




√ 实时数据库同步,如 Oracle → Oracle, Oracle → MySQL, MySQL → MySQL 等
√ 数据入湖入仓,或者为现代数据平台供数,如:
△ 常规 ETL 任务(建宽表、数据清洗、脱敏等)
△ 为 Kafka/MQ/Bitsflow 供数或下推
具体场景则数不胜数,值此之际,我们将以系列文章形式,为大家盘点 Tapdata Cloud 可以支撑的业务场景和 3.0 版本新特性,以便大家更好在业务中应用 Tapdata。本期为系列文章第四弹,将以 MySQL → Doris 的数据同步任务为例,介绍 Tapdata Cloud 如何简化数据实时入湖入仓,让业务系统的数据变动稳定连续地实时复制到数据湖或数仓,为实时分析提供新鲜的原始数据。(点击文末「阅读原文」申请产品内测,抢先体验)
数据量走向爆炸的这些年,企业通过对业务数据的采集与分析使用,逐步将其转化为可用的信息和可操作的见解,反哺业务优化的方方面面。但如果直接从业务数据库中抽取数据进行分析,则往往需要面临结构复杂、数据脏乱、难以理解、缺少历史,以及大规模查询缓慢等实际操作问题。在这样的背景下,搭建面向分析需求的数据仓库也就成了非常常见的解决方案,并发展为数据整合及处理的核心。
Apache Doris:数据湖、仓场景下的核心优势
性能突出:依托列式存储引擎、现代的 MPP 架构、向量化查询引擎、预聚合物化视图、数据索引的实现,在低延迟和高吞吐查询上,都达到了极速性能
简单易用:部署只需两个进程,不依赖其他系统;在线集群扩缩容,自动副本修复;兼容 MySQL 协议,并且使用标准 SQL 统一数仓:单一系统,可以同时支持实时数据服务、交互数据分析和离线数据处理场景 联邦查询:支持对 Hive、Iceberg、Hudi 等数据湖和 MySQL、Elasticsearch 等数据库的联邦查询分析 多种导入:支持从 HDFS/S3 等批量拉取导入和 MySQL Binlog/Kafka 等流式拉取导入;支持通过 HTTP 接口进行微批量推送写入和 JDBC 中使用 Insert 实时推送写入
Tapdata Cloud:如何优化数据入湖入仓架构?
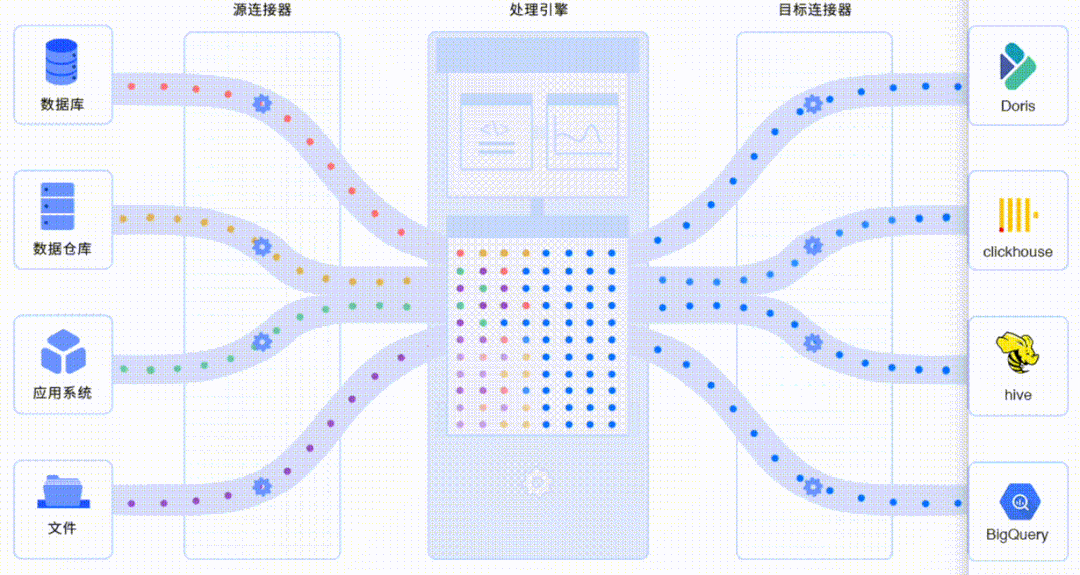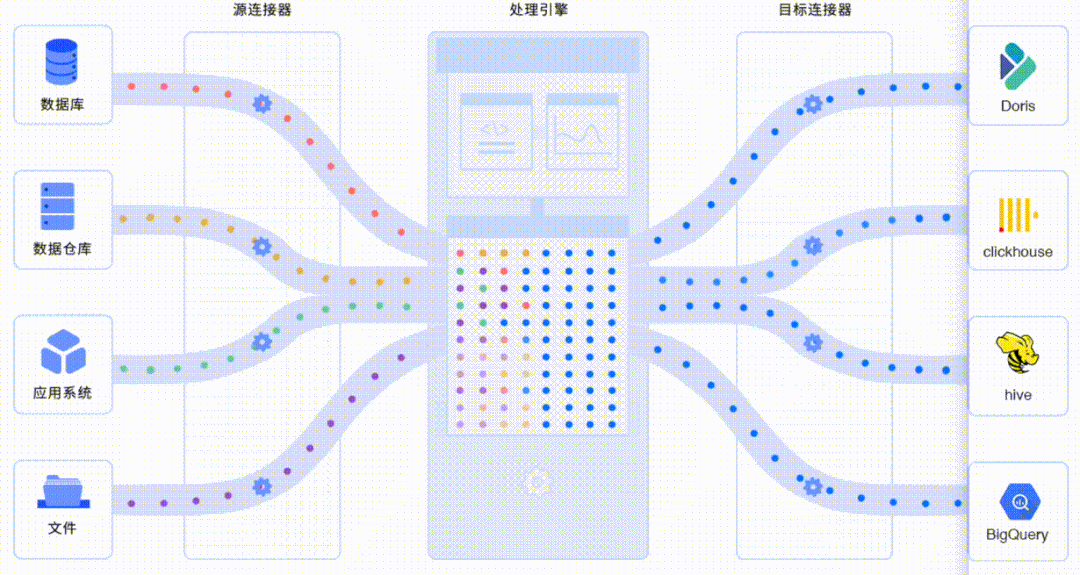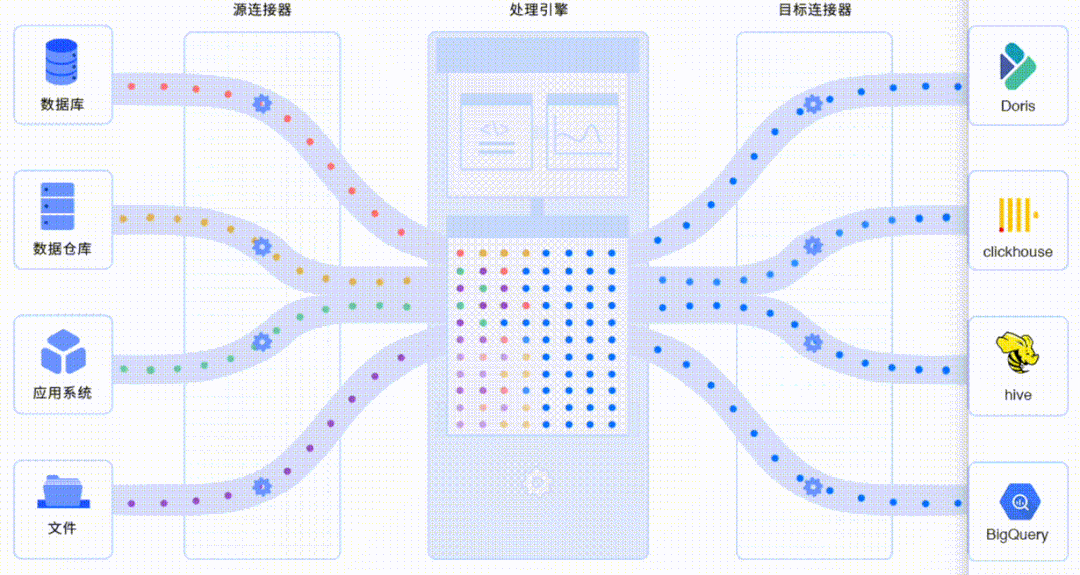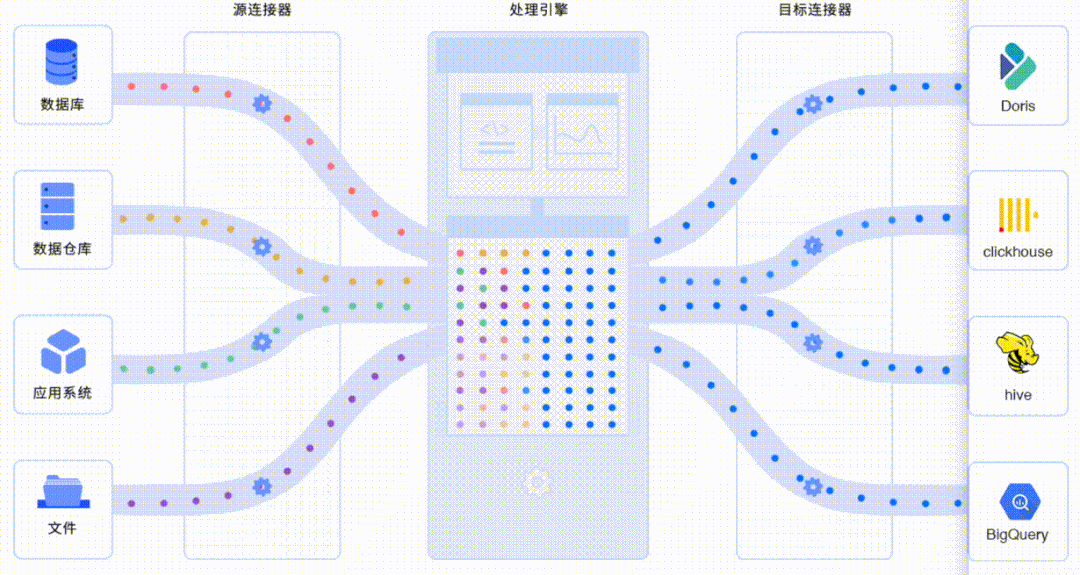
传统数据入湖入仓架构,一般存在全量、增量链路分离;链路长且复杂,维护困难;依赖离线调度分析,延时较大等缺陷。面对这些问题,作为一款开箱即用的实时数据服务,Tapdata Cloud 基于自身技术优势,为新一代数据入湖入仓架构提供了更具实践价值的解题思路——链路更短、延迟更低、更易维护和排查。(Tapdata Cloud 3.0 现已开放内测通道,点击文末「阅读原文」即可申请)
借助 Tapdata Cloud 全量增量一体的实时同步能力,可以实现极简的数据入湖入仓架构——读取源库的全量和增量数据,直接复制并更新入数据仓库。这一优化一方面极大降低了对源库的影响,保障了企业自身业务的稳定性;另一方,极大提升了数据交付速度,助力企业以连续的方式将业务系统的数据变动实时复制到数据湖或数仓,为实时分析提供新鲜的原始数据。在这个过程中,Tapdata 展现出的核心亮点包括:
全链路实时
对源库几乎无影响
可视化任务运行监控和告警
数据一致性保障
内置 50+ 数据连接器,稳定的实时采集和传输能力
操作演示:以 MySQL → Doris 为例
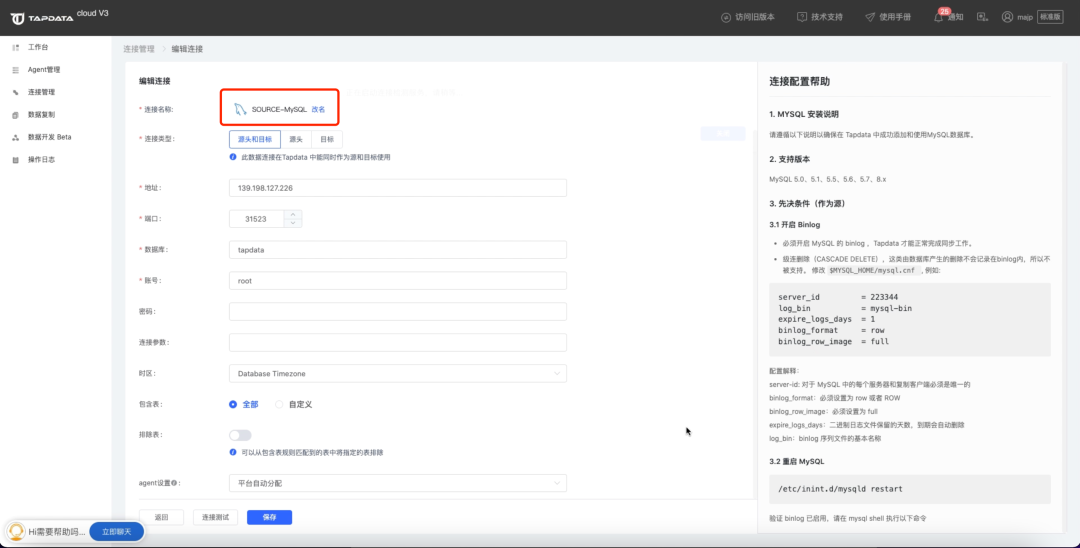
① 创建数据源 MySQL 的连接
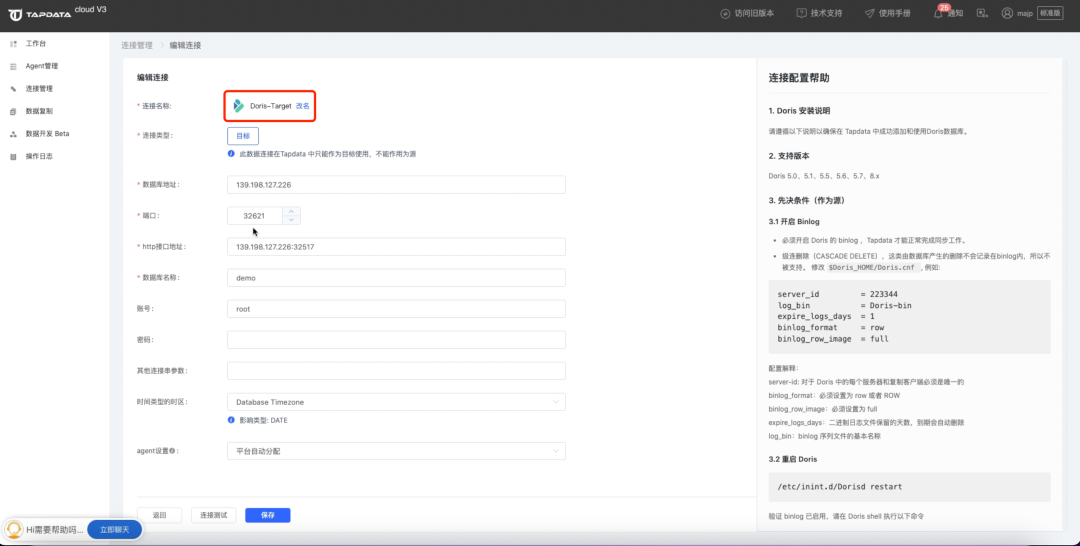
② 创建数据目标 Doris 的连接
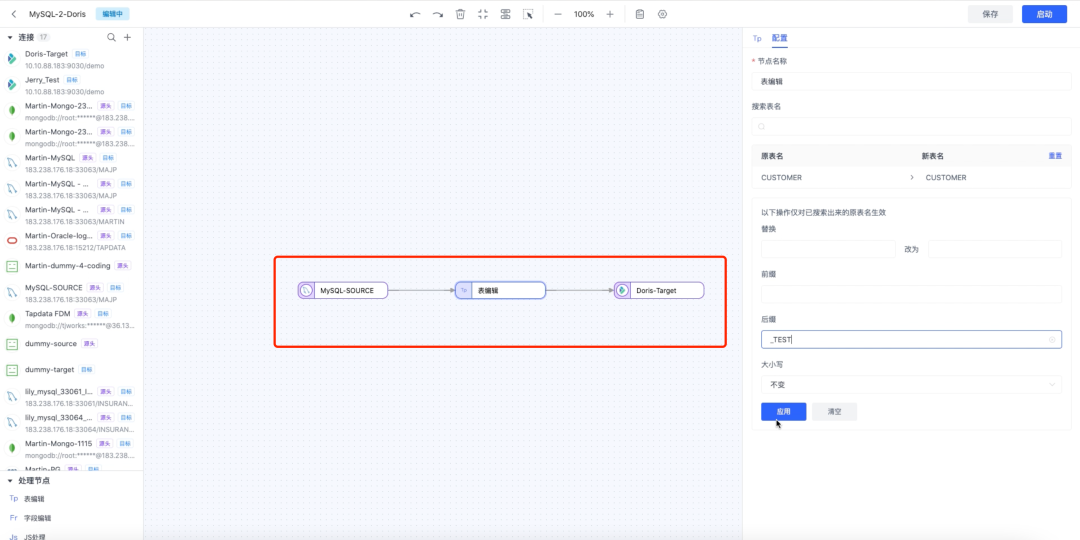
③ 创建数据复制任务
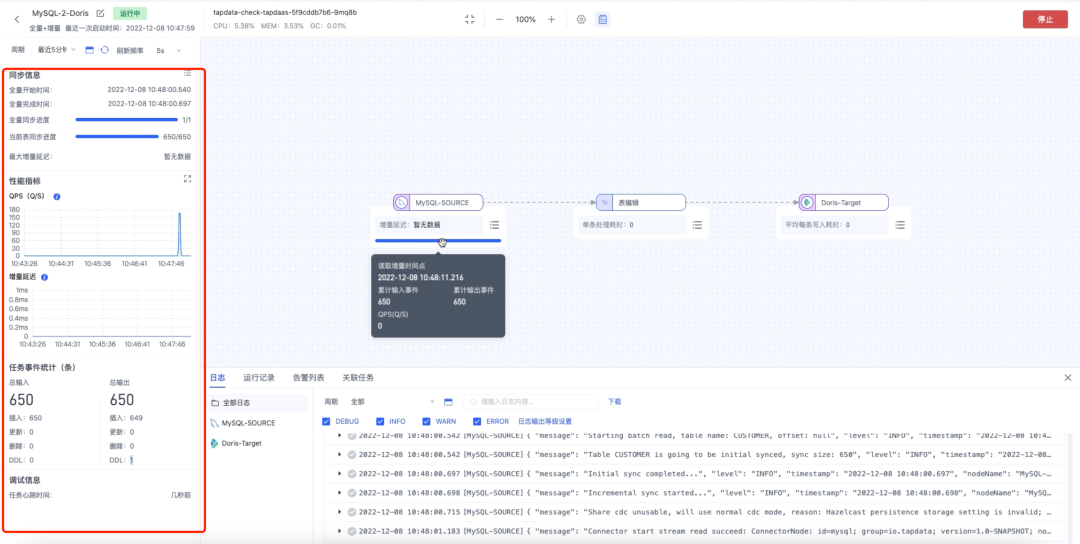
④ 任务监控
Tapdata Cloud 3.0:限量内测报名中
全新升级的 Tapdata Cloud 3.0 拥有更加全面的链路可观测性的可视化操作界面、增强的数据复制能力,以及数据开发 beta 等多重功能特性上新。
内测权益
将您的应用场景在最新的 Tapdata Cloud 上得到验证,帮助您解决切实的技术/业务痛点,您的内测反馈和宝贵建议,将第一时间在 Tapdata Cloud 上得到实现。
使用及技术支持:当您遇到使用问题或疑问时,将获得快速响应和支持。
专享订阅折扣:新版 Tapdata Cloud 将推出收费版本,用户可获得 SLA 级服务,保障生产使用的要求。内测用户将获得优惠订购特权。
成为产品共创贡献者:您将成为 Tapdata Cloud 产品的共创贡献者,内测提出的功能需求及优化建议,将有机会纳入产品路线图。

