





桔妹导读:HBase作为Hadoop生态中表现较为突出的分布式在线数据存储产品,在滴滴有着非常广泛的应用,但同样存在比较突出的短板问题——例如可用性较弱、毛刺严重等,一定程度上限制了它的业务边界。本文主要介绍在此背景下,HBase团队近期进行的一些探索工作。
1.
背景

HBase 是一个基于 HDFS 的低成本、分布式LSM结构数据库,可以支持毫秒级别查询;支持海量的PB级的大数据存储,适用于高QPS的随机读写和前缀范围查询等场景。此外,优秀的开源环境使得HBase还可以支持丰富的上下游生态与离线任务。
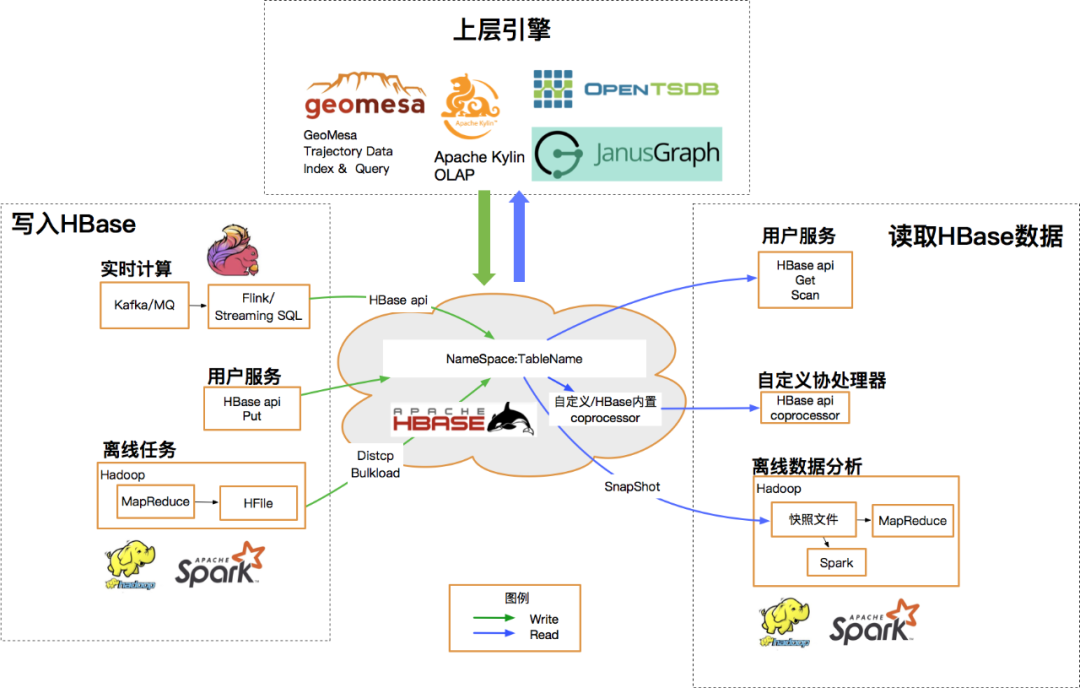
2020年下半年,HBase团队逐渐将视野投向端上/类端上业务,希望能够承载更加重要的流量。然而对于HBase自身架构和实现而言,主要存在两方面痛点:
▍1.可用性问题
架构层面看,HBase在CAP定理中选择了C,以较弱的可用性为代价换取强一致性,数据层面依赖HDFS保证数据安全,计算层面region无副本。
这样当region迁移、分裂、合并、RS宕机等情况发生时,对应region都会有短时不可用;而作为高吞吐的数据服务,客户端往往都会大量使用线程池,少量region不可用会迅速形成木桶短板,进而放大为整体TPS掉底。
社区提供的region replica功能一定程度上可以缓解这一问题,但一方面目前这个feature可靠性还不算高,社区仍在推进各种加固和改善,目测稳定的目标release版本可能要放到未发布的3.0了;另一方面端上服务需要双机房,保证容灾和降级,而replica是集群内的region副本,显然也不能支持。
HBase主要受Java GC和底层HDFS共用影响,HBase的毛刺相对突出,是进一步提升性能的瓶颈点。
基于以上两个痛点问题,HBase团队近半年进行了一些尝试与探索,主要是基于 replication的客户端多路读功能 与 HBase-ZGC应用实践,预期能够优化HBase的可用性与毛刺问题,简单分享给大家。
基于replication的客户端多路读功
2020年来,为提升HBase可用性,我们大体经历了两个阶段:
1. replication主备
replication是HBase的异步数据同步机制,和Mysql利用Binlog实现主从库类似,HBase利用WAL实现主备集群的数据同步。大致流程为主集群记录写入的WAL,并将数据异步发送给备集群,备集群接收数据并将其转换为put/delete操作,批量写入备集群。提供最终一致性保证。
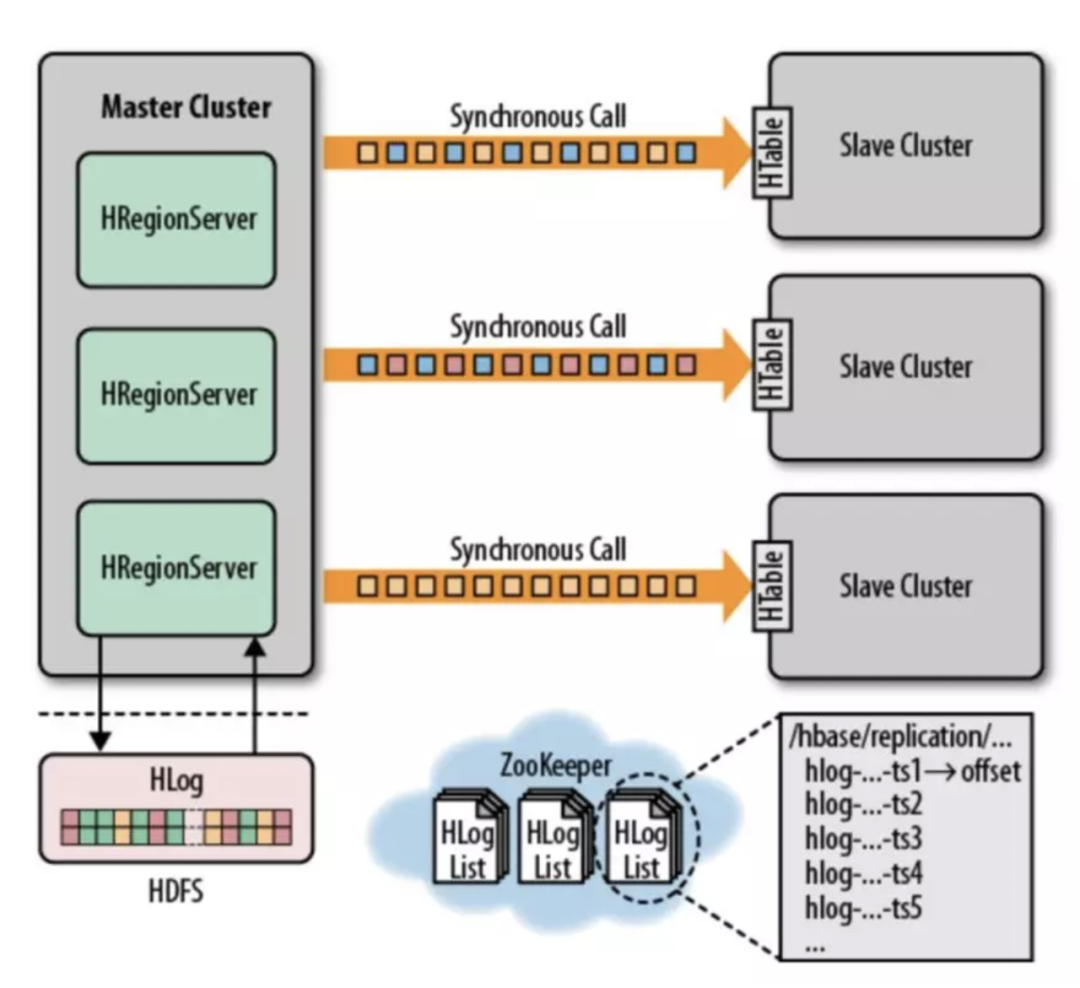
故障时用户有感知,需用户侧切读;
备集群利用率较低,资源闲置存在浪费;
2. replication + failover
failover是滴滴HBase团队基于replication自研的增强feature,架构如下图:
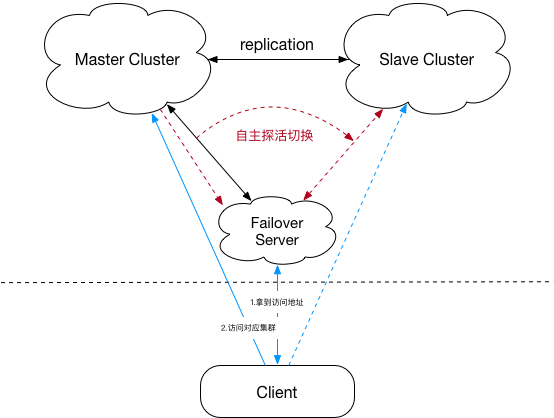
相比第一阶段,failover可以基于zk实现服务切换,不需用户操作。但仍然存在用户有感知、备集群无法充分利用的问题;
基于以上背景,我们又开发了基于replication的客户端多路读功能,预期解决以下问题:
故障时用户无感知;
提升备集群利用率;
打磨HBase毛刺;
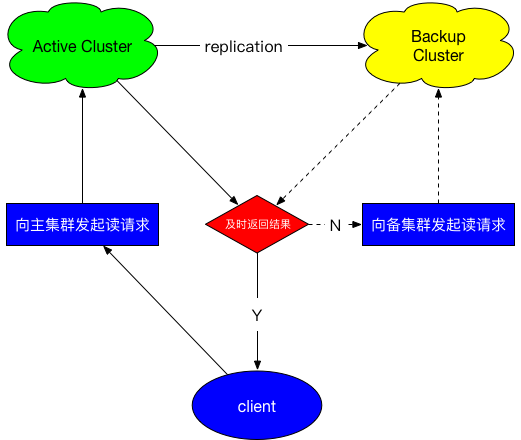
整体设计参考HDFS的hedgedRead功能,客户端首先向主集群发起读请求,一定时间没有返回结果则并发向备集群发起请求,两者取先完成者返回。
param | default value | desc |
hbase.client.hedged.read | false | 是否开启多路读 |
hbase.client.hedged.read.timeout | 50 | 启动备集群读线程的时间阈值 |
hbase.zookeeper.quorum.hedged.read | - | 备集群zk地址 |
两个集群分别创建主备测试表,构建replication
ycsb打入100w测试数据
测试组打开多路读,对照组关闭多路读,各发起10w次scan
客户端统计max、P999、P99
3.2 测试结论

max对比
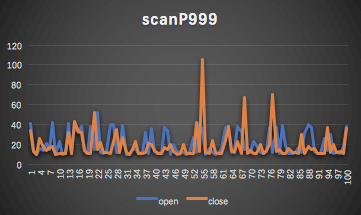
P999对比
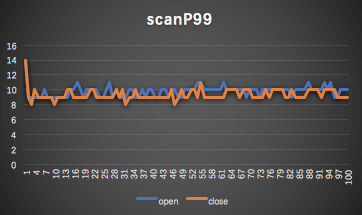
P99对比
方案一:多活 + 最终一致性
方案二:主备 + 强一致性
HBase-ZGC应用实践
▍1.为什么要更换GC算法?

Max pause times of a few milliseconds(*)
Pause times do not increase with the heap or live-set size (*)
Handle heaps ranging from a 8MB to 16TB in size
ZGC 的核心设计原则是将Load barriers与染色对象指针结合使用,这使得 ZGC 能够在 Java 应用程序线程运行时执行并发操作,例如对象重定向。从 Java 线程的角度来看,在 Java 对象中加载引用字段的行为受到加载屏障的影响。除了对象地址之外,colored oops 还包含加载屏障使用的信息,以确定在允许 Java 线程使用指针之前是否需要采取某些操作。
更低延迟:GC停顿时间更短,不超过 10ms
更大内存:堆内存支持范围更大(8MB-16TB)
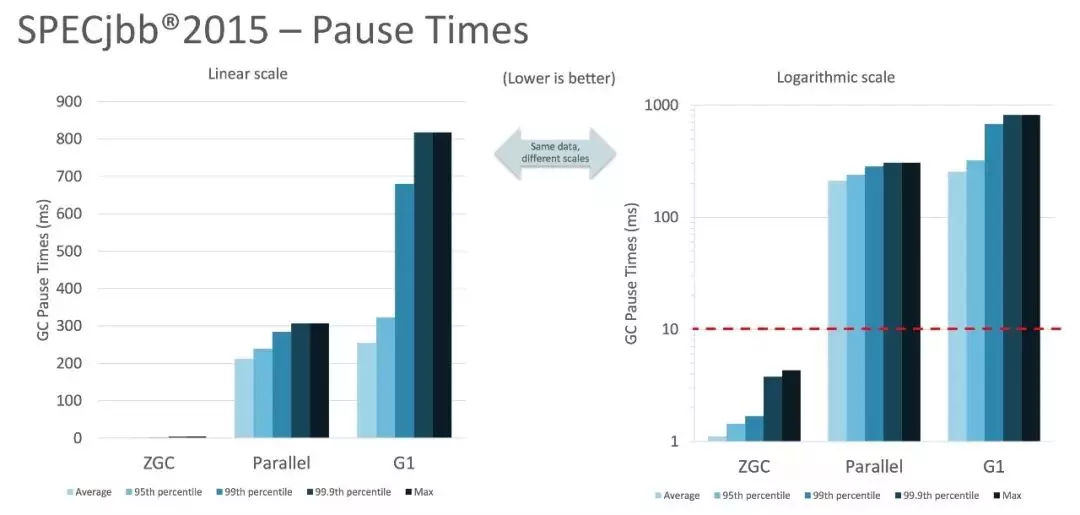
相较于G1只有写屏障没有读屏障,复制移动的过程需要Stop the world,ZGC通过读屏障、Remark标记和重定向表来并发拷贝非GC Roots对象,尽可能的减少了Stop the world。
官方的性能测试对比可以参考JEP333。本文主要介绍HBase场景的ZGC应用实践,对ZGC的原理不展开介绍。
JDK11存在小概率crash的问题
ZGC在JDK15版本正式生产环境可用
1. 部分类找不到或被删除,比如javax.xml.ws.http.HTTPException。解决办法:找到替换类或依赖包;
2. 一些类不可读,比如sun.nio.ch.DirectBuffer。解决办法:运行时添加--add-exports=java.base/sun.nio.ch=ALL-UNNAMED;
3. 依赖的组件包不支持JDK15,如Jetty、Jruby等。解决办法:升级对应的组件到高版本;
4. 编译插件不支持JDK15,如maven-shade-plugin、extra-enforcer-rules等。解决办法:升级对应的插件到高版本。
2.3 应用ZGC的效果:
1、顺序读场景ZGC和G1性能表现对比

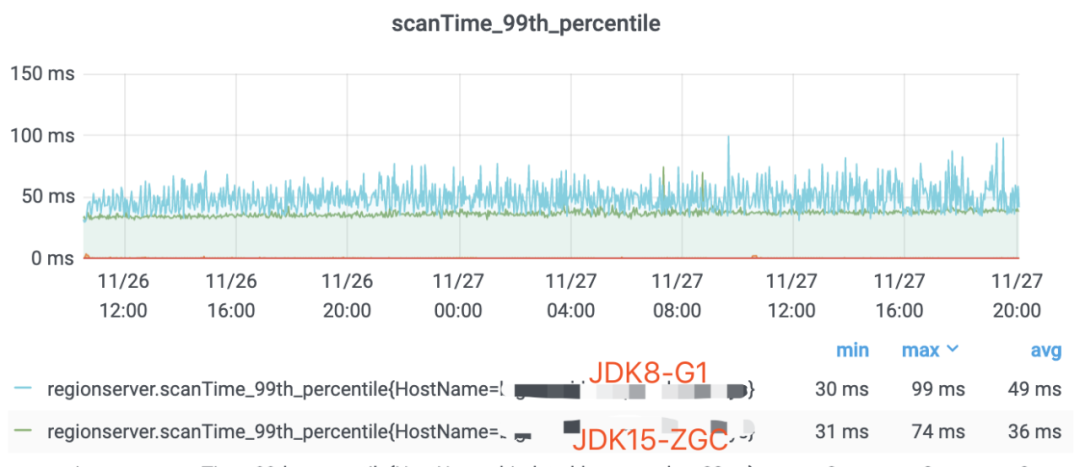
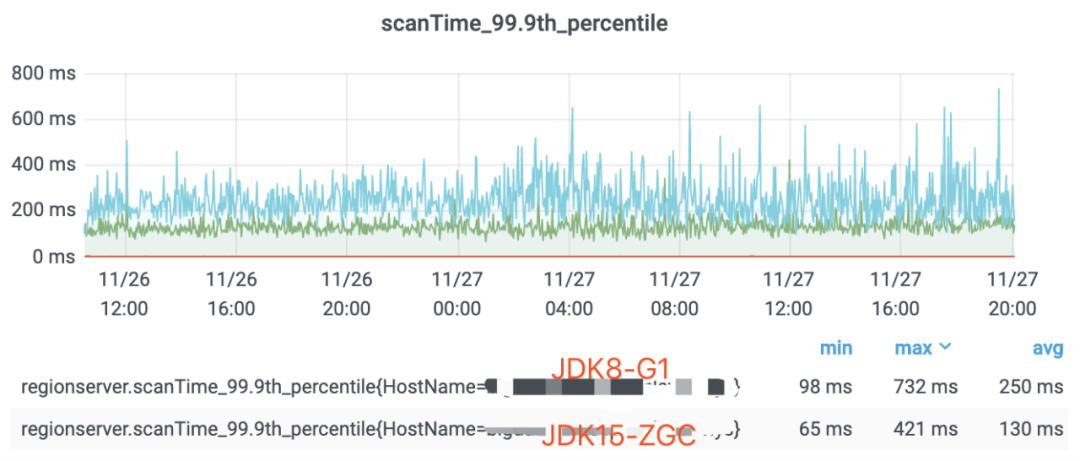
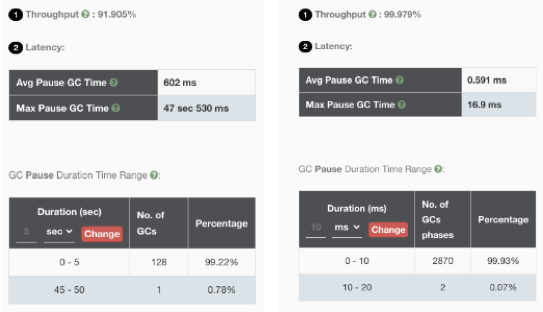
HBase使用ZGC可以有效的降低了服务端P99及P999的延时,非常适合对延迟较敏感的业务场景。
HBase在真正海量数据的离线应用场景下具备毋庸置疑的竞争力,但受其自身实现短板的限制,距离端上应用的标准还是存在一定距离的。滴滴HBase希望通过一系列优化手段,服务好离线业务的同时,未来可以接入更多的不涉及核心流程的线上/类线上业务,欢迎感兴趣的同学一起交流。
▬


团队招聘
▬
滴滴大数据架构离线引擎&HBase 团队主要负责滴滴集团大数据离线存储、离线计算、NoSQL 等引擎的开发与运维工作,通过持续应用和研发新一代大数据技术,构建稳定可靠、低成本、高性能的大数据基础设施,更多赋能业务,创造更多价值。
团队持续招聘 HDFS、YARN,Spark,HBase 等领域专家,参与滴滴大数据架构的建设工作,欢迎加入。
可投递简历到 diditech@didiglobal.com,邮件主题请命名为「姓名-应聘部门-应聘方向」。

扫码了解更多岗位




