




导读
相信对于Oracle DBA来说,直方图一定不陌生了,但是对于MySQL DBA来说,尤其是MySQL5.6 5.7的使用者来说,可能就有一点陌生了。在使用MySQL5.7及以下版本的时候,经常会碰到由于数据倾斜等原因,导致优化器根据现有的索引统计信息并没有给出最优的执行计划,而直方图就能够很好地解决这种尴尬的窘境,今天我们就一起来看看什么是直方图。
什么是直方图
直方图是MySQL8.0.2开始推出的,也是MySQL8.0最重要的特性之一。在某些情况下,优化器无法找到最佳的执行计划,因为忽略了某些未索引的列。引入直方图的目的是为优化器提供基于直方图的统计信息,从而生成更优的执行计划。
假如有一个存储火车出发时间表:
CREATE TABLE train_schedule(
id INT PRIMARY KEY,
train_code VARCHAR(10),
departure_station VARCHAR(100),
departure_time TIME);
假设高峰时段(从7AM到9AM),而夜间一般来说班次很少,也就是说在7-9点之间的行很多,而凌晨的行数很少,现有查询如下
SELECT * FROM train_schedule WHERE departure_time BETWEEN '07:30:00' AND '09:15:00';
SELECT * FROM train_schedule WHERE departure_time BETWEEN '01:00:00' AND '03:00:00';
在没有任何统计信息的情况下,优化器默认情况下会假设departure_time列中的值是均匀分布的,但实际上并不是均匀的,第一个SQL返回的行数更多。
直方图的出现能够为优化器提供更好的预估,尤其是在JOIN中包含多个表,对于优化器决定执行计划中考虑表的顺序,返回的行数就非常重要了。
如果对返回的行进行了很好的预估,优化器可以在返回少数行的情况下在第一阶段打开表,这样可以使笛卡尔积的总行数最小化,使查询更快。
直方图的分类
等宽直方图
等高直方图
等宽直方图
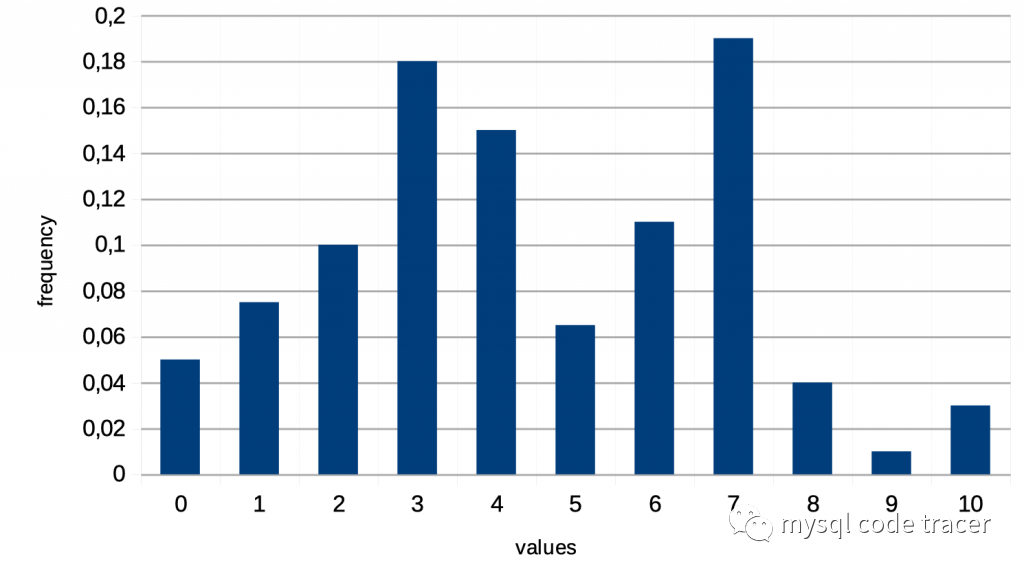
等宽直方图的特点:
每个桶代表一个值
每个桶存储了值、频率数据
适用于等值和范围条件
等高直方图
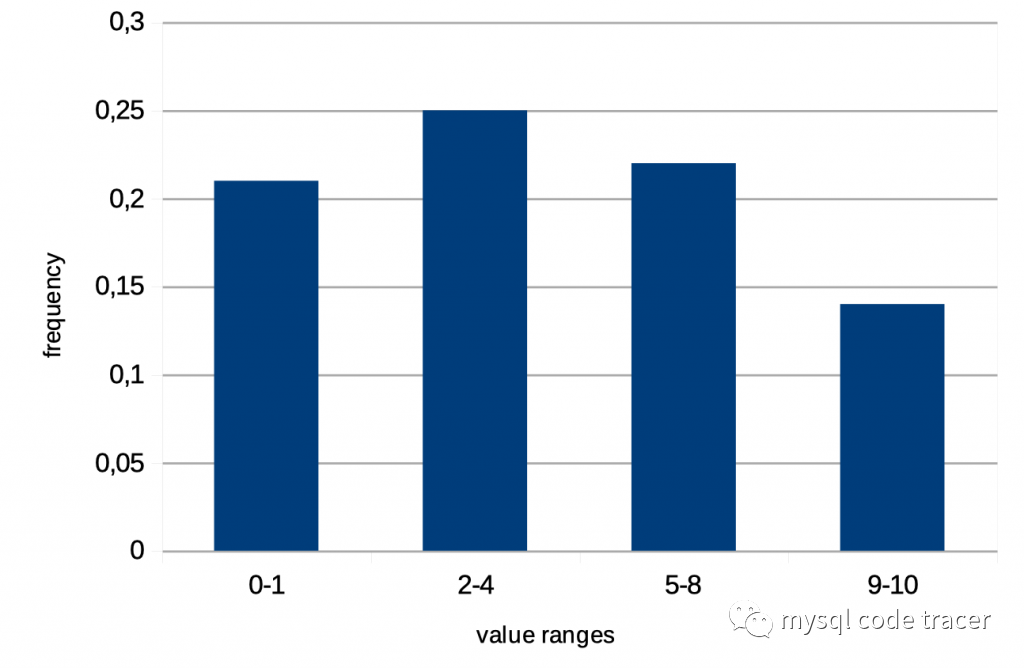
等高直方图的特点:
每个桶存储了多个值
每个桶存储了最大值、最小值、累积频率、不同值的数量
不是真正的等高:频繁的值存储在单独的桶中
适合范围条件
直方图运维
创建直方图
mysql> ANALYZE TABLE city UPDATE HISTOGRAM ON population WITH 1024 BUCKETS;
+------------+-----------+----------+-------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+------------+-----------+----------+-------------------------------------------------------+
| world.city | histogram | status | Histogram statistics created for column 'Population'. |
+------------+-----------+----------+-------------------------------------------------------+
说明:如果不指定BUCKETS的数量,默认为100
删除直方图
mysql> ANALYZE TABLE city DROP HISTOGRAM ON population;
+------------+-----------+----------+-------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+------------+-----------+----------+-------------------------------------------------------+
| world.city | histogram | status | Histogram statistics removed for column 'population'. |
+------------+-----------+----------+-------------------------------------------------------+
查看直方图
mysql> SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, JSON_PRETTY(HISTOGRAM)
-> FROM information_schema.column_statistics
-> WHERE COLUMN_NAME = 'population'\G
*************************** 1. row ***************************
SCHEMA_NAME: world
TABLE_NAME: city
COLUMN_NAME: Population
JSON_PRETTY(HISTOGRAM): {
"buckets": [
[
42,
455,
0.000980632507967639,
4
],
...
[
9696300,
10500000,
1.0,
4
]
],
"data-type": "int",
"null-values": 0.0,
"collation-id": 8,
"last-updated": "2020-04-26 13:06:01.657385",
"sampling-rate": 1.0,
"histogram-type": "equi-height",
"number-of-buckets-specified": 1024
}
1 row in set (0.00 sec)
说明:
schema_name:schema的名字
table_name:表名
column_name:列名字
json_pretty(histogram):json格式化直方图信息
data-type:数据类型
null-values:null值个数
collation-id:直方图数据的collation id,对应于INFORMATION_SCHEMA.COLLATIONS表中的值,对于string类型的列该列才有意义
last-updated:最近更新时间
sampling-rate:采样率
histogram-type:直方图类型
number-of-buckets-specified:buckets数量
来看一个等宽直方图
mysql> ANALYZE TABLE country UPDATE HISTOGRAM ON Region;
+---------------+-----------+----------+---------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+---------------+-----------+----------+---------------------------------------------------+
| world.country | histogram | status | Histogram statistics created for column 'Region'. |
+---------------+-----------+----------+---------------------------------------------------+
1 row in set (0.01 sec)
mysql> SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, JSON_PRETTY(HISTOGRAM) FROM information_schema.column_statistics WHERE COLUMN_NAME = 'Region'\G
*************************** 1. row ***************************
SCHEMA_NAME: world
TABLE_NAME: country
COLUMN_NAME: Region
JSON_PRETTY(HISTOGRAM): {
"buckets": [
[
"base64:type254:QW50YXJjdGljYQ==",
0.02092050209205021
],
...
[
"base64:type254:V2VzdGVybiBFdXJvcGU=",
1.0
]
],
"data-type": "string",
"null-values": 0.0,
"collation-id": 8,
"last-updated": "2020-04-26 13:10:44.368923",
"sampling-rate": 1.0,
"histogram-type": "singleton",
"number-of-buckets-specified": 100
}
什么时候创建等宽直方图,什么时候创建等高直方图?
这一点在MySQL创建直方图时自动将值划分为存储桶,并自动决定要创建哪种直方图。
关于histogramgenerationmaxmemsize
histogramgenerationmaxmemsize定义了直方图使用的最大内存,默认值为20000000,单位是bytes,约为20M,该值建议不要设置过大,避免直方图占用过多的内存。
但是这个值如果不够大的话,也会导致采样比例过低,数据统计不准确。
直方图测试
# 数据及查询条件说明
mysql> select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000;
+-----------------+-----------+
| name | language |
+-----------------+-----------+
| Mumbai (Bombay) | Asami |
| Mumbai (Bombay) | Bengali |
| Mumbai (Bombay) | Gujarati |
| Mumbai (Bombay) | Hindi |
| Mumbai (Bombay) | Kannada |
| Mumbai (Bombay) | Malajalam |
| Mumbai (Bombay) | Marathi |
| Mumbai (Bombay) | Orija |
| Mumbai (Bombay) | Punjabi |
| Mumbai (Bombay) | Tamil |
| Mumbai (Bombay) | Telugu |
| Mumbai (Bombay) | Urdu |
+-----------------+-----------+
12 rows in set (0.04 sec)
mysql> show create table city\G
*************************** 1. row ***************************
Table: city
Create Table: CREATE TABLE `city` (
`ID` int NOT NULL AUTO_INCREMENT,
`Name` char(35) NOT NULL DEFAULT '',
`CountryCode` char(3) NOT NULL DEFAULT '',
`District` char(20) NOT NULL DEFAULT '',
`Population` int NOT NULL DEFAULT '0',
PRIMARY KEY (`ID`),
KEY `CountryCode` (`CountryCode`),
CONSTRAINT `city_ibfk_1` FOREIGN KEY (`CountryCode`) REFERENCES `country` (`Code`)
) ENGINE=InnoDB AUTO_INCREMENT=4080 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
mysql> show create table countrylanguage\G
*************************** 1. row ***************************
Table: countrylanguage
Create Table: CREATE TABLE `countrylanguage` (
`CountryCode` char(3) NOT NULL DEFAULT '',
`Language` char(30) NOT NULL DEFAULT '',
`IsOfficial` enum('T','F') NOT NULL DEFAULT 'F',
`Percentage` float(4,1) NOT NULL DEFAULT '0.0',
PRIMARY KEY (`CountryCode`,`Language`),
KEY `CountryCode` (`CountryCode`),
CONSTRAINT `countryLanguage_ibfk_1` FOREIGN KEY (`CountryCode`) REFERENCES `country` (`Code`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
#执行计划1
mysql> desc select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000;
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | CountryCode | NULL | NULL | NULL | 4188 | 33.33 | Using where |
| 1 | SIMPLE | countrylanguage | NULL | ref | PRIMARY,CountryCode | CountryCode | 3 | world.city.CountryCode | 4 | 100.00 | Using index |
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
# 创建直方图
mysql> ANALYZE TABLE city UPDATE HISTOGRAM ON population WITH 1024 BUCKETS;
+------------+-----------+----------+-------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+------------+-----------+----------+-------------------------------------------------------+
| world.city | histogram | status | Histogram statistics created for column 'Population'. |
+------------+-----------+----------+-------------------------------------------------------+
1 row in set (0.02 sec)
#执行计划2
mysql> explain select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000;
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | ALL | CountryCode | NULL | NULL | NULL | 4188 | 0.06 | Using where |
| 1 | SIMPLE | countrylanguage | NULL | ref | PRIMARY,CountryCode | CountryCode | 3 | world.city.CountryCode | 4 | 100.00 | Using index |
+----+-------------+-----------------+------------+------+---------------------+-------------+---------+------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
#创建索引
mysql> create index index idx_population on city(population);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
#执行计划3
mysql> explain select city.name, countrylanguage.language from city join countrylanguage using(countrycode) where population>10000000;
+----+-------------+-----------------+------------+-------+----------------------------+----------------+---------+------------------------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+-------+----------------------------+----------------+---------+------------------------+------+----------+-----------------------+
| 1 | SIMPLE | city | NULL | range | CountryCode,idx_population | idx_population | 4 | NULL | 1 | 100.00 | Using index condition |
| 1 | SIMPLE | countrylanguage | NULL | ref | PRIMARY,CountryCode | CountryCode | 3 | world.city.CountryCode | 4 | 100.00 | Using index |
+----+-------------+-----------------+------------+-------+----------------------------+----------------+---------+------------------------+------+----------+-----------------------+
2 rows in set, 1 warning (0.00 sec)
说明:
从执行计划1和执行计划2可以看出,两个执行计划貌似没有很大的区别,但是可以注意到的是filtered列差距很大,没有直方图时为33.33,有直方图的情况下是0.06,因此对于行数语句会更加准确,在关联情况下可能会影响到驱动顺序(本案例中并没有体现)
对比执行计划2和执行计划3,可以看出,在有索引的情况下,优化器还是选择了索引,并没有使用直方图
结论
通常可以依靠索引的执行计划是最好的,但是直方图在某些情况下会有所帮助,例如对于非索引列特别有用
直方图并不像MySQL的索引一样会自动维护,必须通过手动去维护,另外如果真的需要使用直方图,不要滥用,务必控制好histogramgenerationmaxmemsize,并且建议业务低峰期进行统计。
通常来说直方图的适用场景是:
随时间变化不大的值
低基数值
分布不均
另外直方图无法使用的场景是:
加密表、临时表
JSON数据类型、空间数据类型
已创建唯一索引的单列
参考文章:
《Percona Server和MySQL 8.0上的列直方图》:
https://www.percona.com/blog/2019/10/29/column-histograms-on-percona-server-and-mysql-8-0/
