





你可以向左转也可以朝前走
但你不能停留
—— 万晓利

Hello,真的是......好久不见!
《因果推断之Uplift Model》这个系列目前已经发了两篇文章。《入门篇》介绍了uplift模型是如何预测用户的“营销敏感度”的以及几种主流的建模方式。《Pylift实战篇》演示了用Pylift库搭建uplift模型的全流程,其中提到Pylift库拓展性较差、官方文档描述不清晰等问题。
本文将介绍另一个可用于搭建uplift模型的python包,CausalML,包括算法原理、安装方法和建模示例三部分。相比Pylift,它支持更丰富的建模方法,重视模型的可解释性,官方文档可读性更强。
建模部分是使用CausalML自带的函数来生成数据,与真实数据的训练效果会有差异,没有太强的可解释性,重在说明用法。
欢迎探讨指正!>.<
01
Methodology
/ 原理篇
S-Learner & T-Learner:对应我们在入门篇中提到的一段式(Single-Model)和两段式(Two-Model)差分响应模型,即不直接对uplift建模,而是用响应模型预测客户在营销/不营销下的响应率,相减得到ITE。
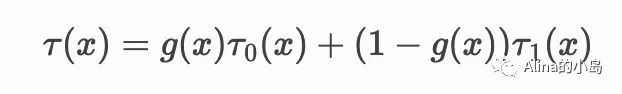
这样处理的原因是,如果 g(x) 很小(客户被营销的可能性低),则 τ^1 的权重更大,即更倾向于control组数据训练的模型。
一个形象的说法是,X-Learner就像它的名字一样,是个交叉的X:用treatment组模型去计算control组的增益,用control组模型去计算treatment组的增益,加入“倾向性得分”参数,解决了组间数量差异大时T-Learner表现不佳的问题。
R-Learner是通过将问题转化为定义损失函数的形式进行学习训练,利用了学习残差的思想。具体原理文档中写的比较复杂,我没看明白就不多解释了:-) 感兴趣的朋友可以去看看文档,后面会做用法的演示。
2. Tree-Based Method 基于树的方法
由于我们无法获得每个样本实际的uplift值,无法形成以uplift值为标准的类内相似而类间不同的模型输出,因此决策树的特征选择与分裂过程无法复用传统的熵增益、基尼系数等评价指标。以下是几种改造后的分裂标准:
DDP:非常简单易懂的一种分裂标准:衡量分裂后两个叶子结点的CATE的差值。第一步先计算叶子结点内实验组和控制组的响应率差值,第二步计算左右结点响应率差值的差值。因此非常形象称作DDP,delta-delta-p (ΔΔP)。
Divergence Gain:我们可以将实验组和控制组看作两个关于outcome的概率分布,用D表示这两个概率分布的差异,如果分裂后D增大,说明此次分裂能体现出treatment对于outcome的影响,所以每一次分裂都会选择使分裂前后D的增益最大的特征与阈值,D的增益写成公式如下:
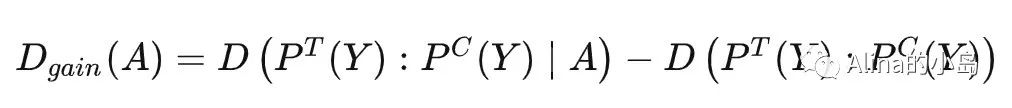
度量两个概率分布的差异主要有以下三种方式(p为实验组,q为控制组):
基于KL散度
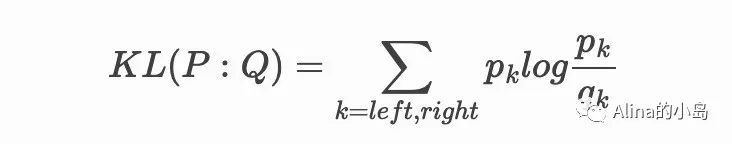
基于欧几里德距离
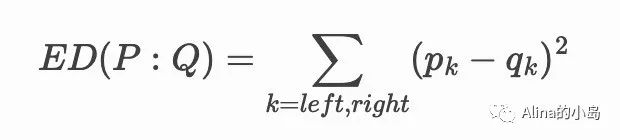
基于卡方检验
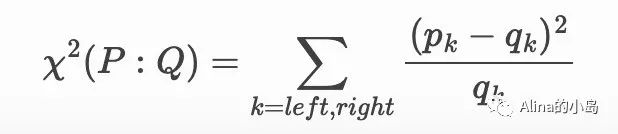
CTS:全称Contextual Treatment Selection,从名字可以看出,这种方法可用于多treatment的问题。
我们知道在二分类中,模型输出一个类别的置信度得分即可反映分类结果,但在多分类问题中则需要输出所有类别的置信度分数;类比到uplift问题中,两种treatment问题中利用treatment与control组的输出期望差值反应增益效果,而多treatment场景下每两个treatment的输出期望之间可求差值得到相应的uplift score。
因此CTS在进行树的分裂时将按照如下公式计算分裂增益:
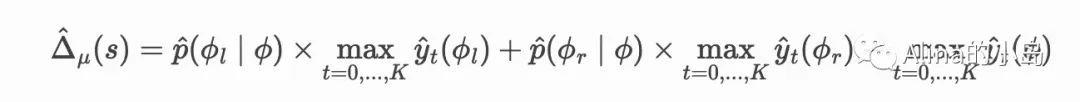
其中φ代表树结点,t代表treatment类型。CTS计算分裂后子结点中不同treatment下输出期望的最大值加权和与父结点对应指的差值,并以此作为分裂标准,希望分裂所得的两个结点中都存在对某种treatment较为敏感的人群。
CTS的测试阶段将根据测试样本落在的叶子结点,返回该结点上各treatment下的输出期望,以提供treatmet选择的依据,若存在多棵树组合的结构(如随机森林、gbdt等),则将多棵树的结果取均值得到最终结果。
02
Installation
/ 安装篇
官方文档上列举的安装方式有以下三种:
✔使用pip安装:pip安装依赖git工具获取源码,以获得前置依赖库列表,随后再安装causalml本体。
git clone https://github.com/uber/causalml.gitcd causalmlpip install -r requirements.txtpip install causalml
✔使用conda安装:conda安装依赖官方提供的anaconda虚拟环境打包文件(yml文件),需要利用anaconda在本地新建python环境,在通过文件新建的方式采用对应python版本的yml文件,搭建包含CausalML本体库的虚拟环境。
git clone https://github.com/uber/causalml.gitcd causalml/envs/conda env create -f environment-py38.yml # for the virtual environment with Python 3.8 and CausalMLconda activate causalml-py38
✔源码安装:源码安装方式必须通过git拉取源代码,并利用setup文件进行本地安装。
git clone https://github.com/uber/causalml.gitcd causalmlpip install -r requirements.txtpython setup.py build_ext --inplacepython setup.py install
我在按照上述方法安装的时候频频报错,查了一下发现是比较共性的问题,所以再啰嗦两句给大家参考。
我在Mac系统中进行安装,首先尝试了pip,遇到报错 setup.py: egg_info did not run successfull,该问题可能由pip等安装工具版本过低等问题引起,但尝试更新后仍不能解决,因此尝试了conda安装方式。这种方式需要依赖官方提供的anaconda打包环境文件,安装过程中没有报错提示,但在程序内import时报错dlopen() : Library not loade。解决方法是需要安装外部动态链接库,仔细看报错提示,按照提示的方法安装其所需的dll动态连接库后问题得到解决。
总而言之,CausalML库的安装过程相比于传统python库较为复杂,主要原因可能是使用了大量非python环境的工具,例如CausalML中的模型大量使用了C/C++编译的dll文件,并且依赖Visual C++工具。
对此,个人比较推荐在Linux系的系统中使用conda方式进行安装,可以利用官方提供的yml文件将CausalML及所需环境依赖项部署到anaconda虚拟环境中,Linux系统本身提供了较为完善的下载与软件版本管理工具,可以方便地下载所需的其他依赖文件;配置好环境后,在每次需要执行CausalML相关的程序前,都需要通过anaconda的activate指令激活环境。
03
Modeling
/ 建模篇
import pandas as pdimport numpy as npfrom matplotlib import pyplot as pltfrom sklearn.model_selection import train_test_splitfrom xgboost import XGBRegressorfrom causalml.inference.meta import XGBTRegressorfrom causalml.inference.meta import BaseSLearner, BaseTLearner, BaseRLearner, BaseXLearnerfrom causalml.inference.tree import UpliftRandomForestClassifierfrom causalml.dataset import *from causalml.metrics import *
STEP1 数据生成(如有数据可忽略)
与pylift相似,CausalML也提供了数据生成功能。synthetic_data是针对回归任务的数据生成接口,提供了五种不同的数据生成模式,对应不同类型的分布,输出是tuple格式的数据集。make_uplift_classification是针对分类任务的数据生成接口,输出是DataFrame格式的数据集和一个特征名列表。
# 使用synthetic_data生成数据# 默认Treatment是0/1y, X, treatment,_,_,e = synthetic_data(mode=1, n=10000, p=8, sigma=1.0)y, X, treatment,e

# 使用make_uplift_classification生成数据# 默认treatment是'control','treatment1','treatment2','treatment3'df, x_names = make_uplift_classification(n_samples=100000, treatment_name=[0,1], n_classification_features=10)df
假设现在的场景是一个分类问题,例如针对广告点击转化的用户营销增益预测,Outcome是1-转化或0-未转化,且treatment只有0/1两种情况,我们使用上述第二种方法生成的数据进行后续训练。
STEP2 模型训练
CausalML的数据准备与模型训练过程基本继承自sklearn架构,在得到带有label的原始数据后通过train_test_split进行训练集与验证集划分,其模型架构也与sklearn类似。下面将分别使用Meta-Learner中的S、T、R、X Learner和uplift tree在训练集上进行训练,并在测试集上预测。
2.1 Train with Meta-Learner
CausalML提供两种调用方式:
一是通过调用一个基础学习器Base-Learner,并提供一个sklearn/xgboost回归器类作为输入;
二是直接使用包里一些集成好的学习器,例如直接调用LRSRegressor,等于调用BaseSLearner,并使Learner = LinearRegressor,如下所示:
# S Learnerlearner_s = BaseSLearner(learner=XGBRegressor())learner_s.fit(X=df_train[x_names].values,treatment=df_train['treatment_group_key'].values,y=df_train['conversion'].values)cate_s = learner_s.predict(df_test[x_names].values)# T Learnerlearner_t = BaseTLearner(learner=XGBRegressor())learner_t.fit(X=df_train[x_names].values,treatment=df_train['treatment_group_key'].values,y=df_train['conversion'].values)cate_t = learner_t.predict(df_test[x_names].values)# X Learnerlearner_x = BaseXLearner(learner=XGBRegressor())cate_x = learner_x.fit(X=df_train[x_names].values,treatment=df_train['treatment_group_key'].values,y=df_train['conversion'].values)cate_x = learner_x.predict(df_test[x_names].values)# R Learnerlearner_r = BaseRLearner(learner=XGBRegressor())cate_r = learner_r.fit(X=df_train[x_names].values,treatment=df_train['treatment_group_key'].values,y=df_train['conversion'].values)cate_r = learner_r.predict(df_test[x_names].values)
2.2 Train with Tree-Based Method
Causal ML里有 DescisionTree、UpliftTreeClassifier、UpliftRandomForest-Classifier、UpliftTreeRegressor、UpliftRandomForestRegressor等接口可以使用,n_estimators, max_depth, normalization等参数的设定方式与sklearn中树模型类似,evaluationFunction参数可以设置成上文提到的KL、ED、Chi、CTS、DDP等。
# Random Forest Classifieruplift_model = UpliftRandomForestClassifier(control_name='control', n_estimators=69, max_depth=5, evaluationFunction='KL')uplift_model.fit(X=df_train[x_names].values,treatment=df_train['treatment_group_key'].map({0:"control", 1:"treatment"}).values,y=df_train['conversion'].values)cate_rf = uplift_model.predict(df_test[x_names].values, full_output=False)
2.3 Visualize Predictions
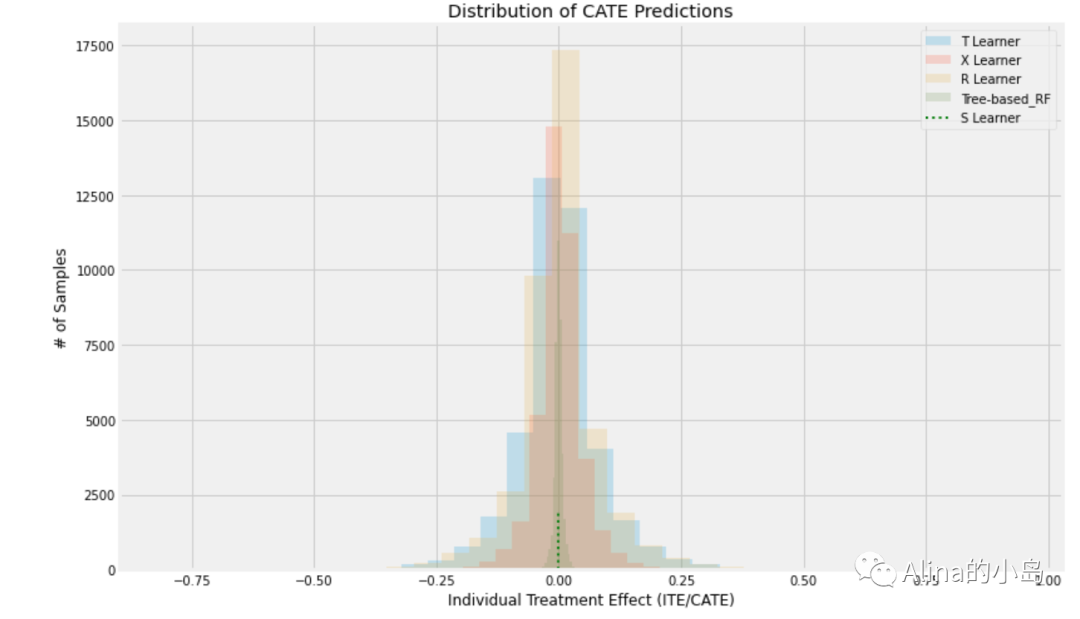
可以对不同预测结果进行可视化,便于观察数据分布差异。
alpha=0.2bins=30plt.figure(figsize=(12,8))# plt.hist(cate_s, alpha=alpha, bins=bins, label='S Learner')plt.hist(cate_t, alpha=alpha, bins=bins, label='T Learner')plt.hist(cate_x, alpha=alpha, bins=bins, label='X Learner')plt.hist(cate_r, alpha=alpha, bins=bins, label='R Learner')plt.hist(cate_rf, alpha=alpha, bins=bins, label='Tree-based_RF')plt.vlines(cate_s[0], 0, 1950, label='S Learner', linestyles='dotted', colors='green', linewidth=2)plt.title('Distribution of CATE Predictions')plt.xlabel('Individual Treatment Effect (ITE/CATE)')plt.ylabel('# of Samples')_=plt.legend()
将样本按照模型评分降序排序后分成n组,可以计算每一组的增益和前n组的累积增益,描绘出累计增益曲线,即uplift curve。该曲线表现出模型的预测能力,通常来说曲线下面积越大,模型效果越好。除此以外,还可以通过累积增益提升度、基尼系数、基尼曲线下面积等指标评估模型效果。以下为上述各类评估指标的计算及可视化实现方式。
# 计算前t个样本的累计增益get_cumgain(df, outcome_col='y', treatment_col='treatment',normalize=False, random_seed=42)# 可视化前t个样本的累计增益,即 Uplift Curveplot_gain(df, outcome_col='y', treatment_col='treatment', normalize=False, random_seed=10, n=100, figsize=(8, 8))# 计算AUUC,即Uplift Curve下面积auuc_score(df, outcome_col='y', treatment_col='treatment', normalize=True, tmle=False)# cate_rf_pred 0.317780# cate_s_pred 0.470058# cate_r_pred 0.811364# cate_x_pred 0.812155# cate_t_pred 0.622380# Random 0.494298# 计算前t个样本的累计增益提升度、可视化get_cumlift(df, outcome_col='y', treatment_col='treatment',random_seed=42)plot_lift(df, outcome_col='y', treatment_col='treatment', random_seed=42, n=100, figsize=(8, 8))# 计算前t个样本的基尼系数、可视化causalml.metrics.get_qini(df, outcome_col='y', treatment_col='treatment', normalize=False, random_seed=42)causalml.metrics.plot_qini(df, outcome_col='y', treatment_col='treatment', normalize=False, random_seed=42, n=100, figsize=(8, 8))
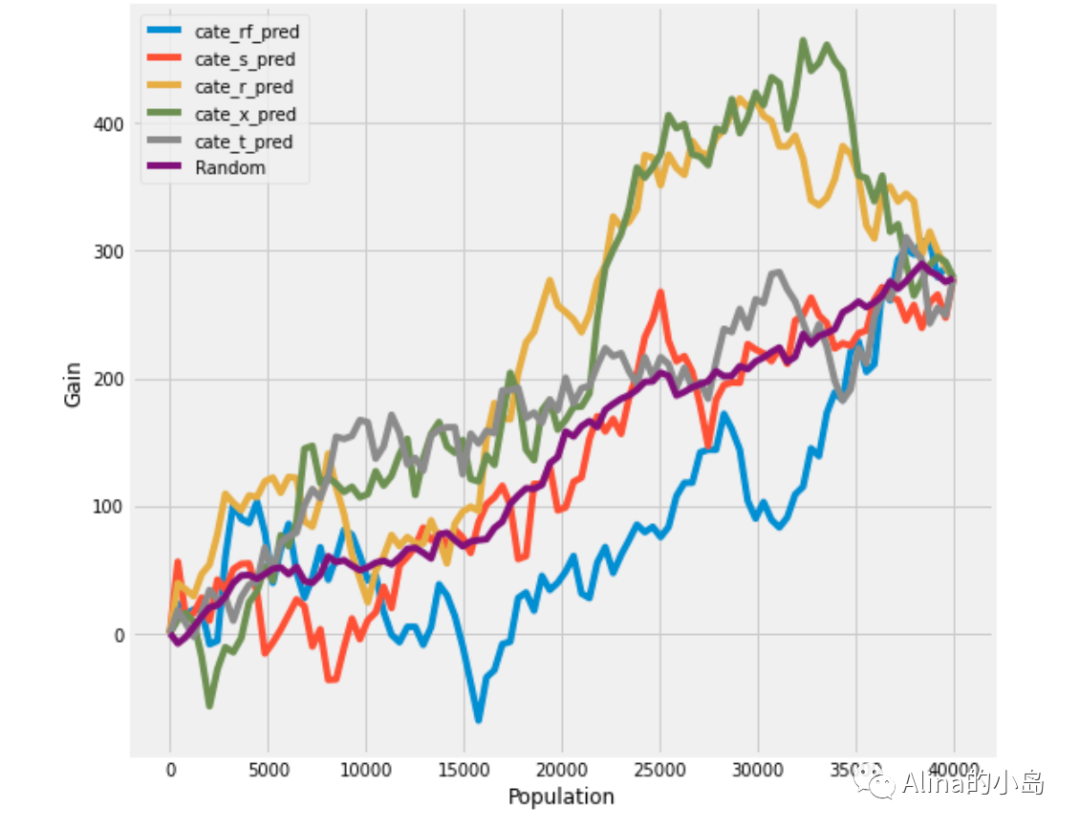
累积增益曲线, Uplift Curve
上方的每条曲线表示按照该模型预测的uplift score降序排序后,前t组的累积增量效果。random表示随机排序时的累积增益效果。每条曲线最终相交的位置表示全量营销时的平均增量效果。
这组模型的uplift curve普通波动比较大,尤其在前1/3的排序能力不是非常理想(理想情况是一个先增后降的拱形曲线)。其中,Xlearner的AUUC为0.81,预测效果最好。若基于Xlearner的预测结果做筛选,可以取累积增益最高点,即前32000人进行营销。
STEP4 模型可解释性
4.1 Meta-Learner特征重要性
CausalML的Meta-Learner接口中包含多种计算特征重要性的方法,如下所示:
# Using the feature_importances_ method in the base learner# method = auto (calculates importance based on estimator’s default implementation of feature importance;learner_x.plot_importance(X=df_test[x_names].values, tau=cate_x, normalize=True, method='auto')# Using the feature_importances_ method in the base learner# method = permutation (calculates importance based on mean decrease in accuracy when a feature column is permuted;learner_x.plot_importance(X=df_test[x_names].values, tau=cate_x, normalize=True, method='permutation')# Using SHAPlearner_x.plot_shap_values(X=df_test[x_names].values, tau=cate_x)
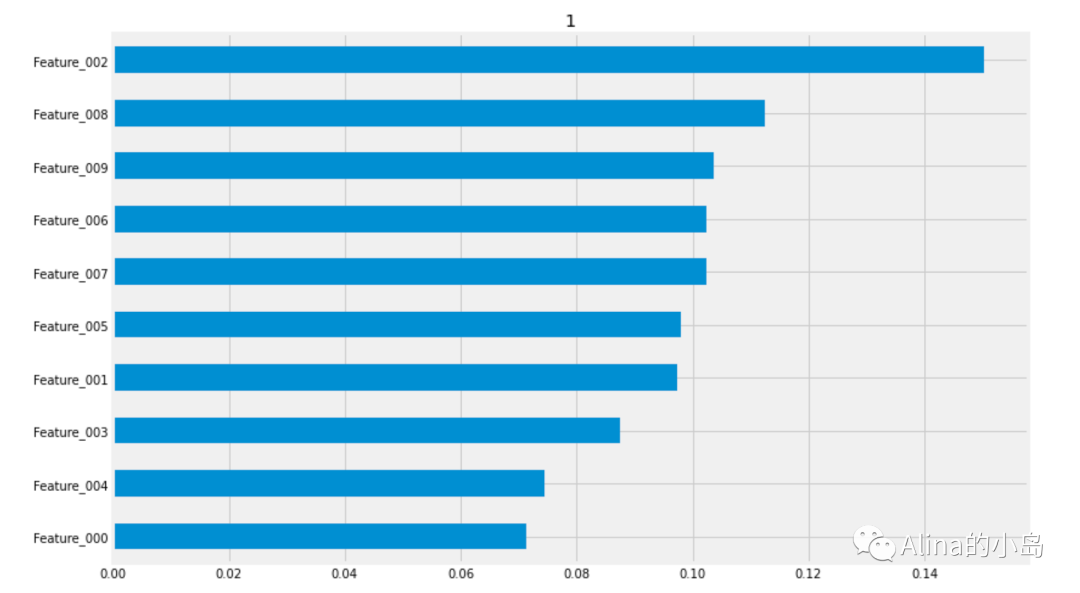
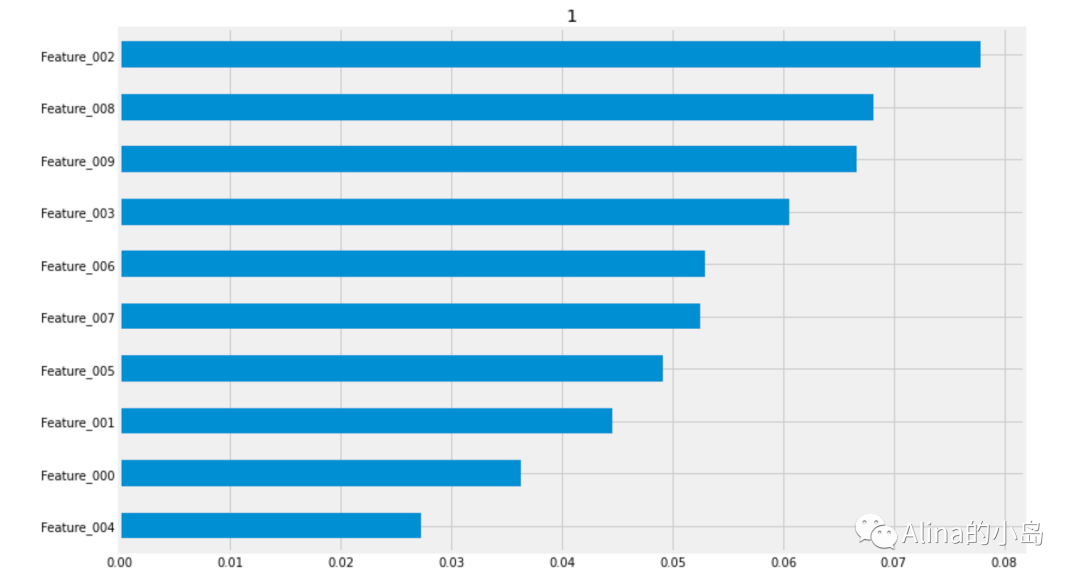

左滑依次查看输出结果
4.2 Uplift Tree特征重要性
与传统树模型类似,Uplift Tree也可以使用weight,gain,cover等指标来判断特征的重要性,不过我在CausalML中没有找到集成这些指标的接口。
官方Example中是使用uplift_tree_plot函数可视化树模型,我在运行该函数时显示的fitted_uplift_tree不存在,目前的文档中也没有这个接口的说明。不确定是不是版本更新后删掉了。 Anyway,这部分也没找到别的可用的接口,还是放出来给大家参考一下吧。如下所示:
from IPython.display import Imagefrom causalml.inference.tree import uplift_tree_string, uplift_tree_plotgraph = uplift_tree_plot(uplift_model.fitted_uplift_tree,x_names)Image(graph.create_png())
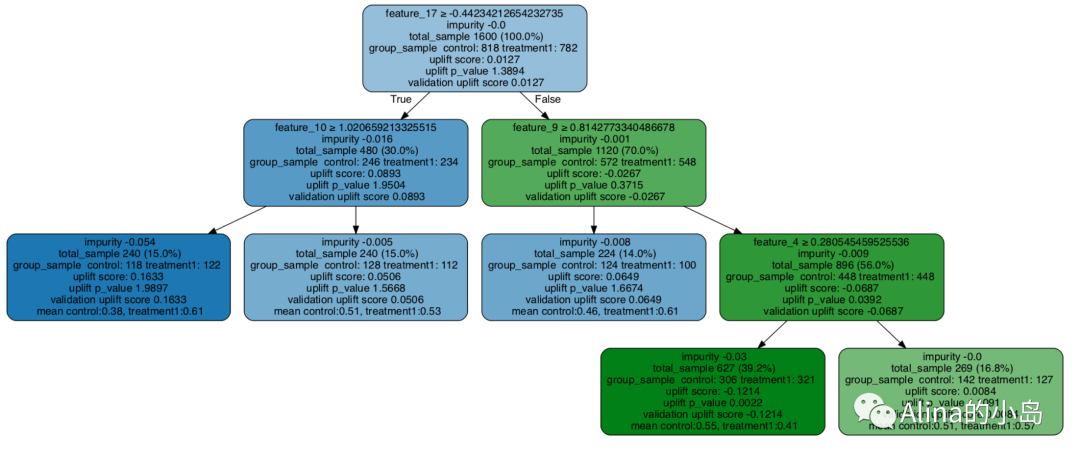
图片取自Uplift Tree visualization example notebook
最
后
CausalML的使用感受
Causalml包含了非常丰富的与uplift场景相关的模型可供使用,在数据处理与模型训练方式上继承了sklearn,提供了一种通用化的模型训练与统计指标评估的方式,官方Github上有各个场景下的建模示例可以参考。
缺点是,Causalml的环境配置与安装存在一定的困难;源码实现中存在一些较为随意的变量命名和不一致的数据格式要求,在不同类型的uplift任务之间需要注意数据形式的转换。
总体而言,Causalml提供了全面详细且通用化的uplift场景建模接口,使用起来还是很方便的。
🌷Uplift系列暂时打算更新到这里啦,一晃也小半年了,希望这三期能对你有帮助,之后如果有好的学习资料再不定期更新~
大家多保重,增强免疫力
我们一起健康幸福地过完这个冬天!
Reference
1. Causalml Document:
causalml.readthedocs.io
2. Causalml Example Notebook:
https://github.com/uber/causalml/tree/master/examples
