




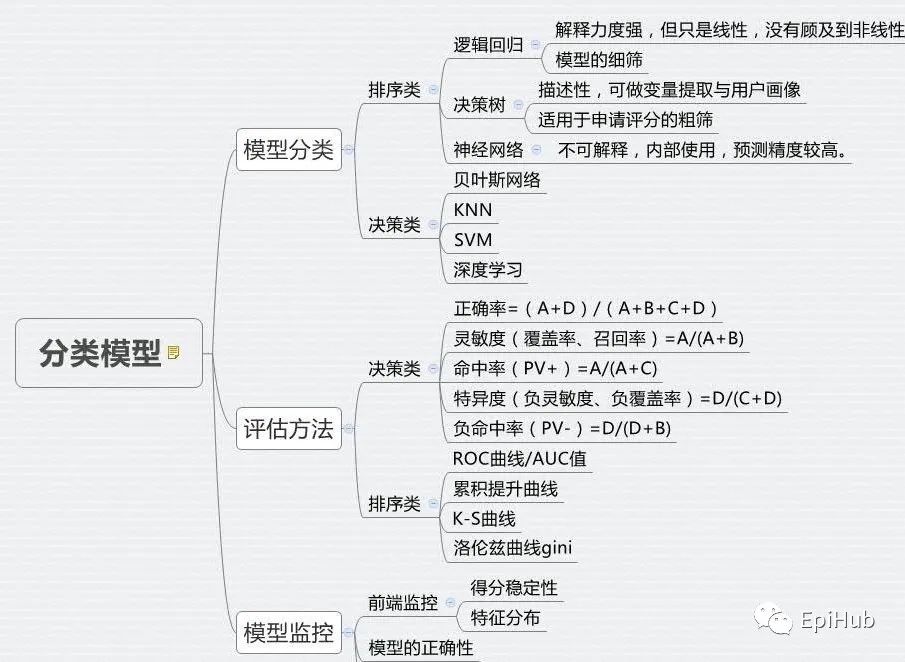
写在前面
不同模型基于的前提假设、算法、参数设置不同,预测结果存在不确定性。
在时间、内存允许的情况下,建议构建多个模型,进行“择优”、“集成”、“耦合”,使得预测行为更加谨慎、结果更加合理准确。
1 本节简介

2 模型解释
数据加载,处理;构建模型
library(breakDown)
library(DALEX)
library(CARET)
data(wine)
str(wine)
wine$quality <- factor(ifelse(wine$quality > 5, 1, 0)) #将quality转变为二分类
str(wine)
#to create train and test datasets
library(caret)
trainIndex <- createDataPartition(wine$quality,
p = 0.6, list = FALSE, times = 1)
wineTrain <- wine[ trainIndex,]
wineTest <- wine[-trainIndex,]
#随机森林RF、逻辑回归、支持向量机
classif_rf <- train(quality~., data = wineTrain,
method = "rf", ntree = 100, tuneLength = 1)#GLM中,当family = "binomial”,为逻辑回归classif_glm <- train(quality~., data = wineTrain,
method = "glm", family = "binomial")
classif_svm <- train(quality~., data = wineTrain,
method = "svmRadial", prob.model = TRUE, tuneLength = 1)
将观察到的类别和预测的概率之间的差异视为残差。
利用 predict 函数返回一个带有概率的数字向量。
p_fun <- function(object, newdata){predict(object, newdata=newdata, type="prob")[,2]}
yTest <- as.numeric(as.character(wineTest$quality))
explainer_classif_rf <- DALEX::explain(classif_rf, label = "rf",
data = wineTest, y = yTest,
predict_function = p_fun,
verbose = FALSE)
explainer_classif_glm <- DALEX::explain(classif_glm, label = "glm",
data = wineTest, y = yTest,
predict_function = p_fun,
verbose = FALSE)
explainer_classif_svm <- DALEX::explain(classif_svm, label = "svm",
data = wineTest, y = yTest,
predict_function = p_fun,
verbose = FALSE)
#3.1Model performance
#We use the generic plot() function to get a comparison of models.残差图
mp_classif_rf <- model_performance(explainer_classif_rf)
mp_classif_glm <- model_performance(explainer_classif_glm)
mp_classif_svm <- model_performance(explainer_classif_svm)
plot(mp_classif_rf, mp_classif_glm, mp_classif_svm)
#Setting the geom = "boxplot" parameter we can compare the distribution of residuals for selected models.
plot(mp_classif_rf, mp_classif_glm, mp_classif_svm, geom = "boxplot")
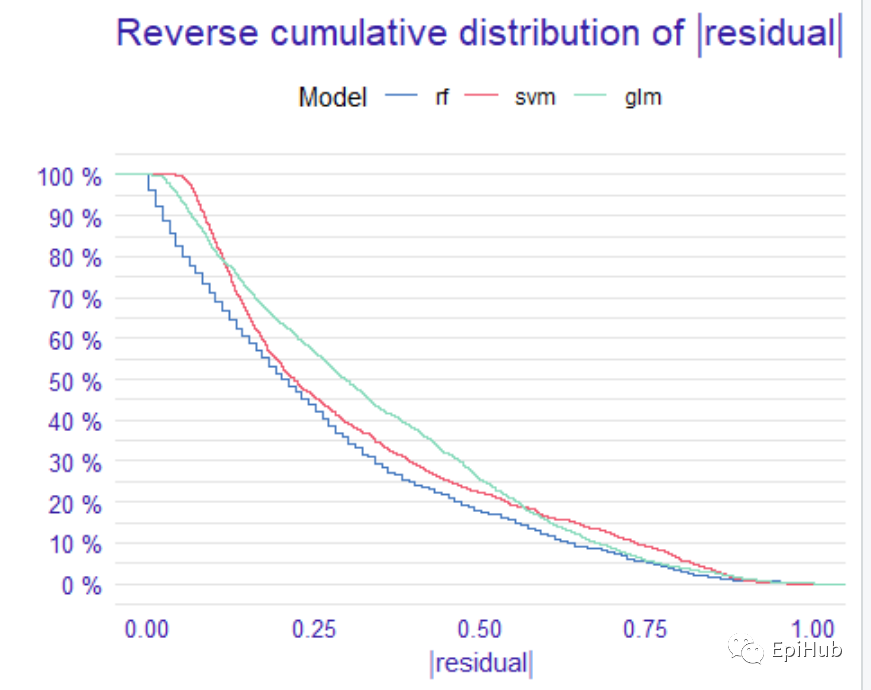
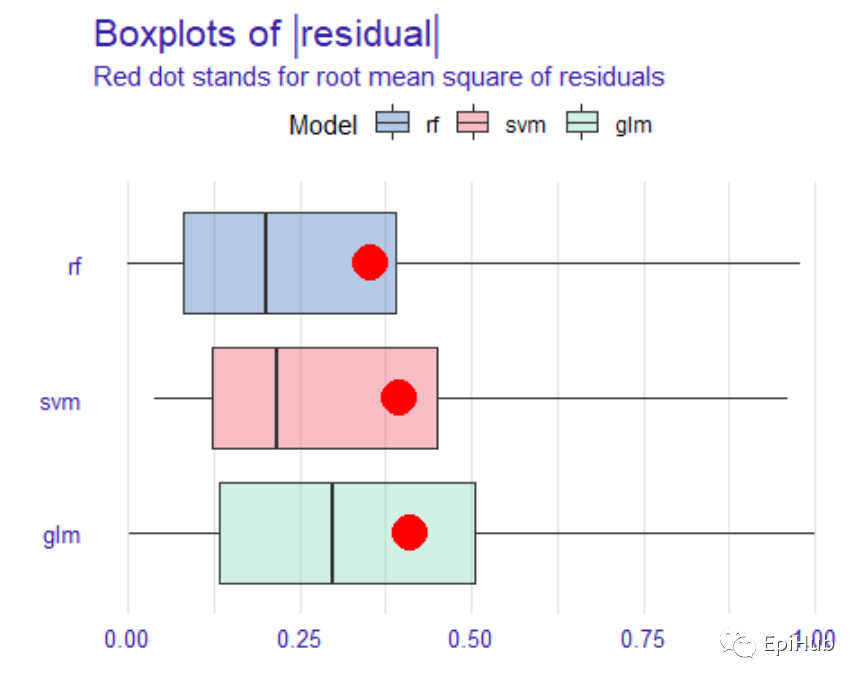
残差图:随机森林的模型性要优于支持向量机和逻辑回归模型
#3.2 Variable importance
#Function model_parts() computes variable importances which may be plotted.
vi_classif_rf <- model_parts(explainer_classif_rf, loss_function = loss_root_mean_square)
vi_classif_glm <- model_parts(explainer_classif_glm, loss_function = loss_root_mean_square)
vi_classif_svm <- model_parts(explainer_classif_svm, loss_function = loss_root_mean_square)
plot(vi_classif_rf, vi_classif_glm, vi_classif_svm)
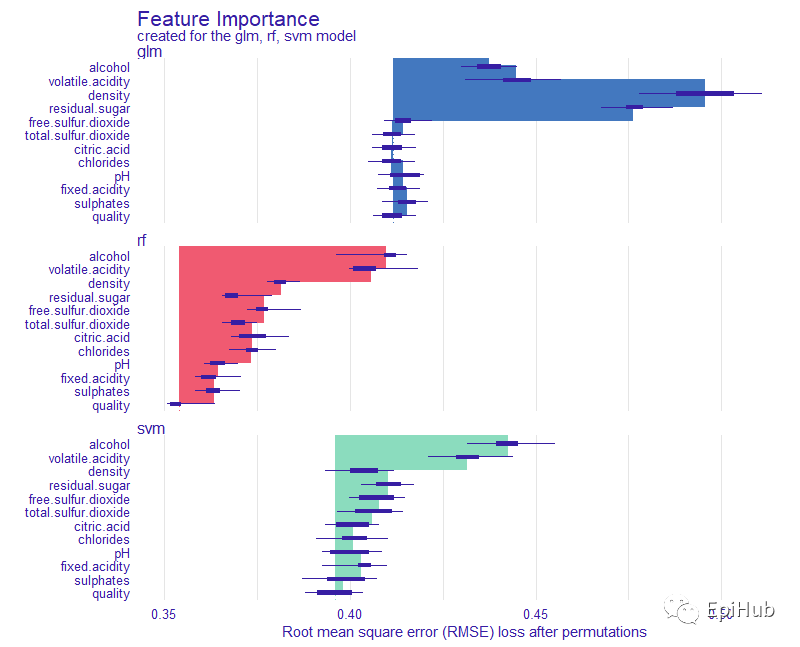
三种模型的变量重要性
随机森林:alcohol、volatile .acidity相对重要,对模型贡献大于其它变量。
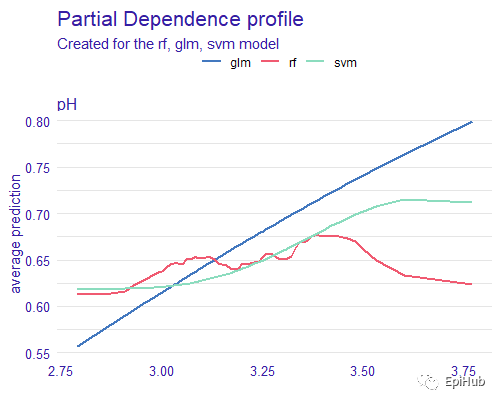
#3.2.1 Partial Depedence Plot局部依赖曲线
pdp_classif_rf <- model_profile(explainer_classif_rf, variable = "pH", type = "partial")
pdp_classif_glm <- model_profile(explainer_classif_glm, variable = "pH", type = "partial")
pdp_classif_svm <- model_profile(explainer_classif_svm, variable = "pH", type = "partial")
plot(pdp_classif_rf, pdp_classif_glm, pdp_classif_svm)
随机森林:随ph增加,质量提高;当ph达3.4时,随着ph增加,质量下降
支持向量机:随着ph增加,质量一直提高;当ph达3.6时,质量趋于稳定
逻辑回归:ph与质量呈相性关系,随ph增加,质量提高
#3.2.2 Acumulated Local Effects plot
ale_classif_rf <- model_profile(explainer_classif_rf, variable = "alcohol", type = "accumulated")
ale_classif_glm <- model_profile(explainer_classif_glm, variable = "alcohol", type = "accumulated")
ale_classif_svm <- model_profile(explainer_classif_svm, variable = "alcohol", type = "accumulated")
plot(ale_classif_rf, ale_classif_glm, ale_classif_svm)
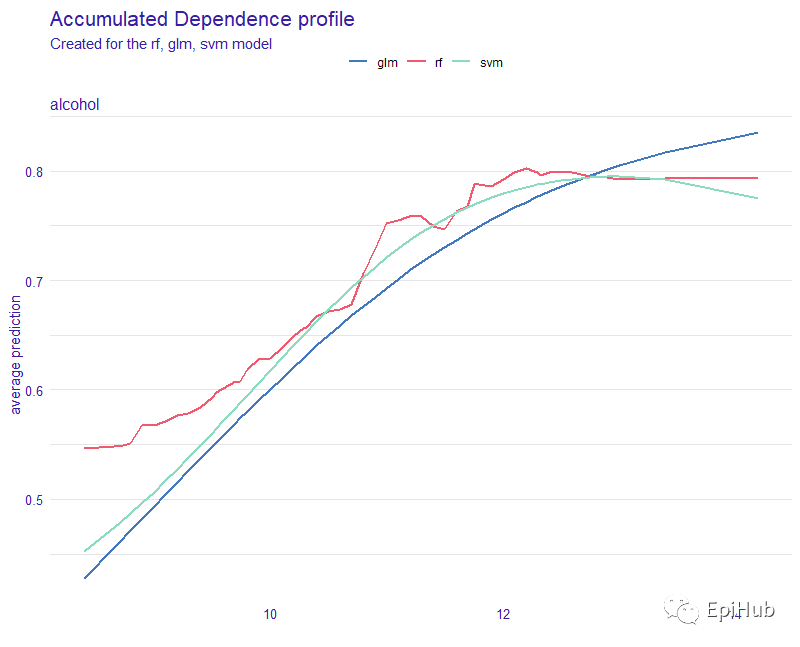 局部累积效应图(ALE)显示,随着alcohol的增加,预测概率在增加。
局部累积效应图(ALE)显示,随着alcohol的增加,预测概率在增加。
随机森林和支持向量机显示,当alcohol达13时,预测概率会趋于稳定。
关于本公众号推送的R语言和流行病学知识,请扫下方二维码,已整理成电子书的模式便于学习分享。

文章转载自EpiHub,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
