




本文主要总结SSD扇区大小特点,以及对IO行为和ORACLE数据库的影响。理解不当之处,欢迎留言指出。
SSD扇区
扇区(sector)最早是机械盘(HDD)的概念,大小是512B。从HDD到驱动、文件系统以及各种IO相关函数在设计上都有相关的优化。固态盘(SSD)出来后,在物理上没有扇区,但为了跟上层的兼容,还是保留了扇区这个概念。
早期HDD的扇区大小定的是512B,SSD的扇区大小通常是4KiB,这样可以节省一些元数据和校验信息占用的空间。后来HDD也推出了扇区大小为4KiB的盘。

概念上扇区又分物理扇区和逻辑扇区。SSD在使用之前都会格式化一次,格式化的时候会确定逻辑扇区的大小。
Advanced Format
有些老的应用是基于512B大小的扇区设计的,在碰到4KiB扇区的盘时应用会无法正常运行。所以为了兼容老的应用,4KiB的盘通常会支持512B和4KiB两种逻辑扇区访问。这种格式叫做 Advanced Format,简称AF。HDD 4KiB盘也采用这个叫法。就访问方式定义有三种:
访问模式 | 逻辑扇区 | 物理扇区 | 备注 |
512n | 512 | 512 | 老的HDD常用。 |
512e | 512 | 4096 | 仿真模式 emulation |
4kn | 4096 | 4096 | 原生模式 native |
SSD 扇区大小查看方法
出厂的SSD一般已经按照默认配置格式化一次,所以可以先看扇区大小。最直观的方法是用命令:nvme list (这里针对NVME SSD)。

查看Format列可以看出逻辑扇区大小。这里有两块SSD,逻辑扇区大小分别是4KiB和512B。这个看不了物理扇区大小。
完整方法就是使用blockdev的getss 和 getpbsz 命令。
[root@ ~]# blockdev --getss dev/nvme0n14096[root@ ~]# blockdev --getpbsz dev/nvme0n14096[root@ ~]# blockdev --getss dev/nvme1n1512[root@ ~]# blockdev --getpbsz dev/nvme1n14096
SSD格式化
每个品牌的SSD支持的扇区大小不一定一样,可以通过命令:nvme id-ns 查看。
[root@ ~]# nvme id-ns dev/nvme0n1 -HNVME Identify Namespace 1:nsze : 0x37e3ee56ncap : 0x37e3ee56LBA Format 0 : Metadata Size: 0 bytes - Data Size: 512 bytes - Relative Performance: 0x2 GoodLBA Format 1 : Metadata Size: 8 bytes - Data Size: 512 bytes - Relative Performance: 0x2 GoodLBA Format 2 : Metadata Size: 0 bytes - Data Size: 4096 bytes - Relative Performance: 0x2 Good (in use)LBA Format 3 : Metadata Size: 8 bytes - Data Size: 4096 bytes - Relative Performance: 0x2 GoodLBA Format 4 : Metadata Size: 64 bytes - Data Size: 4096 bytes - Relative Performance: 0x2 Good
上面支持两种逻辑扇区大小 512B 和4KB。512B是为了兼容以前的IO库函数和上层应用用法。没有512B,某些老的应用在4KB的SSD上可能就跑不起来。比如说部署在文件系统上的ORACLE数据库。这是本文要解决的一个问题,后面会逐步展开分析。
格式化命令可以选择LBA格式,确定相应的扇区大小。也可以直接指定 block size 。
[root@ ~]# nvme format dev/nvme0n1 -l 0Success formatting namespace:1## 或者指定block size[root@ ~]# nvme format dev/nvme0n1 -b 4096Success formatting namespace:1
SSD分区
分区指用fdisk或 parted 命令对格式化后的SSD设备进行再分区。
分区不是必需的。一般是只有一块SSD 且想分开使用的时候采用。分区时如果是指定起点和结束点,那分区起点位置和容量都要是4096的倍数,通常称之为4KB对齐。如果是parted 命令的按比例创建分区,会自动对齐到4KiB。其他图形化分区软件通常也会4KiB对齐选项。
分区时之所以要做4KiB对齐,就是通常SSD物理扇区大小是4KiB。如果分区不做4KiB对齐,有可能一个4KiB的IO会跨越2个物理扇区。虽然SSD没有实际的扇区,但2个物理扇区在SSD内部也是两次IO。这个容易导致不必要的IO,降低SSD的性能。
Fdisk 命令通常也能看SSD的物理扇区和逻辑扇区大小。
[root@ ~]# fdisk -l dev/nvme0n1Disk dev/nvme0n1: 3840.8 GB, 3840755982336 bytes, 937684566 sectorsUnits = sectors of 1 * 4096 = 4096 bytesSector size (logical/physical): 4096 bytes 4096 bytesI/O size (minimum/optimal): 4096 bytes 4096 bytes[root@ ~]# fdisk -l dev/nvme1n1Disk dev/nvme1n1: 3200.6 GB, 3200631791616 bytes, 6251233968 sectorsUnits = sectors of 1 * 512 = 512 bytesSector size (logical/physical): 512 bytes 4096 bytesI/O size (minimum/optimal): 4096 bytes 4096 bytes
上面最后一行信息,虽然逻辑扇区是512B,但是I/O size最小还是4KB,这也说明AF的512e访问的一个特点。
512e问题
512e访问模式的问题主要是小于4096B的IO(指512、1024、1536、2048、3684)在发到SSD时,实际物理扇区读取的IO为4096。读取的多余数据会被丢弃。这个叫部分读(partial read)。小IO写时也会读取4KB的数据,修改其中512B 部分,然后再写回整个4KB的数据。这个叫部分写(partial write),在SSD扇区层面引起写放大。这类特点在数据库块设计里也存在,BTree的写放大 同理。
512e访问模式的另外一个问题是错位问题。即使IO大小是4KiB,如果起点没有做4KB对齐,则每个4KiB的IO实际在SSD内部都可能是两次IO。
文件IO
大部分应用场景并不直接读写磁盘,而是会在磁盘上建文件系统,通过文件IO读写磁盘数据。内核针对文件系统的读写有缓存设计,使用内存充当文件读写的缓存(内存中的PageCache部分),读写可以选择读PageCache或者写到PageCache,从而提升读写性能。PageCache里如果没有要读的数据,再从磁盘上读取到PageCache中。同时PageCache的数据也会定时刷新到磁盘中。文件读写是否选择缓存PageCache由文件打开时的标志决定。如果指定了 O_DIRECT,则后面所有相关读写都绕过PageCache直接操作磁盘,这种读写IO称为Direct I/O;如果没有指定,则后面所有相关读写都到PageCache,这种读写IO称为Buffer IO。
PageCache
PageCache是内存的一部分,大小没有固定的值。PageCache增长时可以用尽绝大部分可用内存。当内存不足的时候,PageCache中内存也会释放。如果释放不及时,可能导致某些程序申请内存失败,或者有程序因为OOM被杀掉。
PageCache大小可以通过命令:free -h 查看。
[root@ hcache]# free -htotal used free shared buff/cache availableMem: 503G 20G 367G 64G 115G 417GSwap: 0B 0B 0B
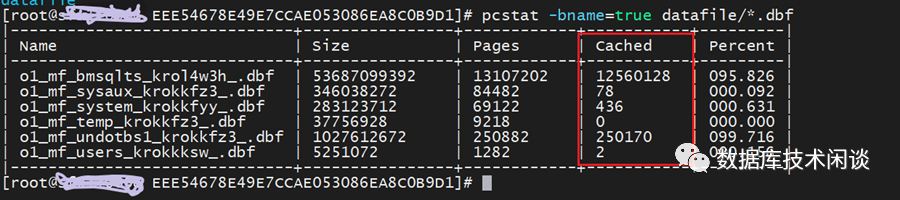
如果想看PageCache中被进程访问的文件,可以使用 hcache命令(下载地址:https://github.com/silenceshell/hcache)。hcache 是依赖命令 pcstat (下载地址:https://github.com/tobert/pcstat)获取信息。pcstat 可以看指定文件是否在PageCache中。
应用写在PageCache中的数据在没有刷到磁盘上时是“脏数据”,脏数据在刷新到磁盘前如果机器掉电了,脏数据就丢失了。刷新脏数据的策略由内核参数控制。调整参数可以在性能和数据安全之间取得一个平衡。
vim + /etc/sysctl.confvm.dirty_background_bytes = 0vm.dirty_background_ratio = 3vm.dirty_bytes = 0vm.dirty_expire_centisecs = 100vm.dirty_ratio = 10vm.dirty_writeback_centisecs = 50
PageCache 也可以立即刷脏清理,命令如下:
[root@ hcache]# sysctl -w vm.drop_caches=3 && free -hvm.drop_caches = 3total used free shared buff/cache availableMem: 503G 17G 477G 1.3G 8.6G 482GSwap: 0B 0B 0B[root@ hcache]#
文件系统屏蔽了底层存储的差异,当使用PageCache读写的时候,PageCache会自动跟SSD的物理扇区做4KiB对齐。所以应用的IO 大小就比较随意,不需要跟SSD扇区大小对齐。
如果应用IO是Direct I/O,那就直接绕过了PageCache,那应用IO的起点和大小就要跟SSD的扇区对齐。
Direct I/O
Direct I/O 是不使用PageCache的IO,可以将用户数据直接从用户空间的内存写到磁盘或者将磁盘数据直接读取到用户空间的缓冲区。因为不需要在内核缓冲和应用空间复制数据,所以最大性能会更高。这里有三个地方要跟磁盘扇区大小对齐:
1.用户空间的缓冲区在内存中要跟磁盘扇区大小对齐。
2.读写IO的起始值(start)地址要跟磁盘扇区大小对齐。
3.读写IO的大小要跟磁盘扇区大小对齐。
任意条件不满足,这个读写请求都会报错。
下面看一个示例:
[root@ ioresearch]# cat hello.c#define _GNU_SOURCE#define BUF_SIZE 8192#include <stdio.h>#include <unistd.h>#include <sys/stat.h>#include <sys/types.h>#include <fcntl.h>int main(int argc, char *argv[]){int count;int fd;int ret;//char buf[8192] = {0};char * buf ;if(argc<=2){printf("help: %s data/nvme0n1/text.txt 4 \n", argv[0]);return 1;}count = atoi(argv[2]);fd=open(argv[1], O_RDONLY|O_DIRECT);if(fd == -1){perror("open failed.");return 1;}ret = posix_memalign((void **)&buf, 4096, BUF_SIZE);if (ret){perror("posix_memalign buf failed.");return 1;}ret=pread(fd,buf,512*count,0);if(ret== -1){perror("pread text.txt error.");return 1;}printf("Bytes: %d\n",ret);//printf("Buff: %s\n", buf);return 0;}
代码使用 O_DIRECT 打开指定文件,然后读取一个指定大小(512B的倍数)的数据。当文件运行在逻辑扇区大小为512B的SSD上时不会报错,但运行在4KiB扇区大小的SSD上时可能就会报错。
[root@ ioresearch]# nvme listNode SN Model Namespace Usage Format FW Rev---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------/dev/nvme0n1 BTAC14930A0A3P8AGN INTEL SSDPF2KX038TZ 1 3.84 TB 3.84 TB 4 KiB + 0 B JCV10100/dev/nvme1n1 UE2237C1501M CSD-3310 1 25.92 GB 3.20 TB 512 B + 0 B U3219118[root@ ioresearch]# ls -lrth /data/nvme*n1/text.txt-rw-r--r--. 1 root root 487K Dec 3 13:20 /data/nvme0n1/text.txt-rw-r--r--. 1 root root 487K Dec 3 13:20 /data/nvme1n1/text.txt[root@ ioresearch]#[root@ ioresearch]# ./hello /data/nvme1n1/text.txt 7Bytes: 3584[root@ ioresearch]#[root@ ioresearch]# ./hello /data/nvme0n1/text.txt 7pread text.txt error.: Invalid argument
当没有应用源码的时候,可以通过 strace 命令追踪定位报错原因。
[root@ ioresearch]# strace ./hello /data/nvme0n1/text.txt 7execve("./hello", ["./hello", "/data/nvme0n1/text.txt", "7"], 0x7ffe914d5b70 /* 32 vars */) = 0uname({sysname="Linux", nodename="xxxxxx", ...}) = 0access("/etc/sysconfig/strcasecmp-nonascii", F_OK) = -1 ENOENT (No such file or directory)access("/etc/sysconfig/strcasecmp-nonascii", F_OK) = -1 ENOENT (No such file or directory)brk(NULL) = 0x129d000brk(0x129e1c0) = 0x129e1c0arch_prctl(ARCH_SET_FS, 0x129d880) = 0brk(0x12bf1c0) = 0x12bf1c0brk(0x12c0000) = 0x12c0000open("/data/nvme0n1/text.txt", O_RDONLY|O_DIRECT) = 3pread64(3, 0x129f000, 3584, 4096) = -1 EINVAL (Invalid argument)dup(2) = 4fcntl(4, F_GETFL) = 0x8002 (flags O_RDWR|O_LARGEFILE)fstat(4, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 15), ...}) = 0mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f1347d72000write(4, "pread text.txt error.: Invalid a"..., 40pread text.txt error.: Invalid argument) = 40close(4) = 0munmap(0x7f1347d72000, 4096) = 0exit_group(1) = ?+++ exited with 1 +++
报错位置:pread64(3, 0x129f000, 3584, 4096) = -1 EINVAL (Invalid argument)
Direct I/O大小跟文件系统块大小没有必然关系,只要是扇区大小的倍数即可。而Buffer I/O大小可以是任意大小,跟磁盘交互的是PageCache,I/O大小是文件系统块大小的倍数,所以使用Buffer I/O 的应用在扇区为4KiB的SSD上读写是没有问题的。
使用Direct I/O的场景原因推测至少有两个:
1.应用对数据安全要求很高。PageCache中缓存数据如果还么有刷到磁盘就碰到掉电,该数据会永久丢失。
2.应用自身对数据有缓存机制,使用PageCache再缓存性能不一定好。应用更懂自己的数据。
满足这两个推测的场景主要是数据库。使用 DirectI/O 估计挑战很大,所以真正用了的数据库也不多。如ORACLE、DB2、OceanBase 等。
ORACLE 数据库
ORACLE数据库有自己的缓存(SGA),支持以文件系统和裸设备两种方式访问存储设备。裸设备访问时没有文件系统,不需要文件系统缓存,在 IO负载型的 ORACLE 实例中,使用裸设备比使用文件系统性能要更好(据说能提升40%)。ORACLE使用裸设备时,读写IO无疑都是Direct I/O,所以内部会跟存储设备扇区大小对齐。裸设备的缺点就是管理和运维非常麻烦,容易出风险。后来 ORACLE 推出了ASM存储解决方案。
ORACLE ASM
ASM支持直接在裸设备上创建磁盘组(DISKGROUP),创建的时候可以指定扇区大小。如果没有指定,ASM会自动根据磁盘扇区去判断。同一个ASM DISKGROUP中的磁盘的扇区大小必须保持一致。虽然ASM提供了内部参数 _DISK_SECTOR_SIZE_OVERRIDE 去规避,但这个风险极大。
ASM主要是方便文件管理的,并不参与读写IO的路径,ORACLE使用ASM的时候,默认都会使用Direct I/O。
ORACLE 的 文件读写 I/O
ORACLE文件部署在文件系统上时,所有文件的读写IO特点是由ORACLE参数 filesystemio_options 控制。如果ORACLE 部署在文件系统上,这个参数默认值是 none (如 12c、19c)。
Property | Description |
Parameter type | String |
Syntax | FILESYSTEMIO_OPTIONS = { none | setall | directIO | asynch } |
Default value | Varies by database version and operating system. |
Modifiable | No |
Modifiable in a PDB | No |
Basic | No |
参数说明:
1.none:打开文件时禁用异步I/O和DIRECT I/O,默认是BUFFER IO和同步IO。
2.asynch:打开文件时允许异步 I/O。
3.directIO:打开文件时允许DIRECT I/O,绕过内核缓存PageCache。
4.setall:打开文件时允许异步I/O和DIRECT I/O。
这个参数应该是影响ORACLE所有文件,至少数据文件、REDO文件、UNDO文件是如此。
ORACLE 数据文件
ORACLE 数据库部署时需要指定块大小,默认是8KB。ORACLE 也支持1KB、2KB、4KB、16KB等块大小。使用4KB以及以上4KB的倍数大小时,在任何SSD上都没有问题。使用1KB和2KB 这种块大小时,在扇区大小为4KB的SSD上使用4kn访问模式是报错的,使用512e访问模式虽然OK,但是也可能有性能下降问题。
由于绝大部分客户ORACLE数据库块大小都是默认值8KB,所以这里从来都没有在SSD上碰到问题。ORACLE控制文件默认大小是16KB,因此理论上读写也不会有类似问题。
麻烦的是 ORACLE REDO文件。
ORACLE REDO
ORACLE数据库默认部署后,REDO文件默认块大小是512B。估计绝大部分客户的ORACLE实例都是这样。当把ORACLE实例放到只支持4kn访问模式的SSD盘上并且启用Direct I/O时,实例在启动的时候会报错。
SQL> startupORACLE instance started.Total System Global Area 1.6214E+11 bytesFixed Size 30393664 bytesVariable Size 2.4159E+10 bytesDatabase Buffers 1.3744E+11 bytesRedo Buffers 506474496 bytesDatabase mounted.ORA-03113: end-of-file on communication channelProcess ID: 87354Session ID: 6293 Serial number: 19434
查看数据库日志里报错信息如下。
2022-12-03T15:31:58.638659+08:00Errors in file /opt/oracle/diag/rdbms/orasfx/orasfx/trace/orasfx_lgwr_87202.trc:ORA-00313: open failed for members of log group 1 of thread 1ORA-00312: online log 1 thread 1: '/data/nvme0n1/oradata/ORASFX/onlinelog/o1_mf_1_krowg974_.log'ORA-27047: unable to read the header block of fileLinux-x86_64 Error: 22: Invalid argumentAdditional information: 12022-12-03T15:31:58.638753+08:00Errors in file /opt/oracle/diag/rdbms/orasfx/orasfx/trace/orasfx_lgwr_87202.trc:ORA-00313: open failed for members of log group 1 of thread 1ORA-00312: online log 1 thread 1: '/data/nvme0n1/oradata/ORASFX/onlinelog/o1_mf_1_krowg974_.log'ORA-27047: unable to read the header block of fileLinux-x86_64 Error: 22: Invalid argument
这个报错现象跟前面 Direct I/O 报错测试结果是一样的。我们也可以通过 strace 跟踪 lgwr 进程来定位更深一步的报错原因。(注:ORACLE 19C 启动时打开日志文件是 lgwr进程,打开成功后写日志文件是新的进程 lg0[0-4]。)
这里有个技巧,先将数据库实例启动到mount状态,得到 lgwr 进程的 pid 并用 strace 进行跟踪。然后再 open 数据库。
[root@ ~]# ps -ef|grep lgwr |grep -v greporacle 93757 1 0 15:35 ? 00:00:00 ora_lgwr_orasfx[root@ ~]# strace -p 93757^C[root@ ~]# strace -v -o /tmp/strace_orasfx_lgwr.log -ftt -p 93757 &[1] 97194[root@ ~]# strace: Process 93757 attached[root@ ~]# vim /tmp/strace_orasfx_lgwr.log<…>86 93757 15:39:08.435221 open("/data/nvme0n1/oradata/ORASFX/onlinelog/o1_mf_1_krowg974_.log", O_RDONLY|O_DIRECT) = 1087 93757 15:39:08.435245 fcntl(10, F_SETFD, FD_CLOEXEC) = 088 93757 15:39:08.435264 fstatfs(10, {f_type=EXT2_SUPER_MAGIC, f_bsize=4096, f_blocks=922933296, f_bfree=921945746, f_bavail=875057422, f_files=234422272, f_ffree=234422235, f_fsid={val=[67492032, 1889187805]}, f_namelen=255, f_frsize=4096, f_flags=ST_VALID|ST_NOATIME}) = 089 93757 15:39:08.435287 pread64(10, 0x7ffc3f414000, 512, 0) = -1 EINVAL (Invalid argument)90 93757 15:39:08.435306 close(10) = 091 93757 15:39:08.435330 rt_sigprocmask(SIG_BLOCK, NULL, [], 8) = 092 93757 15:39:08.435361 --- SIGSEGV {si_signo=SIGSEGV, si_code=SEGV_MAPERR, si_addr=NULL} ---93 93757 15:39:08.435379 rt_sigprocmask(SIG_BLOCK, [ALRM], NULL, 8) = 094 93757 15:39:08.435398 rt_sigprocmask(SIG_UNBLOCK, [SEGV], NULL, 8) = 095 93757 15:39:08.435418 rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
可以看到报错的地方是 pread 打开 redo log 时读取512 字节报错。
要解决这个问题有两个办法:
1.一是重新格式化SSD,逻辑扇区设置为512,提供 512e 仿真模式访问SSD。
2.二是更换 ORACLE REDO日志的块大小到4KB。
这里说后面这种方法。ORACLE 11G开始支持 4KB 块大小的 REDO 。刚开始新建不同块大小的REDO,ORACLE 默认会报错。
SQL> alter database add logfile group 4 size 2g blocksize 4096;alter database add logfile group 4 size 2g blocksize 4096*ERROR at line 1:ORA-01378: The logical block size (4096) of file /data/nvme0n1/oradata/ORASFX/onlinelog/o1_mf_4_%u_.log is not compatible with the disk sector size (media sector size is 512 and host sector size is512)
可以在ORACLE实例里开启参数 "_disk_sector_size_override"然后新增 4KB的REDO。
SQL> alter system set "_disk_sector_size_override"=TRUE scope=both;System altered.SQL> alter database add logfile group 4 size 2g blocksize 4096;Database altered.
最后再删除老的 512B的REDO 文件,就可以打开数据库了。这中间为了删除旧的REDO成功,还需要临时将参数 filesystemio_options 改回 none 将数据库打开才行。
结论
SSD使用之确认一下支持的访问模式。如果是全新的应用,或者不使用Direct I/O的数据库,建议 SSD 格式化时选择 4kn 模式。如果是 ORACLE 数据库,使用512e仿真模式最保险(但性能未必最好),对于使用 4kn 需要更换 REDO块大小,并充分测试,要考虑数据库扩容、升级、备份与恢复等多个情形。
参考
·Advanced Format: 4k Sector Size | flashdba : https://flashdba.com/4k-sector-size/
·Deep Dive: Oracle with 4k Sectors | flashdba : https://flashdba.com/4k-sector-size/deep-dive-oracle-with-4k-sectors/
·Oracle Workloads and Redo Log Blocksize – 512 bytes or 4k blocksize for redo log (VMware 4k Sector support in the roadmap) - Virtualize Applications : https://blogs.vmware.com/apps/2022/01/oracle-redo-blocksize-512b-4k.html
