2.https://malisper.me/the-missing-postgres-scan-the-loose-index-scan/#easy-footnote-bottom-1-544
3.https://www.postgresql-archive.org/Index-Skip-Scan-new-UniqueKeys-td6140637.html
评论

 0 点赞
0 点赞