导读:本文将 ClickHouse 分布式 DDL 执行原理进行剖析。主要包括三部分内容,首先探讨分布式 DDL 常见的执行异常的典型案例,然后结合典型案例剖析分布式 DDL 执行原理,最终在掌握原理的基础上对有可能踩到的坑做一个避险。
全文目录:
分享嘉宾|何李夫 网易数帆 技术专家
编辑整理|唐洪超 敏捷云
出品社区|DataFun
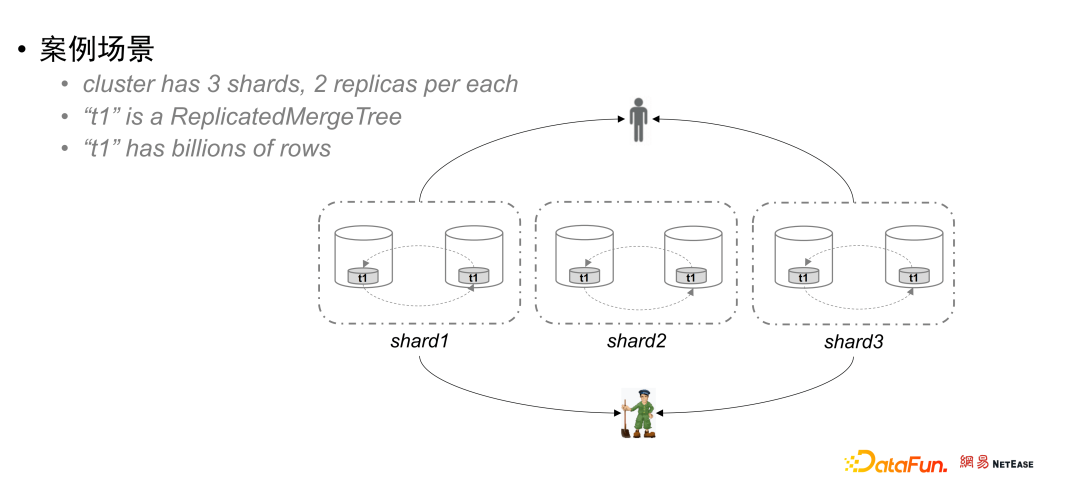
如上图所示,假设案例集群中有 3 个 Shard,每个 Shard 有两个副本,每个节点上都有一个本地表 t1,且是复制表引擎(ReplicatedMergeTree)类型,每张本地表存有数十亿的数据。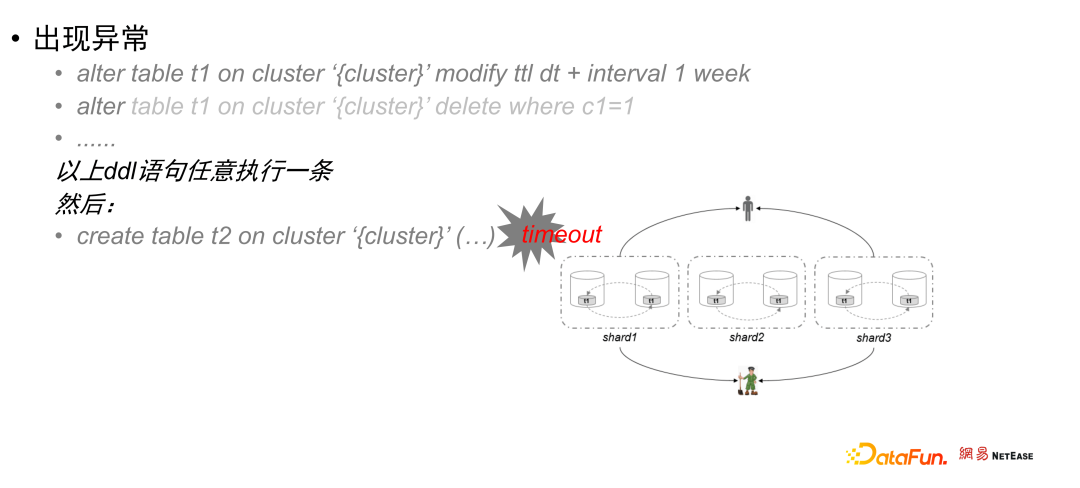
此时,过来一个需求,要求对 t1 表做元数据变更或者数据订正,直接提交执行:alter table t1 on cluster ‘{cluster}’ modify ttl dt + interval 1 weekalter table t1 on cluster ‘{cluster}’ delete where c1=1create table t2 on cluster ‘{cluster}’(……)不出意外,这个创建语句会执行超时,而且,后续的分布式 DDL 也会报超时,这就是大家通常说的 DDL 卡住了。
一旦 DDL 卡住,马上会有一堆的业务同学找上门来,此时冷静的运维同学会先检查集群的内部状态信息,针对上述出现的超时问题,凭经验通常会有以下一些运维操作:- 重启 clickhouse 或者 zookeeper
- 重新装载表 detach/attach table
但是哪一个操作方式是最恰当的呢,既不影响到整个集群,又能短时间内马上恢复业务?对于不了解内部实现机制的同学来说,简直就是两眼一抹黑,修复全靠猜。
耳熟能详的 ClickHouse 运维难,叠加此次的 DDL 卡住亲历事件,让业务方和平台运维方都心有余悸,为了避免这个问题的再次出现,最终规定:生产系统禁止使用 on cluster 语句,也就是禁止分布式 DDL,要求后续 DDL 语句必须在每个节点上单独执行;更有甚者为了避免麻烦,直接退回到单幅本集群去了。无论如何,运维时碰到分布式 DDL 执行的问题,不能蛮干,需要了解分布式 DDL 的执行原理,知道是在哪个环节出现的这个问题,下面剖析 clickhouse on zookeeper 分布式 DDL 的原理。02

通过前面这个典型案例的介绍,我们很有必要了解分布式 DDL 的执行原理,这里还是以上面的修改元数据 DDL 为例(胶片中是一段动画):client 端发送请求到接入 clickhouse 节点(coordinator),此节点将请求寄存到 zookeeper 分布式 DDL 队列中,然后请求会被拆成多个子任务,下发到每个节点执行,执行完成后的结果统一返回到 zookeeper,最后由接入 clickhouse 节点将 zookeeper 中的执行结果返回到 client 端。这个过程描述有点粗略,下面我们把每个具体的步骤结合代码再展开,强烈推荐给喜欢看源码的同学。首先我们需要知道,Clickhouse 集群是一种对等架构,在一个集群里每个clickhouse 节点都是独立的,即使是同一个 shard 内的不同副本节点间,也是没有主从节点的概念(但是内部通过 Zookeeper 还是存在 leader 角色的),所以分布式 DDL 处理逻辑就变得很复杂。下图是通过对源码的理解,绘制出的 clickhouse 处理分布式 DDL 任务流程图: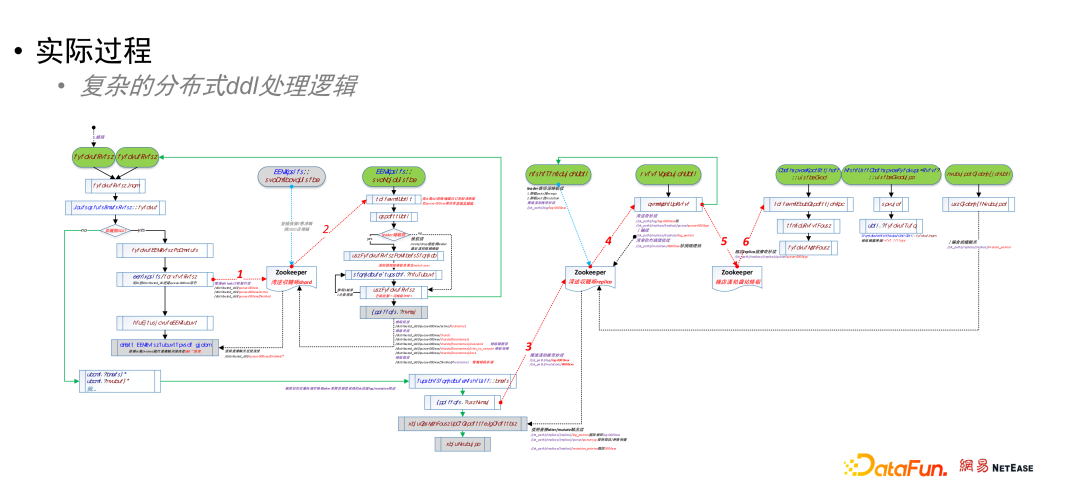
从流程图中看到,当有 DDL 任务进来的时候会先判断是否为分布式 DDL。如果为分布式 DDL,则在 zookeeper 中创建 ddl task 和子目录并同步到所有的 shard(以下涉及的目录详细信息会在下一节中进行阐述):- /distributrd_ddl/queue-000xxx
- /distributed_ddl/queue-000xxx/active
- /distributed_ddl/queue-000xxx/finished
①目录创建完成后,阻塞 getDistributedDDLStatus 进程等待获取/distributed_ddl/queue-000xxx/finished 目录下的各个节点执行的完成信息,在这里默认是 180 秒超时,如果在 180 秒内没有获取到完成信息,则进入后台指令模式,提示超时。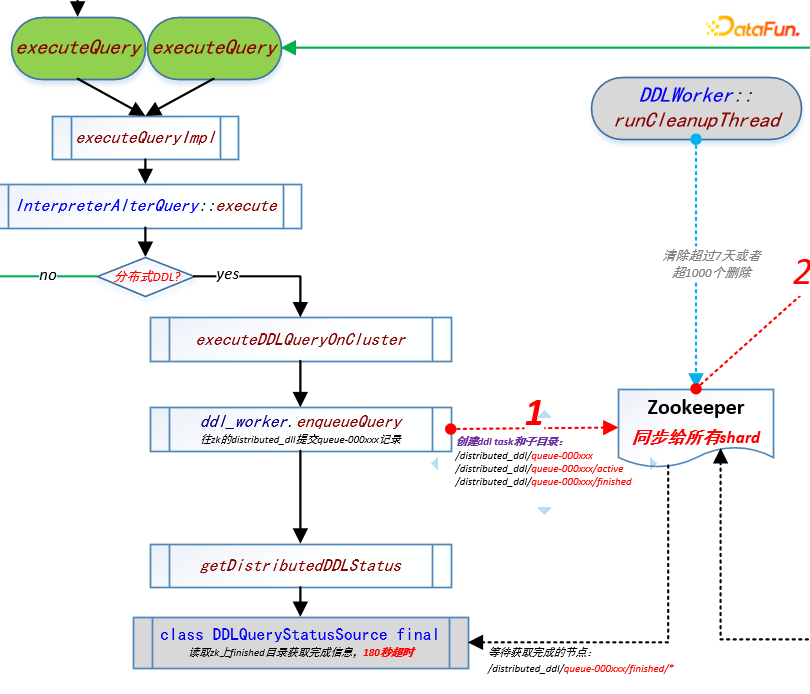
②每个 clickhosue 节点内部全局 context 都有一个 DDLWorker 模块,在该模块有一个线程 runMainThread,它的职责负责过滤出和本节点有关的 queue-000xxx 集合并下载到本地内存中逐一执行(串行),获取到集合后,根据 DDL 类型的不同判断是需要 leader 角色执行还是副本直接执行(如:creaete/drop 等不走 leader,各自副本直接执行),对于需要主节点执行的任务,程序进入到 tryExecuteQueryOnLeaderReplica 逻辑中,同时副本往 shard 路径下创建抢占锁,获得锁的副本在当前线程中执行 alter(绿色线),此时又会调 executeQuery,此时提交的为非分布式 DDL,直接执行 alter 或 mutate 等操作。
③承上,如在执行 alter 操作的时候,在当前 shard 下 replica 对应zookeeper 目录下的 log 目录下写入一个更改 matedata 的任务 {zk_path}/log/log-00000xxx,同时,如果操作涉及数据变更 mutation,会在当前 shard 下 replica 的 zookeeper 目录下的 mutations 下创建一个任务 {zk_path}/mutations/0000xxx,(以上任务 ID 都为递增 ID,ID 小的先执行,保证任务的顺序性),创建完成任务后,由各个 replica 去主动拉取 zookeeper 中的副本间任务到本地并执行(见下文流程4),此时进程阻塞,在 waitForLogEntryToBeProcessedIfNecessary 逻辑中监控 shard 对应 replica 目录下 log_pointer 和 mutation_pointer 是否大于当前提交的指针 log_0000xxx 和 oooooxxx,以及 queue/queue-yyy 是否消失,在都为是的情况下代表 replica 任务执行完成。
④ 在③中创建副本间任务后,每个 replica 中的 queueUpdatingTask 任务会通过 pullLogsToQueue 逻辑将副本间任务 /{zk_path}/log/log-00000xxx 同步到自己的副本目录 /{zk_path}/replicas/{replica}/queue/queue-0000yyy,移动/{zk_path}/replicas/(replica)/log_pointer,同时将 /{zk_path}/mutations/0000xxx 记录到内存中,当 mutation 积累一定量后,由副本中的 leader 角色节点的 mergeSelectingtask 任务选择 parts 做 merge 或者选择 part 做 mutation,选择完成后,创建副本间任务 {zk_path}/log/log-00000xxx,然后再通过副本queueUpdatingTask 拉取此任务到/{zk_path}/replicas/{replica}/queue/queue-0000yyy,进入处理队列中,最后由各个副本的后台线程池执行,执行完成删除 /{zk_path}/replicas/{replica}/queue/queue-0000yyy。
通过对流程图的描述,不难发现,其实一个分布式 DDL 操作是依托zookeeper 将任务从 DDL queue 到 shard 到 replica 一级一级传递下去执行的,显然,了解 clickhouse 在 zookeeper 中的文件目录结构对于理解 clickhouse 分布式 DDL 执行实际过程是很有必要的。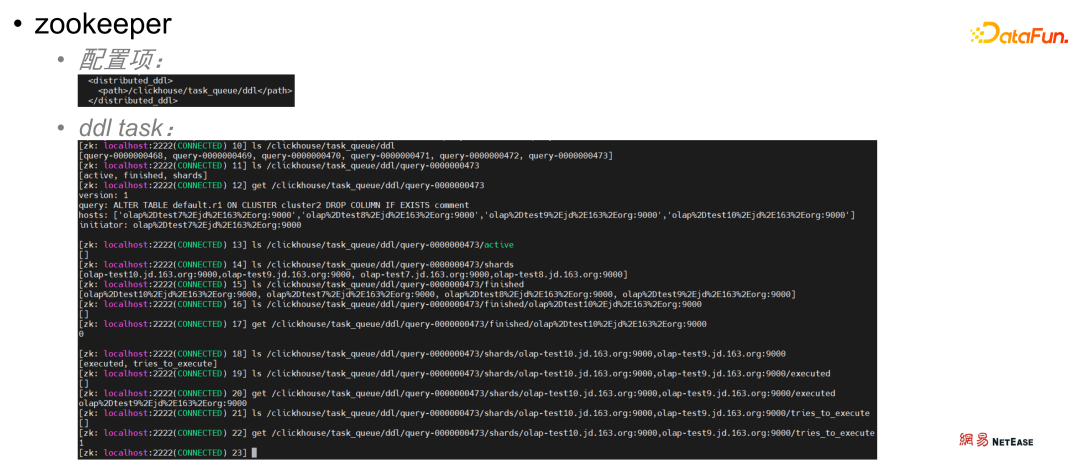
如上图,/clickhouse/task_queue/ddl 为 clickhouse 的 distributed_ddl 配置项配置的分布式 DDL zookeeper 目录。通过 zookeeper 客户端查看,可以看到在此目录下有多个任务,每个任务对应着不同的目录,目录的编号也是顺序的,这里通过 ls 命令查看 /clickhouse/task queue/ddl/query-0000000473 目录下的文件或目录可以看到有如下文件或目录:- /clickhouse/task queue/ddl/query-0000000473/active
- /cLickhouse/task queue/dd1/query-0000000473/shards
- /clickhouse/task_queue/ddl/query-0000000473/finished
- Active 保存当前集群内状态为 active 的节点 Finished 表示当前任务的完成情况;
- Shards 保存这个任务涉及哪些节点,即哪些节点需要执行这个任务;
- finished 用于检查任务的完成情况,每个节点执行完毕后就会在该目录下写入一条记录。
通过 get /clickhouse/task queue/ddl/query-0000000473 目录,可以看到详细任务描述。
- query 项的值表示该任务的执行的语句:ALTER TABLE default.r1 ON CLUSTER cLuster2 DROP COLUMN IF EXISTS comment
- initiator 项的值表示任务提交节点,query 语句也是由该节点记录到 zk 的 ddl 目录上的,同时由这个节点负责监控任务的执行进度
在 /clickhouse/task_queue/ddl/query-0000000473/finished 目录下还有用节点 ip 和 9000 端口命令的目录,通过 get 可以看到值为 0,表示该节点的任务执行成功。从上述 clickhouse 分布式 DDL 任务实际过程中可以看到,DDLWorker是串行执行的,因此当前一个任务未执行完成时,后面所有的任务都会堵塞,这就是造成实际使用中 DDL 任务超时的原因。下面是 clickhouse 源码 DDLWorker.cpp 部分中的一段:
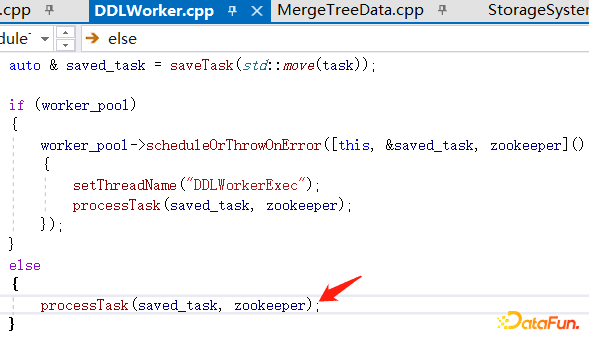
通过对源码的阅读,看到当 pool_size 大于 1 的时候 clickhouse 是支持线程池的方式运行 DDL,但是在源码中,pool_size 默认是 1,也即没有开启线程池模式,这是为了保证 DDL 语句在执行时候的顺序性,如果 pool_size 修改为大于 1,这个时候,DDL 不再保持顺序性,执行结果不再可控,或许多个 DDL 语句执行下来,结果并不如预期,只有在对 DDL 顺序执行不关注的业务中,才可以开启 clickhouse 线程池运行 DDL。由于 clickhouse 默认是单线程,提交的任务会提交到一个队列中,先提交的先执行,先提交的 DDL 任务未执行完成时,后提交的任务会一直阻塞,当你操作大对象的时候,需要的变更耗时增长,这个时候,很可能会造成长时间的阻塞,导致后面提交的任务出现 timeout。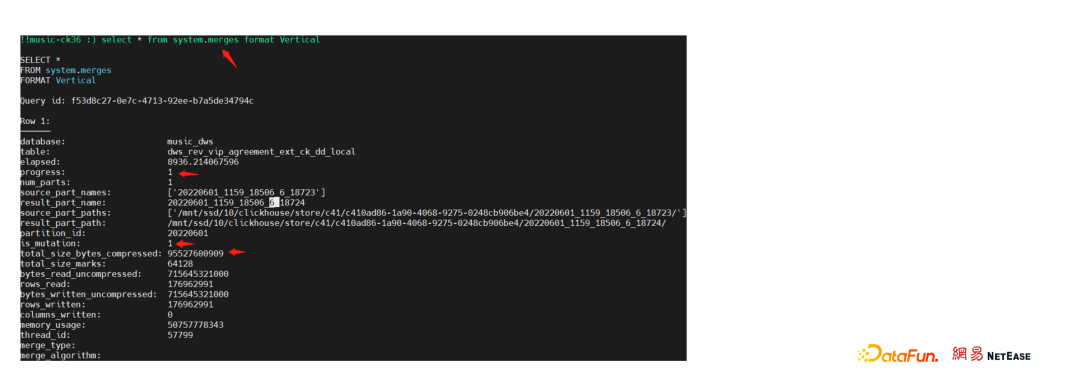
如上图,查看 system.merges 表,查询到一个变更,涉及 90GB+ 的数据需要读取、订正、写入,这个过程耗费大量时间,会导致后面提交的 DDL 堵塞。下图为某个表的信息,通过查看该表的分区信息表 system.parts 可以看到,不同的分区数据量大小不一,最小的分区才 5.21Kib,最大的分区超过 100GB。
再如下图,对该表做如图所示 delete 删除操作时,涉及所有字段,此时涉及到的文件要重新写一遍,io 开销很大;而 drop操作和 update 操作,只涉及到某一列(即文件)的数据,drop 操作(删除 C2 列)只涉及到 c2 列,update 操作(对 C4 中某一个字段做更新)对 C4 列只涉及到 C4 列,其余列文件通过 hard link 继续使用而无需其余操作,IO 开销较小。
因此,在 DDL 操作中要明确操作对象和操作范围,减少不必要的 IO 开销,提高 DDL 操作的效率,减少堵塞。如果操作对象和范围无法规避,应控制尽量减少 IO 开销,如:① 在执行操作 alter table t1 on cluster ’{cluster}’ modify ttl dt -interval 1 week 前:- 在操作上判断剔除不需要的分区,在执行任务前先把该分区删除:drop unwanted partitions
- 在参数上开启延迟物化,让任务在后台延迟完成而不是立即执行:配置参数 matetialize_ttl_after_modify=0
- 在参数上开启延迟删除,让任务在后台延迟完成而不是立即执行:配置参数 ttl_only_drop_parts=1
② 在执行 alter table t1 on cluster ‘{cluster}’ delete where c1=1- 在设计上使用 update 代替 delete,即将需要删除的数据修改为某些特定的值 在 select时通过该值将数据过滤掉,或者使用更友好的 row policy 限制,使得查询更加无感知
生产上在很多时候,提供了 SQL 的执行入口后,很多操作是不可控的,为了集群的健康和安全,监控报警是我们的必要操作。- 查询 clickhouse 进程列表:show processlist
- 查询 clickhouse 的合并信息:select * from system.merges
- 查询 clickhouse 执行的任务:select * from system.mutations where is_done=0
- 查询是否有运行时间超过规定时间的 mutation 操作:select * from cluster(‘{cluster}’, system.merges) where database not in ('system','information_schema', 'INFORMATION_SCHEMA') and is_mutation and elapsed > 120
通过 kill语句将长时间运行的 mutation 任务杀掉:kill mutation where database=‘’ and table=‘’- 通过二次开发,增加新特性,通过阈值,拒绝超过限定大小的重 IO 操作,在任务还未启动时将任务 kill 掉
社区也已经提交了一个轻量级删除的项目,可能在不久后就会上生产:
https://github.com/ClickHouse/ClickHouse/pull/37893
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。













