




Postgres设计指导原则之一是严重依赖环境(尤其是操作系统)提供的功能,文件系统就是一个典型的例子。与其它数据库不同,Postgres从不支持原始设备,即无需先创建常规文件系统即可将数据存储在块设备上的能力 -——这将需要实现一个“自定义”文件系统,该系统可能是针对数据库的需求量身定制的(以及因此更快),但它需要大量的开发时间投资(例如,支持不同的平台, 适应不断发展的硬件等)。
由于开发时间是非常宝贵的资源(在开源项目早期阶段的小型开发团队中更是如此),理性的选择是期望操作系统提供足够好的通用文件系统,并专注于为使用者提供具有高附加值的数据库特定功能。
因此,你可以在许多文件系统上运行 Postgres,这就引出了一个问题:它们之间有什么显着差异吗?甚至选择哪个文件系统重要吗?旨在得出分析而去探索这些问题。
我将研究Linux上的一些通用文件系统 -——传统(ext4 / xfs)和现代(zfs / btrfs)文件系统,在不同配置的SSD设备上运行OLTP基准测试(pgbench),并呈现结果以及基本分析。
注意:对于OLTP来说,使用传统磁盘并不实用(或经济高效)。结果可能不同,又或许很有趣,但最终毫无用处。
设置
我使用了两台具有不同硬件配置的“普通”机器,其中一台带有SATA SSD,而另一台较大的机器带有NVMe SSD。
i5
- 英特尔 i5-2500K(4 核)
- 8GB 内存
- 6 个英特尔 DC S3700 100GB (SATA SSD)
- PG: shared_buffers=1GB, checkpoint_timeout = 15m, max_wal_size = 64GB
- ZFS 调谐:full_page_writes=关闭,wal_init_zero = 关闭,wal_recycle = 关闭
至强
- 2 个英特尔 e5-2620v3(16/32 核)
- 64GB 内存
- 1 个 WD 金牌固态硬盘 960GB (NVMe)
- PG shared_buffers=8GB,checkpoint_timeout = 15m,max_wal_size = 128GB
- ZFS 调谐:full_page_writes=关闭,wal_init_zero = 关闭,wal_recycle = 关闭
两台计算机都运行内核 5.17.11 和 zfs 2.1.4 或 2.1.5。
在i5机器上,我们也可以测试不同的RAID配置。zfs 和 btrs 都允许直接使用多个设备,对于 ext4/xfs,我们可以使用 mdraid。RAID 级别的名称(和实现)略有不同,所以这里得到了一个粗略的映射:
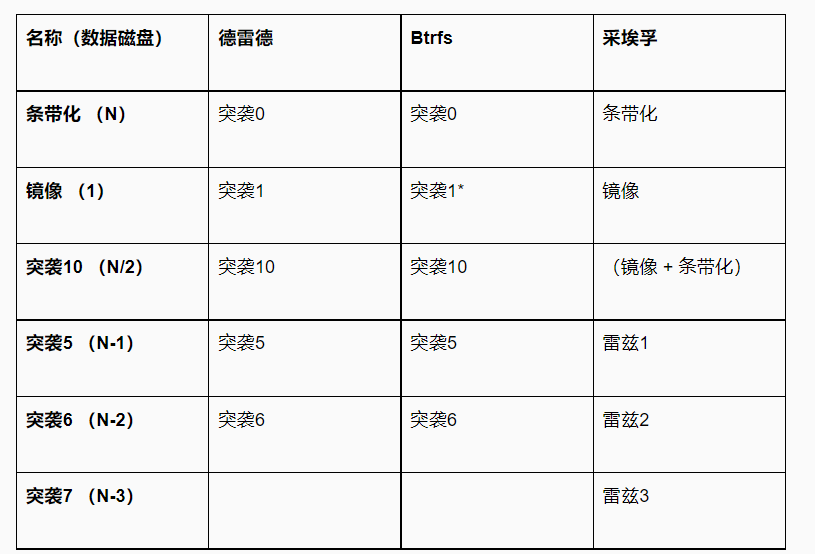
注意:第一列中的数字表示“数据承载”磁盘的数量。例如,通过条带化,所有 N 个磁盘都用于存储数据。通过 raid5,其中一个驱动器被用于存储奇偶校验信息,因此我们只使用 (N-1) 数据磁盘。使用 raid10,我们为每条数据保留一个副本,因此我们有 N/2 容量。
注意:btrfs对 raid1 的定义与 mdraid 略有不同,因为它的意思是“2 个副本”而不是“N 个副本”,这使得它更像 raid10 而不是镜像。在解释结果/图表时,请记住这一点。
注意:btrfs 实现了 raid5/6,但这种支持被认为是实验性的。多年来一直如此,考虑到这一变化更多的是阻止人们将 btrfs 与 RAID5/6 一起使用,而不是解决问题,我并没有屏住我的呼吸。它可用,所以让我们测试一下,但请记住这一点。
有关各种 RAID 级别的更详细说明,请参阅此处。
执行了一些基本的文件系统调整,以确保正确的对齐、条带/步幅和挂载选项。对于 ZFS,调优范围更广一些,并为整个池设置了以下内容:
- recordsize=8K
- compression=lz4
- atime=关闭
- relatime=开启
- logbias=延迟
- redundant_metadata=最
这个基准测试的所有脚本(和结果)都可以在我的github上找到。其中包括 RAID 设备/池的设置、挂载等。
注意:若您有使用哪些其他挂载选项(或任何其他优化想法)的其他建议,请告诉我。我选择了我认为最重要的优化,但也许我错了,可能其中一些选项会产生很大的不同。
i5 (6 个 100GB SATA 固态硬盘)
让我们先看一下较小的机器,比较各种 RAID 配置中多个设备上的文件系统。这些是简单的“总吞吐量”数字,来自足够长的 pgbench 运行(只读:15 分钟读写:60 分钟),适用于不同的规模。
只读
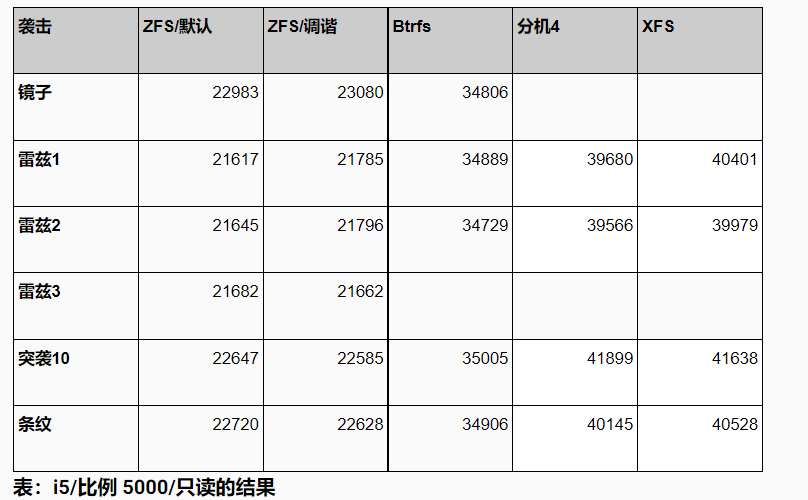
对于只读运行,无论是当数据适合 RAM(比例 250 是 ~4GB)还是当它变得更大(比例 5000 是 ~75GB)时,结果都非常均匀。
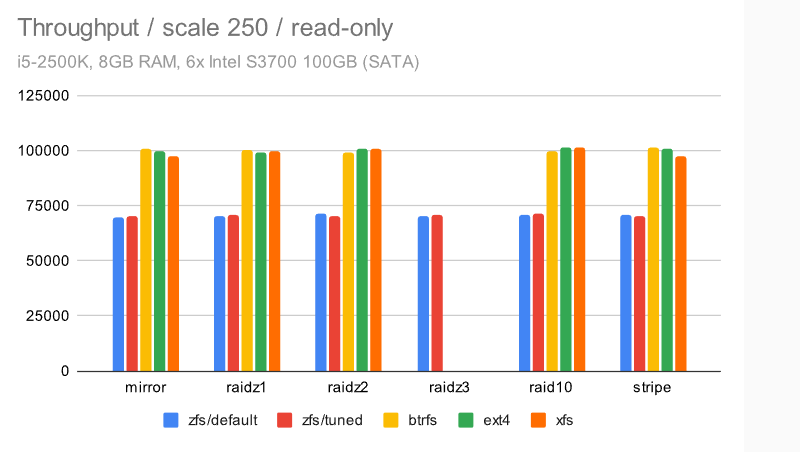
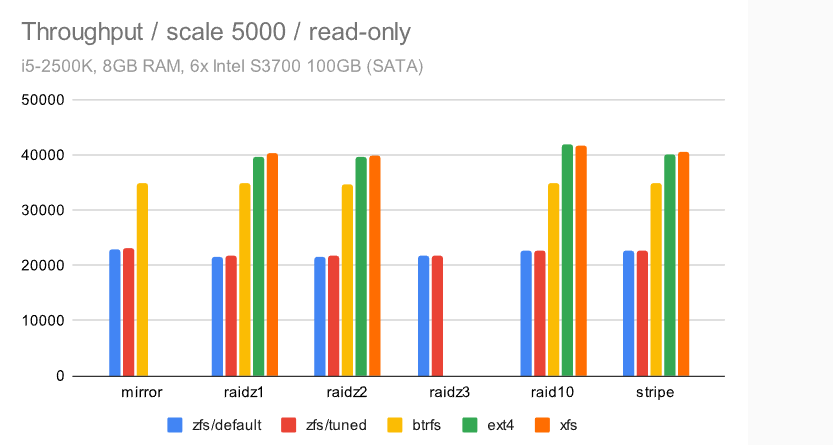
主要区别似乎是 zfs 一直较慢——我不知道具体原因,但考虑到这甚至会影响所有内容都适合 RAM(或 ARC)的情况,我的猜测是这是由于使用了比“本机”Linux 文件系统更多的 CPU。这台机器只有 4 个内核,所以这可能很重要。

读写
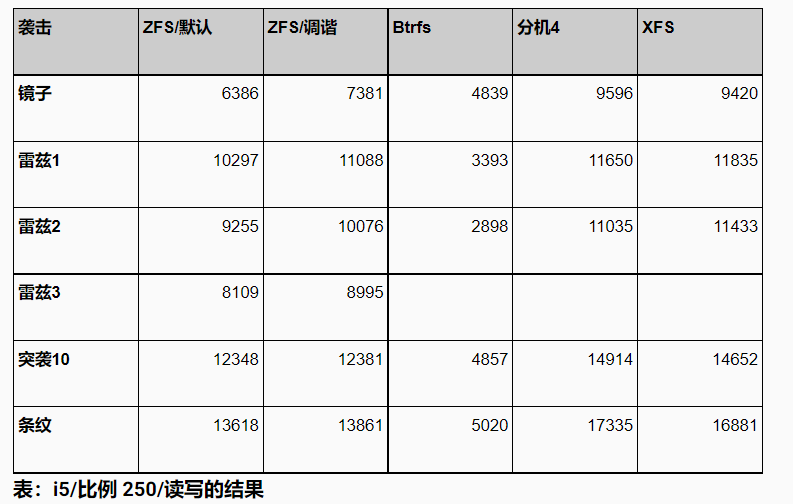
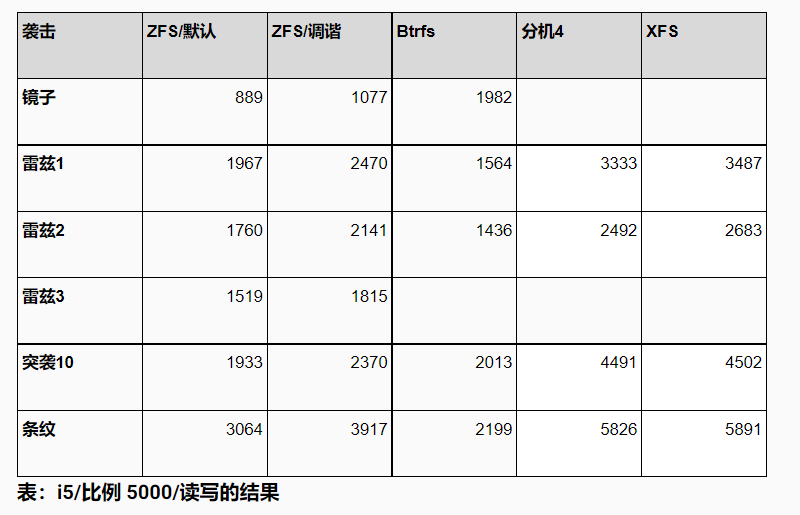
对于读写测试,所有数据集大小,结果都不太均匀。
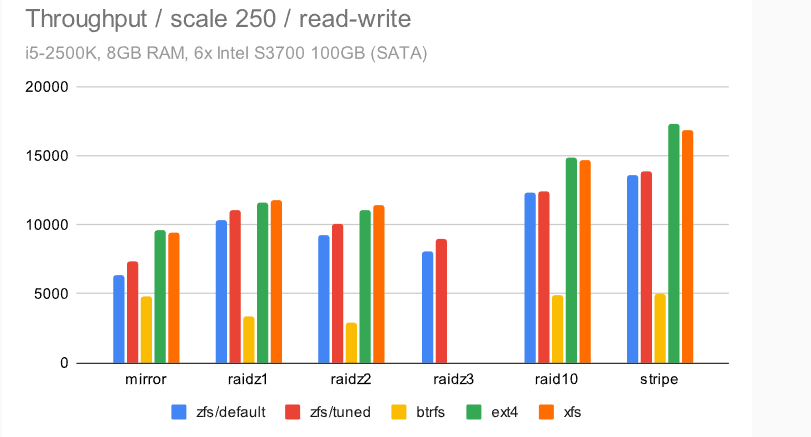
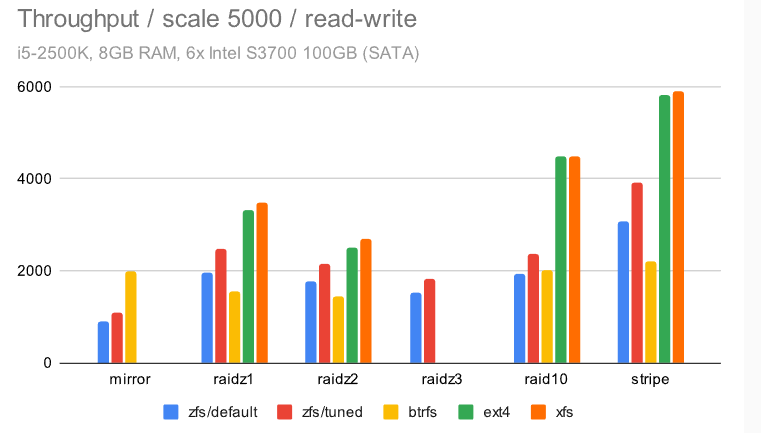
有几个有趣的观察结果。首先,ext4/xfs 显然是赢家,至少在总吞吐量方面是这样(我们稍后会看看其他东西)。其次,对于小数据集,ZFS 几乎和 ext4/xfs 一样快,这很棒——这涵盖了许多实际用例,因为甚至当你拥有大量数据,也有可能只能访问一小部分。
不幸的是,由于某种原因,btrfs 明显表现不佳。这对于较小的数据集尤其明显,其中 btrfs 的最高吞吐量为 ~5000 tps,而其他文件系统的吞吐量要高得多(2-3 倍)。
注意:这是记住 btrfs 以不同方式定义 raid1 的地方,这意味着较大数据集的“良好”结果不是那么好,因为 btrfs 只保留 2 个而不是 6 个副本(因此数据磁盘比其他文件系统多 3 倍)。
至强 (1x NVMe 固态硬盘)
现在,让我们看一下一台“更大”的机器,但它只有一个SSD(NVMe)设备。因此,我们无法测试各种 RAID 级别,这意味着我们可以通过两个简单的图表中来呈现结果。

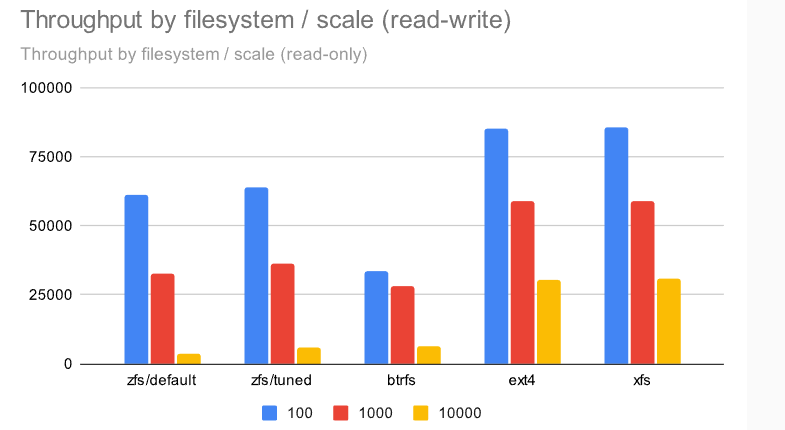
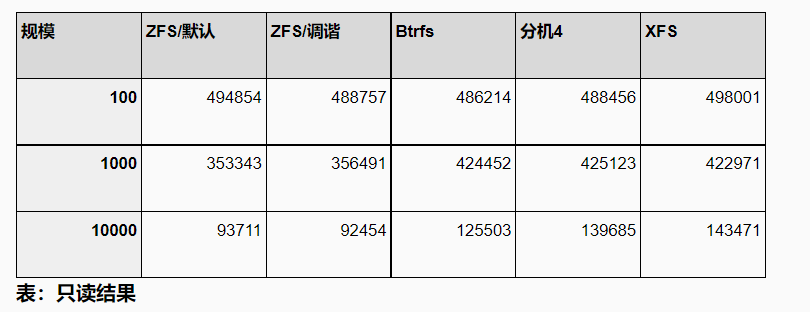
对于只读测试,结果(再次)相当均匀 -——ZFS 比其他文件系统慢一点,特别是在处理较大的规模,此时类似于较小的机器。
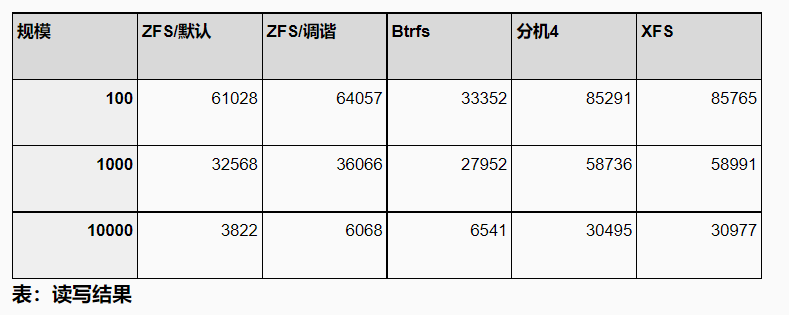
对于读写测试,差异要大得多。EXT4 / XFS是明显的赢家。ZFS 在两个较小的数据集(适合共享缓冲区/RAM)上保持同步,但在 10000 的规模上,它下降到只有 ~6k tps(相比之下,ext4/xfs 为 ~30k tps)。Btrfs 的表现相当差——在中小型数据集上,它与 ZFS 有些竞争力,但除此之外,它明显表现不佳。
随时间推移的吞吐量
到目前为止,呈现的吞吐量结果忽略了一件重要的事情 -——吞吐量的稳定性,即它如何随时间演变。假设两个系统运行相同的基准测试:
- 系统 A 始终如一地执行 15k tps,在基准测试运行期间变化最小
- 系统 B 在上半场执行 30k tps,然后卡住并执行 0 tps
两个系统的平均速度为15k tps,因此到目前为止提供的图表中将具有相同的图表。但我认为我们会赞成系统 A会更具有一致性和可预测的性能。
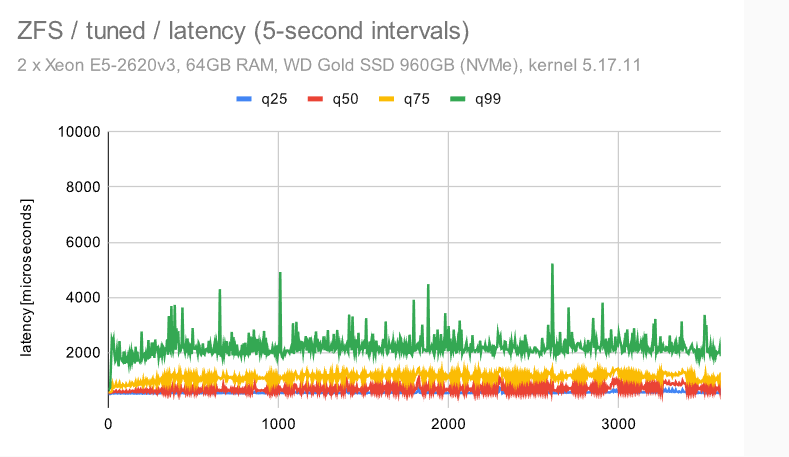
因此,我们不仅要看一下总吞吐量,还要看一下吞吐量是如何随时间发展。本节中的图表显示 60 分钟读写基准测试期间每秒的吞吐量(蓝色),运行平均值超过 15 秒间隔(红色)。
这应该可以让您了解吞吐量的波动程度,以及趋势/模式(随时间退化、检查点的影响…)。
i5 / 规模 1000
本节中的所有结果均来自 RAID0/条带化设置。对于规模 1000(超过 RAM,但与 wal_max_size 相比足够小),我们得到:
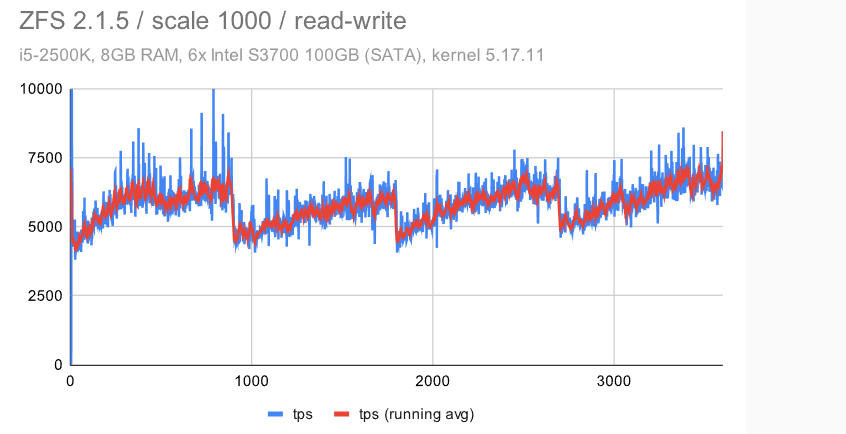

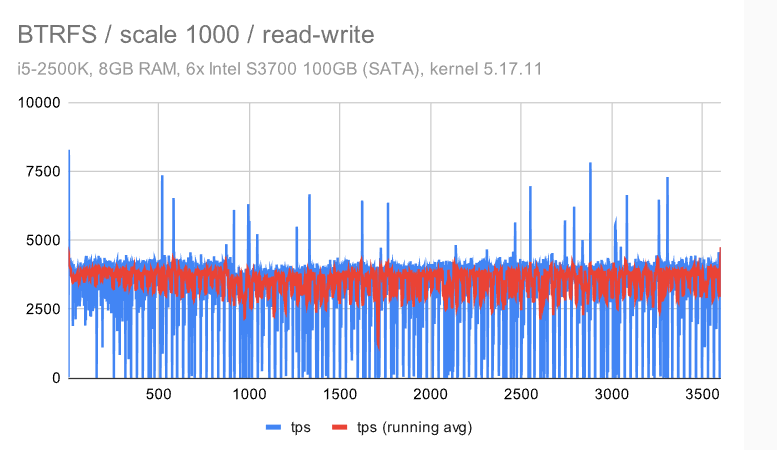
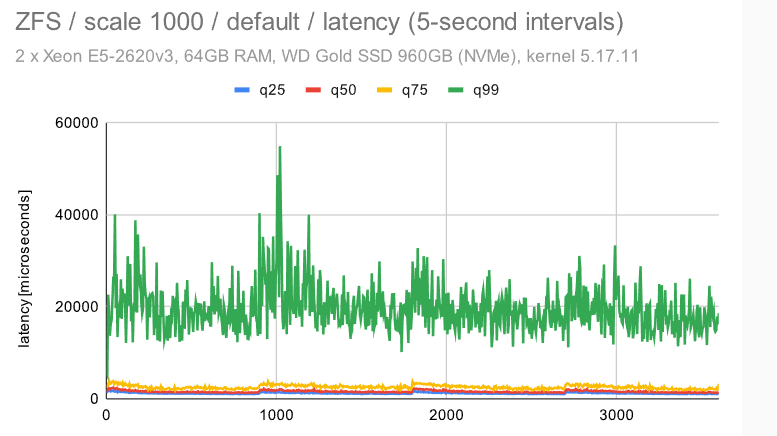
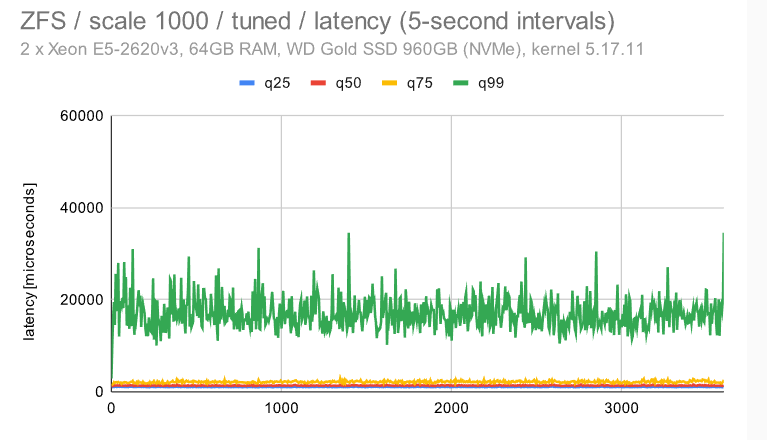

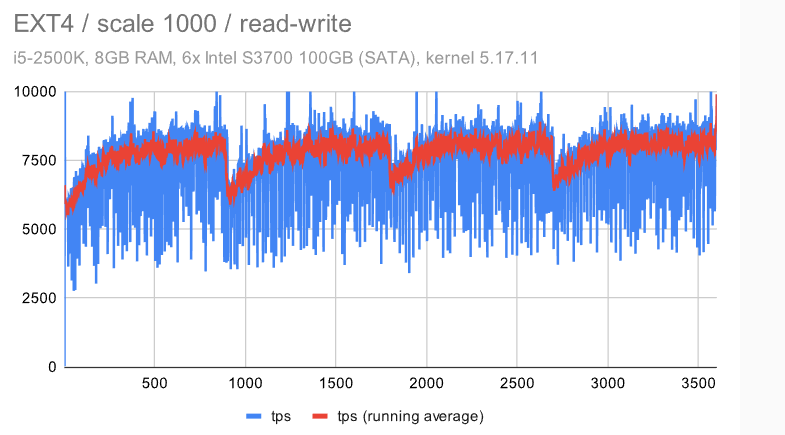
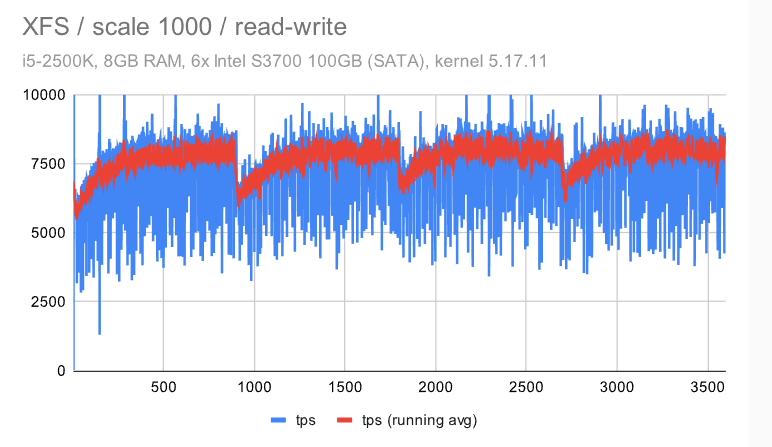
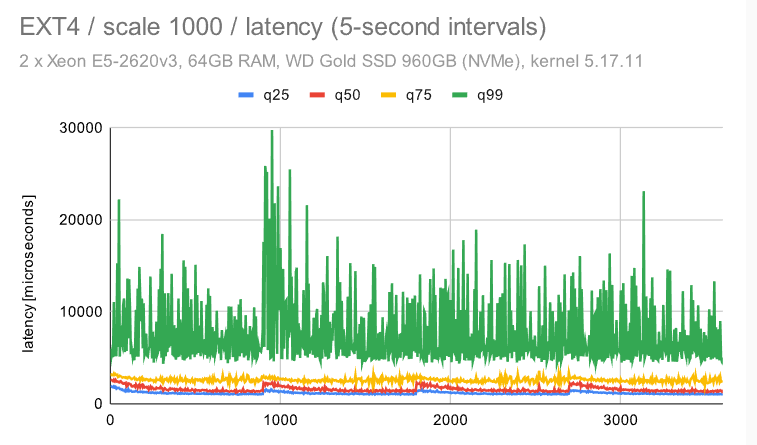
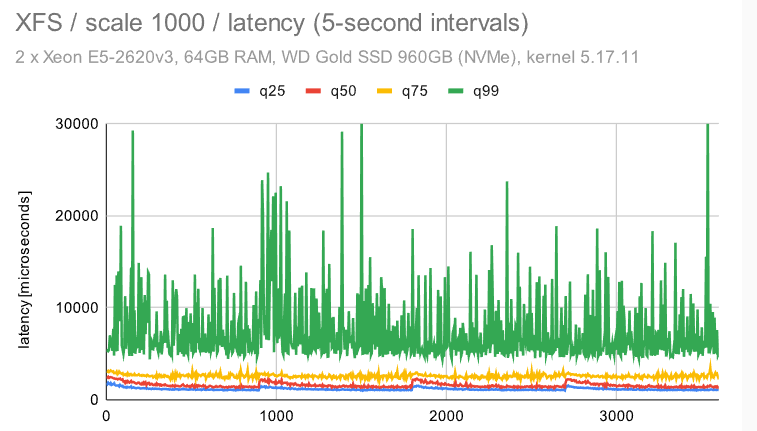
立即很明显,ZFS 具有非常纯粹和一致的行为 -——使用默认配置时会有一些检查点影响,但禁用 FPW 会让这种情况消失。作为 DBA,你会希望在系统上看到以下内容 ———在整个基准测试运行期间的最小差异(抖动)。
EXT4/XFS 实现了更高的吞吐量(~7.5k tps 与 6.5k tps,因此增加了 ~20%),但抖动明显要高得多。每秒吞吐量大致在 5k 到 9k tps 之间变化 -——不是很好,但也不是很糟糕。检查点也有明显的影响,但我们不能禁用 FPW 来消除这一点——我们只能通过增加timeout/WAL 的大小来降低检查点的频率。
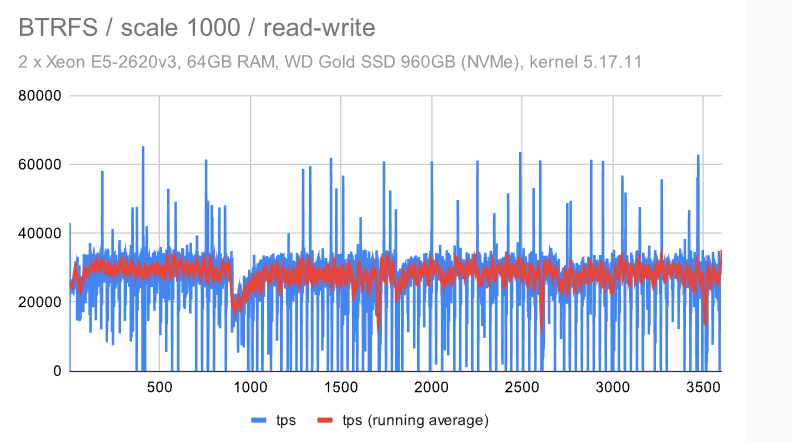
但是,BTRFS有更多的问题 -——吞吐量低于ZFS,而抖动比EXT4 / XFS差得多。平均而言(红线)它并没有那么糟糕,但它经常下降到接近 0,这意味着某些事务的高延迟。
i5 / 规模 5000
现在让我们看一下“大型”数据集(比 RAM 大得多)。
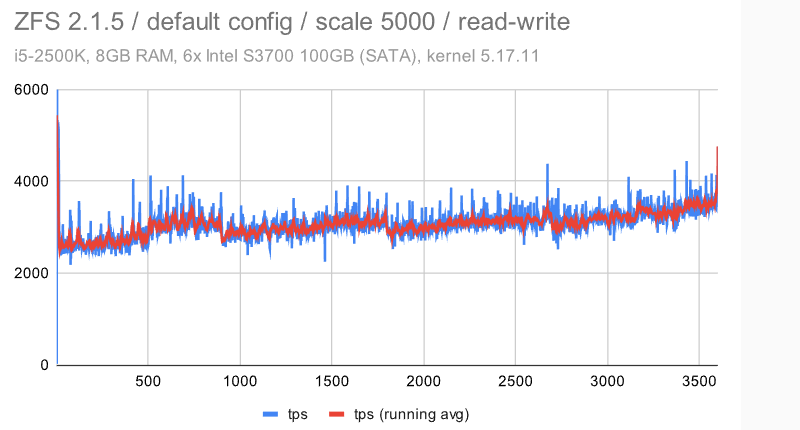
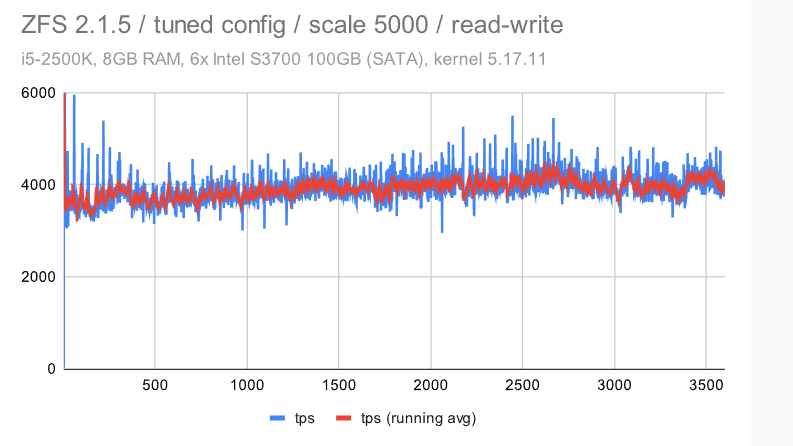
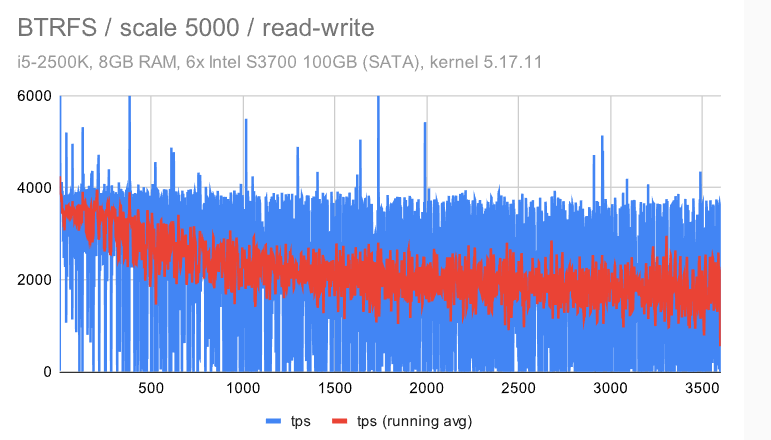
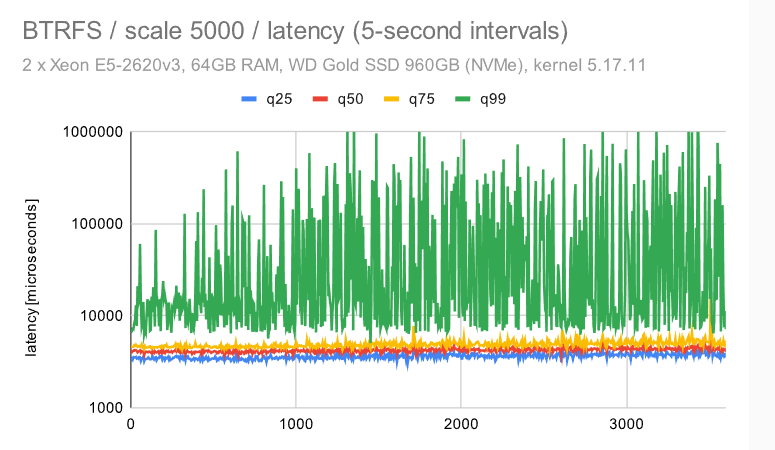
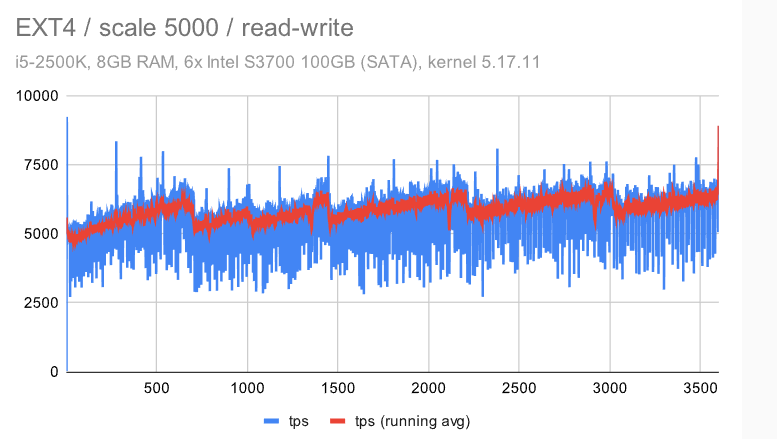
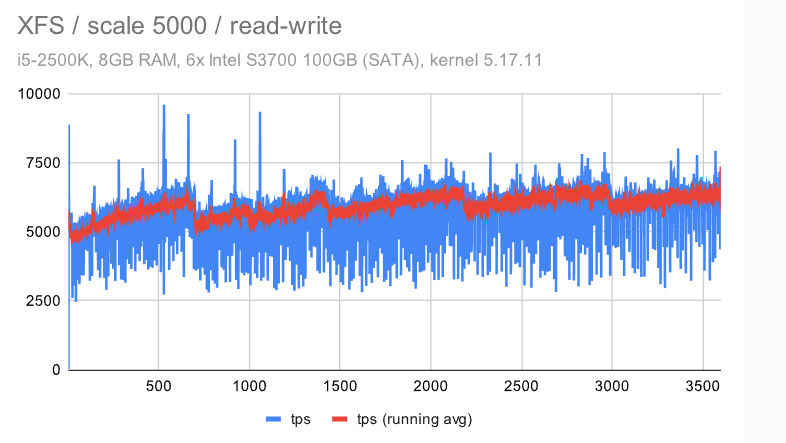
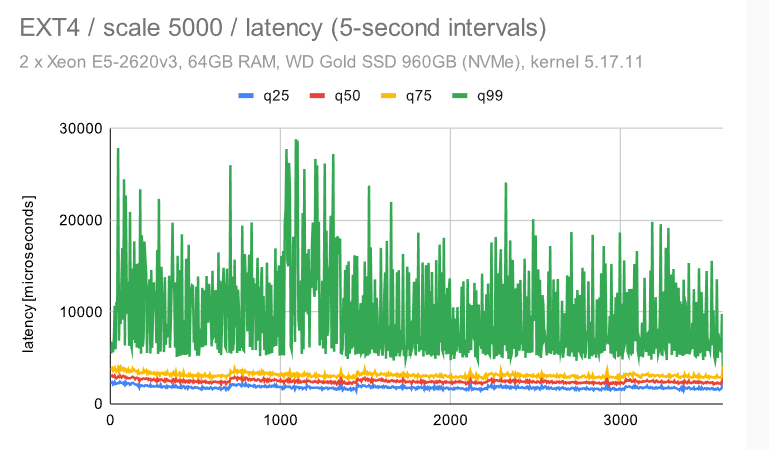

第一个观察结果是,检查点受到的影响要明显少很多 — 无论是对于具有默认配置的 ZFS 还是EXT4/XFS。这是由于数据集大小和随机访问 -——这意味着生成的FPW数量在达到WAL限制(并开始下一个检查点)之前不会下降。
对于BTRFS,情况比中等(规模1000)数据集要糟糕得多 -——不仅抖动更严重,而且吞吐量随着时间的推移逐渐下降 -——它开始接近4000 tps,但最终下降到只有大约2000 tps。
至强/规模 1000
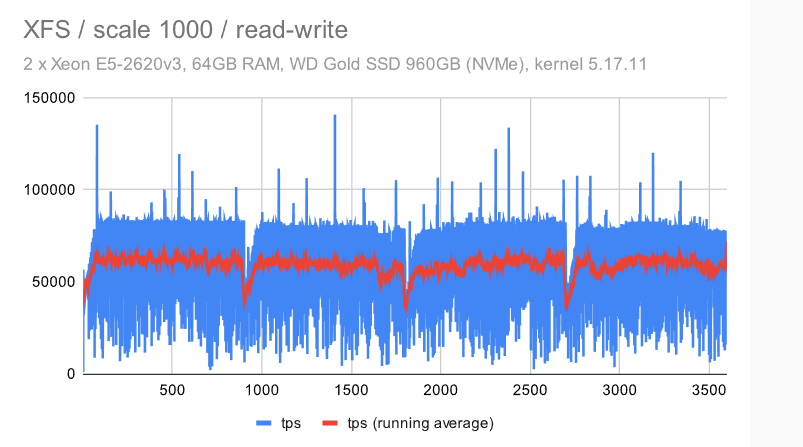
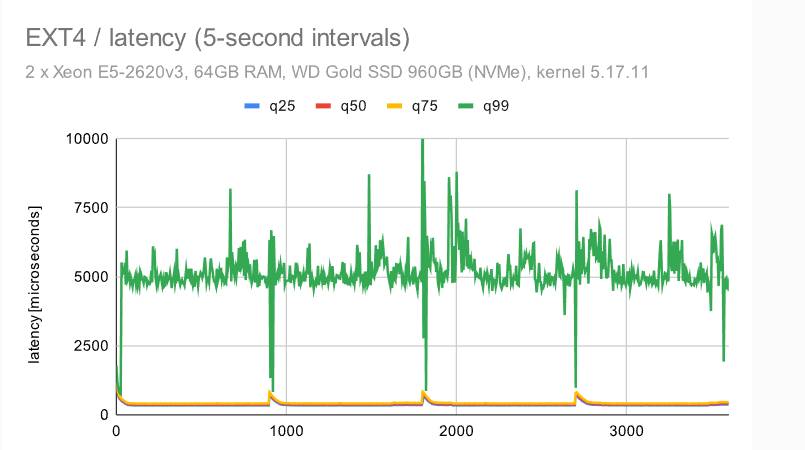
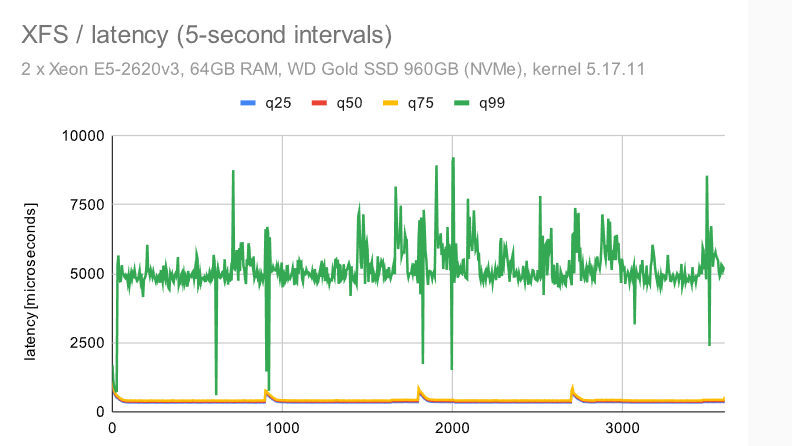
现在,让我们来看看使用单个NVMe设备的大型计算机的吞吐量。在中等规模上(大于共享缓冲区,适合RAM),它看起来像这样:
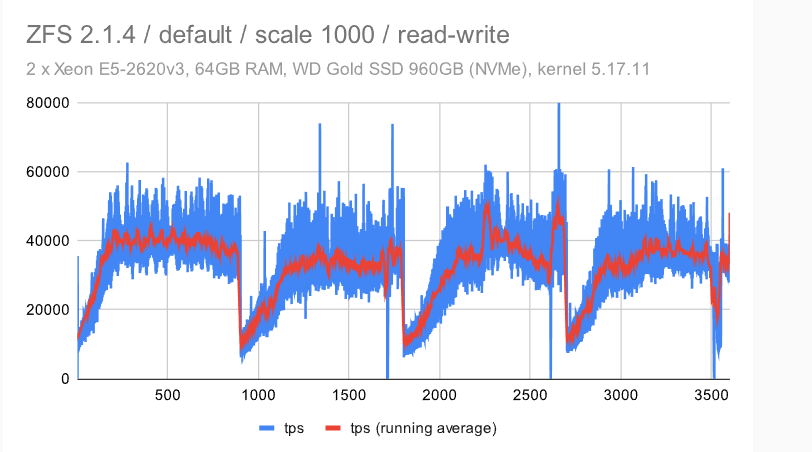
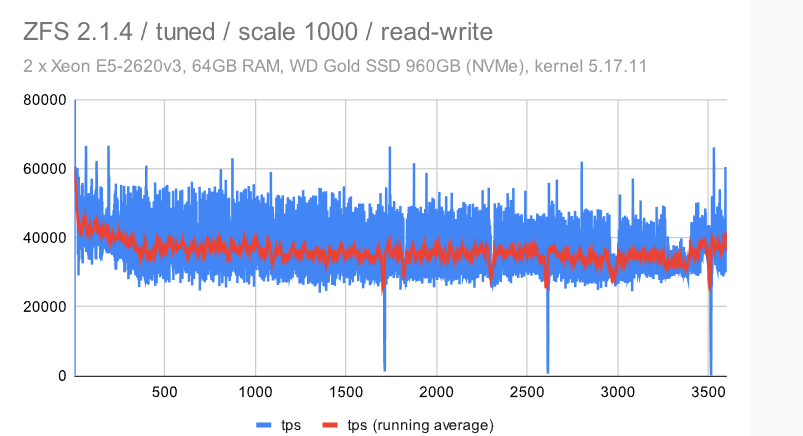

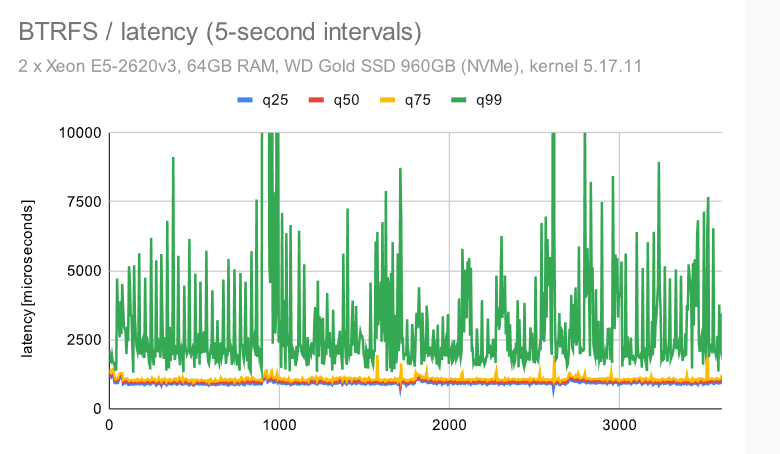

在具有默认配置的 ZFS 上,检查点模式清晰可见。使用调整后的配置,模式消失,而且行为变得更加一致。不同于具有多个设备的小型计算机流畅,但比其他文件系统更好。
EXT4 和 XFS 略有区别,无论是在总吞吐量还是随时间推移的行为方面。EXT4总吞吐量优于 ZFS(40k 与 60k),但抖动更严重。
对于BTRFS,整体吞吐量相当低(~30k tps),而抖动有时会比EXT4 / XFS更好,有时会更差。它似乎更接近平均吞吐量,但同时它也经常下降到 0。
至强/刻度 10000
在大型 (~150GB) 数据集上,结果如下所示:
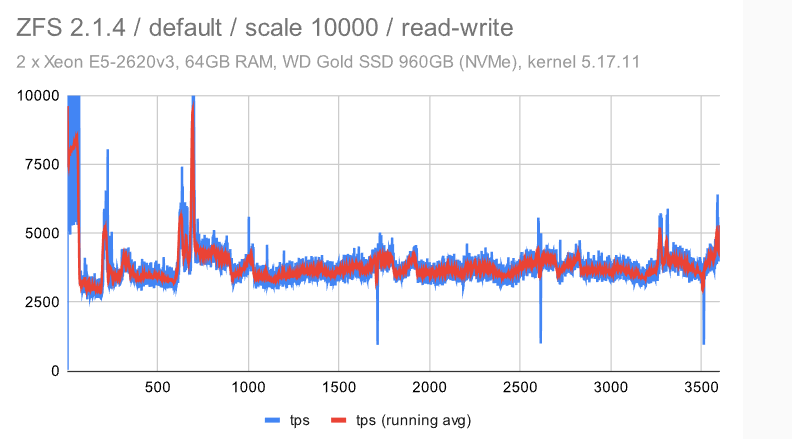
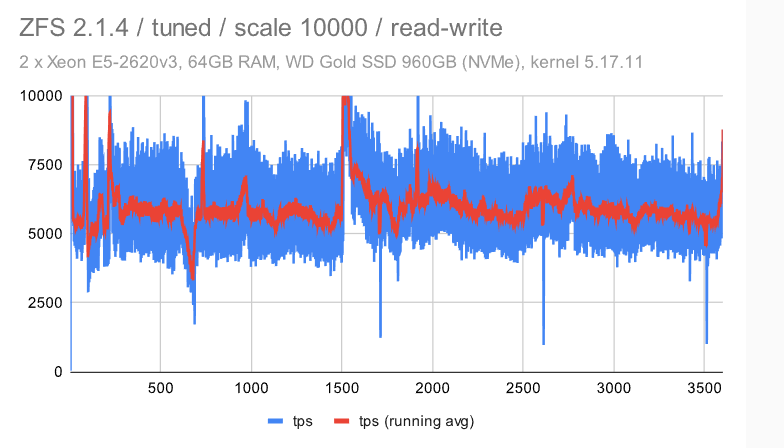
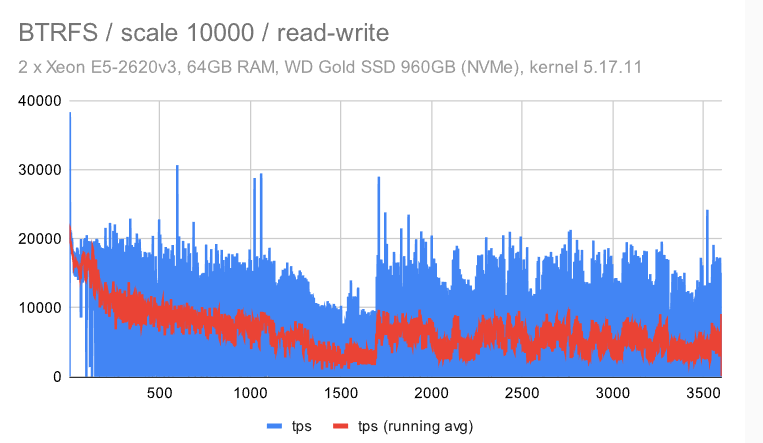
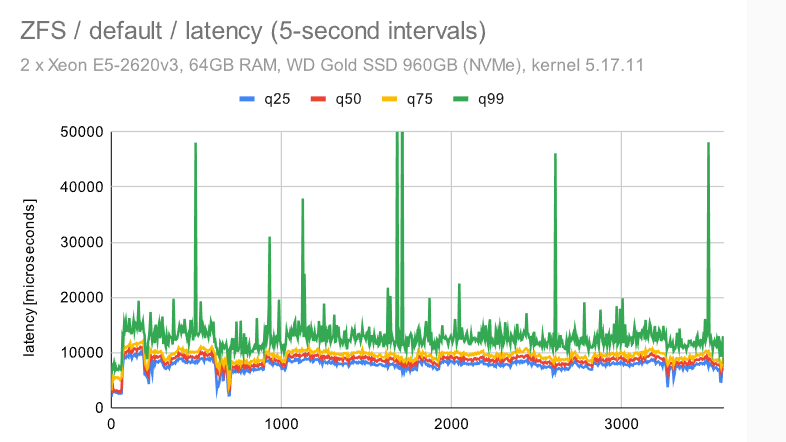
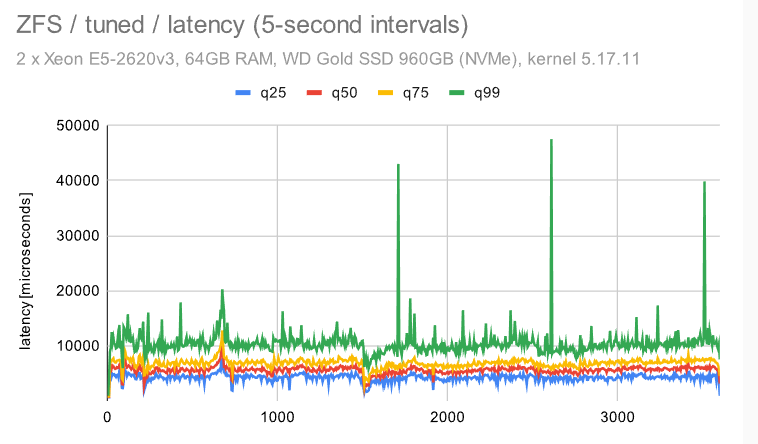

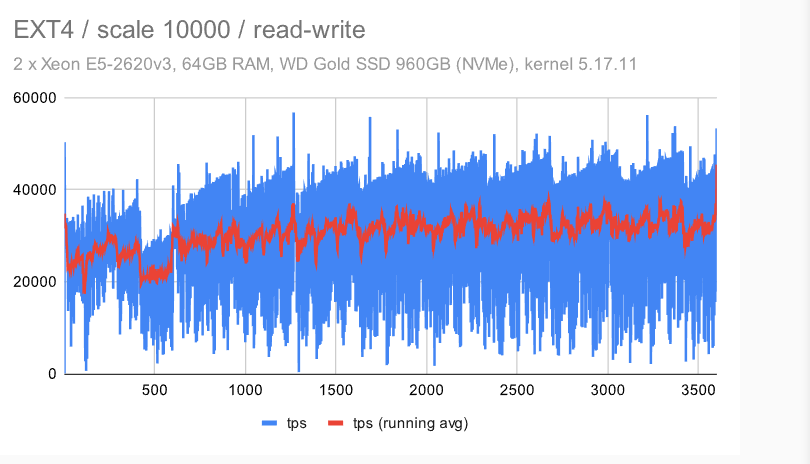

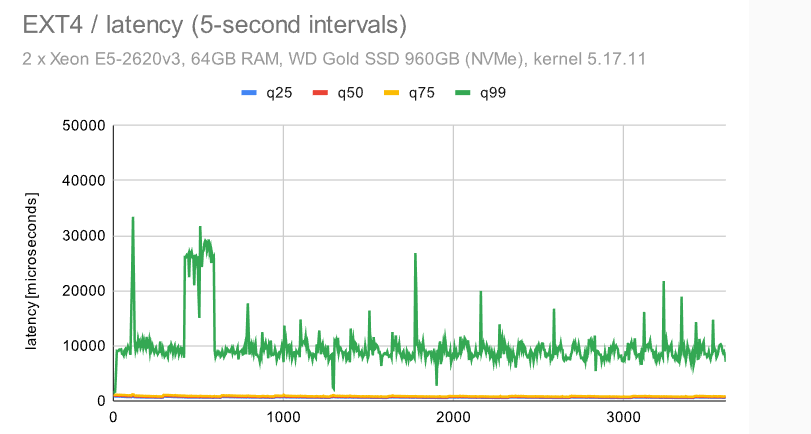
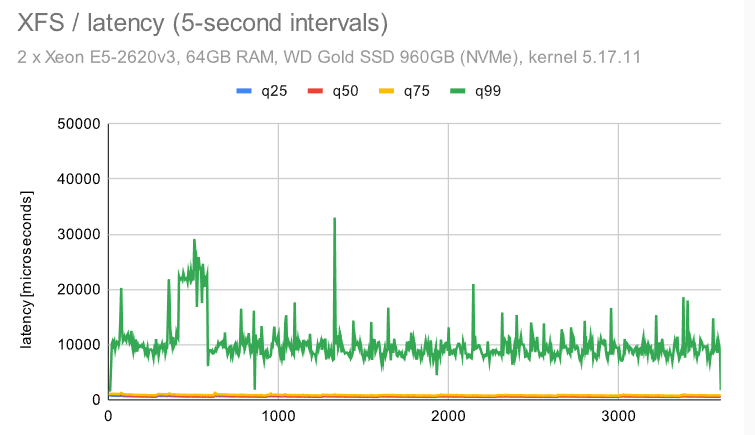
这类似于我们在较小的机器上看到的 -——检查点模式消失,这是因为我们必须写入WAL的FPW量。
在具有调谐配置的 ZFS 上,抖动显著增加。我不确定原因,但我想说它仍然相当一致(与其他文件系统相比)。
对于 EXT4/XFS,吞吐量下降到 ~50%(与中等规模相比),而同时抖动保持不变——我认为这是一个相当不错的结果。
使用BTRFS,我们看到与小型机器相同的不幸行为 -——使用大型数据集,吞吐量逐渐降低,同时抖动明显。
结论
那么,我们学到了什么?第一个观察结果是,评估的文件系统之间存在显著差异 ——但是,很难选出一个明显的赢家。
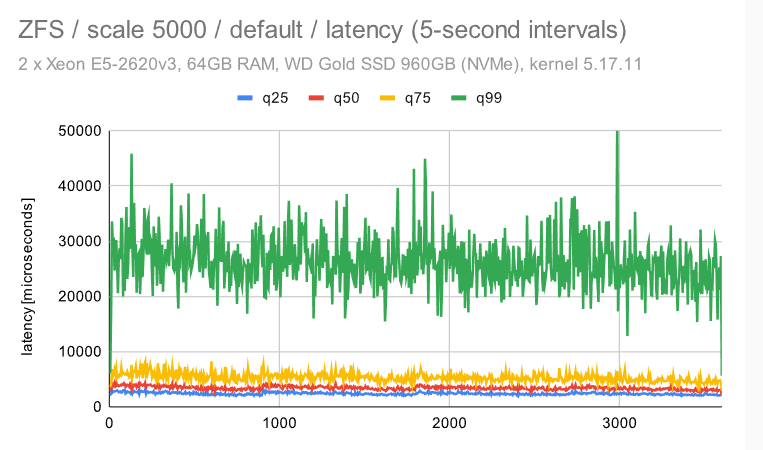
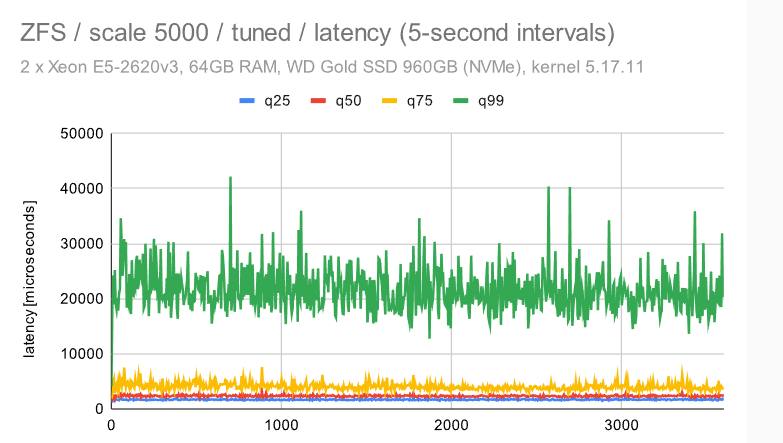
传统文件系统 (EXT4/XFS) 在 OLTP 工作负载中表现非常好,至少在总吞吐量方面是这样。ZFS 的性能也相当不错 ——在吞吐量方面有点慢,但行为非常一致,抖动最小(特别是禁用整页写入)。它也非常灵活 —— 例如,它允许将ZIL移动到单独的设备,这应该能够提高吞吐量。
至于BTRFS,结果不是很乐观 -——其实在几年前,我做了一个类似的OLTP基准测试,那一次BTRFS的表现要好一些。然而,总体共识似乎是,BTRFS不是特别适合数据库,其他人也观察到了这一点。这有点不幸,因为其中某些功能(更高的弹性,易于快照)对数据库非常有用。
读取结果时要记住的最后一件事是理解这些是使I / O子系统完全饱和的压力测试。在大多数生产系统上,情况并非如此 ———一旦 I/O 长时间饱和,你就已经在考虑升级系统以减少存储负载了,这通常意味着延迟应该改善等等。
原文标题:Postgres vs. File Systems: A Performance Comparison
原文作者:Tomas Vondra
原文链接:https://www.enterprisedb.com/blog/postgres-vs-file-systems-performance-comparison