




首先HOT ,heap only tuples 是Postgres 用户用于减少基于UPDATE 后的大量的IO 所做的工作,主要的问题就是在MVCC 导致的UPDATE 等于INSERT + 废弃行,以及新插入的行都需要对当前的索引负责。
相对于表本身需要VACUUM 和 AUTOVACUUM 的情况下,我们的其实需要更多的I/O 工作在针对这些操作针对索引的问题的IO消耗,因为索引需要修改指针到新的行。
Postgres 为了降低指针重新指向的问题,提出在一个行UPDATE后,就在原有的位置上插入他的新的版本的行,通过这样的方式让索引知道新的行就在老得行的下一个位置,避免大量的更新索引的操作,使用这样的方式就可以在索引上直接指向原来的位置的下一个位置。
而要完成这个事情,需要一个特殊的条件就是,更新的列不能是当前的索引列。
下面是经典的两个图 ,1 如果没有 HOT 的情况下 2 使用HOT 的情况
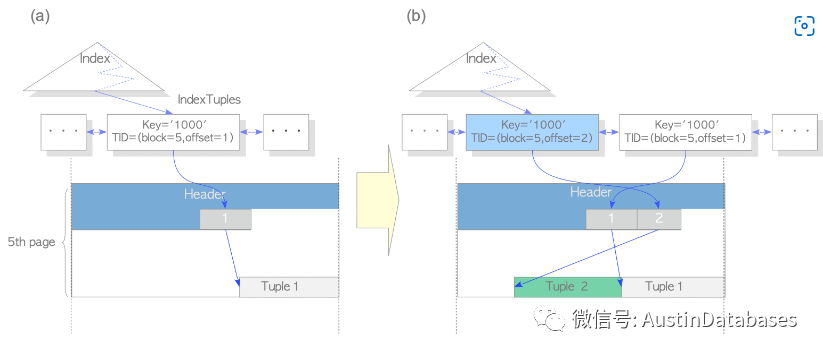
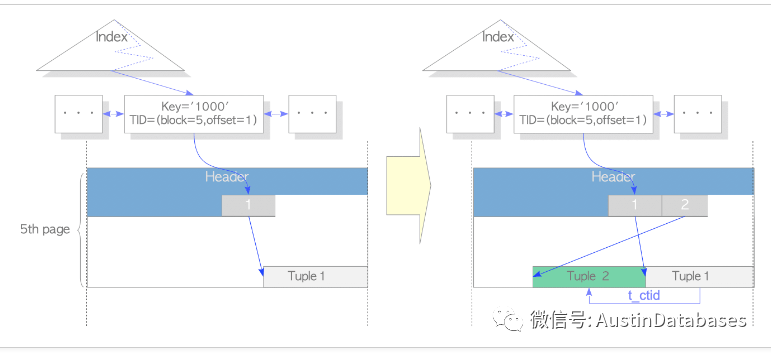
所以结论是POSTGRESQL 在频繁的UPDATE 当中,如果更新的字段是索引的情况下,将引发大量的索引更新,引起IO的消耗的情况。
在POSTGRESQL 有这样的问题的情况下,我们需要针对POSTGRESQL 的索引更加的小心和谨慎。
所以我们需要注意以下的问题
1 unused indexes 无用的索引
2 bloated indexes 膨胀的索引
3 Duplicate and invalid index 重复的索引
为什么会产生以上的这些问题呢
1 添加索引是在业务确认之前添加的,也就是添加索引并不是完全确认了业务的情况下进行的。
2 添加的索引针对的业务下线了
3 服务器的资源提升了,增加了,暂时不使用索引可以达到更好的
4 业务发展,后期添加的索引替代了早期的索引
5 操作失误,建立了同样的索引
那么针对以上的问题,我们需要
1 找到无用的索引
SELECT s.schemaname,
s.relname AS tablename,
s.indexrelname AS indexname,
pg_relation_size(s.indexrelid) AS index_size
FROM pg_catalog.pg_stat_user_indexes s
JOIN pg_catalog.pg_index i ON s.indexrelid = i.indexrelid
WHERE s.idx_scan = 0
AND 0 <>ALL (i.indkey)
AND NOT i.indisunique
AND NOT EXISTS
(SELECT 1 FROM pg_catalog.pg_constraint c
WHERE c.conindid = s.indexrelid)
ORDER BY pg_relation_size(s.indexrelid) DESC;
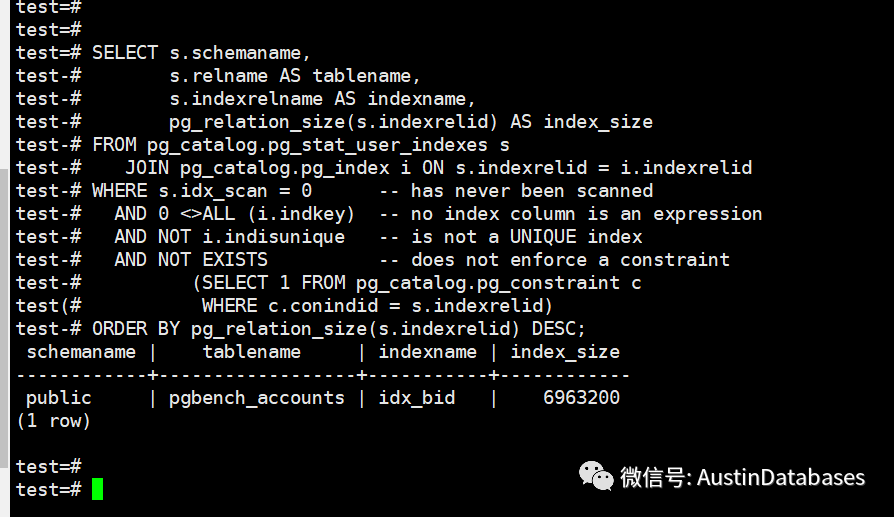
这里的无用的索引的问题,在通过语句找出相关得信息,只能作为一个借鉴的值,而不是一个可以完全借鉴的值。
得到这些信息,只能是还需要更多的分析,才能将这些索引清理掉。
2 索引的碎片率的问题,导致索引的性能的问题 ,基于POSTGRESQL MVCC 以及相关的问题,导致表膨胀,这样的情况下,也会导致索引碎片的问题,所以发现并重建索引是一个需要注意的问题。
create extension pgstattuple;
SELECT i.indexrelid::regclass,
s.leaf_fragmentation
FROM pg_index AS i
JOIN pg_class AS t ON i.indexrelid = t.oid
JOIN pg_opclass AS opc ON i.indclass[0] = opc.oid
JOIN pg_am ON opc.opcmethod = pg_am.oid
CROSS JOIN LATERAL pgstatindex(i.indexrelid) AS s
WHERE t.relkind = 'i'
AND pg_am.amname = 'btree' and s.leaf_fragmentation > 0 and s.leaf_fragmentation <> 'NaN';
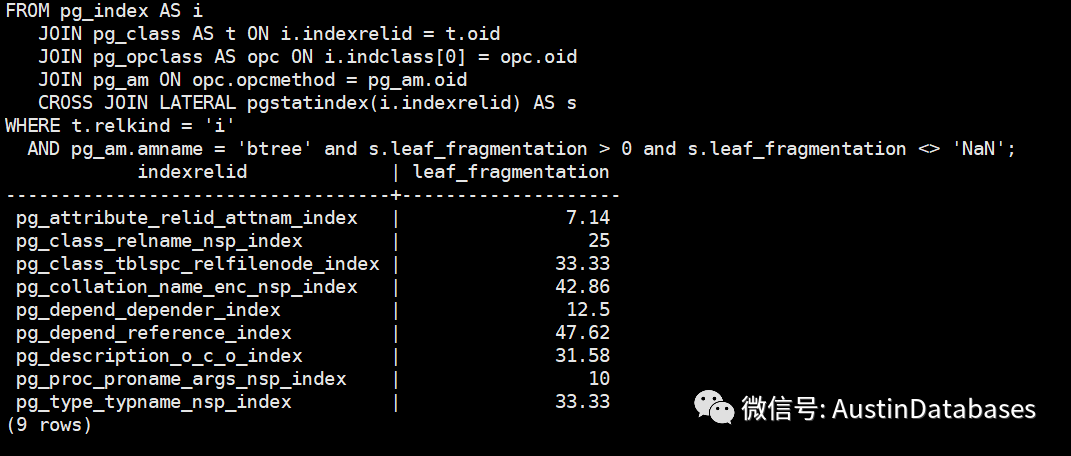
通过上面的语句去查询你索引的碎片率,通过这个来决定你的是否要进行索引的重建的工作。
3 重复索引的问题
基于上面的问题,索引不使用另外一种可能是有同类的索引,所以在发现索引不被使用的情况下,可以先看看是否有重复的索引的原因引起的,重复索引的害处可谓是“罄竹难书”
1 众所周知的重复索引,引起插入效率低
2 重复索引导致的数据量加大的问题
3 进行VACUUM AUTOVACUUM 多余的重复索引导致的操作时间和资源消耗过大的问题。
所以重复索引的问题一定要将多余的索引清理出去
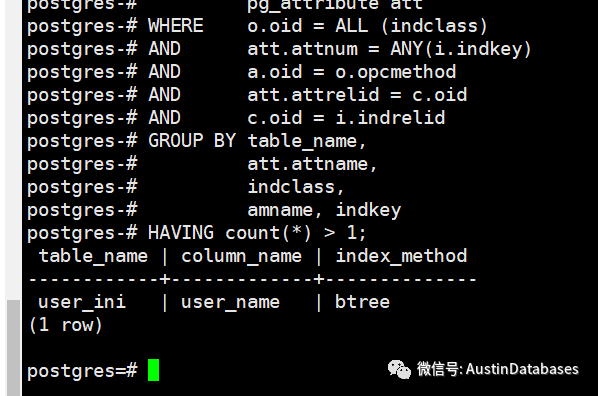
SELECT indrelid::regclass table_name,
att.attname column_name,
amname index_method
FROM pg_index i,
pg_class c,
pg_opclass o,
pg_am a,
pg_attribute att
WHERE o.oid = ALL (indclass)
AND att.attnum = ANY(i.indkey)
AND a.oid = o.opcmethod
AND att.attrelid = c.oid
AND c.oid = i.indrelid
GROUP BY table_name,
att.attname,
indclass,
amname, indkey
HAVING count(*) > 1;
SELECT indrelid::regclass AS TableName ,array_agg(indexrelid::regclass) AS Indexes
FROM pg_index
GROUP BY indrelid ,indkey
HAVING COUNT(*) > 1;
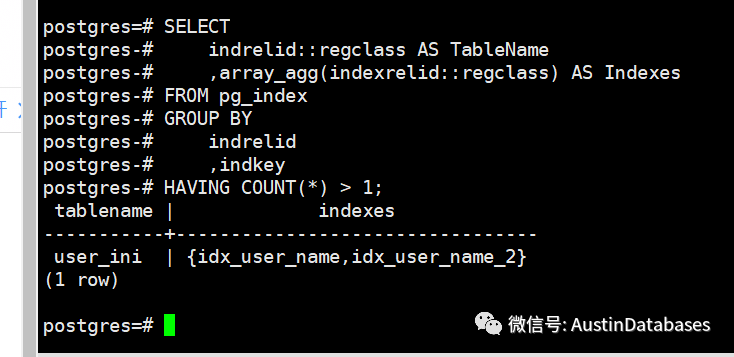
通过上面的语句来查看当前的数据库中是否有重复的索引。
除此以外,我们还可以针对索引做如下的一些工作
1 在Postgresql 中创建针对索引的表空间,数据和索引进行分离,而不要将索引和数据创建在一个数据文件内。
postgres=# create tablespace index_storage location '/pgdata/index';
CREATE TABLESPACE
postgres=# create index idx_user_name on user_ini(user_name) tablespace index_storage;
CREATE INDEX
postgres=#

2 针对当前的索引进行查询和分析
1 针对当前有多少索引进行信息的获取
SELECT CONCAT(n.nspname,'.', c.relname) AS table,i.relname AS index_name,x.indisunique as is_unique FROM pg_class c
INNER JOIN pg_index x ON c.oid = x.indrelid
INNER JOIN pg_class i ON i.oid = x.indexrelid LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = ANY (ARRAY['r', 't']) and c.relname not like 'pg%';
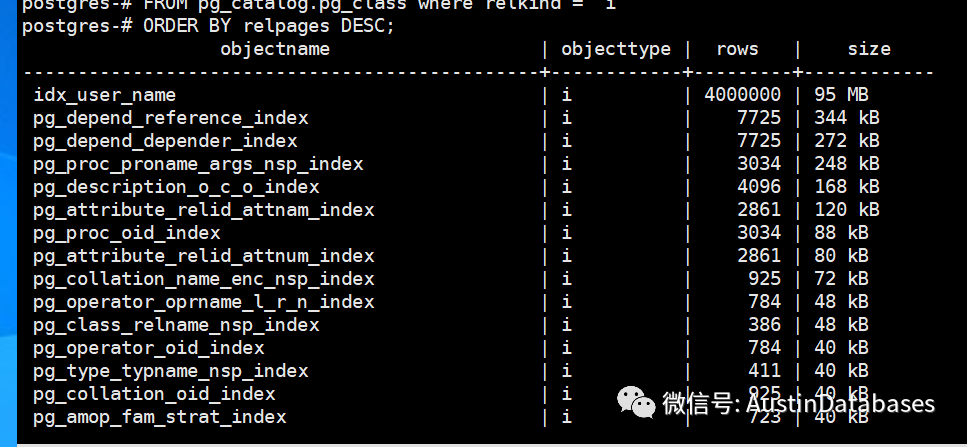
2 这对当前的索引的大小进行分析
SELECT
relname AS objectname,
relkind AS objecttype,
reltuples :: bigint AS "rows",
pg_size_pretty(relpages::bigint*8*1024) AS size
FROM pg_catalog.pg_class where relkind = 'i'
ORDER BY relpages DESC;
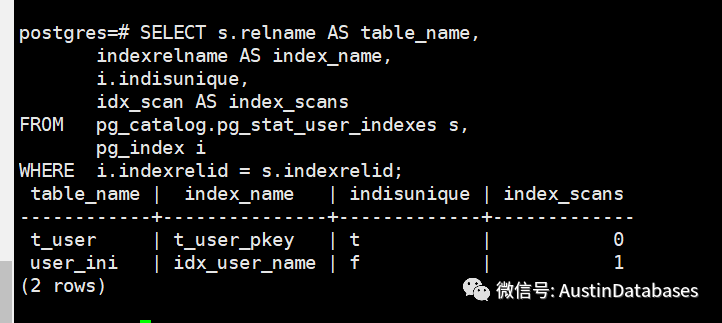
3 针对索引使用的次数进行统计,如每天索引被使用多少次,如果索引组最近一段时间使用的频次明显比之前要少,或者根本就不使用了,就需要分析有没有可能是因为索引损坏造成的问题。
SELECT s.relname AS table_name,
indexrelname AS index_name,
i.indisunique,
idx_scan AS index_scans
FROM pg_catalog.pg_stat_user_indexes s,
pg_index i
WHERE i.indexrelid = s.indexrelid;
另外,在索引的工作中,还有一些问题基于索引的损坏导致的问题,会发现如下的一些问题
1 本来有索引但是在查询中不走索引而是走全表扫描
2 通过 pg_stat_user_tables 表中的 seq_scan 和 idx_scan 两个字段的数值的对比来发现问题,如 seq_scan 疯狂的增加数字,而idx_scan 里面不增长或增长很慢,(1 是否有对应的索引 2 索引是否损坏)
3 在查询中出现错误的数据,如查询范围的明显标定的很清楚,但是查询的数据突破了这个范围,也就是查询的值不对。
以上的方式也可能是其他问题造成的,如数据库表的analyze 操作不及时,导致统计分析的数据出现偏差造成的。
基于以上的一些内容,索引的维护和信息的收集,以及问题的发现对于索引的维护是非常重要的。
